工具精選策略通過重排序與可選的查詢改寫,在請求發送至大語言模型前對工具列表進行預先處理和篩選,可提升大規模工具集情境下的響應速度與選擇精度,並降低Token成本。
適用情境
大規模工具集管理:當開發人員構建包含數十或上百個工具的複雜Agent時,需確保模型能夠高效且準確地進行工具選擇。
多輪對話中的意圖識別挑戰:在連續多輪對話中,使用者的核心意圖可能分布在歷史對話內容中,若僅依據最新輸入進行工具匹配,可能導致選擇偏差。
Token限制下的最佳化需求:當所有工具的名稱與描述(不含參數)總長度超出Rerank模型的輸入Token限制時,需採用有效篩選或排序策略以保障功能正常運行。
方案說明
工具精選在API請求被轉寄至後端大語言模型服務前執行。其工作流程如下:
請求接收:AI網關接收包含查詢和原始工具列表的API請求。
查詢改寫(可選):若啟用,該模組分析對話上下文,對原始查詢(Query)進行最佳化和重寫,產生更明確的查詢語句,以提升後續工具匹配的準確性。
工具精排:該模組接收(可能已被改寫的)查詢和完整的工具列表,使用Rerank模型計算每個工具與查詢之間的相關性得分。
工具篩選:根據預設的篩選策略(如Top-N、Top-K),從排序後的工具列表中篩選出一個最優子集。相關性得分低於設定閾值的工具將被丟棄。
請求轉寄:AI網關將原始請求中的工具列表替換為篩選後的精簡工具列表,然後將請求轉寄給後端的大語言模型。
此策略僅適用於工具資訊位於請求體tools欄位內的Function Calling請求。
效能表現
在Salesforce的開來源資料集上,使用50/100/200/300/400/500個不同規模的工具集進行評測,結果表明:
準確性提升:經過查詢改寫(Query Rewrite)和工具精排(Reranker)後,工具及參數的選擇準確性最高可提升6%。
響應速度提升:當工具集規模超過50個時,回應時間(RT)有顯著下降。在500個工具的測試情境下,響應速度最高可提升7倍。
成本降低:Token消耗(費用)可降低4~6倍。
評測使用的模型:
大語言模型:
qwen3-235b-a22b-instruct-2507Rerank模型:
gte-rerank-v2查詢改寫模型:
qwen3-30b-a3b-instruct-2507
評測效果
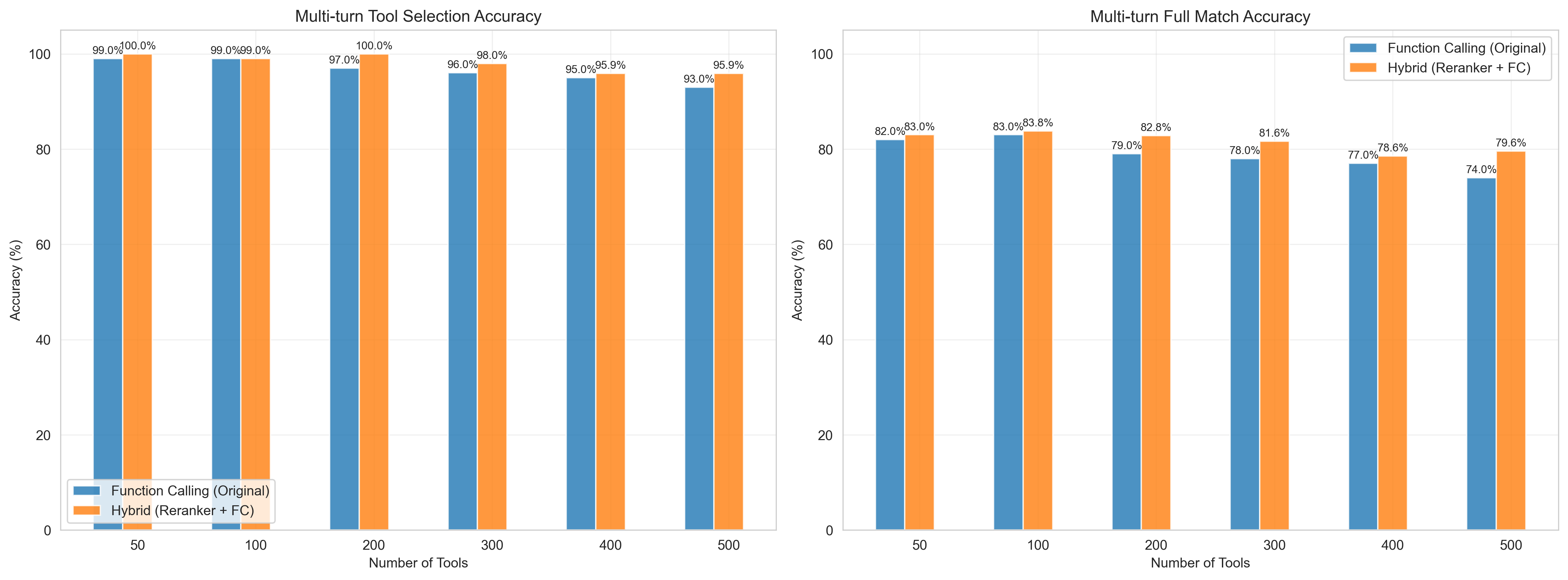
藍色柱狀圖為直接使用模型Function Calling。
橙色柱狀圖為使用工具精選(查詢改寫 + Rerank + Function Calling)。
橫座標為工具數,縱座標為準確率(%)。
左圖為工具選用準確率,右圖為工具選用+參數選用準確率。

藍色柱狀圖為直接使用模型Function Calling。
橙色柱狀圖為使用工具精選(查詢改寫 + Rerank + Function Calling)。
橫座標為工具數,縱座標為單次調用耗時。
隨著工具數量增加,採用工具精選的方案幾乎不會增加耗時,而直接使用大模型的Function Calling耗時隨工具數量增加而線性增加。

藍色柱狀圖為直接使用模型Function Calling。
橙色柱狀圖為使用工具精選(查詢改寫 + Rerank + Function Calling)。
橫座標為工具數,縱座標為每次工具調用的整體費用(以阿里雲百鍊標準進行Token計費)。
隨著工具數量增加,使用工具精選方案並不會產生明顯的Token費用提升,相比直接使用大模型Function Calling能節省大量費用。
操作步驟
前往AI 網關控制台執行個體頁面,在頂部功能表列選擇目標執行個體所在地區,單擊目標執行個體 ID。
在左側導覽列,選擇Model API,然後單擊目標API 名稱進入API 詳情頁面。
單擊策略與外掛程式,開啟工具精選開關並完成配置,相關配置參考配置項說明。
確認配置資訊並單擊儲存。
配置項說明
全域配置
配置項 | 說明 |
啟用工具精選 | 工具精排功能總開關。開啟後相關配置生效。關閉後,網關將透傳原始請求,不進行工具篩選。 |
觸發條件 | 工具數量的最小閾值。當API請求中的工具數量大於或等於此閾值時,工具精排功能才會被啟用。 |
工具精排
通過智慧型工具精選功能,在請求送達LLM之前對工具列表進行預先處理和篩選,提升模型響應速度、提高工具選擇精確性並降低API調用成本。
配置項 | 說明 |
Rerank 模型服務 |
|
篩選方式 |
|
相關性得分閾值 | 範圍0.0~1.0。Rerank得分低於此閾值的工具將被丟棄,即使它在Top-K/N範圍內。0表示禁用此功能。 |
失敗處理策略 | 當精排模型調用失敗時的處理方式:• 跳過精排,使用原始工具• 插斷要求並報錯 |
查詢改寫
適用於多輪對話,在工具精排前,匯總多輪對話摘要,最佳化使用者查詢,以提升精排準確率。建議多輪對話情境中開啟。
配置項 | 說明 |
啟用查詢改寫 | 是否啟用此增強功能。 |
改寫模型服務 |
|
改寫提示詞 | 可選用內建最佳化過的Prompt模板,或自訂Prompt。 |
最大輸出Token | 控制改寫後查詢的最大長度。 |
觸發條件 | 對話輪次超過此數值時啟用查詢改寫。設定為0表示禁用此條件。 |
上下文選擇 | 定義用於改寫的上下文範圍。 |
失敗處理策略 | 當改寫模型調用失敗時的處理方式:
|
常見問題
問題一:“工具精排”功能相比傳統的向量檢索有什麼優勢?為什麼它更精準?
兩者的核心區別在於資訊處理的方式,這直接決定了其精確度的差異。
傳統向量檢索(不夠精準):此方法通常先將“使用者查詢”和“工具描述”分開、獨立地轉換成數學向量(Embedding),然後再計算這些向量之間的相似性來排序。局限性:這個過程是“隔離”的,查詢和工具之間缺乏深度的互動。這就像是通過比較兩本書的摘要來判斷它們是否相關,很多細節、上下文和複雜的邏輯關係會丟失,導致對使用者真實意圖的理解不夠深入。
AI網關工具精選的Rerank交叉編碼器(更精準): Rerank模型採用了一種更先進的架構。不會分開處理,而是將“使用者查詢”和“工具描述”配對拼接在一起,作為一個整體輸入給模型進行分析。優勢:這種方式實現了“深度互動”。模型可以直接、細緻地分析查詢中的每個詞與工具描述中每個詞的關聯。這就像是把兩本書並排放在一起逐頁對比閱讀,能夠捕捉到複雜的意圖、否定關係和特定條件。結果:因此,Rerank的判斷標準從“語義上是否相似”躍升到了“功能上是否真正匹配”,能夠更精準地理解使用者的任務需求,從而篩選出最合適的工具。
問題二:查詢改寫(Query Rewriting)功能推薦開啟嗎?有什麼副作用?
在多輪對話的業務情境下,強烈推薦開啟。
收益:查詢改寫能將依賴內容相關的模糊、簡潔的使用者問題,轉化為一個資訊完整的獨立查詢,極大地提升後續工具精排(Reranking)和最終LLM選擇工具的準確性。
副作用:會引入一次額外的模型調用,因此會帶來輕微的響應耗時增加。但對於多輪對話情境,增加的耗時換來的準確性提升通常是完全值得的。如果應用情境均為單輪對話,則可以關閉此功能。
問題3:遇到不符合預期的工具選擇結果,應如何解決?
可以從以下幾個方面進行排查和最佳化:
最佳化工具描述:確保每個工具的名稱(name)和描述(description)清晰、準確且具有區分度。Rerank模型和LLM都強依賴這部分資訊來理解工具的功能。
自訂查詢改寫提示詞:如果內建的改寫邏輯不完全符合業務需求,可以嘗試使用自訂Prompt,設計更貼合情境的改寫策略,指導改寫模型產生更精準的查詢。
調整篩選參數:根據實際情況調整Top-N/Top-K的數值。如果發現正確的工具經常被過濾掉,可以適當調高該值;如果總是引入不相關的工具,可以適當調低。
調整相關性得分閾值:適當提高相關性得分閾值(如設定為0.3),可以過濾掉相關性不高的工具,進一步提升工具列表的“信噪比”。