在PAI-Rec中所有的服務和實驗都需要關聯一個推薦的情境,例如“首頁瀑布流推薦”,“購物車猜你喜歡”,“詳情頁相關推薦”等等。下面我們介紹建立的細節。
推薦情境
我們先建立一個推薦情境(建議情境的名稱可以說明推薦情境的頁面位置),下面“首頁瀑布流推薦”中的“首頁”說明了情境的位置,“瀑布流”說明情境是可以不斷下滑瀏覽的。
流量編碼是為不走PAI-Rec系統的推薦請求預留的。這種情況非常常見:當使用者自己已有推薦系統的時候,在剛開始會把這個情境從切10%到20%的推薦流量給PAI-Rec系統。當PAI-Rec的推薦效果達到預期之後再逐漸增加流量。HomePageRec的預設流量是走PAI-Rec的,而selfhold表示使用者自持的流量,thirdparty是第三方流量。
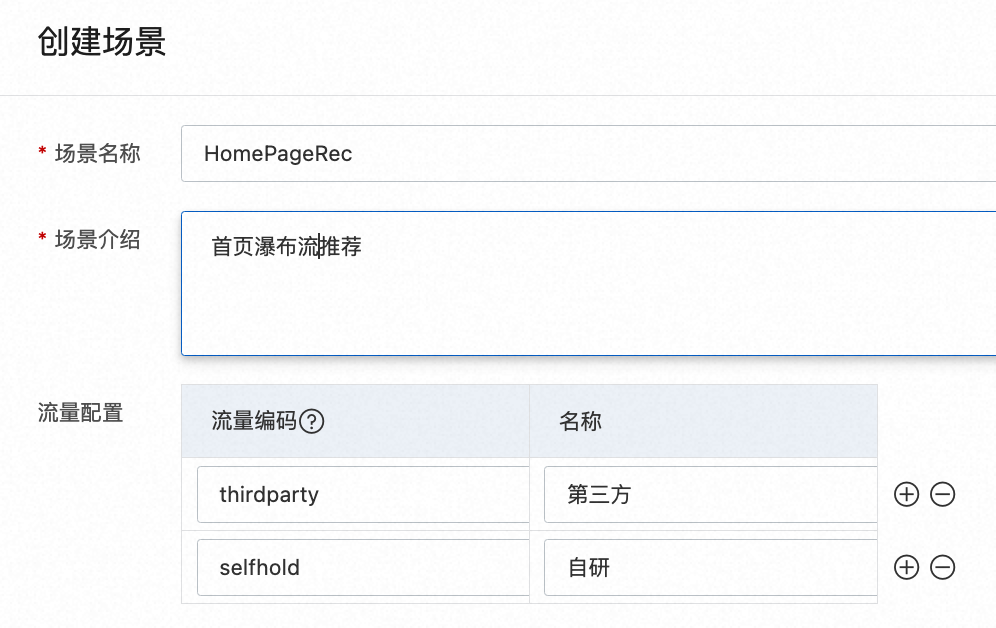
如下圖中有6個使用者,根據系統的分桶邏輯(由客戶實現),兩個使用者通過selfhold(客戶自持流量)得到推薦結果;兩個使用者通過PAI-Rec得到推薦結果;兩個使用者通過thirdparty(第三方)得到推薦結果;
實驗室和實驗層
當使用者的推薦請求路由到PAI-Rec的內部之後,我們對這些推薦請求做了進一步的流量分桶。我們根據業界常用a/b test方案設計了實驗室、實驗層、實驗組、實驗,實驗室包含了實驗層,實驗層包含實驗組,實驗組中包含了實驗。
首先,實驗室是一組流量的集合,既可以只建立一個實驗室,也可以建立多個實驗室。當只有一個實驗室的時候,這個實驗室必須是Base實驗室(作為兜底的實驗室),並且Base實驗室是必須的。流量會優先匹配非 Base 實驗室,當推薦請求沒有匹配到非base實驗室時會進入 Base實驗室。因此,我們可以只建立一個兜底的實驗室。
我們可以建立一個召回和排序邏輯都相對簡單的實驗室作為兜底實驗室,而通常用的複雜的召回和排序邏輯放在非Base實驗室。這樣,當流量突然太大時,我們可以把部分流量切換到base實驗室,以防止整個推薦系統被拖垮。
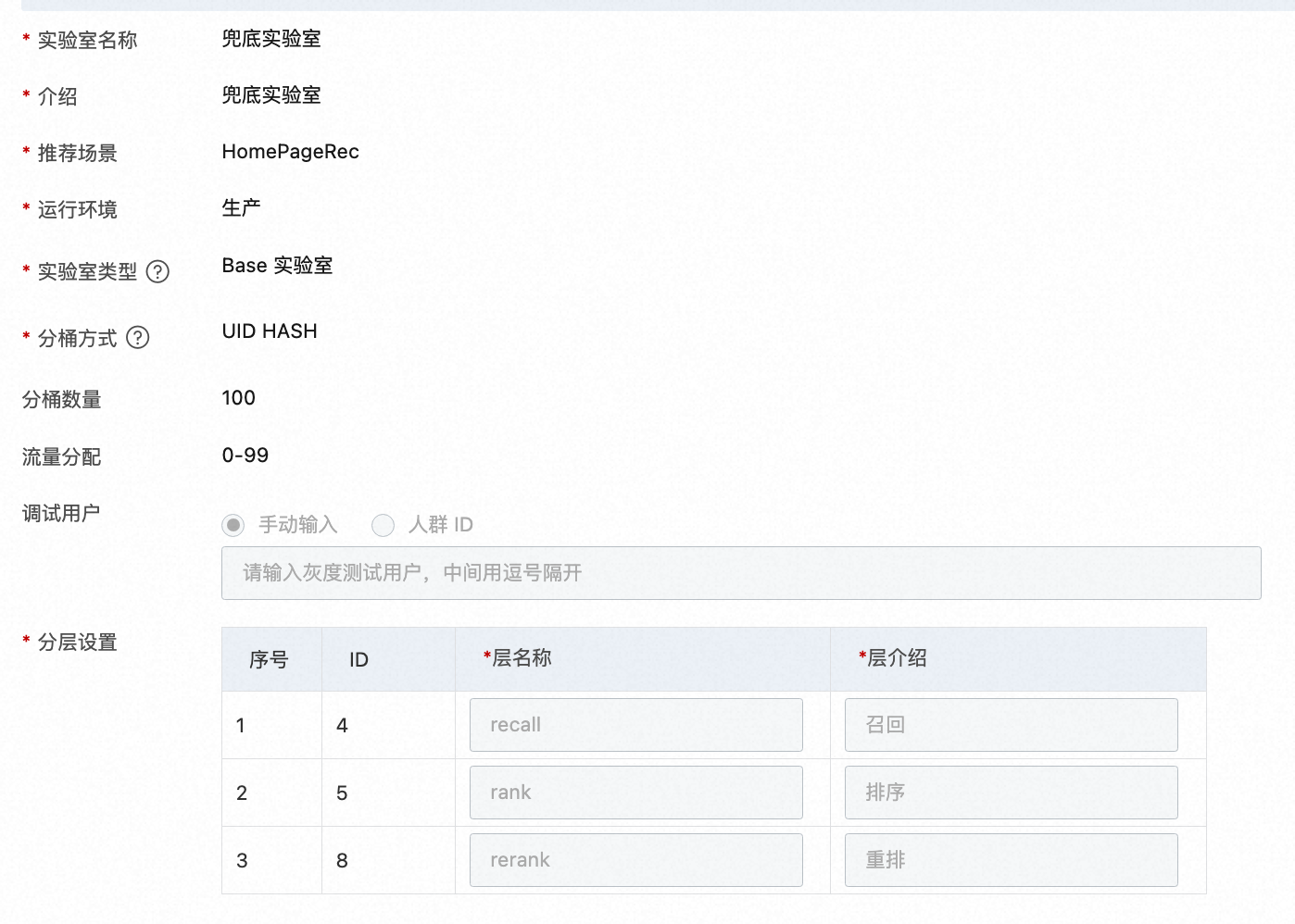
上面是Base實驗室的案例,對上圖表格中的名稱解釋如下:
實驗室名稱:自訂實驗室名稱
介紹:實驗室的詳細描述
實驗室類型:
base 實驗室:必須有一個base實驗室,可以沒有非base實驗室。
非 base 實驗室:優先匹配非 base 實驗室。當base實驗室的模型比較簡單,而非base實驗室的模型比較複雜的時候,可以設定兩個實驗室。base實驗室也可以完全用一個熱門隨機兜底邏輯來實現。
運行環境:對應引擎的運行環境,日常(daily), 預發(prepub),生產(product)
實驗室桶類型:
UID分桶:根據 uid 的末尾數字分桶
UID HASH:根據 uid 的 hash 值分桶
過濾條件分桶:kv 運算式分桶,如 gender=man
分桶數量:此實驗室分得的桶數,總數為100
流量分配:分得的桶的編號,可以設定為0-99
分層:實驗層一般設定recall(召回)、filter(過濾)、coarse_rank(粗排)、rank(排序)等
調試使用者:調試使用者可以不經過匹配,直接進入此實驗室
手動輸入:可以輸入多個,以逗號分隔
人群 ID:一組 uid 的集合,需要提前在【人群管理】中建立
實驗組和實驗室
在每一層可以設定多個實驗組,每一個組裡面可以設定多個實驗。為什麼要設定多個實驗組呢?當有多個演算法工程師做召回或者排序實驗的時候,我們可以通過劃分實驗組,可以讓他們相互自己不干涉。
每個實驗組中,一般都會有多個實驗。例如下面我們配置了swing、etrec兩個實驗,而dssm還在測試中,因此流量佔比設定為“0%”,但是處於上線狀態。DSSM處於上線狀態是方便我們通過白名單來觀察推薦效果。
