本文將指導您如何在 ACK 叢集中通過VeRL基於Qwen2.5-3B-Instruct模型部署和運行典型的強化學習任務,包括環境準備、鏡像構建、任務提交、資源監控及最佳實務。
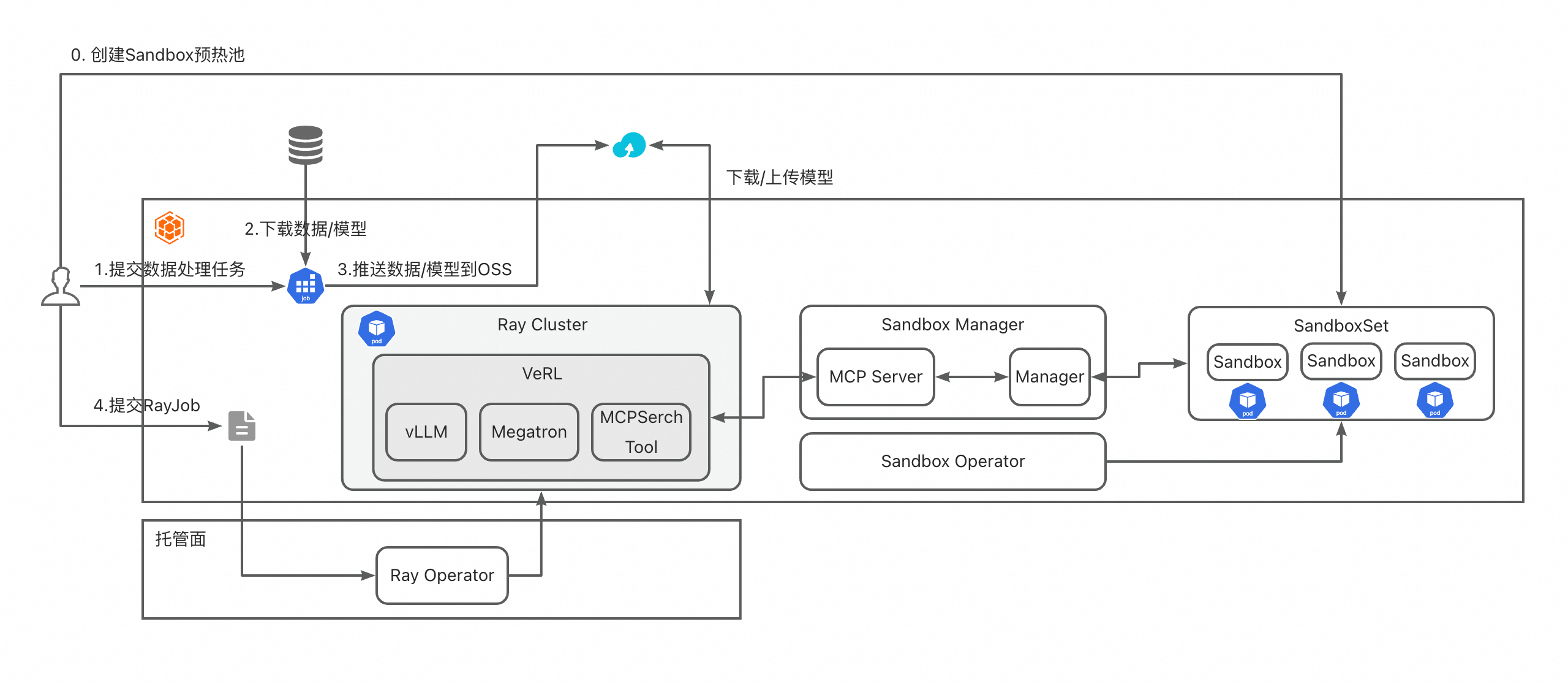
Container Service for Kubernetes (ACK)為企業提供了一種高效、彈性、可擴充的容器化平台。強化學習(Reinforcement Learning, RL)作為人工智慧的重要分支,通常涉及大量計算資源、分布式訓練和複雜環境類比。藉助 ACK,您可以輕鬆部署、管理和擴充強化學習訓練任務,充分利用 Kubernetes 的調度能力與阿里雲的彈性基礎設施。下圖展示了本次作業啟動並執行組件架構。
準備工作
-
-
推薦使用 GPU 執行個體節點以加速訓練。本文樣本中使用 1 台 8 卡 GU8TF 的靈駿節點。
-
-
(可選)已開通Object Storage Service,用於持久化模型檢查點、日誌和訓練資料。
步驟一:準備強化學習訓練鏡像
本樣本採用VeRL架構執行強化學習任務,您可以使用VeRL官方提供的鏡像,也可以使用自建鏡像。使用自建鏡像時需要保證鏡像中有已安裝相關依賴包,如VeRL,vLLM,SGLang,Ray等。下面是一個樣本Dockerfile:
from verl/verl:vllm012.latest
WORKDIR /home/verl
COPY . .
RUN apt update && apt install -y openssh-server vim
RUN apt remove python3-blinker -y; pip install -e .步驟二:配置MCP Server並使用ACS Sandbox
-
安裝MCP Server和Sandbox組件。
開源版本
# 下載代碼倉庫 git clone https://github.com/openkruise/agents cd agents # 產生agents operator部署yaml kubectl kustomize config/default >operator-install.yaml # 按需修改 operator-install.yaml 中的配置資訊 kubectl apply -f operator-install.yaml # 部署測試 sandbox-manager,參考 https://github.com/openkruise/agents/blob/master/config/sandbox-manager/README_zh-CH.md kubectl kustomize config/sandbox-manager >sandbox-manager.yaml # mcp 代碼還未合入因此需要手動將sandbox-manager鏡像改成 # baicun-business-registry.cn-beijing.cr.aliyuncs.com/baicun-dev/sandbox:sandbox-manager-v12 # 確認管理pod運行正常 kubectl get pod -l "app.kubernetes.io/name=sandbox-manager" -A kubectl get pod -l "app.kubernetes.io/name=sandbox-controller-manager" -A應用市場版本
-
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇組件管理。
-
安裝 Ingress Controller 和 Sandbox 相關組件。
-
安裝
ack-agent-sandbox-controller組件使用預設配置安裝組件。
-
安裝
ack-sandbox-manager組件-
準備E2B網域名稱。
準備網域名稱、網域名稱解析和申請認證的詳細操作,請參見應用於生產環境。
-
配置組件參數。
修改
className為alb(以安裝ALB Ingress Controller組件為例),修改domain為實際網域名稱,修改adminApiKey為自訂API Key,其他配置保持預設。組件安裝完成後會在sandbox-system命名空間中建立一個名為sandbox-manager的路由。 -
若使用ALB Ingress Controller,還需同時為ALB執行個體和Ingress新增HTTPS:443監聽配置。
-
-
-
-
將以下內容儲存為
sandbox.yaml,然後執行kubectl apply -f sandbox.yaml部署Sandbox定義。SandboxSet會建立出大小為3的預熱池,在強化學習過程中SandboxManager會不斷從該預熱池中取出並使用Sandbox。--- apiVersion: v1 kind: Service metadata: name: mcp-sandbox spec: selector: app.kubernetes.io/instance: release-name app.kubernetes.io/name: ack-sandbox-manager component: sandbox-manager type: ClusterIP sessionAffinity: None sessionAffinityConfig: clientIP: timeoutSeconds: 10800 ports: - name: vllm protocol: TCP port: 8000 targetPort: 18082 --- apiVersion: agents.kruise.io/v1alpha1 kind: SandboxSet metadata: annotations: # 啟用 SandboxManager 的 Envd 初始化能力 e2b.agents.kruise.io/should-init-envd: "true" name: code-interpreter namespace: default spec: # 預熱池的大小,建議比預估的請求突發量略大 replicas: 3 template: spec: initContainers: - name: init image: registry-cn-hangzhou.ack.aliyuncs.com/acs/agent-runtime:v0.0.1 imagePullPolicy: IfNotPresent terminationMessagePolicy: File volumeMounts: - name: envd-volume mountPath: /mnt/envd env: - name: ENVD_DIR value: /mnt/envd restartPolicy: Always containers: - name: sandbox image: acs-image-test-01-registry.cn-hangzhou.cr.aliyuncs.com/e2b/code-interpreter:v1.6 imagePullPolicy: IfNotPresent terminationMessagePolicy: File env: - name: ENVD_DIR value: /mnt/envd volumeMounts: - name: envd-volume mountPath: /mnt/envd lifecycle: postStart: exec: command: - bash - /mnt/envd/envd-run.sh startupProbe: failureThreshold: 20 successThreshold: 1 httpGet: path: /health port: 49999 scheme: HTTP initialDelaySeconds: 1 periodSeconds: 2 timeoutSeconds: 1 # 保證容器快速銷毀,提高複用的機率 terminationGracePeriodSeconds: 1 restartPolicy: Always dnsPolicy: ClusterFirst volumes: - name: envd-volume emptyDir: { }
(可選)步驟三:準備強化學習資料集
VeRL中可以通過指定data.train_files的方式從遠端下載資料集。不過由於資料集通常較大,且通常需要一些預先處理,在生產環境中建議通過預先處理任務下載資料,完成預先處理並推送到雲端儲存。
-
將以下內容儲存為
data.yaml,然後執行kubectl apply -f data.yaml從Hugging Face下載資料,進行預先處理,並推送到OSS Bucket。apiVersion: v1 kind: Secret metadata: name: hf-oss-credentials namespace: default type: Opaque stringData: # HuggingFace Token HF_TOKEN: "hf_xxxxx" # 阿里雲 OSS 憑證 (alibabacloud-oss-v2 SDK 使用環境變數認證) akId: "xxx" akSecret: "xxx" OSS_REGION: "xxx" OSS_BUCKET: "xxx" --- apiVersion: v1 kind: ConfigMap metadata: name: preprocess-script namespace: default data: preprocess.py: | #!/usr/bin/env python3 """ 資料集預先處理指令碼樣本 """ import os import json from datasets import load_from_disk def preprocess_dataset(input_dir, output_dir): """預先處理資料集""" print(f"Loading dataset from {input_dir}") dataset = load_from_disk(input_dir) train_dataset = dataset["train"] test_dataset = dataset["test"] instruction_following = "Let's think step by step and output the final answer after `####`." # add a row to each data item that represents a unique id def make_map_fn(split): def process_fn(example, idx): question_raw = example.pop("question") question = question_raw + " " + instruction_following answer_raw = example.pop("answer") solution = extract_solution(answer_raw) data = { "data_source": data_source, "agent_name": "tool_agent", "prompt": [ { "role": "system", "content": ( "You are a math expert. You are given a question and you need to solve it step by step. " "Reasoning step by step before any tool call. " "You should use the `calc_gsm8k_reward` tool after step by step solving the question, " "before generate final answer at least once and refine your answer if necessary. " "Put your final answer in the format of `#### <answer>`." ), }, { "role": "user", "content": question, }, ], "ability": "math", "reward_model": {"style": "rule", "ground_truth": solution}, "extra_info": { "split": split, "index": idx, "answer": answer_raw, "question": question_raw, "need_tools_kwargs": True, "tools_kwargs": { "calc_gsm8k_reward": { "create_kwargs": {"ground_truth": solution}, # "execute_kwargs": {}, # "calc_reward_kwargs": {}, # "release_kwargs": {}, }, }, "interaction_kwargs": { "query": question, "ground_truth": solution, }, }, } return data return process_fn train_dataset = train_dataset.map(function=make_map_fn("train"), with_indices=True, num_proc=8) test_dataset = test_dataset.map(function=make_map_fn("test"), with_indices=True, num_proc=8) # 儲存處理後的資料集 os.makedirs(output_dir, exist_ok=True) train_dataset.to_parquet(os.path.join(output_dir, "train.parquet")) test_dataset.to_parquet(os.path.join(output_dir, "test.parquet")) print(f"Processed dataset saved to {output_dir}") return output_dir if __name__ == "__main__": input_path = os.environ.get("INPUT_PATH", "/data/raw") output_path = os.environ.get("OUTPUT_PATH", "/data/processed") preprocess_dataset(input_path, output_path) --- apiVersion: batch/v1 kind: Job metadata: name: dataset-pipeline namespace: default labels: app: dataset-pipeline spec: backoffLimit: 3 template: metadata: labels: app: dataset-pipeline spec: restartPolicy: OnFailure volumes: # 預先處理指令碼 - name: scripts configMap: name: preprocess-script defaultMode: 0755 containers: - name: dataset-pipeline image: python:3.10-slim command: - /bin/bash - -c - | set -e #========================================== # Step 1: 安裝所有依賴 #========================================== echo "=== Installing dependencies ===" pip install --no-cache-dir datasets huggingface_hub pandas numpy alibabacloud-oss-v2 Pillow #========================================== # Step 2: 從 HuggingFace 下載資料集 #========================================== echo "=== Downloading dataset from HuggingFace ===" python3 << 'EOF' import os from datasets import load_dataset from huggingface_hub import login # 登入 HuggingFace(如果需要訪問私人資料集) hf_token = os.environ.get("HF_TOKEN") if hf_token: login(token=hf_token) # 下載資料集 dataset_name = os.environ.get("DATASET_NAME", "hiyouga/geometry3k") dataset_config = os.environ.get("DATASET_CONFIG", None) print(f"Downloading dataset: {dataset_name}") dataset = load_dataset(dataset_name, dataset_config) # 儲存到本地 output_path = "/data/raw" dataset.save_to_disk(output_path) print(f"Dataset saved to {output_path}") EOF echo "=== Download completed ===" #========================================== # Step 3: 執行預先處理指令碼 #========================================== echo "=== Running preprocessing script ===" python3 /scripts/preprocess.py echo "=== Preprocessing completed ===" #========================================== # Step 4: 上傳到 OSS (使用 alibabacloud-oss-v2 SDK) #========================================== echo "=== Uploading to OSS ===" python3 << 'EOF' import os from pathlib import Path import alibabacloud_oss_v2 as oss # OSS 配置 bucket_name = os.environ["OSS_BUCKET"] region = os.environ["OSS_REGION"] oss_prefix = os.environ.get("OSS_PREFIX", "data/geo3k-processed/") local_path = os.environ.get("OUTPUT_PATH", "/data/processed") # 使用環境變數憑證提供者 (自動讀取 OSS_ACCESS_KEY_ID 和 OSS_ACCESS_KEY_SECRET) credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider() # 載入預設配置並設定憑證提供者 cfg = oss.config.load_default() cfg.credentials_provider = credentials_provider cfg.region = region # 建立 OSS 用戶端 client = oss.Client(cfg) def upload_directory(local_dir, oss_prefix): """遞迴上傳目錄到 OSS""" local_path = Path(local_dir) uploaded_count = 0 failed_count = 0 for file_path in local_path.rglob("*"): if file_path.is_file(): relative_path = file_path.relative_to(local_path) oss_key = f"{oss_prefix}{relative_path}" try: # 讀取檔案內容 with open(file_path, 'rb') as f: data = f.read() # 上傳到 OSS result = client.put_object(oss.PutObjectRequest( bucket=bucket_name, key=oss_key, body=data, )) print(f"Uploaded: {file_path} -> {oss_key} (status: {result.status_code})") uploaded_count += 1 except Exception as e: print(f"Failed to upload {file_path}: {e}") failed_count += 1 return uploaded_count, failed_count uploaded, failed = upload_directory(local_path, oss_prefix) print(f"=== Upload completed: {uploaded} files uploaded, {failed} files failed ===") if failed > 0: raise Exception(f"{failed} files failed to upload") EOF echo "=== Pipeline completed successfully ===" env: # HuggingFace 配置 - name: HF_TOKEN valueFrom: secretKeyRef: name: hf-oss-credentials key: HF_TOKEN - name: DATASET_NAME value: "hiyouga/geometry3k" - name: HF_HOME value: "/tmp/huggingface" # 預先處理配置 - name: INPUT_PATH value: "/data/raw" - name: OUTPUT_PATH value: "/data/processed" # OSS 配置 - name: OSS_ACCESS_KEY_ID valueFrom: secretKeyRef: name: hf-oss-credentials key: akId - name: OSS_ACCESS_KEY_SECRET valueFrom: secretKeyRef: name: hf-oss-credentials key: akSecret - name: OSS_REGION valueFrom: secretKeyRef: name: hf-oss-credentials key: OSS_REGION - name: OSS_BUCKET valueFrom: secretKeyRef: name: hf-oss-credentials key: OSS_BUCKET - name: OSS_PREFIX value: "data/geo3k-processed/" volumeMounts: - name: scripts mountPath: /scripts resources: requests: memory: "2Gi" cpu: "1" limits: memory: "16Gi" cpu: "4"
步驟四:提交強化學習任務配置
-
將以下內容儲存為
pvpvc.yaml,然後執行kubectl apply -f pvpvc.yaml通過PV和PVC掛載OSS靜態儲存卷。以下樣本使用AK/SK方式認證,RRSA方式請參考使用ossfs 2.0靜態儲存卷。
apiVersion: v1 kind: PersistentVolume metadata: name: ym-dataset labels: alicloud-pvname: ym-dataset spec: capacity: storage: 20Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: ym-dataset # 需要和PV名字一致。 nodePublishSecretRef: name: hf-oss-credentials namespace: default volumeAttributes: bucket: "xxxx" #替換為實際Bucket名稱。 url: "oss-ap-southeast-1-internal.aliyuncs.com" #替換為實際oss url名稱。 otherOpts: "-o umask=022 -o max_stat_cache_size=100000 -o allow_other -o dbglevel=debug -o curldbg" path: "/" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: ym-dataset spec: accessModes: - ReadWriteMany resources: requests: storage: 20Gi selector: matchLabels: alicloud-pvname: ym-dataset # (可選)Model可以通過傳入HuggingFace倉庫路徑進行即時下載 --- apiVersion: v1 kind: PersistentVolume metadata: name: ym-models labels: alicloud-pvname: ym-models spec: capacity: storage: 20Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: ym-models # 需要和PV名字一致。 nodePublishSecretRef: name: hf-oss-credentials namespace: default volumeAttributes: bucket: "xxxx" #替換為實際Bucket名稱。 url: "oss-ap-southeast-1-internal.aliyuncs.com" #替換為實際oss url名稱。 otherOpts: "-o umask=022 -o max_stat_cache_size=100000 -o allow_other -o dbglevel=debug -o curldbg" path: "/" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: ym-models spec: accessModes: - ReadWriteMany resources: requests: storage: 20Gi selector: matchLabels: alicloud-pvname: ym-models -
將以下內容儲存為
configs.yaml,然後執行kubectl apply -f configs.yaml提交任務相關配置。--- apiVersion: v1 kind: ConfigMap metadata: name: gsm8k-configs namespace: default data: gsm8k_multiturn_grpo.yaml: | hydra: searchpath: - file://verl/trainer/config defaults: - ppo_trainer - _self_ data: max_prompt_length: 1024 max_response_length: 1024 train_batch_size: 256 return_raw_chat: True actor_rollout_ref: hybrid_engine: True rollout: name: vllm multi_turn: enable: True max_assistant_turns: 5 mcp_server.json: | { "mcpServers": { "Tavily Expert": { "url": "xxxxx", # 替換成sandbox mcp的ingress地址 "api_key": "xxxxx" # 如果需要添加api_key,可以在ray cluster中新增nginx容器進行代理 } } } gsm8k_mcp_tool_config.yaml: | tools: - class_name: verl.tools.mcp_search_tool.MCPSearchTool config: rate_limit: 120 timeout: 120 type: mcp mcp: mcp_servers_config_path: /var/configs/mcp_server.json tool_selected_list: - run_code_once - class_name: "verl.tools.gsm8k_tool.Gsm8kTool" config: type: native tool_schema: type: "function" function: name: "calc_gsm8k_reward" description: "A tool for calculating the reward of gsm8k. (1.0 if parsed answer is correct, 0.0 if parsed answer is incorrect or not correctly parsed)" parameters: type: "object" properties: answer: type: "string" description: "The model's answer to the GSM8K math problem, must be a digits" required: ["answer"]
步驟五:提交強化學習任務
VeRL中支援通過MCPSearchTool的方式查詢MCP Server提供的工具,在每個用例開始時會通過AgentLoop連結到MCP Server並在多輪對話中調用工具。
-
將以下內容儲存為
rayjob.yaml,然後執行kubectl apply -f rayjob.yaml提交強化學習任務。--- apiVersion: ray.io/v1 kind: RayJob metadata: name: rayjob-example namespace: default spec: shutdownAfterJobFinishes: false # ttlSecondsAfterFinished: 300 runtimeEnvYAML: | working_dir: /home/verl submissionMode: SidecarMode entrypoint: | python3 -m verl.trainer.main_ppo \ --config-path=/var/configs \ --config-name='gsm8k_multiturn_grpo' \ algorithm.adv_estimator=grpo \ data.train_batch_size=16 \ data.max_prompt_length=1024 \ data.max_response_length=1024 \ data.filter_overlong_prompts=True \ data.truncation='error' \ data.return_raw_chat=True \ actor_rollout_ref.model.path=/var/model/Qwen2.5-3B-Instruct \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=8 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=1 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.actor.entropy_coeff=0 \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=False \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=1 \ actor_rollout_ref.rollout.tensor_model_parallel_size=2 \ actor_rollout_ref.rollout.name=vllm \ actor_rollout_ref.rollout.mode=async \ actor_rollout_ref.rollout.gpu_memory_utilization=0.5 \ actor_rollout_ref.rollout.n=16 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=1 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ actor_rollout_ref.rollout.trace.backend=mlflow \ actor_rollout_ref.rollout.trace.token2text=True \ algorithm.use_kl_in_reward=False \ trainer.critic_warmup=0 \ trainer.logger='["console","mlflow"]' \ trainer.project_name='gsm8k_tool-agent' \ trainer.experiment_name='qwen2.5-3b_function_rm-gsm8k-vllm-tool-agent-verify-n16' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=1 \ trainer.test_freq=20 \ trainer.total_training_steps=1 \ data.train_files=/var/model-dataset/processed-gsm8k/train20.parquet \ data.val_files=/var/model-dataset/processed-gsm8k/test100.parquet \ actor_rollout_ref.rollout.multi_turn.tool_config_path="/var/configs/gsm8k_mcp_tool_config.yaml" \ actor_rollout_ref.actor.checkpoint.save_contents='["hf_model", "model"]' \ trainer.total_epochs=1 rayClusterSpec: headGroupSpec: rayStartParams: dashboard-host: 0.0.0.0 serviceType: ClusterIP template: metadata: annotations: labels: spec: affinity: {} tolerations: - key: node-role.alibabacloud.com/lingjun containers: - env: - name: VERL_ROOT value: /home/verl image: registry-ap-southeast-1.ack.aliyuncs.com/dev/verl:vllm012.latest.43dc9a44 imagePullPolicy: IfNotPresent name: ray-head resources: limits: cpu: "100" memory: 500Gi nvidia.com/gpu: "8" securityContext: runAsUser: 0 volumeMounts: - mountPath: /var/configs name: configs - mountPath: /var/model name: model - mountPath: /var/model-dataset name: model-dataset imagePullSecrets: - name: regcred-hangzhou - name: regcred-ap-southeast volumes: - name: configs configMap: name: gsm8k-configs - name: model persistentVolumeClaim: claimName: ym-models - name: model-dataset persistentVolumeClaim: claimName: ym-dataset