本文深入解析基於阿里雲Container ServiceACK的DeepSeek-R1-671B大模型分布式推理實戰方案。針對該千億參數模型(671B)單卡顯存不足的挑戰,提出混合并行策略(Pipeline Parallelism=2 + Tensor Parallelism=8),結合阿里雲Arena工具,實現在2台ecs.ebmgn8v.48xlarge(8*96GB)節點上的高效分布式部署。進一步示範如何將部署於ACK的DeepSeek-R1無縫整合至Dify平台,快速構建支援長文本理解的企業級智能問答系統。
背景介紹
DeepSeek模型
DeepSeek-R1模型是DeepSeek推出的第一代推理模型,旨在通過大規模強化學習提升大語言模型的推理能力。實驗結果表明,DeepSeek-R1在數學推理、編程競賽等多個任務上表現出色,不僅超過了其他閉源模型,而且在某些任務上接近或超越了OpenAI-o1系列模型。DeepSeek-R1在知識類任務和其他廣泛的任務類型中也表現出色,包括創意寫作、一般問答等。DeepSeek還將推理能力蒸餾到小模型上,通過對已有模型(Qwen、Llama等)微調提升模型推理能力。蒸餾後的14B模型顯著超越了現有的開源模型QwQ-32B,而蒸餾後的32B和70B模型均重新整理紀錄。 更多模型資訊,請參見DeepSeek AI GitHub倉庫。
vLLM
vLLM是一個高效易用的大語言模型推理服務架構,vLLM支援包括通義千問在內的多種常見大語言模型。vLLM通過PagedAttention最佳化、動態批量推理(continuous batching)、模型量化等最佳化技術,可以取得較好的大語言模型推理效率。更多關於vLLM架構的資訊,請參見vLLM GitHub程式碼程式庫。
Arena
前提條件
已建立包含GPU的Kubernetes叢集。具體操作,請參見為叢集添加GPU節點。推薦機型
ecs.ebmgn8v.48xlarge (8*96GB)。重要GPU節點請使用550及以上版本的驅動,您可以通過為GPU節點池添加標籤
ack.aliyun.com/nvidia-driver-version:550.144.03指定驅動版本為550.144.03。具體操作,請參見通過指定版本號碼自訂節點GPU驅動版本。Kubernetes叢集版本需要≥1.28。
(可選)已安裝雲原生AI套件。具體操作,請參見安裝雲原生AI套件。
(可選)已安裝Arena用戶端,且版本不低於0.14.0。具體操作,請參見配置Arena用戶端。
1. 多機分布式部署
1.1 模型切分
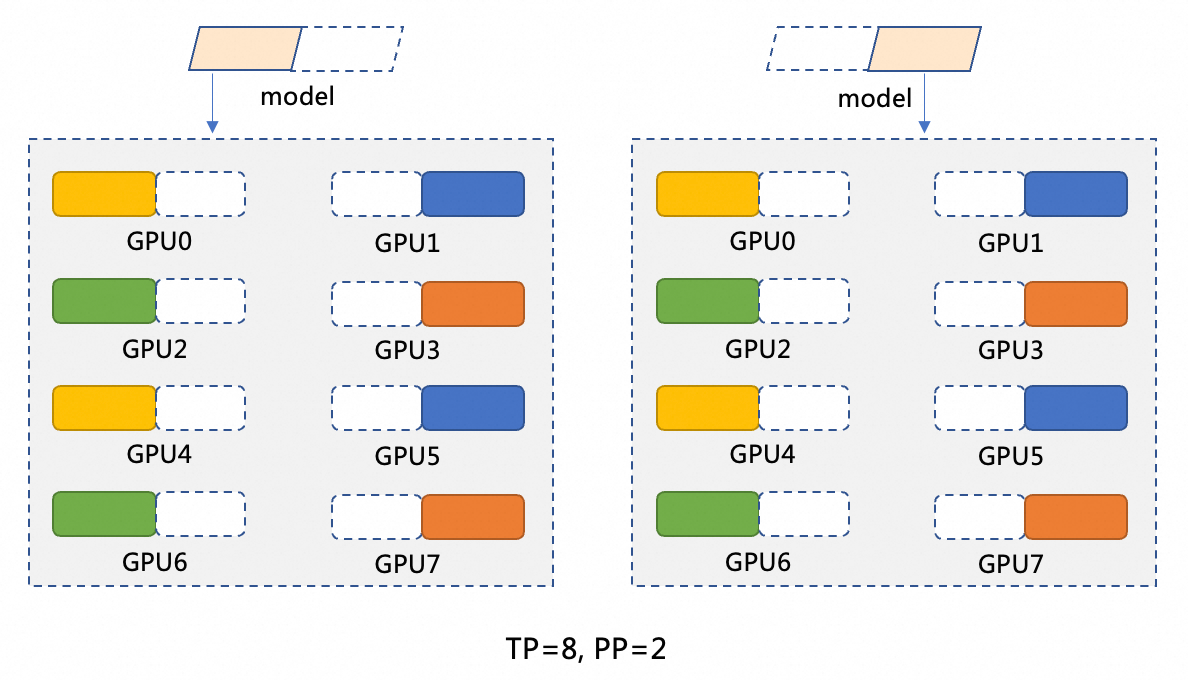
DeepSeek-R1模型共有671B參數,單張GPU顯存只有96GB,無法載入全部模型,因此需要將模型切分。本文採用了TP=8,PP=2的切分方式,模型切分示意圖如下。模型並行(PP=2)將模型切分為兩個階段,每個階段運行在一個GPU節點上。例如有一個模型 M,我們可以將其切分為M1和M2,M1在第一個GPU上處理輸入,完成後將中間結果傳遞給M2,M2在第二個GPU上進行後續操作。資料並行(TP=8)在模型的每個階段內(例如M1和M2),將計算操作分配到8個GPU上進行。在 M1階段,當輸入資料傳入時,這些資料將被分割為8份,並分別在8個GPU上同時處理。每個GPU處理一小部分資料,計算擷取的結果然後合并。
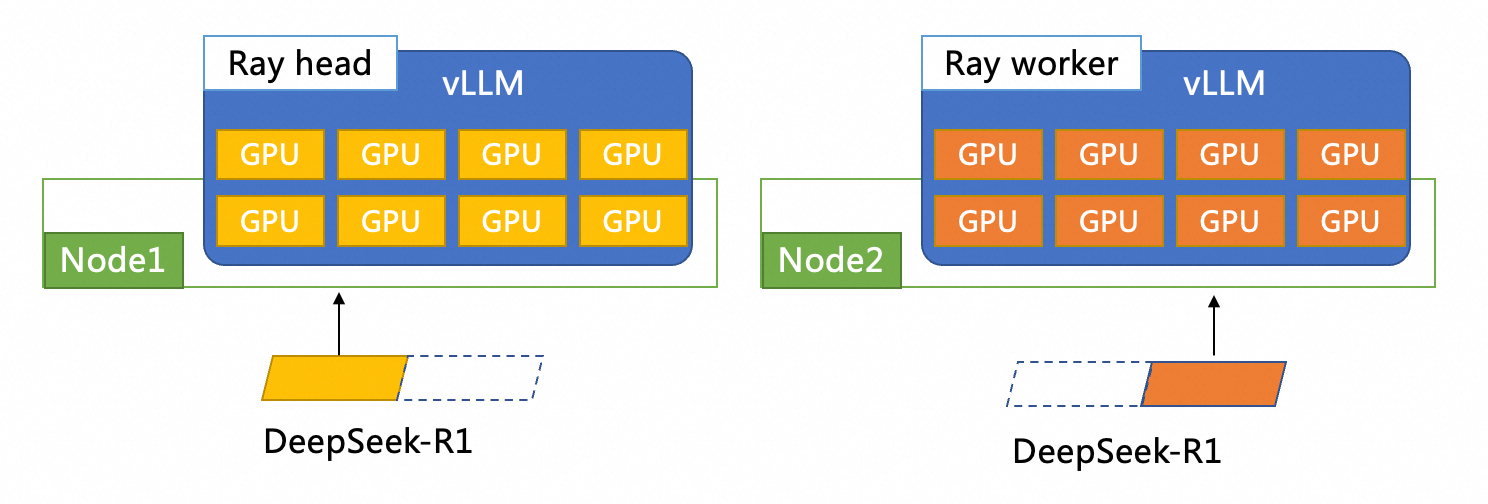
本文選擇vllm + ray的方式分布式部署DeepSeek-R1模型,整體部署架構如下所示。兩個vLLM Pod部署在兩台ECS上,每個vLLM Pod有8張GPU。兩個Pod一個作為Ray head節點,一個作為Ray worker節點。
1.2 模型下載
以DeepSeek-R1模型為例,將為您示範如何下載模型、上傳模型至OSS,以及在ACK叢集中建立對應的儲存卷PV和儲存卷聲明PVC。
如需上傳模型至NAS,請參見使用NAS靜態儲存卷。
模型檔案下載和上傳比較慢,您可以通過快速將模型檔案複製到您的OSS Bucket。
下載模型檔案。
執行以下命令,安裝Git。
# 可執行yum install git或apt install git安裝。 yum install git執行以下命令,安裝Git LFS(Large File Support)外掛程式。
# 可執行yum install git-lfs或apt install git-lfs安裝。 yum install git-lfs執行以下命令,將ModelScope上的DeepSeek-R1倉庫複製到本地。
GIT_LFS_SKIP_SMUDGE=1 git clone https://modelscope.cn/models/deepseek-ai/DeepSeek-R1執行以下命令,進入DeepSeek-R1目錄,下載LFS管理的大檔案。
cd DeepSeek-R1 git lfs pull
將下載的DeepSeek-R1檔案上傳至OSS。
為目的地組群配置儲存卷PV和儲存聲明PVC。具體操作,請參見使用ossfs 1.0靜態儲存卷。
建立PV。
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在儲存卷頁面,單擊右上方的建立。
在建立儲存卷對話方塊中配置參數。
以下為樣本PV的基本配置資訊:
配置項
說明
儲存卷類型
OSS
名稱
llm-model
訪問認證
配置用於訪問OSS的AccessKey ID和AccessKey Secret。
Bucket ID
選擇上一步所建立的OSS Bucket。
OSS Path
選擇模型所在的路徑,如/models/DeepSeek-R1。
建立PVC。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在儲存聲明頁面,單擊右上方的建立。
在建立儲存聲明頁面中,填寫介面參數。
以下為樣本PVC的基本配置資訊:
配置項
說明
儲存宣告類型
OSS
名稱
llm-model
分配模式
選擇已有儲存卷。
已有儲存卷
單擊選擇已有儲存卷連結,選擇已建立的儲存卷PV。
1.3 模型部署
安裝LeaderWorkerSet。
登入Container Service管理主控台,在左側導覽列選擇叢集列表。單擊目的地組群名稱,進入叢集詳情頁面,使用Helm為目的地組群安裝lws。您無需為組件配置應用程式名稱和命名空間,單擊下一步後會出現一個請確認的彈框,單擊是,即可使用預設的應用程式名稱(lws)和命名空間(lws-system)。然後選擇Chart 版本為最新版本,單擊確定即可完成lws的安裝。
模型部署。
以下是vLLM分布式部署架構圖。
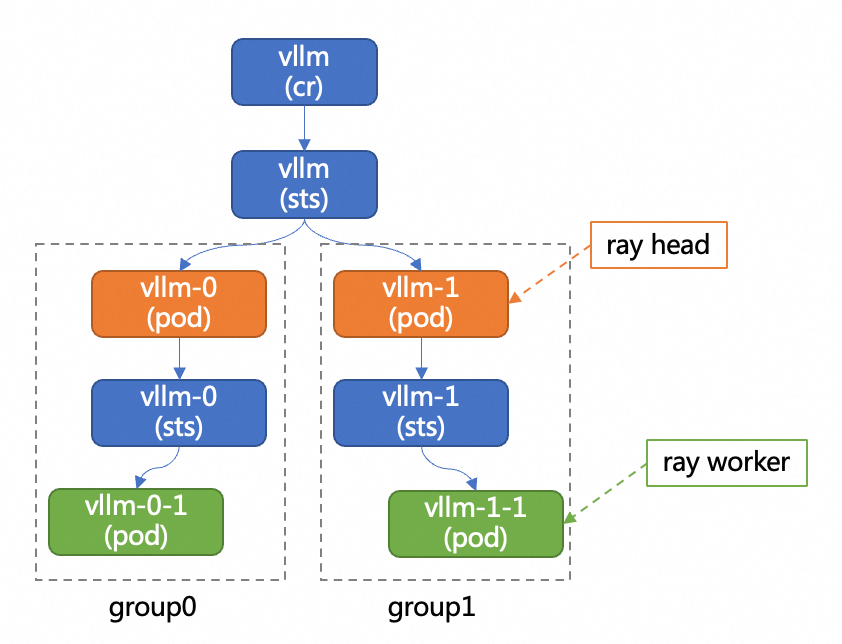
arena模型部署樣本
執行以下命令部署服務。
arena serve distributed \ --name=vllm-dist \ --version=v1 \ --restful-port=8080 \ --image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 \ --readiness-probe-action="tcpSocket" \ --readiness-probe-action-option="port: 8080" \ --readiness-probe-option="initialDelaySeconds: 30" \ --readiness-probe-option="periodSeconds: 30" \ --share-memory=30Gi \ --data=llm-model:/models/DeepSeek-R1 \ --leader-num=1 \ --leader-gpus=8 \ --leader-command="bash /vllm-workspace/examples/online_serving/multi-node-serving.sh leader --ray_cluster_size=\$(LWS_GROUP_SIZE); python3 -m vllm.entrypoints.openai.api_server --model /models/DeepSeek-R1 --port 8080 --trust-remote-code --served-model-name deepseek-r1 --gpu-memory-utilization 0.95 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enforce-eager" \ --worker-num=1 \ --worker-gpus=8 \ --worker-command="bash /vllm-workspace/examples/online_serving/multi-node-serving.sh worker --ray_address=\$(LWS_LEADER_ADDRESS)"預期輸出如下所示。
configmap/vllm-dist-v1-cm created service/vllm-dist-v1 created leaderworkerset.leaderworkerset.x-k8s.io/vllm-dist-v1-distributed-serving created INFO[0002] The Job vllm-dist has been submitted successfully INFO[0002] You can run `arena serve get vllm-dist --type distributed-serving -n default` to check the job status執行下列命令,查看驗證推理服務的部署情況。
arena serve get vllm-dist預期輸出如下所示。
Name: vllm-dist Namespace: default Type: Distributed Version: v1 Desired: 1 Available: 1 Age: 3m Address: 192.168.138.65 Port: RESTFUL:8080 GPU: 16 Instances: NAME STATUS AGE READY RESTARTS GPU NODE ---- ------ --- ----- -------- --- ---- vllm-dist-v1-distributed-serving-0 Running 3m 1/1 0 8 cn-beijing.10.x.x.x vllm-dist-v1-distributed-serving-0-1 Running 3m 1/1 0 8 cn-beijing.10.x.x.x
kubectl模型部署樣本
執行以下
DeepSeek_R1.yaml檔案部署模型服務。apiVersion: leaderworkerset.x-k8s.io/v1 kind: LeaderWorkerSet metadata: name: vllm-dist spec: replicas: 1 leaderWorkerTemplate: size: 2 restartPolicy: RecreateGroupOnPodRestart leaderTemplate: metadata: labels: role: leader spec: volumes: - name: model persistentVolumeClaim: claimName: llm-model - name: dshm emptyDir: medium: Memory sizeLimit: 15Gi containers: - name: vllm-leader image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 command: - sh - -c - >- bash /vllm-workspace/examples/online_serving/multi-node-serving.sh leader --ray_cluster_size=$(LWS_GROUP_SIZE); python3 -m vllm.entrypoints.openai.api_server --model /models/DeepSeek-R1 --port 8080 --trust-remote-code --served-model-name deepseek-r1 --gpu-memory-utilization 0.95 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enforce-eager resources: limits: nvidia.com/gpu: "8" requests: nvidia.com/gpu: "8" ports: - containerPort: 8080 readinessProbe: initialDelaySeconds: 30 periodSeconds: 30 tcpSocket: port: 8080 volumeMounts: - mountPath: /models/DeepSeek-R1 name: model - mountPath: /dev/shm name: dshm workerTemplate: spec: volumes: - name: model persistentVolumeClaim: claimName: llm-model - name: dshm emptyDir: medium: Memory sizeLimit: 15Gi containers: - name: vllm-worker image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.10.0 command: - sh - -c - "bash /vllm-workspace/examples/online_serving/multi-node-serving.sh worker --ray_address=$(LWS_LEADER_ADDRESS)" resources: limits: nvidia.com/gpu: "8" requests: nvidia.com/gpu: "8" ports: - containerPort: 8080 volumeMounts: - mountPath: /models/DeepSeek-R1 name: model - mountPath: /dev/shm name: dshm --- apiVersion: v1 kind: Service metadata: name: vllm-dist-v1 spec: type: ClusterIP ports: - port: 8080 protocol: TCP targetPort: 8080 selector: leaderworkerset.sigs.k8s.io/name: vllm-dist role: leaderkubectl create -f DeepSeek_R1.yaml執行下列命令,查看驗證推理服務的部署情況。
kubectl get po |grep vllm-dist預期輸出如下所示。
NAME READY STATUS RESTARTS AGE vllm-dist-0 1/1 Running 0 20m vllm-dist-0-1 1/1 Running 0 20m
建立本地連接埠轉寄發送模型推理請求。
使用
kubectl port-forward在推理服務與本地環境間建立連接埠轉寄。說明請注意
kubectl port-forward建立的連接埠轉寄不具備生產層級的可靠性、安全性和擴充性,因此僅適用於開發和調試目的,不適合在生產環境使用。更多關於Kubernetes叢集內生產可用的網路方案的資訊,請參見Ingress管理。kubectl port-forward svc/vllm-dist-v1 8080:8080發送模型推理請求。
curl http://localhost:8080/v1/completions -H "Content-Type: application/json" -d '{ "model": "deepseek-r1", "prompt": "San Francisco is a", "max_tokens": 10, "temperature": 0.6 }'預期輸出如下所示。
{"id":"cmpl-15977abb0adc44d9aa03628abe9fcc81","object":"text_completion","created":1739346042,"model":"ds","choices":[{"index":0,"text":" city that needs no introduction. Known for its iconic","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":15,"completion_tokens":10,"prompt_tokens_details":null}}
2. 使用Dify構建DeepSeek問答助手
如果您想要通過Container Service for Kubernetes叢集安裝配置Dify平台。具體操作,請參見安裝ack-dify。
2.1. 配置DeepSeek模型
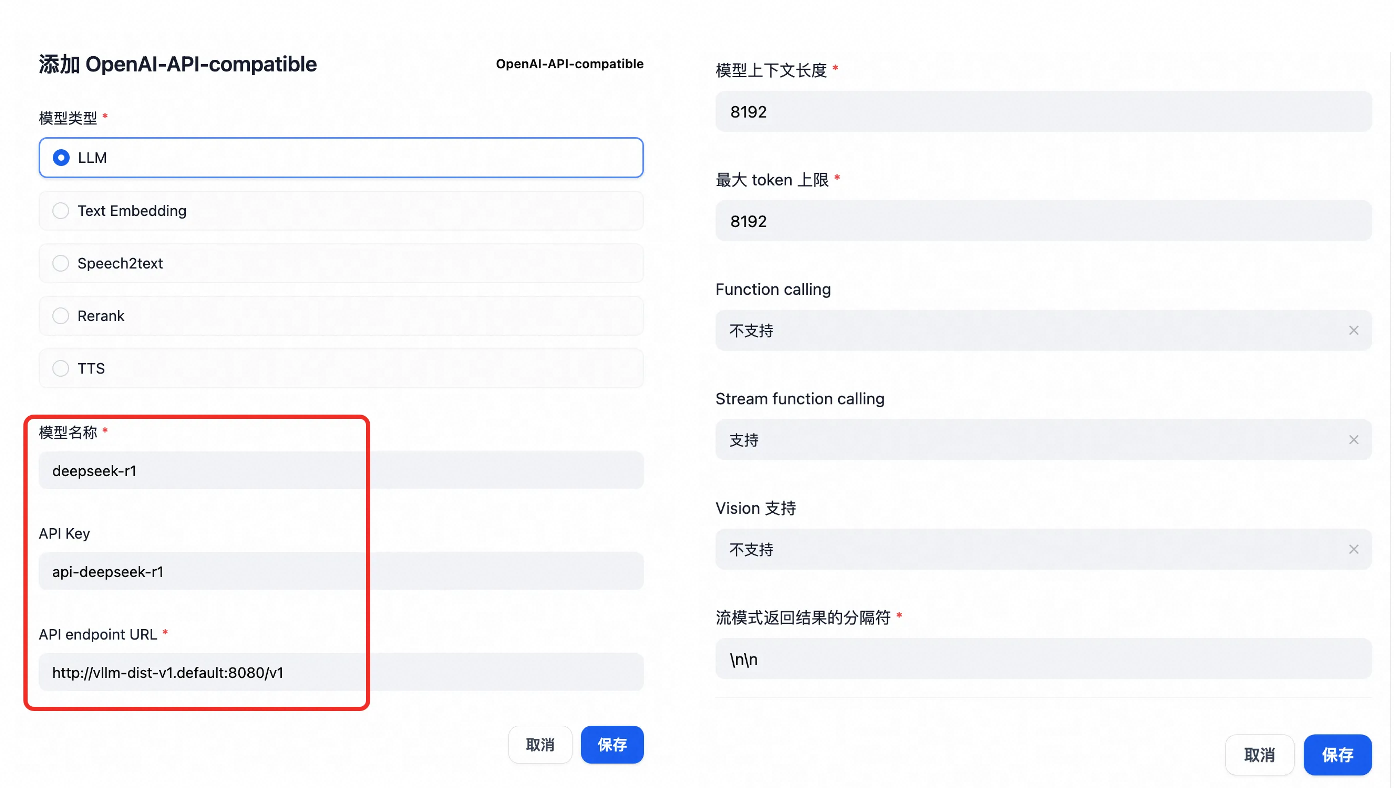
登入Dify應用。登入後點擊頭像,選擇設定。點擊左側模型供應商,在右側找到
OpenAI-API-compatible,點擊添加模型。
模型參數配置如下所示。
參數名稱
設定
備忘
模型名稱
deepseek-r1不可修改。
API Key
如
api-deepseek-r1可自行設定。
API endpoint URL
http://vllm-dist-v1.default:8080/v1不可修改。值為第二步部署的本地DeepSeek服務名稱。
2.2. 建立聊天助手應用
建立一個通用型AI問答助手。依次單擊工作室>建立空白應用,並為AI問答助手輸入名稱和描述,其他參數保持預設即可。

2.3. 驗證AI問答助手
現在您可以在頁面右側與DeepSeek進行對話。

如果您想將配置完成的DeepSeek問答助手整合到您的個人生產環境。具體操作,請參見應用到生產環境。
