cloud-controller-manager組件使得Kubernetes核心組件能夠通過Kubernetes API與雲端服務供應商進行互動。本文介紹cloud-controller-manager組件的指標清單、對應大盤的使用指導以及常見指標異常的問題解析。
使用前須知
操作入口
請參見查看叢集控制面組件監控大盤。
指標清單
指標是組件對外透出狀態和參數的方式之一,cloud-controller-mananger組件使用的指標清單如下。
指標 | 類型 | 說明 |
ccm_slb_latency_ms | Histogram | CLB(Classical Load Balancer)同步時延。單位:ms。 Bucket閾值為 |
ccm_node_latency_ms | Histogram | 節點同步時延。單位:ms。 Bucket閾值為 |
ccm_route_latency_ms | Histogram | 路由同步時延。單位:ms。 Bucket閾值為 |
workqueue_adds_total | Counter | Workqueue處理的新增事件(Adds)數量。 |
workqueue_depth | Gauge | Workqueue當前隊列深度。如果隊列深度長時間保持在較高水平,表明Controller不能及時處理隊列中的任務,導致任務堆積。 |
workqueue_queue_duration_seconds_bucket | Histogram | 任務在Workqueue中存在的時間長度。Bucket閾值為{10-8, 10-7, 10-6, 10-5, 10-4, 10-3, 10-2, 10-1, 1, 10}。單位:秒。 |
memory_utilization_byte | Gauge | 記憶體使用量量。單位:位元組(Byte)。 |
cpu_utilization_core | Gauge | CPU使用量。單位:核(Core)。 |
resource_utilization_level | Gauge | 資源使用水位。
|
rest_client_requests_total | Counter | 從狀態值(Status Code)、方法(Method)和主機(Host)維度分析HTTP請求次數。 |
rest_client_request_duration_seconds_bucket | Histogram | 從方法(Verb)和URL維度分析HTTP請求時延。 |
大盤使用指導
大盤基於組件指標和相關PromQL繪製,大盤可觀測性展示和功能解析如下。
CCM
可觀測性展示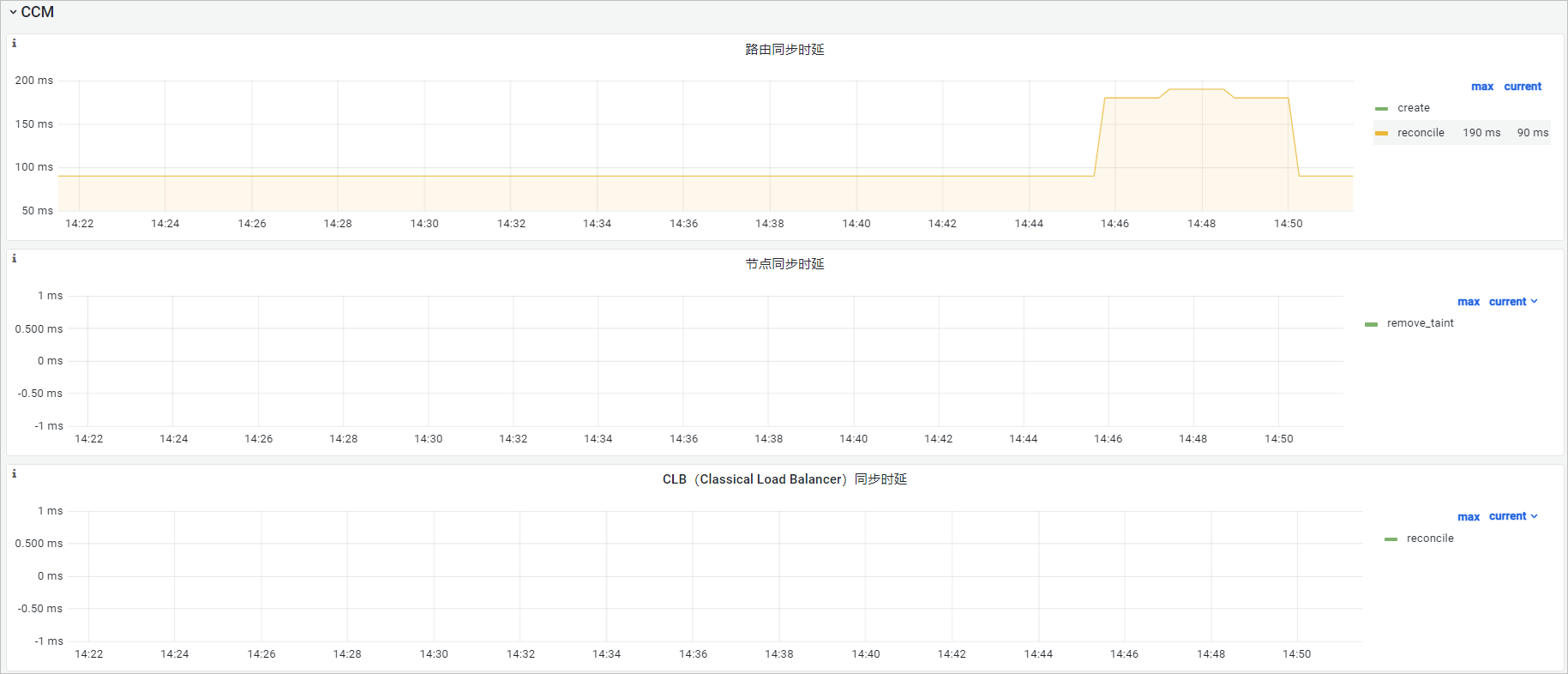
功能解析
大盤名稱 | PromQL | 說明 |
路由同步時延 | histogram_quantile($quantile, sum(rate(ccm_route_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | 路由同步時延。單位:ms。 |
節點同步時延 | histogram_quantile($quantile, sum(rate(ccm_node_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | 節點同步時延。單位:ms。 |
CLB(Classical Load Balancer)同步時延 | histogram_quantile($quantile, sum(rate(ccm_slb_latencies_duration_milliseconds_bucket[$interval])) by (verb, le)) | CLB同步時延。單位:ms。 |
Queue
可觀測性展示
功能解析
大盤名稱 | PromQL | 說明 |
Workqueue入隊速率 | sum(rate(workqueue_adds_total{job="ack-cloud-controller-manager"}[$interval])) by (name) | Workqueue在單位時間內新增事件(Adds)的數量。 |
Workqueue深度 | workqueue_depth{job="ack-cloud-controller-manager"} | Workqueue深度在單位時間內的變化。 |
Workqueue處理時延 | histogram_quantile($quantile, sum(rate(workqueue_queue_duration_seconds_bucket{job="ack-cloud-controller-manager"}[$interval])) by (name, le)) | 事件在Workqueue中存在的時間長度。 |
資源
可觀測性展示
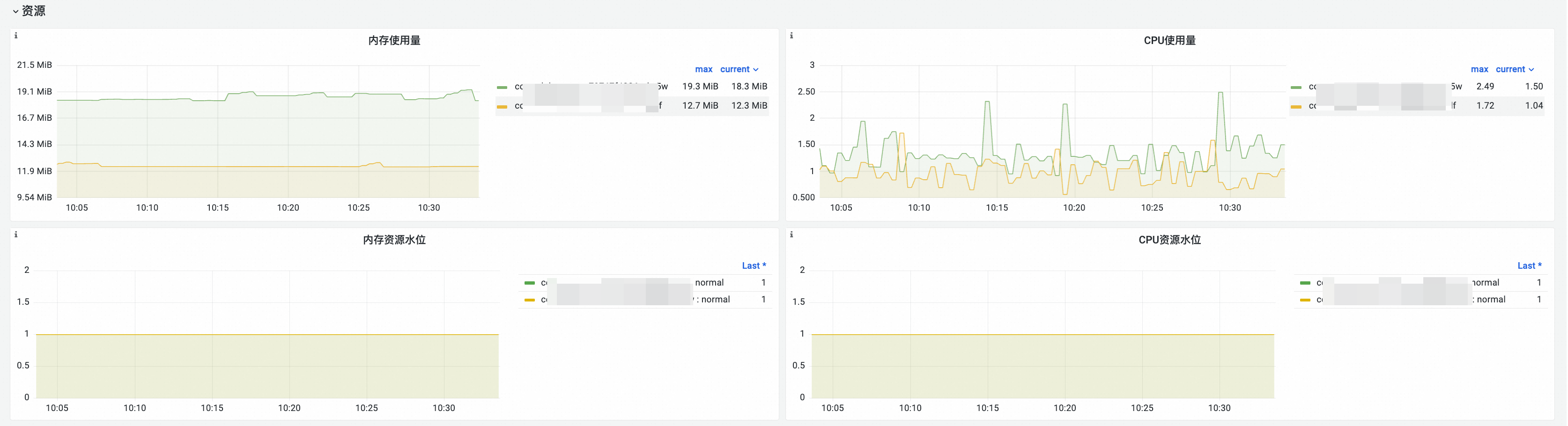
功能解析
大盤名稱 | PromQL | 說明 |
記憶體使用量量 | memory_utilization_byte{container="cloud-controller-manager"} | 記憶體使用量量。單位:位元組。 |
CPU使用量 | cpu_utilization_core{container="cloud-controller-manager"}*1000 | CPU使用量。單位:毫核。 |
記憶體資源水位 |
|
|
CPU資源水位 |
|
Kube API
可觀測性展示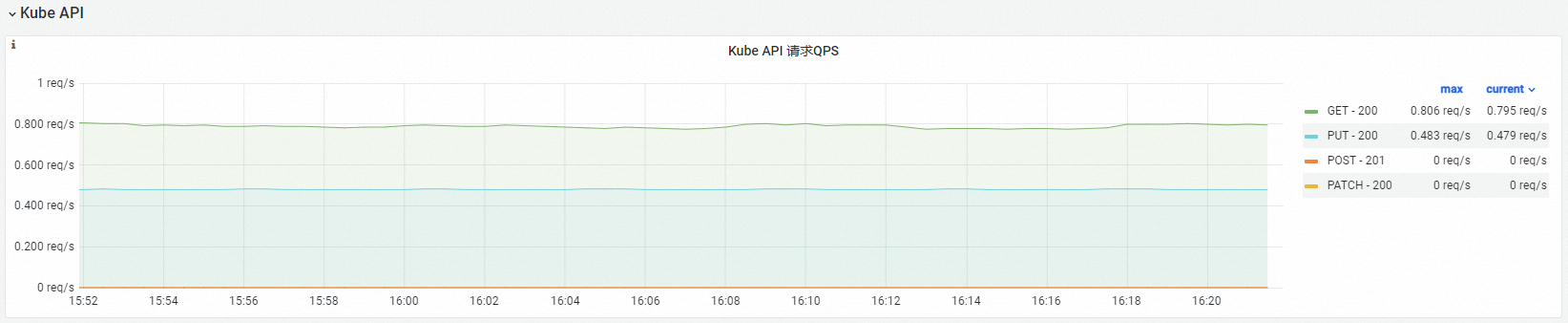
功能解析
大盤名稱 | PromQL | 說明 |
Kube API 請求QPS |
| cloud-controller-manager對kube-apiserver發起的HTTP請求QPS,從方法(Verb)和請求URL維度分析。 |
常見指標異常
CLB(Classical Load Balancer)同步時延
正常情況 | 異常情況 | 異常說明 | 建議 |
CLB(Classical Load Balancer)同步時延在10s內。 | CLB(Classical Load Balancer)同步時延大於10s。 | CLB同步耗費時間過長。 | 查看Service中是否有例外狀況事件。 |
Workqueue深度
正常情況 | 異常情況 | 異常說明 | 建議 |
Workqueue深度在10以內。 | Workqueue深度大於10。 | Workqueue中存在較多待同步的Service。 | 隊列長度過長,會導致Service同步變慢。請適當減少叢集內節點、Pod以及Service的變更頻率。 |
相關文檔
關於其他叢集控制面組件監控的指標詳情、大盤使用指引和常見指標異常說明,請參見kube-apiserver組件監控指標說明、etcd組件監控指標說明、kube-scheduler組件監控指標說明、kube-controller-manager組件監控指標說明。