Argo Workflows廣泛應用於定時任務、機器學習和ETL資料處理等情境,但當對Kubernetes不太熟練時,YAML定義工作流程可能會增加學習難度。Hera Python SDK提供了一種簡潔易用的替代方案,允許以Python代碼構建工作流程,支援複雜任務情境,易於測試,並與Python生態無縫整合。
功能介紹
Argo Workflows主要依賴YAML來定義工作流程,以實現配置的清晰與簡潔。但當資料科學家不熟悉YAML時,在複雜的工作流程設計中,YAML的嚴格縮排要求及層次化的結構可能會增加配置難度。
Hera是一個專為構建和提交Argo工作流程設計的Python SDK架構,旨在簡化工作流程的構建和提交。在處理複雜工作流程時,使用Hera可以有效避免YAML可能產生的語法錯誤。使用Hera PythonSDK還具有以下優勢。
-
代碼簡潔性:Hera提供了易於理解和編寫的代碼,可提升開發效率。
-
Python生態整合簡單:每個Function就是一個Template,與Python生態中的各種架構無縫整合,提供了豐富的Python庫和工具。
-
可測試性:可直接利用Python的測試架構,有助於提高代碼的品質和可維護性。
前提條件
-
已安裝Argo組件和控制台,並擷取訪問憑證和Argo Server 訪問IP。具體操作,請參見啟用批量任務編排能力。
-
已安裝Hera。
pip install hera-workflows
情境一:Simple DAG Diamond
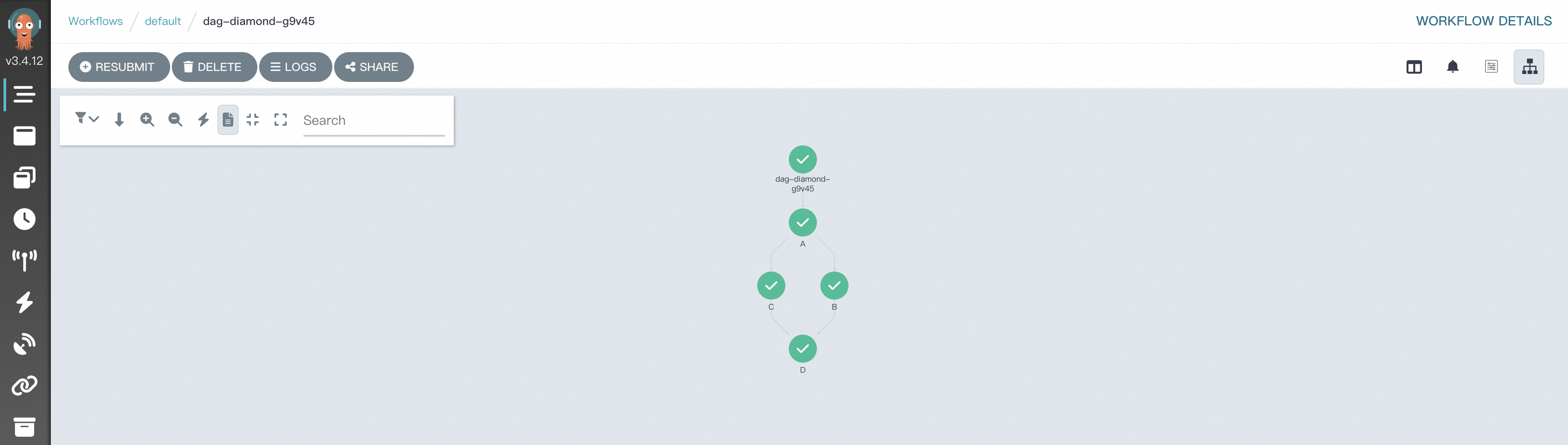
在Argo Workflows中,DAG(有向非循環圖)常用於定義複雜的任務依賴關係,其中Diamond結構是一種常見的工作流程模式,可以實現多個任務並存執行後,並將結果匯聚到一個共同的後續任務。這種結構適用於需要合并不同資料流或處理結果的情境。以下展示如何使用Hera定義一個具有Diamond結構的工作流程,其中兩個任務taskA和taskB並行運行,它們的輸出共同作為輸入傳遞給taskC。
-
使用以下內容,建立simpleDAG.py。
# 匯入相關包。 from hera.workflows import DAG, Workflow, script from hera.shared import global_config import urllib3 urllib3.disable_warnings() # 配置訪問地址和Token。 global_config.host = "https://${IP}:2746" global_config.token = "abcdefgxxxxxx" # 填入之前擷取的Token。 global_config.verify_ssl = "" # 裝飾器函數script是Hera實現近乎原生的Python函數編排的關鍵功能。 # 它允許您在Hera上下文管理器(例如Workflow或Steps上下文)下調用該函數。 # 該函數在任何Hera上下文之外仍將正常運行,這意味著您可以在給定函數上編寫單元測試。 # 該樣本是列印輸入的資訊。 @script() def echo(message: str): print(message) # 構建Workflow,Workflow是Argo中的主要資源,也是Hera的關鍵類,負責儲存模板、設定進入點和運行模板。 with Workflow( generate_name="dag-diamond-", entrypoint="diamond", namespace="argo", ) as w: with DAG(name="diamond"): A = echo(name="A", arguments={"message": "A"}) # 構建Template。 B = echo(name="B", arguments={"message": "B"}) C = echo(name="C", arguments={"message": "C"}) D = echo(name="D", arguments={"message": "D"}) A >> [B, C] >> D # 構建依賴關係,B、C任務依賴A,D依賴B和C。 # 建立Workflow。 w.create() -
執行以下命令, 提交工作流程。
python simpleDAG.py -
工作流程運行後,在工作流程控制台(Argo)查看任務DAG流程與運行結果。
情境二:Map-Reduce
在Argo Workflows中實現MapReduce風格的資料處理時,需要有效利用其DAG模板,以組織和協調多個任務,從而類比Map和Reduce階段。以下展示如何使用Hera構建一個簡單的MapReduce工作流程,用於處理文字檔的單詞計數任務。每一步都是一個Python函數,便於和Python生態進行整合。
-
配置Artifacts,相關操作,請參見配置Artifacts。
-
使用以下內容,建立map-reduce.py。
-
執行以下命令,提交工作流程。
python map-reduce.py -
工作流程運行後,您可以在工作流程控制台(Argo)查看任務DAG流程與運行結果。

相關文檔
-
Hera相關文檔。
-
如果您需要詳細瞭解Hera相關資訊,請參見Hera概述。
-
若您想學習如何設定和使用Hera來進行LLM的訓練過程,請參見Train LLM with Hera。
-
-
YAML部署樣本。
-
如果您想瞭解以YAML的方式部署simple-diamond,請參見dag-diamond.yaml。
-
如果您想瞭解以YAML的方式部署map-reduce,請參見map-reduce.yaml。
-
聯絡我們
若您有任何產品建議或疑問,請加入DingTalk群(DingTalk群號:35688562)聯絡我們。