OSS儲存卷支援多種用戶端,不同用戶端對寫操作的支援程度不同。通常來說,完備的寫操作支援會犧牲部分讀效能。因此,資料的讀寫分離能最大程度避免寫操作對讀效能的影響,顯著提升讀多寫少情境的資料訪問效能。本文介紹在讀多寫少情境下如何通過不同的OSS儲存卷用戶端,或OSS SDK、ossutil工具等方式實現資料的讀寫分離。
前提條件
叢集的儲存群組件為CSI。不同用戶端要求的CSI組件版本不同,請及時升級組件版本。具體操作,請參見管理csi-plugin和csi-provisioner組件。
已建立OSS Bucket,且Bucket與叢集屬於同一阿里雲帳號。
重要不建議跨帳號使用OSS。
使用情境
OSS儲存常見的使用情境包含唯讀和讀寫。對於讀多寫少的情境,建議您將OSS資料的讀寫操作進行分離:
讀:通過選擇不同的OSS儲存卷用戶端,或修改配置參數,以最佳化資料讀取速度。
寫:通過ossfs 1.0用戶端實現完整寫能力,或通過OSS SDK等方式寫入資料。
唯讀
在巨量資料業務的推斷過程、資料分析、資料查詢等情境中使用時,為避免資料被誤刪除和誤修改,建議您將OSS儲存卷的訪問模式配置為ReadOnlyMany。
OSS儲存卷當前支援ossfs 1.0, ossfs 2.0和strmvol三種類型的用戶端,均支援唯讀操作。
建議您升級CSI組件版本至1.33.1及以上,並使用ossfs 2.0替代ossfs 1.0最佳化唯讀情境效能。關於ossfs 2.0儲存卷的使用方式,請參見使用ossfs 2.0儲存卷。
若您的業務為資料集讀取、量化回測、時序日誌分析等需要讀取海量小檔案資料的情境,可選擇使用strmvol儲存卷。關於strmvol儲存卷的使用方式,請參見使用strmvol儲存卷。
更多關於用戶端適用情境和選型建議的資訊,請參見用戶端選型參考。
若您的業務需要在唯讀情境使用ossfs 1.0用戶端,可參考以下參數配置提升資料讀取效能。
參數
說明
kernel_cache
開啟後,通過核心緩衝最佳化讀效能。適用於不需要即時訪問最新內容的情境。
快取命中時,ossfs重複讀取檔案時,將通過核心緩衝區快取處理,僅使用未被其他進程使用的可用記憶體。
parallel_count
以分區模式上傳或下載大檔案時,分區的並發數,預設值為20。
max_multireq
列舉檔案時,訪問檔案元資訊的最大並發數。此處需大於等於parallel_count的值,預設值為20。
max_stat_cache_size
用於指定檔案中繼資料的緩衝空間可緩衝多少個檔案的中繼資料。單位為個,預設值為1000。如需禁止使用中繼資料快取,可設定為0。
在不需要即時訪問最新內容的情境下,當目錄下檔案比較多時,可以根據執行個體規格增加支援的緩衝個數,加快ls的速度。
direct_read
ossfs 1.91及以上版本針對唯讀情境新增直讀模式。
直讀模式的功能介紹與效能測試詳情,請參見ossfs 1.0新版本功能介紹及效能壓測。
直讀模式調優的具體方式,請參考唯讀情境效能調優。
讀寫
在讀寫情境中,您需要將OSS儲存卷的訪問模式配置為ReadWriteMany。
目前ossfs 1.0支援完整的寫操作,ossfs 2.0僅支援順序追加寫。通過ossfs進行寫操作時,注意事項如下:
在並發寫情境中,ossfs無法保證資料寫入的一致性。
掛載狀態下,登入應用Pod或宿主機,在掛載路徑下刪除或變更檔案,都會直接刪除或變更OSS Bucket中對應的源檔案。您可以開啟OSS Bucket的版本控制,避免誤刪除重要資料,請參見版本控制。
在讀多寫少、尤其是讀寫路徑分離的情境中,例如,在巨量資料業務的訓練過程中,建議您將OSS資料的讀寫操作進行分離,即將OSS儲存卷的訪問模式配置為
ReadOnlyMany,然後通過配置緩衝參數最佳化資料讀取速度,並通過SDK等方式寫入資料。具體操作,請參見使用樣本。
使用樣本
本文以手寫Image Recognition訓練應用為例,介紹如何?OSS儲存的讀寫分離。該樣本為一個簡單的深度學習模型訓練,業務通過唯讀OSS儲存卷從OSS Bucket的/data-dir目錄中讀取訓練集,並通過讀寫OSS儲存卷或OSS SDK將checkpoint寫入OSS Bucket的/log-dir目錄。
操作前,請先擷取測試使用的MNIST手寫映像訓練集,並將其上傳到您的OSS Bucket的/tf-train/train/data目錄中,供應用讀取。
MNIST手寫映像訓練集
OSS Bucket隱藏檔樣本
通過ossfs實現讀寫
由於寫checkpoint是順序追加寫行為,因此可以選擇ossfs 1.0或ossfs 2.0實現。
參考以下範本部署手寫Image Recognition訓練應用。
該應用使用簡單的Python編寫,並掛載使用OSS靜態儲存卷。關於OSS儲存卷配置,請參見使用ossfs 1.0靜態儲存卷或使用ossfs 2.0儲存卷。
以下樣本中,應用將OSS Bucket的子路徑
/tf-train掛載至Pod的/mnt目錄。參考以下內容,建立ossfs 1.0儲存卷。
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Secret metadata: name: oss-secret namespace: default stringData: akId: "<your-accesskey-id>" akSecret: "<your-accesskey-secret>" --- apiVersion: v1 kind: PersistentVolume metadata: name: tf-train-pv labels: alicloud-pvname: tf-train-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: tf-train-pv nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" url: "oss-<region>.aliyuncs.com" otherOpts: "-o max_stat_cache_size=0 -o allow_other" path: "/tf-train" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: tf-train-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: tf-train-pv EOF參考以下內容,建立訓練容器。
在訓練過程中,中間檔案將寫入Pod的
/mnt/training_logs目錄中,由ossfs上傳至OSS Bucket的/tf-train/training_logs目錄中。cat << EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: labels: app: tfjob name: tf-mnist namespace: default spec: containers: - command: - sh - -c - python /app/main.py env: - name: NVIDIA_VISIBLE_DEVICES value: void - name: gpus value: "0" - name: workers value: "1" - name: TEST_TMPDIR value: "/mnt" image: registry.cn-beijing.aliyuncs.com/tool-sys/tf-train-demo:rw imagePullPolicy: Always name: tensorflow ports: - containerPort: 20000 name: tfjob-port protocol: TCP volumeMounts: - name: train mountPath: "/mnt" workingDir: /root priority: 0 restartPolicy: Never securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: train persistentVolumeClaim: claimName: tf-train-pvc EOF
驗證資料正常讀寫。
查看Pod的狀態。
kubectl get pod tf-mnist等待Pod狀態從Running轉換至Completed,約需要數分鐘,預期輸出為:
NAME READY STATUS RESTARTS AGE tf-mnist 0/1 Completed 0 2m12s查看Pod作業記錄。
通過Pod作業記錄查詢資料載入所需的時間,該時間包含從OSS下載檔案及TensorFlow載入的時間。
kubectl logs tf-mnist | grep dataload預期輸出如下,實際查詢的時間與執行個體的效能和網路狀態相關。
dataload cost time: 1.54191803932登入OSS管理主控台。查看OSS Bucket的
/tf-train/training_logs目錄中已出現相關檔案,表明資料可以正常從OSS中讀寫。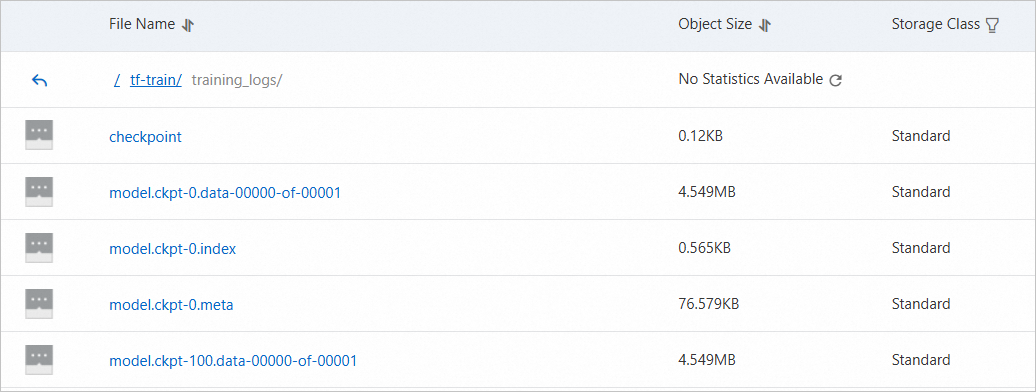
通過讀寫分離最佳化ossfs資料讀取速度
改造應用實現讀寫分離。
讀:參數配置最佳化後的ossfs 1.0隻讀儲存卷實現讀操作
寫:分別以ossfs 1.0讀寫儲存卷以及OSS SDK實現寫操作
使用ossfs 1.0讀寫儲存卷實現寫操作
下文以手寫Image Recognition訓練應用和ossfs 1.0隻讀+讀寫卷為例,介紹如何改造應用實現讀寫分離。
參考以下內容,建立ossfs 1.0隻讀儲存卷。
針對唯讀情境,對ossfs 1.0儲存卷的配置參數進行最佳化。
將PV和PVC的
accessModes均修改為ReadOnlyMany,Bucket的掛載路徑可縮小至/tf-train/train/data。在
otherOpts中通過-o kernel_cache -o max_stat_cache_size=10000 -o umask=022選項,使ossfs在讀取資料時能使用記憶體高速緩衝區加速處理,並增加中繼資料支援的緩衝個數(10000個中繼資料快取大約佔40 M的記憶體,可根據執行個體規格及讀取的資料量多少進行調整),以及通過umask使容器進程以非root使用者運行時也有讀許可權。更多資訊,請參見使用情境。
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Secret metadata: name: oss-secret namespace: default stringData: akId: "<your-accesskey-id>" akSecret: "<your-accesskey-secret>" --- apiVersion: v1 kind: PersistentVolume metadata: name: tf-train-pv labels: alicloud-pvname: tf-train-pv spec: capacity: storage: 10Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: tf-train-pv nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" url: "oss-<region>.aliyuncs.com" otherOpts: "-o kernel_cache -o max_stat_cache_size=10000 -o umask=022 -o allow_other" path: "/tf-train/train/data" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: tf-train-pvc spec: accessModes: - ReadOnlyMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: tf-train-pv EOF參考以下內容,建立ossfs 1.0讀寫儲存卷。
cat << EOF | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: tf-logging-pv labels: alicloud-pvname: tf-logging-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: tf-logging-pv nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" url: "oss-<region>.aliyuncs.com" otherOpts: "-o max_stat_cache_size=0 -o allow_other" path: "/tf-train/training_logs" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: tf-logging-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: tf-logging-pv EOF參考以下內容,建立訓練容器。
說明訓練業務的邏輯無需任何改造,只需要部署時同時掛載唯讀及讀寫儲存卷。
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: labels: app: tfjob name: tf-mnist namespace: default spec: containers: - command: - sh - -c - python /app/main.py env: - name: NVIDIA_VISIBLE_DEVICES value: void - name: gpus value: "0" - name: workers value: "1" - name: TEST_TMPDIR value: "/mnt" image: registry.cn-beijing.aliyuncs.com/tool-sys/tf-train-demo:rw imagePullPolicy: Always name: tensorflow ports: - containerPort: 20000 name: tfjob-port protocol: TCP volumeMounts: - name: train mountPath: "/mnt/train/data" - name: logging mountPath: "/mnt/training_logs" workingDir: /root priority: 0 restartPolicy: Never securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: train persistentVolumeClaim: claimName: tf-train-pvc - name: logging persistentVolumeClaim: claimName: tf-logging-pvc EOF
使用OSS SDK實現寫操作
下文以手寫Image Recognition訓練應用和OSS SDK為例,介紹如何改造應用實現讀寫分離。
在容器環境中安裝SDK,可在構建鏡像時,增加以下內容。具體操作,請參見安裝。
RUN pip install oss2參考OSS的官方文檔Python SDK demo修改原始碼。
以上述手寫Image Recognition訓練應用為例,源鏡像的相關原始碼如下。
def train(): ... saver = tf.train.Saver(max_to_keep=0) for i in range(FLAGS.max_steps): if i % 10 == 0: # Record summaries and test-set accuracy summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False)) print('Accuracy at step %s: %s' % (i, acc)) if i % 100 == 0: print('Save checkpoint at step %s: %s' % (i, acc)) saver.save(sess, FLAGS.log_dir + '/model.ckpt', global_step=i)以上代碼中,每進行100次迭代,會將中間檔案(checkpoint)存入指定的log_dir目錄,即Pod的
/mnt/training_logs目錄。由於Saver的max_to_keep參數為0,將維護所有的中間檔案。如果迭代1000次,則存放10組checkpoint檔案在OSS端。通過修改代碼,實現通過OSS SDK上傳中間檔案,修改要求如下:
配置訪問憑證,從環境變數中讀取AccessKey和Bucket資訊。具體操作,請參見配置訪問憑證。
為減少容器記憶體的使用,可將
max_to_keep設定為1,即總是只儲存最新一組訓練中間檔案。每次儲存中間檔案時,通過put_object_from_file函數上傳至對應Bucket目錄。
說明在讀寫目錄分離的情境中,使用SDK時,還可以通過非同步讀寫進一步提升訓練效率。
import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) url = os.getenv('URL','<default-url>') bucketname = os.getenv('BUCKET','<default-bucket-name>') bucket = oss2.Bucket(auth, url, bucketname) ... def train(): ... saver = tf.train.Saver(max_to_keep=1) for i in range(FLAGS.max_steps): if i % 10 == 0: # Record summaries and test-set accuracy summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False)) print('Accuracy at step %s: %s' % (i, acc)) if i % 100 == 0: print('Save checkpoint at step %s: %s' % (i, acc)) saver.save(sess, FLAGS.log_dir + '/model.ckpt', global_step=i) # FLAGS.log_dir = os.path.join(os.getenv('TEST_TMPDIR', '/mnt'),'training_logs') for path,_,file_list in os.walk(FLAGS.log_dir) : for file_name in file_list: bucket.put_object_from_file(os.path.join('tf-train/training_logs', file_name), os.path.join(path, file_name))修改後的容器鏡像為
registry.cn-beijing.aliyuncs.com/tool-sys/tf-train-demo:ro。修改部分應用模板,使其通過唯讀方式訪問OSS。
將PV和PVC的
accessModes均修改為ReadOnlyMany,Bucket的掛載路徑可縮小至/tf-train/train/data。在
otherOpts中通過-o kernel_cache -o max_stat_cache_size=10000 -o umask=022選項,使ossfs在讀取資料時能使用記憶體高速緩衝區加速處理,並增加中繼資料支援的緩衝個數(10000個中繼資料快取大約佔40M的記憶體,可根據執行個體規格及讀取的資料量多少進行調整),以及通過umask使容器進程以非root使用者運行時也有讀許可權。更多資訊,請參見使用情境。在Pod模板中增加OSS_ACCESS_KEY_ID、OSS_ACCESS_KEY_SECRET環境變數,其值可從oss-secret中擷取,與配置OSS儲存卷中的資訊保持一致。
驗證資料正常讀寫。
查看Pod狀態。
kubectl get pod tf-mnist等待Pod狀態從
Running轉換至Completed,約需要數分鐘,預期輸出為:NAME READY STATUS RESTARTS AGE tf-mnist 0/1 Completed 0 2m25s查看Pod作業記錄。
通過Pod作業記錄查詢資料載入所需的時間,該時間包含從OSS下載檔案及TensorFlow載入的時間。
kubectl logs tf-mnist | grep dataload預期輸出如下,實際查詢的時間與執行個體的效能和網路狀態相關。預期輸出表明,在唯讀模式中合理利用緩衝,可提升資料讀取的速度。在大規模訓練或其他持續載入資料的情境中,最佳化效果更加明顯。
dataload cost time: 0.843528985977登入OSS管理主控台。查看OSS Bucket的
/tf-train/training_logs目錄中已出現相關檔案,表明資料可以正常從OSS中讀寫。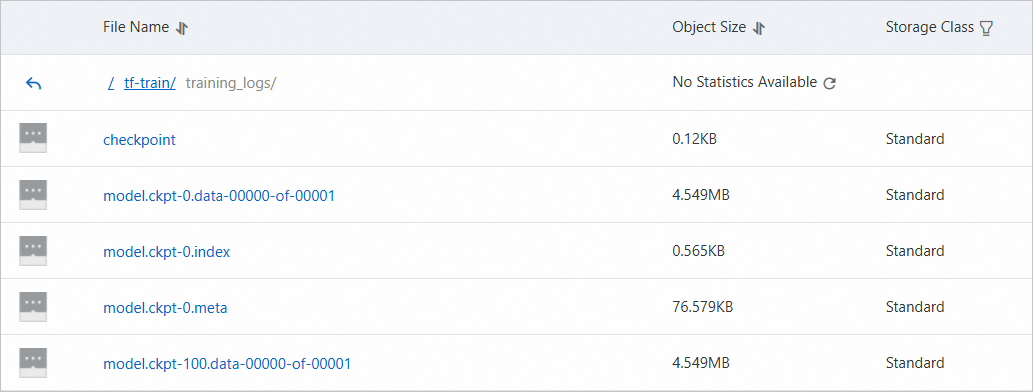
相關參考
OSS SDK參考
阿里雲官方OSS SDK部分參考代碼如下:
更多支援語言PHP、Node.js、Browser.js、.NET、Android、iOS、Ruby,請參見SDK參考。
實現OSS讀寫分離的其他工具
工具 | 相關文檔 |
OpenAPI | |
ossutil命令列工具 | |
ossbrowser圖形化管理工具 |