通過ACK Edge叢集,您可以輕鬆地將分布在不同地區的計算資源納入統一管理,實現雲原生應用的全生命週期管理和高效資源調度。本文將示範如何使用ACK Edge叢集管理分布在多地區的ECS資源。
適用情境
您可以通過一個Kubernetes叢集來統一管理以下情境中的ECS執行個體和應用。
在多個VPC中都有ECS執行個體。
在多個地區中都有ECS執行個體。
在多個帳號中都有ECS執行個體。
管理多個地區分散的應用
在如下情境中,當有大量分散在不同地區的ECS需要統一管理或者部署相同的業務時,您可以建立一個ACK Edge叢集來統一接入不同地區的ECS。具體操作,請參見下文樣本一:使用ACK Edge叢集管理地區分散的應用。
安全防護情境
在分散式運算環境中,為防止系統被惡意攻擊、資料泄露等問題,通常需要在分布式資源上部署網路安全的Agent來為系統提供安全保障,您可以使用ACK Edge叢集完成安全Agent的統一部署和營運。
分布式壓測、撥測情境
在大規模的業務壓測情境中,壓測工具從各個地區同時發起壓測任務。因此,壓測工具需要部署在地區分散的資源中,您可以使用ACK Edge叢集來納管這些資源,快速地向不同地區部署壓測工具。
緩衝加速情境
分布式緩衝加速服務需要在各個地區部署快取服務,以加速網路內容的傳輸速度,您可以使用ACK Edge叢集實現對分布式快取服務的統一部署和營運。
解決單地區GPU資源不足問題
當您在某個地區部署任務時,如果遇到該地區下GPU資源不足的問題,您可以跨地區購買需要的GPU執行個體,然後將對應的GPU執行個體接入ACK Edge叢集中,叢集可以將任務調度到滿足條件的GPU執行個體上。具體操作,請參見下文樣本二:單地區GPU資源不足時,可跨地區購買GPU執行個體擴容。
方案優勢
低成本:提供標準的雲原生介面,採用雲原生的方式營運分布式應用,降低業務營運成本。
免營運:Kubernetes叢集的控制面由阿里雲託管,並提供SLA保障,無需營運Kubernetes叢集。
高可用:與已有的雲產品,包括彈性、網路、儲存、可觀測等能力融合,保障應用的穩定運行。同時提供邊緣自治、雲邊營運通道、單元化管理,支援中心管邊情境下的營運、穩定性以及業務通訊需求。
強相容:支援數十種不同作業系統的異構計算資源接入。
高效能:最佳化了雲邊通訊流量,成功降低了流量成本,單叢集可納管上千節點。
使用樣本
樣本一:使用ACK Edge叢集管理地區分散的應用
準備環境
選擇一個地區作為中心地區,在該地區下建立ACK Edge叢集。
已安裝OpenKruise組件。具體操作,請參見組件管理。
為每個地區分別建立邊緣節點池, 並將ECS執行個體接入到對應的節點池中。
操作步驟
您可以通過原生的DaemonSet或者OpenKruise的DaemonSet兩種方式部署並管理業務。
使用原生的DaemonSet
部署樣本
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在守護進程集頁面,根據需求選擇命名空間及部署方式,輸入應用程式名稱,選擇類型為守護進程集(DaemonSet),根據提示完成部署。
關於部署守護進程集的更多資訊,請參見建立守護進程集工作負載DaemonSet。
業務升級
在守護進程集頁面,單擊目標進程右側操作列下的編輯,通過編輯DaemonSet的模板來實現業務版本及配置的升級。
使用OpenKruise的DaemonSet
部署樣本
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在容器組頁面,單擊使用YAML建立資源,然後選擇樣本模板為自訂,將需要部署的YAML複製粘貼至編輯框後,單擊建立。
業務升級
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在自訂資源頁面,單擊資來源物件瀏覽器,找到對應的DaemonSet,在其右側操作列下,單擊YAML 編輯。通過編輯DaemonSet的模板來實現業務版本及配置的升級。
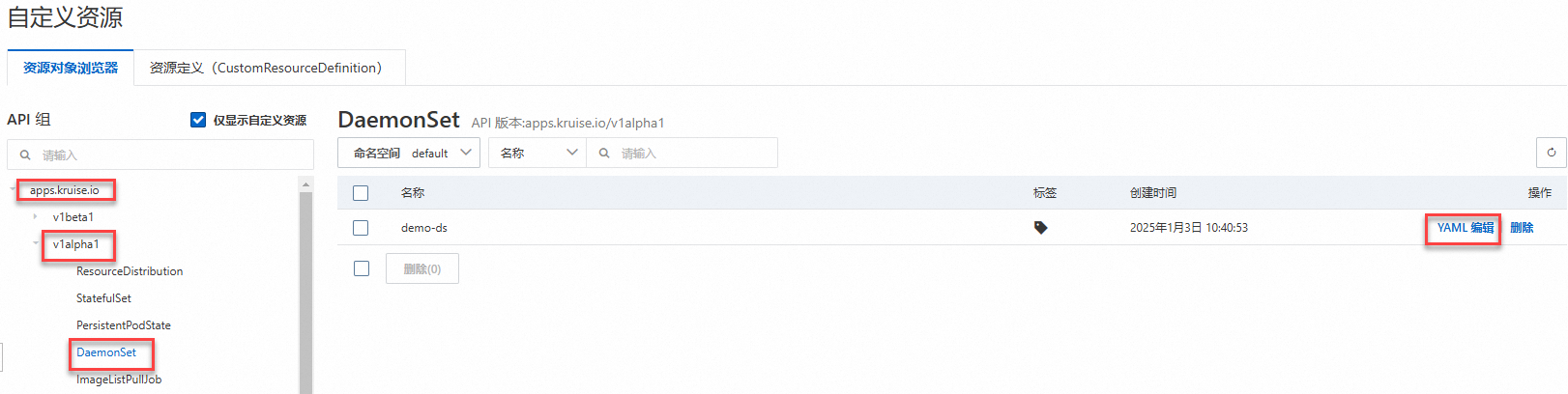
樣本二:單地區GPU資源不足時,可跨地區購買GPU執行個體擴容
準備環境
操作步驟
本樣本以部署推理任務為例,介紹當叢集地區GPU資源不足時,如何通過ACK Edge叢集接入跨地區的GPU執行個體,最終實現任務的調度部署。
部署推理任務並查看任務狀態。
建立tensorflow-mnist.yaml檔案。
部署推理任務。
kubectl apply -f tensorflow-mnist.yaml查看推理任務狀態。
kubectl get pods預期輸出:
NAME READY STATUS RESTARTS AGE tensorflow-mnist-664cf976d8-whrbc 0/1 pending 0 30s當前推理任務狀態為
pending,經確認屬於GPU資源不足問題。
建立邊緣節點池。具體操作,請參見建立邊緣節點池。
將GPU執行個體作為邊緣節點,添加到已建立的邊緣節點池中。具體操作,請參見添加GPU節點。
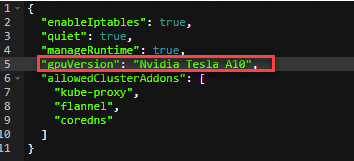
查看邊緣節點狀態。
kubectl get nodes預期輸出:
NAME STATUS ROLES AGE VERSION cn-hangzhou.192.168.XX.XX Ready <none> 9d v1.30.7-aliyun.1 iz2ze21g5pq9jbesubr**** Ready <none> 8d v1.30.7-aliyun.1 izf8z0dko1ivt5kwgl4**** Ready <none> 8d v1.30.7-aliyun.1 izuf65ze9db2kfcethw**** Ready <none> 8d v1.30.7-aliyun.1 # 新添加的GPU邊緣節點。查看推理任務的狀態。
kubectl get pods -owide預期輸出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tensorflow-mnist-664cf976d8-whrbc 1/1 running 0 23m 10.12.XX.XX izuf65ze9db2kfcethw**** <none> <none>預期輸出表明,推理任務已調度到新添加的GPU節點上,並部署成功。