為解決混合雲情境下部署LLM推理業務時,流量的不均衡帶來的資料中心GPU資源分派問題,ACK Edge叢集提供了一套混合雲LLM彈性推理解決方案,幫您統一管理雲上和雲下的GPU資源,低峰期優先使用雲下資料中心資源,高峰期資源不足時快速啟用雲上資源。該方案幫您顯著降低LLM推理服務營運成本,動態調整並靈活利用資源,保障服務穩定性,避免資源閑置。
方案介紹
整體架構
該方案採用ACK Edge叢集的雲邊一體化管理能力,統一納管雲上雲下計算資源,實現計算任務的動態分配。您可以在叢集中通過KServe來配置彈性策略,快速部署一套LLM彈性推理服務。
在業務低峰期時,您可以在叢集中通過自訂資源優先順序調度(ResourcePolicy)來自訂資源調度優先順序,優先使用線下資源進行推理。
在業務高峰期時,通過ACK Edge叢集的監控能力,KServe即時監測GPU使用方式和工作負載,動態擴容推理服務的副本數。當線下GPU資源不足時,系統通過預先配置的彈性節點池迅速啟用雲上GPU資源,保障服務連續性和穩定性。
推理請求:大量使用者請求觸發推理服務擴容。
資源調度:優先調度到雲下IDC資源集區。
雲上擴容:當雲下IDC資源不足時,調度至雲上預先配置的彈性節點池啟用雲上資源。
關鍵技術
該方案涉及到的關鍵技術有ACK Edge叢集、KServe、彈性節點池(節點自動調整)、ResourcePolicy(自訂彈性資源優先順序調度)。
使用樣本
準備環境。
準備工作完成後,將叢集中的資源按照節點池劃分為三類:
類別
節點池類型
作用
樣本
雲上管控資源集區
雲端
用於部署ACK Edge叢集,KServe等管控組件的雲上節點池。
default-nodepool
IDC資源集區
邊緣/專用型
線下資料中心資源,用於承載LLM推理服務。
GPU-V100-Edge
雲上彈性資源集區
雲端
根據叢集GPU資源使用方式靈活擴容,用於在高峰期承載LLM推理服務。
GPU-V100-Elastic
準備AI模型。
您可以使用OSS或NAS準備模型資料。具體操作,請參見準備模型資料並上傳OSS Bucket。
定義調度優先順序。
通過建立ResourcePolicy CRD來定義彈性資源優先順序調度規則。本樣本中,labelSelector匹配了
app: isvc.qwen-predictor的應用來定義規則,此規則明確應用應該優先調度到IDC資源集區,然後再調度到雲上彈性資源集區。更多ResourcePolicy使用說明,請參見自訂彈性資源優先順序調度。重要後續建立應用Pod時,需要為其添加與以下labelSelector一致的Label,用於關聯此處定義的調度策略。
apiVersion: scheduling.alibabacloud.com/v1alpha1 kind: ResourcePolicy metadata: name: qwen-chat namespace: default spec: selector: app: isvc.qwen-predictor # 此處要與後續建立的應用Pod的label相關聯。 strategy: prefer units: - resource: ecs nodeSelector: alibabacloud.com/nodepool-id: npxxxxxx # IDC資源集區,替換為您的IDC資源集區ID。 - resource: elastic nodeSelector: alibabacloud.com/nodepool-id: npxxxxxy # 雲上彈性資源集區。替換為您的雲上彈性資源集區ID。部署LLM推理服務。
在Arena用戶端執行以下命令,啟動一個基於KServe部署的彈性LLM推理服務。
arena serve kserve \ --name=qwen-chat \ --image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:0.4.1 \ --scale-metric=DCGM_CUSTOM_PROCESS_SM_UTIL \ --scale-target=50 \ --min-replicas=1 \ --max-replicas=3 \ --gpus=1 \ --cpu=4 \ --memory=12Gi \ --data="llm-model:/mnt/models/Qwen" \ "python3 -m vllm.entrypoints.openai.api_server --port 8080 --trust-remote-code --served-model-name qwen --model /mnt/models/Qwen --gpu-memory-utilization 0.95 --quantization gptq --max-model-len=6144"參數
是否必選
說明
樣本值
--name是
提交的推理服務名稱,全域唯一。
qwen-chat
--image是
推理服務的鏡像地址。本樣本使用vllm推理架構。
kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:0.4.1
--scale-metric否
應用Auto Scaling標準。本樣本使用GPU卡利用率
DCGM_CUSTOM_PROCESS_SM_UTIL這個指標進行應用伸縮。更多指標,請參見配置HPA。DCGM_CUSTOM_PROCESS_SM_UTIL
--scale-target否
應用伸縮目標。當GPU利用率超過50%時,開始擴容副本。
50
--min-replicas否
最小副本數。
1
--max-replicas否
最大副本數。
3
--gpus否
推理服務需要使用的GPU卡數。預設值為0。
1
--cpu否
推理服務需要使用的CPU數量。
4
--memory否
推理服務需要使用的記憶體數量。
12Gi
--data否
服務的模型地址,本樣本指定的模型儲存在llm-model中,掛載到容器的/mnt/models/目錄下。
"llm-model:/mnt/models/Qwen" \
"python3 -m vllm.entrypoints.openai.api_server --port 8080 --trust-remote-code --served-model-name qwen --model /mnt/models/Qwen --gpu-memory-utilization 0.95 --quantization gptq --max-model-len=6144"
驗證封裝含Auto Scaling的LLM推理服務是否部署成功。
curl -H "Host: qwen-chat-default.example.com" \ # 該地址從KServe自動建立的Ingress資源詳情中擷取。 -H "Content-Type: application/json" \ http://xx.xx.xx.xx:80/v1/chat/completions \ -X POST \ -d '{"model": "qwen", "messages": [{"role": "user", "content": "你好"}], "max_tokens": 512, "temperature": 0.7, "top_p": 0.9, "seed": 10, "stop":["<|endoftext|>", "<|im_end|>", "<|im_start|>"]}'通過壓測工具Hey發送大量的請求到已部署的LLM推理服務中,類比業務流量高峰時觸發雲上資源擴容。
hey -z 2m -c 5 \ -m POST -host qwen-chat-default.example.com \ -H "Content-Type: application/json" \ -d '{"model": "qwen", "messages": [{"role": "user", "content": "測試一下"}], "max_tokens": 10, "temperature": 0.7, "top_p": 0.9, "seed": 10}' \ http://xx.xx.xx.xx:80/v1/chat/completions以上請求會發送到現有的Pod,但由於請求太多,當GPU利用率上升超過閾值50%時,將會觸發之前定義的應用HPA規則,開始擴容Pod副本數,如下圖中出現了3個Pod副本。

由於樣本的測試環境中IDC只有1張GPU卡,擴容出的2個Pod找不到可用的資源,處於
pending狀態。此時,pending狀態的Pod自動觸發了雲上彈性節點池節點伸縮,cluster-autoscaler會自動彈出2個雲上GPU節點來承載這2個Pod。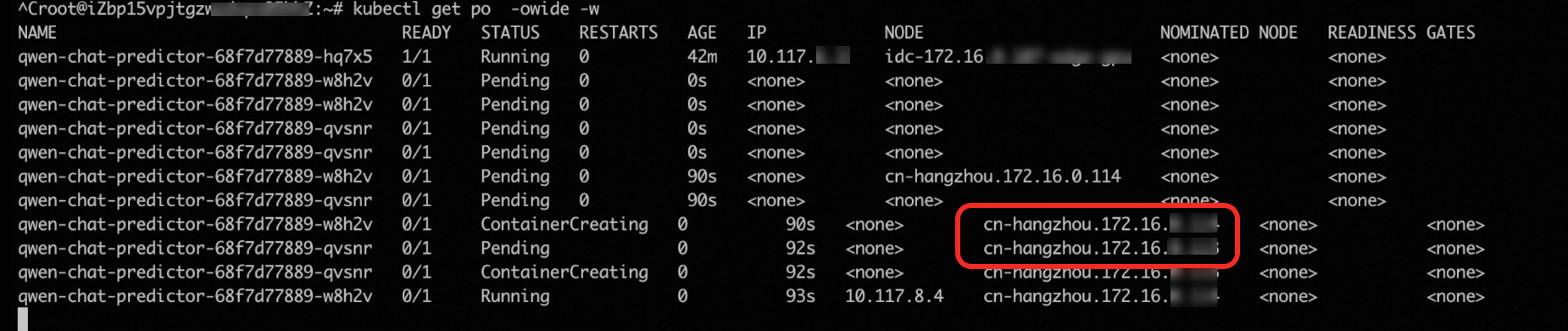
相關文檔
更多推理任務部署,請參見AI服務部署。
更多ACK Edge叢集雲上彈性介紹,請參見雲上彈性。
如需加速邊緣節點訪問OSS檔案,請參見使用Fluid加速邊緣節點訪問OSS檔案。