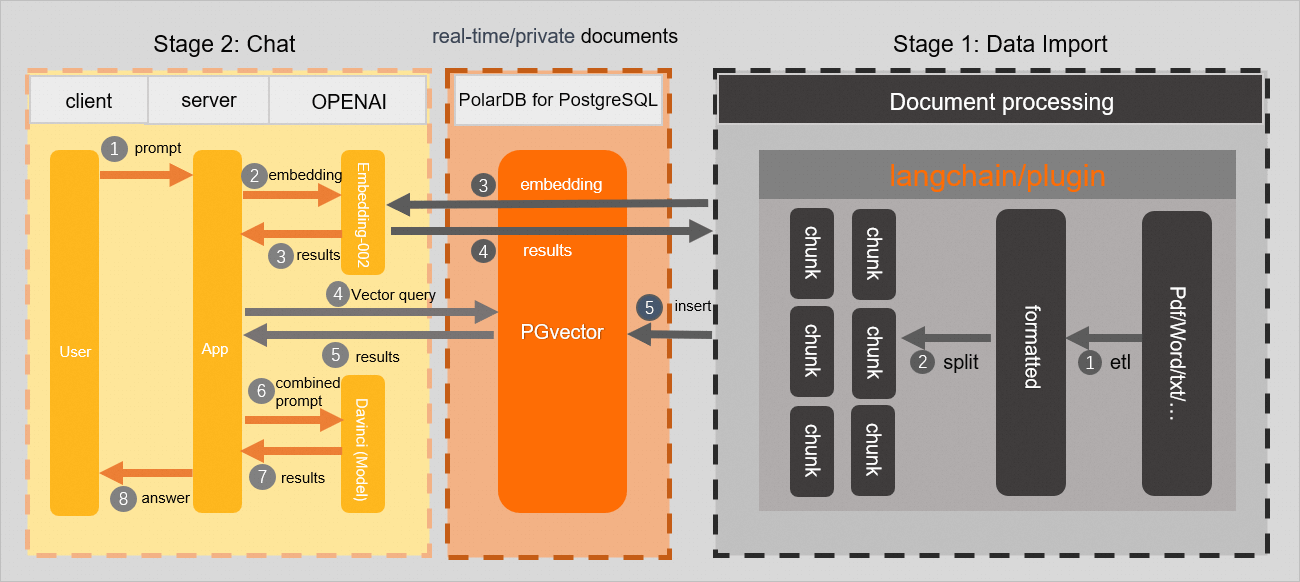
This tutorial walks you through building a domain-specific chatbot that answers questions based on a private knowledge base. The chatbot uses PolarDB for PostgreSQL as the vector database, the pgvector extension for similarity search, and OpenAI as the large language model (LLM) provider.
The LLMs used in this tutorial are third-party models. Alibaba Cloud does not guarantee the compliance or accuracy of third-party models and disclaims all liability related to their use. Evaluate the risks before accessing or using third-party models, and read and comply with all applicable open source licenses and agreements.
How it works
This chatbot uses retrieval-augmented generation (RAG): instead of relying solely on the LLM's training data, it retrieves relevant passages from a private knowledge base at query time and injects them into the prompt.
The workflow has two phases:
Phase 1: Data preparation
-
Extract text from a domain-specific knowledge base and split it into chunks.
-
Call the OpenAI Embeddings API to generate a text embedding for each chunk.
-
Store the embeddings, text chunks, and metadata in your PolarDB for PostgreSQL cluster.
Phase 2: Q&A
-
Receive a user question.
-
Call the OpenAI Embeddings API to generate an embedding for the question.
-
Use the pgvector extension to find text chunks in the PolarDB cluster whose cosine similarity to the question embedding exceeds a threshold.
-
Inject the matched chunks into a prompt and call the OpenAI Completions API to generate the answer.
Background
LLMs excel at general-purpose tasks, but they struggle with domain-specific or time-sensitive knowledge that falls outside their training data. Two common approaches address this limitation:
-
Fine-tuning: Adjust model weights on a new dataset. Effective for task-specific models but costly, resource-intensive, and slow to update.
-
Prompt-tuning: Keep model weights fixed and retrieve relevant information at query time to include in the prompt. Lower compute cost, faster to update, and better suited for knowledge bases that change frequently.
For most enterprise use cases — where knowledge bases are updated regularly and data is proprietary — prompt-tuning (also called retrieval-augmented generation) is the practical choice.
PolarDB for PostgreSQL supports the pgvector extension, which adds vector storage and similarity search to PostgreSQL. This lets you use PolarDB as the retrieval backend in a RAG pipeline without introducing a separate vector database.
pgvector supports:
-
Exact and approximate nearest neighbor search
-
Cosine similarity, L2 distance, and inner product
-
IVFFlat indexes for scalable approximate search
-
Using the PGVector (AISearch) extension of , you can convert real-time content or specialized knowledge from vertical domains into vector embeddings. You can store these embeddings in to perform efficient vector retrieval. This improves the accuracy of answers for private content.
-
The PGVector (AISearch) extension is now widely used in the developer community and in open source databases based on PostgreSQL. Tools such as the ChatGPT Retrieval Plugin have also been adapted for PostgreSQL. This demonstrates that has strong ecosystem support and a broad user base in the field of vector retrieval. This provides users with a rich set of tools and resources.
Prerequisites
Before you begin, ensure that you have:
-
A PolarDB for PostgreSQL cluster running PostgreSQL 14 (revision version 14.7.9.0 or later). For upgrade instructions, see Version management
-
The chatbot in this topic is built on PGVector, an open source plugin for . Ensure that you understand its usage and basic concepts.
-
Basic familiarity with the pgvector extension and its terminology
-
An OpenAI API key (
Secret API key) and a network environment with access to OpenAI. The sample code in this tutorial runs on an Elastic Compute Service (ECS) instance in the Singapore region -
Python 3.11.4 and PyCharm 2023.1.2 (or another Python IDE)
Key concepts
Embedding
An embedding is a numerical representation of text as a fixed-length vector of floating-point numbers. Semantically similar texts produce vectors that are close together in the embedding space, which makes them useful for similarity search.
OpenAI's text-embedding-ada-002 model produces 1,536-dimensional embeddings.
Phase 1: Set up the database and load the knowledge base
In this example, the knowledge base is the 2023 PolarDB for PostgreSQL release notes. Replace it with your own domain-specific data.
Set up the database
-
Create a test database.
CREATE DATABASE testdb; -
Connect to
testdband enable the pgvector extension.CREATE EXTENSION IF NOT EXISTS vector; -
Create a table to store the knowledge base chunks and their embeddings.
Column Type Description idbigserialAuto-incrementing primary key titletextDocument title descriptiontextShort description of the source document doc_chunktextA single text chunk from the knowledge base token_sizeintNumber of tokens in the chunk embeddingvector(1536)Text embedding from text-embedding-ada-002, which outputs 1,536-dimensional vectorsCREATE TABLE polardb_pg_help_docs ( id bigserial PRIMARY KEY, title text, description text, doc_chunk text, token_size int, embedding vector(1536) ); -
Create an IVFFlat index on the
embeddingcolumn to speed up similarity searches.CREATE INDEX ON polardb_pg_help_docs USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
Install dependencies
Open the terminal in PyCharm and run:
pip install openai psycopg2 tiktoken requests beautifulsoup4 numpyIf the psycopg2 installation fails, install it from source.
Split and store the knowledge base
Create knowledge_chunk_storage.py with the following code. This script fetches a web page, splits the HTML content into fixed-size chunks, generates an embedding for each chunk, and stores everything in the polardb_pg_help_docs table.
The splitting function below divides text into fixed-character chunks. For production use, consider the text splitters in LangChain or ChatGPT Retrieval Plugin, which offer more sophisticated chunking strategies. Chunk quality directly affects answer quality.
import openai
import psycopg2
import tiktoken
import requests
from bs4 import BeautifulSoup
EMBEDDING_MODEL = "text-embedding-ada-002"
tokenizer = tiktoken.get_encoding("cl100k_base")
# Connect to PolarDB for PostgreSQL
conn = psycopg2.connect(
database="<database-name>",
host="<cluster-endpoint>",
user="<username>",
password="<password>",
port="<port>"
)
conn.autocommit = True
# OpenAI API key
openai.api_key = "<secret-api-key>"
def get_text_chunks(text, max_chunk_size):
"""Split HTML content into fixed-size character chunks."""
chunks_ = []
soup_ = BeautifulSoup(text, "html.parser")
content = "".join(soup_.strings).strip()
length = len(content)
start = 0
while start < length:
end = min(start + max_chunk_size, length)
chunks_.append(content[start:end])
start = end
return chunks_
# Fetch the knowledge base page
url = "https://www.alibabacloud.com/help/document_detail/602217.html?spm=a2c4g.468881.0.0.5a2c72c2cnmjaL"
response = requests.get(url)
if response.status_code == 200:
web_html_data = response.text
soup = BeautifulSoup(web_html_data, "html.parser")
title = soup.find("h1").text.strip()
description = soup.find("p", class_="shortdesc").text.strip()
chunks = get_text_chunks(web_html_data, 500)
for chunk in chunks:
# Generate embedding for the chunk
embedding_response = openai.Embedding.create(
model=EMBEDDING_MODEL,
input=chunk,
)
embedding = embedding_response["data"][0]["embedding"]
token_size = len(tokenizer.encode(chunk))
cur = conn.cursor()
cur.execute(
"""
INSERT INTO polardb_pg_help_docs
(title, description, doc_chunk, token_size, embedding)
VALUES (%s, %s, %s, %s, %s)
""",
(title, description, chunk, token_size, embedding),
)
conn.commit()
else:
print("Failed to fetch the web page")Replace the following placeholders before running:
| Placeholder | Description | Example |
|---|---|---|
<database-name> |
Name of the target database | testdb |
<cluster-endpoint> |
PolarDB cluster endpoint | pc-xxx.polardb.singapore.rds.aliyuncs.com |
<username> |
Database username | polardbuser |
<password> |
Database password | — |
<port> |
Database port | 5432 |
<secret-api-key> |
OpenAI API key | — |
Run the script from PyCharm. After it completes, verify that the data was stored by connecting to the database and running:
SELECT * FROM polardb_pg_help_docs;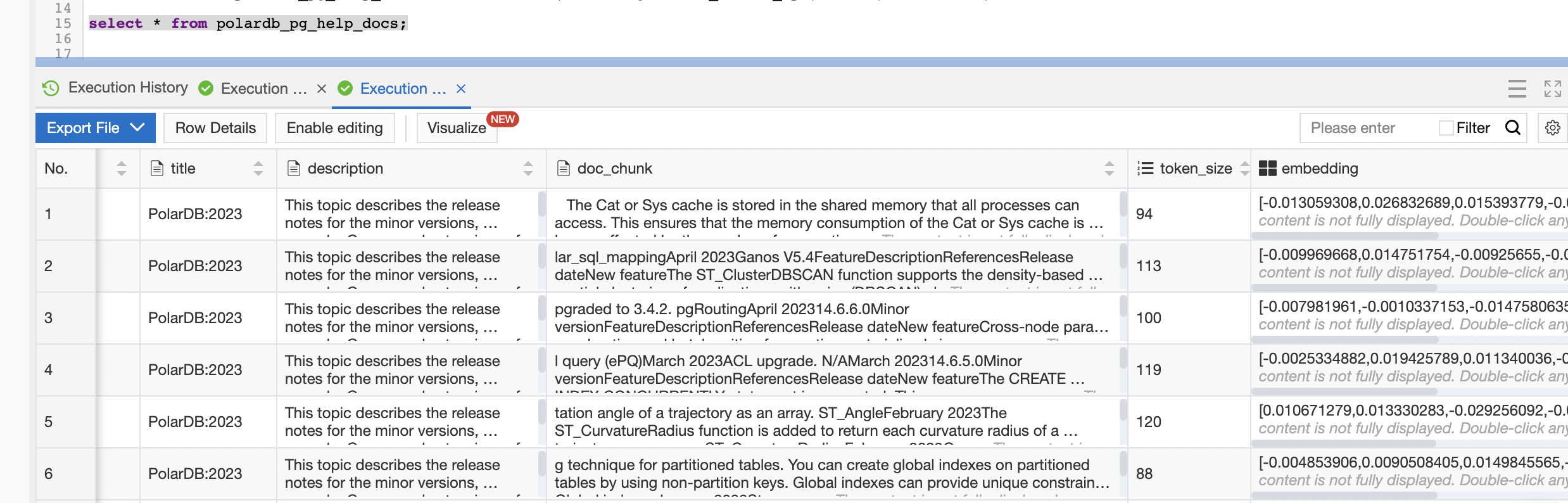
Phase 2: Build the Q&A chatbot
Create chatbot.py with the following code. This script accepts a question, retrieves the most relevant chunks from the database using cosine similarity, and calls the OpenAI Completions API to generate a grounded answer.
import openai
import psycopg2
from psycopg2.extras import DictCursor
EMBEDDING_MODEL = "text-embedding-ada-002"
GPT_COMPLETIONS_MODEL = "<gpt-completions-model>"
MAX_TOKENS = <max-tokens>
# Connect to PolarDB for PostgreSQL
conn = psycopg2.connect(
database="<database-name>",
host="<cluster-endpoint>",
user="<username>",
password="<password>",
port="<port>"
)
conn.autocommit = True
openai.api_key = "<secret-api-key>"
# Similarity search parameters
SIMILARITY_THRESHOLD = 0.78 # Only include chunks above this cosine similarity score
MAX_MATCHED_DOCS = 8 # Maximum number of chunks to retrieve
TOKEN_BUDGET = 1000 # Maximum tokens per LLM call
def answer(prompt_doc, prompt):
"""Call the LLM with retrieved context and the user question."""
improved_prompt = f"""
Answer the following question based on the file below:
a. Check whether the content in the file is related to the question.
b. Use the file content to answer the question and provide a detailed answer in Markdown format.
c. If the question is unrelated to PolarDB for PostgreSQL, respond with "I don't know because the question is beyond my scope."
File:
\"\"\"
{prompt_doc}
\"\"\"
Question: {prompt}
"""
response = openai.Completion.create(
model=GPT_COMPLETIONS_MODEL,
prompt=improved_prompt,
temperature=0.2,
max_tokens=MAX_TOKENS,
)
print(f"{response['choices'][0]['text']}\n")
# --- Main Q&A flow ---
# User question
prompt = "What are the new features in the 2023 PolarDB for PostgreSQL 14 release notes?"
# Generate embedding for the question
prompt_embedding_response = openai.Embedding.create(
model=EMBEDDING_MODEL,
input=prompt,
)
prompt_embedding = prompt_embedding_response["data"][0]["embedding"]
# Retrieve the most similar chunks from the database
similarity_search_sql = f"""
SELECT doc_chunk, token_size,
1 - (embedding <=> '{prompt_embedding}') AS similarity
FROM polardb_pg_help_docs
WHERE 1 - (embedding <=> '{prompt_embedding}') > {SIMILARITY_THRESHOLD}
ORDER BY id
LIMIT {MAX_MATCHED_DOCS};
"""
cur = conn.cursor(cursor_factory=DictCursor)
cur.execute(similarity_search_sql)
matched_docs = cur.fetchall()
# Batch the matched chunks into LLM calls within the token budget
total_tokens = 0
prompt_doc = ""
print("Answer:\n")
for matched_doc in matched_docs:
if total_tokens + matched_doc["token_size"] <= TOKEN_BUDGET:
prompt_doc += f"\n---\n{matched_doc['doc_chunk']}"
total_tokens += matched_doc["token_size"]
continue
answer(prompt_doc, prompt)
total_tokens = 0
prompt_doc = ""
answer(prompt_doc, prompt)Replace<gpt-completions-model>with your chosen OpenAI completions model (for example,gpt-3.5-turbo-instruct) and<max-tokens>with the maximum number of tokens for the response. Use the same placeholder table from Phase 1 when filling in the connection details.
How the prompt is structured
Each call to answer() sends a prompt with three parts:
| Part | Variable | Purpose |
|---|---|---|
| Role instructions | (hardcoded) | Tells the LLM to answer only from the provided context and to fall back to "I don't know" for out-of-scope questions |
| Context | {prompt_doc} |
Retrieved knowledge base chunks, concatenated up to the token budget |
| Question | {prompt} |
The user's question |
This structure grounds the LLM's response in your private knowledge base rather than its general training data.
Run chatbot.py. A sample result looks like this:
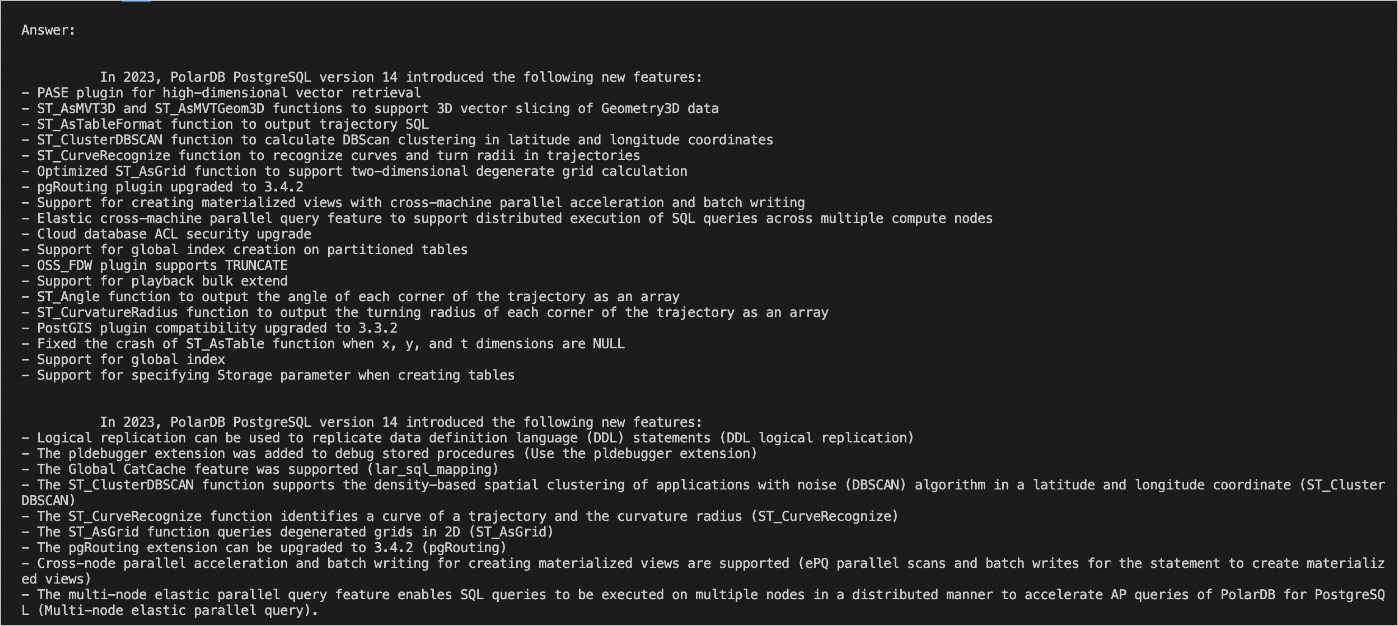
To improve answer quality, tune the chunk splitting strategy and the prompt instructions. Smaller, semantically coherent chunks typically produce better results than fixed-size character splits.
Results
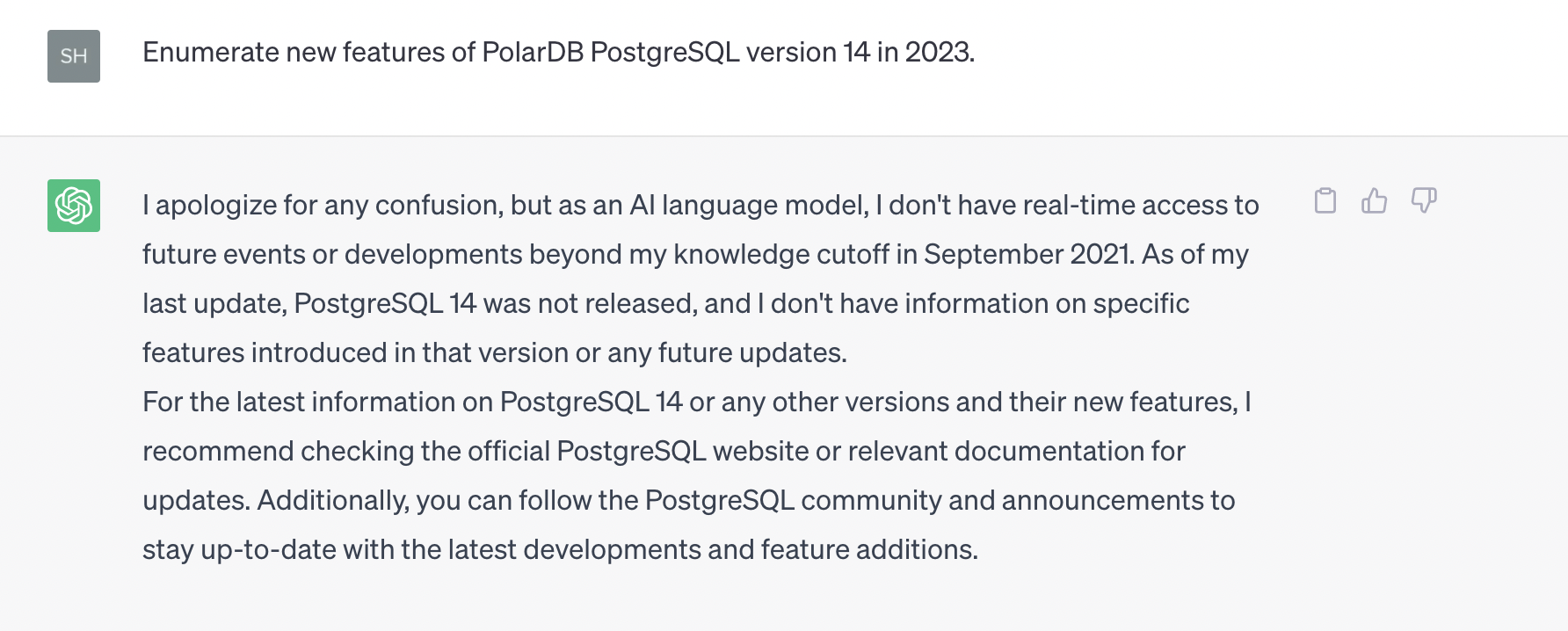
Without the vector database, OpenAI answers the question "What are the new features in 2023 of PolarDB for PostgreSQL 14 release notes?" with generic information unrelated to Alibaba Cloud:
After connecting the PolarDB vector database, the same question returns answers grounded in PolarDB for PostgreSQL release notes:

What's next
-
Explore LangChain and ChatGPT Retrieval Plugin for production-grade document loading, chunking, and retrieval pipelines that integrate directly with PolarDB for PostgreSQL.
-
See the OpenAI cookbook example for PolarDB for additional implementation patterns.
-
For multi-user deployments, consider restricting vector similarity search results by user with row-level security (RLS) policies on the
polardb_pg_help_docstable. This ensures that each user can only retrieve chunks from documents they have access to.
Related videos
AI Chatbots: From Limitations to Possibilities | Practical Guide to Enhance AI Chatbot Capabilities