DashVector は、E コマースの検索とレコメンデーション、 NLP ベースの Q&A、マルチモーダル画像検索、動画検索、分子検出とスクリーニングをサポートしています。
E コマースの検索とレコメンデーション
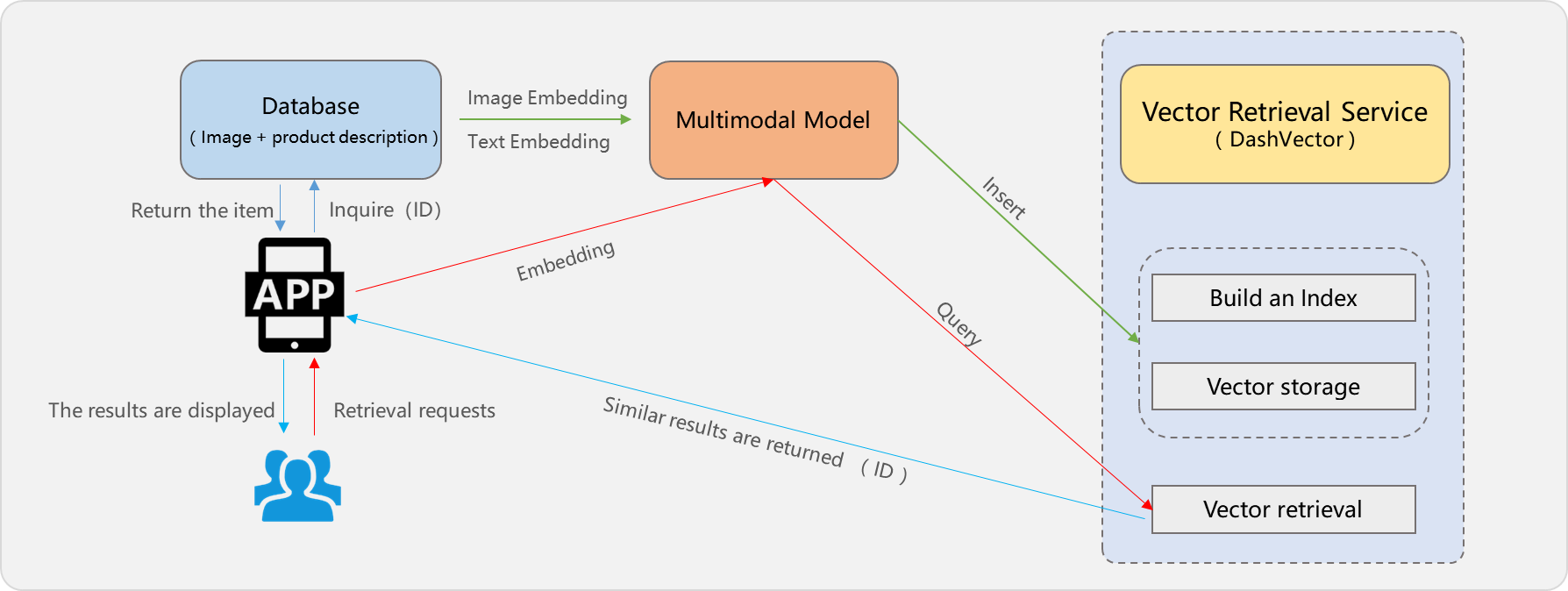
ベクトルデータベースは、E コマースにおける類似性に基づいた商品検索とレコメンデーションを可能にします。E コマースプラットフォームには、商品の画像と説明が保存されています。ユーザーは画像やテキストで検索し、パーソナライズされた商品レコメンデーションを受け取ることができます。
埋め込みモデルを使用して、商品の画像と説明をベクトルに変換し、ベクトルデータベースに保存します。ユーザーがクエリを実行すると、DashVector はクエリをベクトルに変換し、最も類似した商品を返します。ユーザーの行動や好みに基づき、DashVector は閲覧履歴や購入履歴をベクトルに変換して類似商品を検索・推奨し、パーソナライズされたショッピング体験を提供します。
NLP ベースの AI Q&A システム
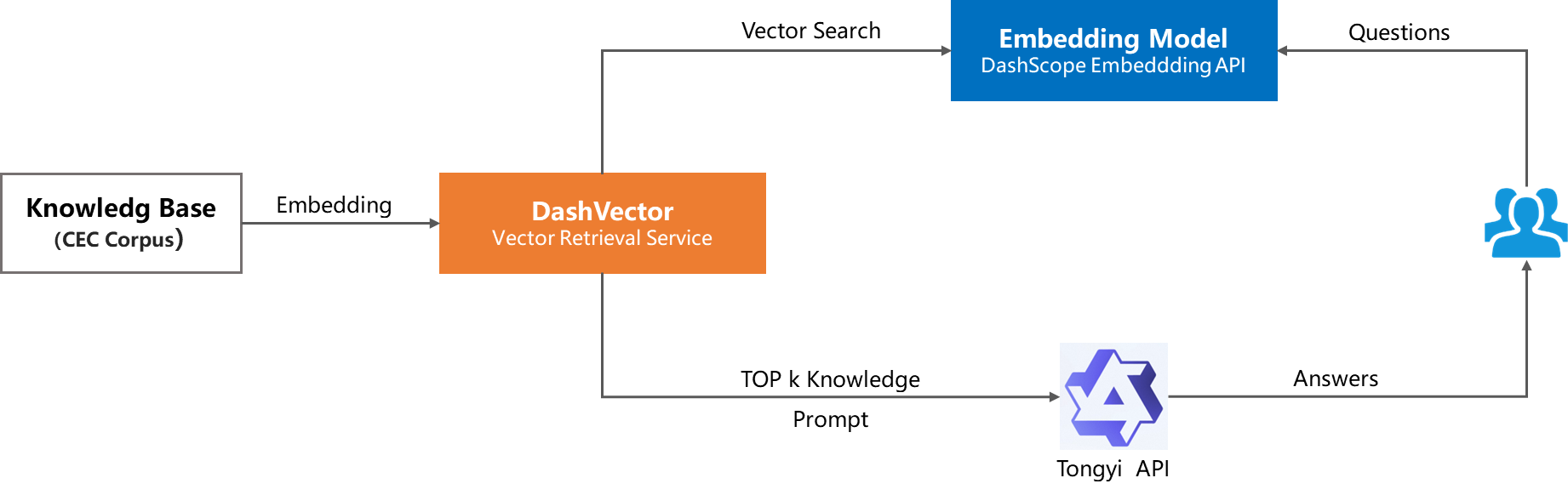
Q&A システムは、Qwen、 ChatGPT、オンラインカスタマーサービスシステム、Q&A チャットボットなど、NLP の一般的なアプリケーションです。Q&A システムには、事前に定義された質問と回答が保存されています。ユーザーが質問をすると、システムは最も類似した事前定義の質問と照合し、その回答を返します。これを構築するには、DashVector を使用して、事前に定義された Q&A ペアをベクトルに変換し、ベクトルデータベースに保存します。ユーザーが質問をすると、DashVector はそれをベクトルに変換し、データベースから最も類似した質問を取得します。モデルトレーニング、Q&A 推論、後処理の最適化と組み合わせることで、Qwen や ChatGPT のようなインテリジェントな対話システムを構築できます。
マルチモーダル画像検索
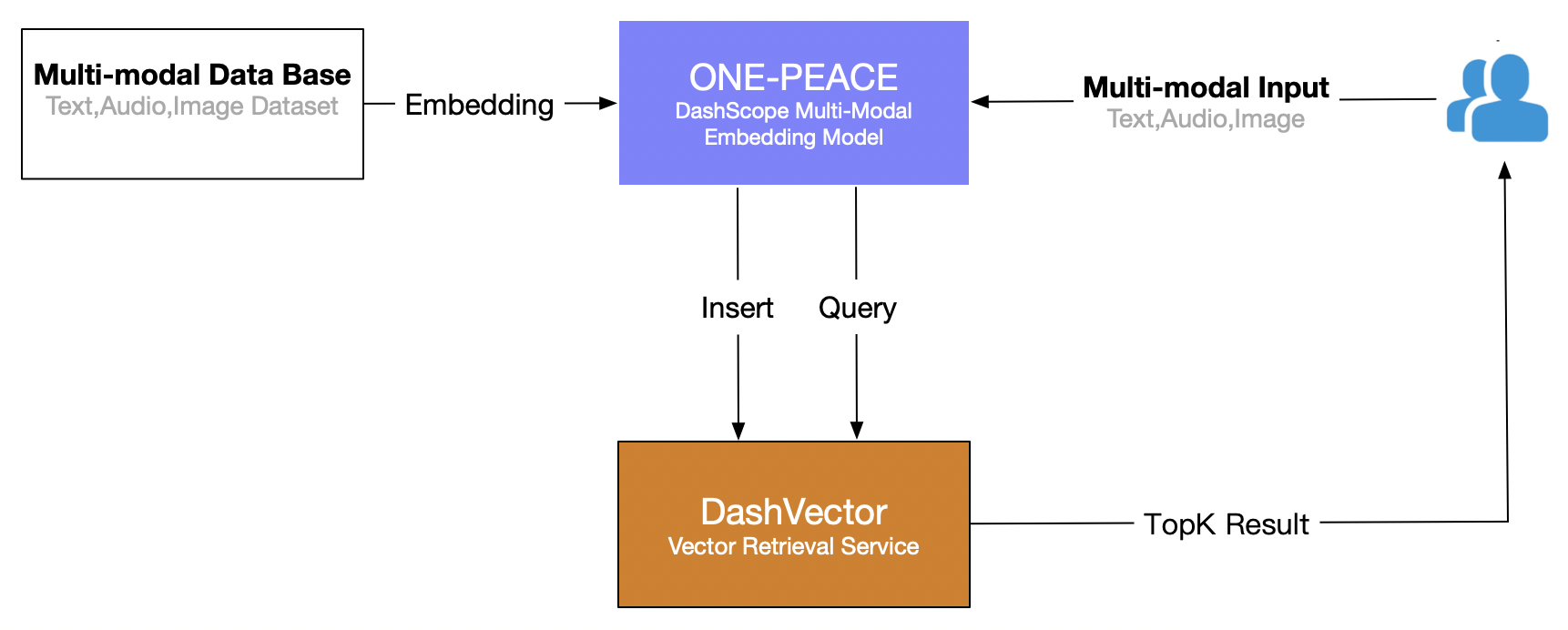
画像素材サイトやソーシャルプラットフォームは何億、何十億もの画像をホストしていますが、通常は基本的なテキスト検索や単一の画像検索しか提供していません。DashVector を使用すると、画像とテキスト記述をベクトルとしてベクトルデータベースで表現できます。このサービスは、Text-to-Image、Image-to-Image、テキストと画像を組み合わせた検索などのマルチモーダル検索パターンをサポートし、正確な絞り込みを可能にします。クエリ入力はベクトル化されて類似性マッチングが行われ、ユーザーが目的の画像を迅速に見つけられるように支援します。
動画検索
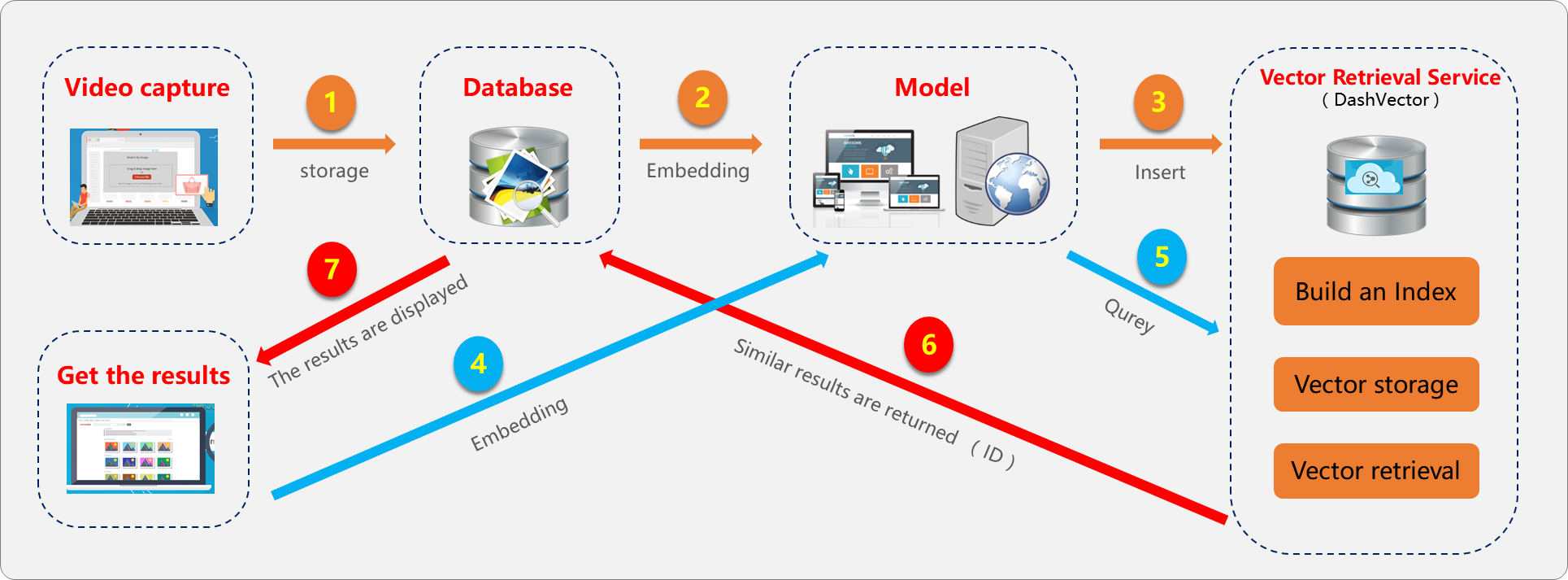
動画モニタリングシステム、映画やテレビ番組のウェブサイト、ショート動画アプリなどは、膨大な動画データを生成します。DashVector を使用して、動画データをベクトルに変換します。ユーザーが映画のクリップやスクリーンショットを持っている場合、動画類似検索システムはコンテンツベクトルを比較することで、最も類似した動画を取得します。クラスタリングベースの検索は、類似した動画をグループ化してクラスター内での検索を高速化することで、効率と精度をさらに向上させます。
分子検出とスクリーニング
ECFP や MACCS キーなどの分子フィンガープリントは、分子構造をベクトルに変換し、ベクトルデータベースに保存します。クエリ分子も同様に変換され、データベースは構造的に最も類似した分子を返します。この類似性に基づいた検索は、分子の検出とスクリーニングを可能にし、分子発見と創薬を加速させます。
