このトピックでは、Spark コンピュートエンジンで Tablestore にアクセスする場合に、DataFrame を使用して Tablestore データのバッチコンピューティングを実行する方法について説明します。 また、ローカル環境とクラスタ環境の両方でコードを実行およびデバッグする方法についても説明します。
前提条件
Tablestore にデータテーブルが作成され、データテーブルにデータが書き込まれます。 詳細については、「Wide Column モデルの概要」をご参照ください。
説明search_viewテーブルのスキーマとサンプルデータについては、「付録: サンプルデータテーブル」をご参照ください。Tablestore にアクセスする権限を持つ Alibaba Cloud アカウントまたは Resource Access Management (RAM) ユーザーの AccessKey ペアが作成されます。 詳細については、「AccessKey ペアを作成する」をご参照ください。
Java 開発環境がデプロイされています。
このトピックでは、Windows 環境、JDK 1.8、IntelliJ IDEA 2024.1.2 (Community Edition)、および Apache Maven を例として使用します。
手順
ステップ 1: プロジェクトのソースコードをダウンロードする
Git を使用してサンプルプロジェクトをダウンロードします。
git clone https://github.com/aliyun/tablestore-examples.gitネットワークの問題でプロジェクトをダウンロードできない場合は、tablestore-examples-master.zip を直接ダウンロードできます。
ステップ 2: Maven の依存関係を更新する
tablestore-spark-demoルートディレクトリに移動します。説明tablestore-spark-demoルートディレクトリにあるREADME.mdドキュメントを読んで、プロジェクト情報を十分に理解することをお勧めします。次のコマンドを実行して、
emr-tablestore-2.2.0-SNAPSHOT.jarをローカルの Maven リポジトリにインストールします。mvn install:install-file -Dfile="libs/emr-tablestore-2.2.0-SNAPSHOT.jar" -DartifactId=emr-tablestore -DgroupId="com.aliyun.emr" -Dversion="2.2.0-SNAPSHOT" -Dpackaging=jar -DgeneratePom=true
ステップ 3: (オプション) サンプルコードを変更する
ステップ 4: コードを実行およびデバッグする
コードは、ローカルまたは Spark クラスタで実行およびデバッグできます。 このセクションでは、TableStoreBatchSample を例として使用して、デバッグプロセスについて説明します。
ローカル開発環境
このセクションでは、IntelliJ IDEA を使用した Windows オペレーティングシステムを例として使用して、コードをデバッグする方法について説明します。
Scala プラグインをインストールします。
デフォルトでは、IntelliJ IDEA は Scala をサポートしていません。 Scala プラグインを手動でインストールする必要があります。
winutils.exe をインストールします (このトピックでは winutils 3.3.6 を使用します)。
Windows 環境で Spark を実行する場合、互換性の問題を解決するために
winutils.exeもインストールする必要があります。winutils.exeは、GitHub プロジェクトのホームページからダウンロードできます。Scala プログラム
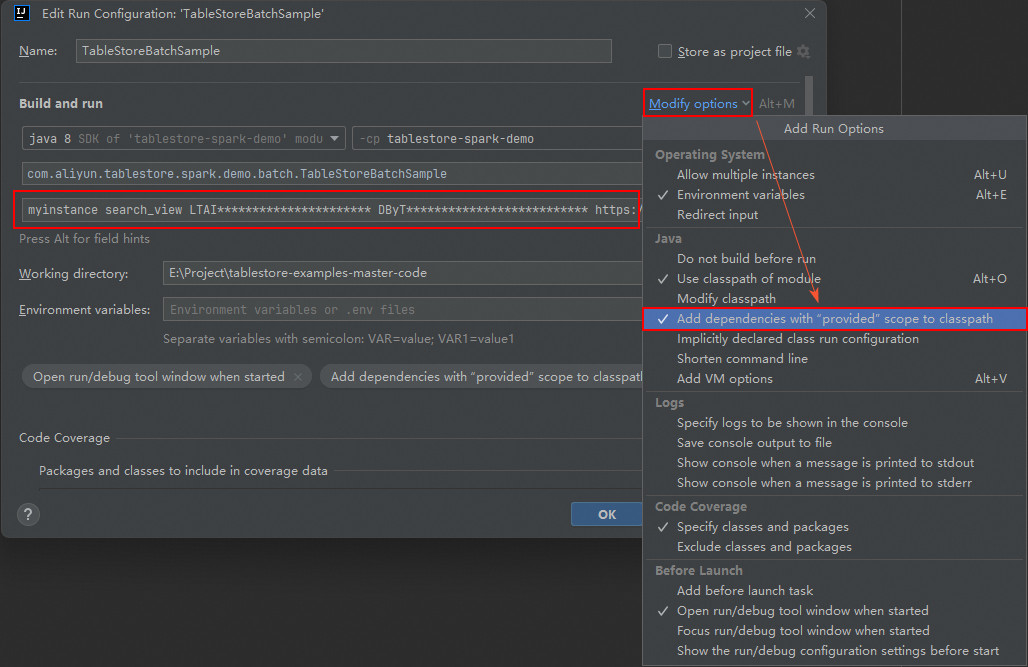
TableStoreBatchSampleを右クリックし、[実行構成の変更] を選択して、[実行] [構成] ダイアログボックスを開きます。説明実際の操作は、オペレーティングシステムと IntelliJ IDEA のバージョンによって多少異なります。
[プログラム引数] フィールドに、インスタンス名、データテーブル名、AccessKey ID、AccessKey シークレット、インスタンスエンドポイントを順番に指定します。
myinstance search_view LTAI********************** DByT************************** https://myinstance.cn-hangzhou.ots.aliyuncs.com[オプションの変更] をクリックし、["provided" スコープの依存関係をクラスパスに追加する] を選択して、[OK] をクリックします。
Scala プログラムを実行します。
Scala プログラムを実行すると、結果は Tablestore コンソールに出力されます。
With DataFrame +----+------+------------------------------------+-----+-------------+ |salt|UserId|OrderId |price|timestamp | +----+------+------------------------------------+-----+-------------+ |1 |user_A|00002664-9d8b-441b-bad7-845202f3b142|29.6 |1744773183629| |1 |user_A|9d8b7a6c-5e4f-4321-8765-0a9b8c7d6e5f|785.3|1744773190240| +----+------+------------------------------------+-----+-------------+ With Spark SQL +--------+ |count(1)| +--------+ | 2| +--------+ +--------+ |count(1)| +--------+ | 1| +--------+ +--------+ |count(1)| +--------+ | 2| +--------+
Spark クラスタ環境
デバッグを実行する前に、Spark クラスタをデプロイし、クラスタ環境の Spark バージョンがサンプルプロジェクトの Spark バージョンと一致していることを確認してください。 そうしないと、バージョンの非互換性によりランタイムエラーが発生する可能性があります。
このセクションでは、spark-submit メソッドを例として使用します。 サンプルコードのマスターは、デフォルトで local[*] に設定されています。 Spark クラスタでコードを実行する場合は、この設定を削除し、spark-submit パラメータを使用してマスターを指定できます。
mvn -U clean packageコマンドを実行して、プロジェクトをパッケージ化します。 JAR パッケージのパスは、target/tablestore-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jarです。JAR パッケージを Spark クラスタの Driver ノードにアップロードし、
spark-submitを使用してタスクを送信します。spark-submit --class com.aliyun.tablestore.spark.demo.batch.TableStoreBatchSample --master yarn tablestore-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar myinstance search_view LTAI********************** DByT************************** https://myinstance.cn-hangzhou.ots.aliyuncs.com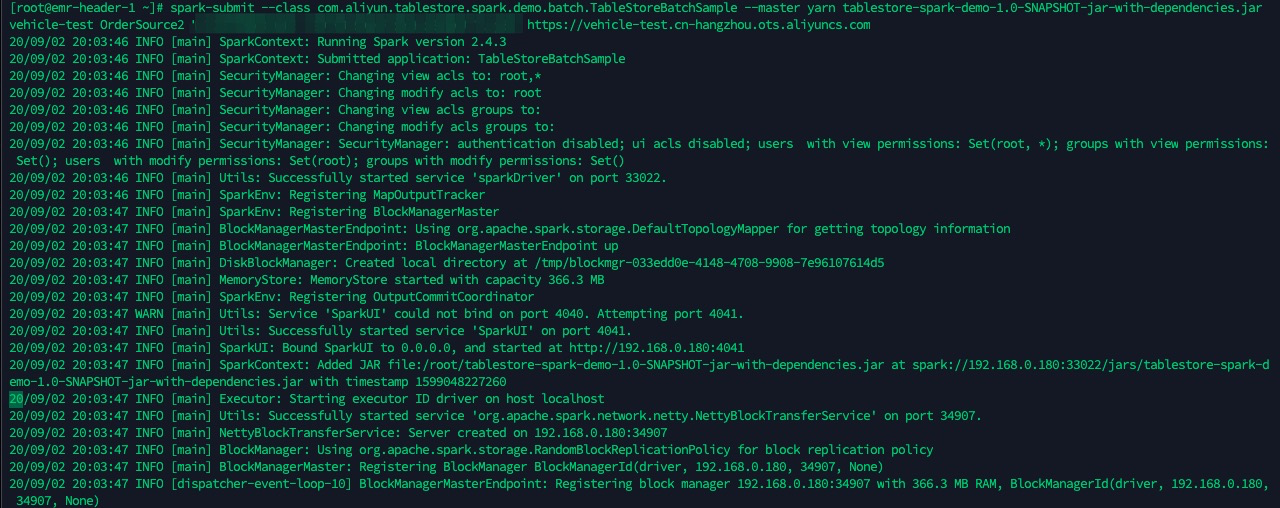
付録: サンプルデータテーブル
次の表に、search_view テーブルのスキーマとサンプルデータを示します。
サンプルテーブルスキーマ
フィールド名 | 型 | 説明 |
pk | long | プライマリキー列。 |
salt | long | ランダムな salt 値。 |
UserId | string | ユーザー ID。 |
OrderId | string | 注文 ID。 |
price | double | 注文金額。 |
timestamp | long | タイムスタンプ。 |
サンプルデータ
pk (プライマリキー列) | salt | UserId | OrderId | price | timestamp |
1 | 1 | user_A | 00002664-9d8b-441b-bad7-845202f3b142 | 29.6 | 1744773183629 |
2 | 1 | user_A | 9d8b7a6c-5e4f-4321-8765-0a9b8c7d6e5f | 785.3 | 1744773190240 |
3 | 2 | user_A | c3d4e5f6-7a8b-4901-8c9d-0a1b2c3d4e5f | 187 | 1744773195579 |
4 | 3 | user_B | f1e2d3c4-b5a6-4789-90ab-123cdef45678 | 11.9 | 1744773203345 |
5 | 4 | user_B | e2f3a4b5-c6d7-4890-9abc-def012345678 | 2547 | 1744773207789 |