Simple Log Service は、Scheduled SQL 機能を提供します。この機能を使用すると、スケジュールされた時間にデータを自動的に分析し、保存のためにデータを集計できます。また、この機能を使用して、データの射影とフィルタリングを行うこともできます。このトピックでは、Scheduled SQL の背景情報、機能、用語、スケジューリングと実行のシナリオ、および使用上の注意について説明します。
背景情報
ログやメトリクスなどの時間関連データは、過度に大量に蓄積される可能性があります。たとえば、1 日に 1,000 万件のデータレコードが生成される場合、年間約 36 億件のデータレコードが蓄積されます。長期のデータ保持には、大容量のストレージが必要です。必要なストレージを削減するためにデータ保持期間を短縮すると、ストレージコストを削減できます。ただし、これにより貴重なデータが失われる可能性があります。さらに、大量のデータは分析パフォーマンスを低下させる可能性があります。
データストレージと分析には、次の要件があります。
ほとんどのメトリクスは時間に敏感です。履歴データは分または時間の精度を持つことができますが、新しいデータはより高い精度を持つ必要があります。
データオペレーションスペシャリストやデータサイエンティストなどのデータユーザーは、分析のために完全データを保存する必要があります。
データ分析中は、完全データの処理と迅速な応答時間を両立させる必要があります。
上記の要件を満たすために、Simple Log Service は Scheduled SQL 機能を提供します。この機能を使用すると、高精度の履歴データを低精度のデータに圧縮し、圧縮されたデータを長期間保存できます。 Scheduled SQL 機能を有効にした後、ビジネス要件に基づいて、ソースログストアまたはメトリックストアのデータ保持期間を 15 日などの小さい値に変更し、宛先ログストアまたはメトリックストアのデータ保持期間を永続的に変更できます。これは、長期間保存されるデータが分析されるときのレイテンシを削減し、ストレージコストを削減するのに役立ちます。
特徴
Scheduled SQL は、SQL-92 構文と Simple Log Service クエリステートメントの構文をサポートしています。 Scheduled SQL ジョブは、スケジューリングルールに基づいて定期的に実行され、実行結果を宛先ログストアまたはメトリックストアに書き込みます。
スケジュールされたデータ分析: ビジネス要件に基づいて SQL ステートメントまたはクエリステートメントを作成して、スケジュールされたデータ分析を実行し、分析結果を宛先ログストアまたはメトリックストアに保存できます。
グローバル集計: 完全で詳細なデータを集計して保存できます。このプロセスには、データの非可逆圧縮が含まれます。圧縮後のストレージサイズとデータ精度は、要件を満たす必要があります。例:
秒単位の精度に基づいて 36 億件のデータレコードを集計して保存する場合、合計 3,150 万件のデータレコードが保存され、ストレージサイズは完全データの 0.875% になります。
分単位の精度に基づいて 36 億件のデータレコードを集計して保存する場合、合計 525,000 件のデータレコードが保存され、ストレージサイズは完全データの 0.015% になります。
射影とフィルタリング: 特定の条件に基づいてフィールドごとに生データをフィルタリングし、取得したデータを宛先ログストアまたはメトリックストアに保存できます。
また、ドメイン固有言語 (DSL) 構文を使用するデータ変換機能を使用して、データの射影とフィルタリングを行うこともできます。 DSL 構文は、SQL 構文よりも高い抽出、変換、ロード (ETL) 機能を提供します。 詳細については、「データ変換の基本」をご参照ください。
用語
ジョブ: 各 Scheduled SQL タスクはジョブに対応します。ジョブには、計算やスケジューリングの構成などの情報が含まれています。
インスタンス: Scheduled SQL ジョブは、スケジューリング構成に基づいてインスタンスを生成します。各インスタンスは、生データに対して SQL 計算を実行し、計算結果を宛先ログストアまたはメトリックストアに書き込みます。
インスタンス ID: インスタンスの一意の識別子。
作成時刻: インスタンスが作成された時刻。ほとんどの場合、インスタンスは構成したスケジューリングルールに基づいて作成されます。履歴データを処理する必要がある場合、またはレイテンシが存在してオフセットする必要がある場合は、インスタンスがすぐに作成されます。
開始時刻: インスタンスの実行が開始された時刻。ジョブが再試行された場合、開始時刻はジョブの最後のインスタンスの実行が開始された時刻です。
終了時刻: インスタンスの実行が停止された時刻。ジョブが再試行された場合、終了時刻はジョブの最後のインスタンスの実行が停止された時刻です。
スケジュールされた時刻: ジョブがスケジュールされている時刻。インスタンスのスケジュールされた時刻は、前のインスタンスがタイムアウトしたか、遅延したか、履歴データを処理するために実行されたかに関係なく、ジョブのスケジューリングルールに基づいて生成されます。
ほとんどの場合、連続して生成されるインスタンスのスケジュールされた時刻は連続しており、連続したインスタンスは完全なデータセットを処理できます。
SQL タイムウィンドウ: Scheduled SQL ジョブの実行時に分析されるデータの時間範囲。 Simple Log Service は、ジョブの実行時に時間範囲を超えるデータを分析しません。 SQL タイムウィンドウは、インスタンスのスケジュールされた時刻に基づいて計算される左閉右開区間です。 SQL タイムウィンドウは、インスタンスの作成時刻と開始時刻とは無関係です。たとえば、インスタンスのスケジュールされた時刻が 2021/01/01 10:00:00 で、SQL タイムウィンドウの式が [@m - 10m, @m) の場合、インスタンスの SQL タイムウィンドウは [2021/01/01 09:50:00, 2021/01/01 10:00:00) です。
ステータス: Scheduled SQL インスタンスのステータス。インスタンスは、RUNNING、STARTING、SUCCEEDED、または FAILED の状態になります。
遅延実行: Scheduled SQL ジョブ用に構成できるパラメーター。パラメーターを N に設定すると、インスタンスはスケジュールされた時刻から N 秒後に実行を開始します。これは、データのレイテンシによって発生する可能性のある不正確な計算結果を防ぐのに役立ちます。インスタンスの実行を遅延させる必要がない場合は、[タスクの遅延] パラメーターを 0 秒に設定できます。
たとえば、[スケジューリング間隔の指定] パラメーターを [時間ごと] に、[タスクの遅延] パラメーターを [30] 秒に設定すると、1 日に 24 個のインスタンスが生成されます。インスタンスのスケジュールされた時刻が 2021/4/6 12:00:00 の場合、インスタンスの開始時刻は 2021/4/6 12:00:30 です。
スケジューリングと実行のシナリオ
各ジョブは複数のインスタンスを生成できます。ジョブが正常にスケジュールされているか、例外のためにインスタンスが再試行されているかに関係なく、一度に RUNNING 状態になることができるジョブのインスタンスは 1 つだけです。複数のインスタンスを同時に実行することはできません。次の例は、スケジューリングと実行の典型的なシナリオを示しています。
シナリオ 1: インスタンスの実行を遅延させる
インスタンスの実行が遅延されているかどうかに関係なく、インスタンスのスケジュールされた時刻は、ジョブのスケジューリングルールに基づいて事前に生成されます。インスタンスが遅延された場合、後続のインスタンスも遅延される可能性があります。ただし、インスタンスがスケジュールどおりに実行されるまで、後続のインスタンスをより高速に実行することで、遅延を徐々にオフセットできます。

シナリオ 2: 過去の時点から Scheduled SQL ジョブをスケジュールする
Scheduled SQL ジョブを作成するときに、ジョブが履歴データを処理できるようにスケジューリングルールを構成できます。ジョブが開始履歴時点にスケジュールされると、履歴データを処理するためにインスタンスが生成されます。次に、履歴データを処理するためにさらに多くのインスタンスが生成されます。インスタンスは、インスタンスがスケジュールどおりに実行されるまで、履歴データを処理するために順番に実行されます。

シナリオ 3: 指定された期間内に Scheduled SQL ジョブをスケジュールする
一定期間内にログを処理するようにジョブをスケジュールする場合、スケジューリングの期間を指定できます。スケジューリングの終了時刻を指定すると、ジョブは最後のインスタンスの実行後にインスタンスを生成しません。最後のインスタンスのスケジュールされた時刻は、スケジューリングの終了時刻と同じかそれ以降にすることはできません。
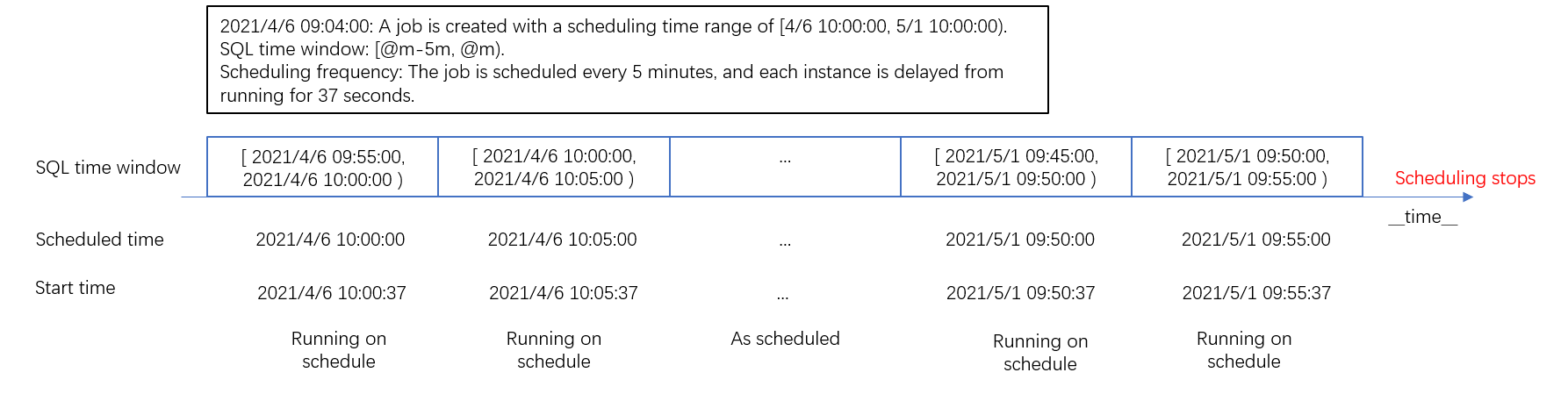
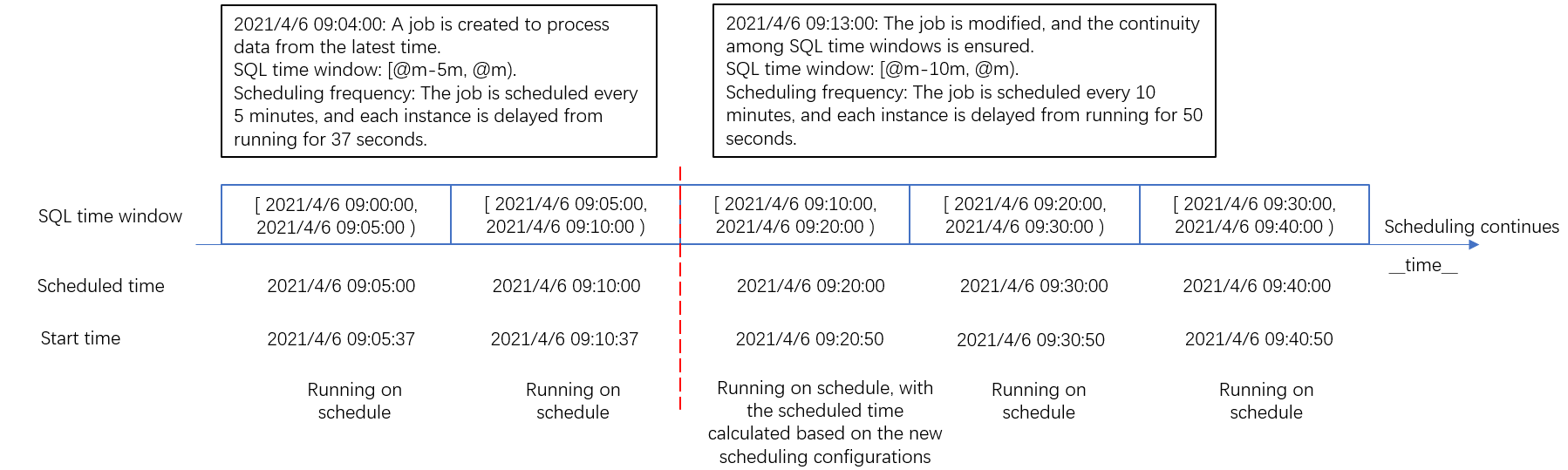
シナリオ 4: スケジューリング構成を変更する
ジョブのスケジューリング構成を変更した後、ジョブは新しい構成に基づいてインスタンスを生成します。インスタンス間で SQL タイムウィンドウの連続性を確保する場合は、スケジューリング構成の SQL タイムウィンドウとスケジューリング頻度を変更できます。
シナリオ 5: 失敗したインスタンスを再試行する
ほとんどの場合、Scheduled SQL ジョブは、スケジュールされた時刻に基づいてインスタンスを時系列で生成します。権限が不十分、ソースログストアまたはメトリックストアが存在しない、宛先ログストアまたはメトリックストアが存在しない、または SQL 構文が無効なためにインスタンスの実行に失敗した場合、システムはインスタンスの自動再試行を許可します。再試行回数が指定した上限を超えた場合、またはインスタンスが指定した最大時間を超えて再試行された場合、インスタンスは再試行を停止し、FAILED 状態になります。次のインスタンスが実行を開始します。
失敗したインスタンスのアラートを構成し、インスタンスを手動で再試行できます。過去 7 日間に生成されたインスタンスを表示および再試行できます。インスタンスの実行後、システムは再試行結果に基づいてインスタンスのステータスを SUCCEEDED または FAILED に変更します。 詳細については、「Scheduled SQL ジョブのインスタンスを再試行する」をご参照ください。
使用上の注意
Scheduled SQL 機能を使用する場合は、ビジネス要件に基づいてデータの適時性と正確性のバランスをとることをお勧めします。
データが Simple Log Service にアップロードされると、レイテンシが発生する可能性があります。この場合、インスタンスの実行時に、SQL タイムウィンドウのデータが Simple Log Service に完全にアップロードされていない可能性があります。この問題を防ぐために、データ収集レイテンシとビジネスで許容される最大結果表示レイテンシに基づいて、[タスクの遅延] パラメーターと [SQL タイムウィンドウ] パラメーターを構成することをお勧めします。さらに、インスタンスが期待どおりに実行されるように、理論値よりもわずかに早い値を指定することをお勧めします。
順序付けられていないデータがアップロードされた場合に処理結果の正確性を確保するために、ジョブに 分または時間レベルの SQL タイムウィンドウを指定することをお勧めします。