このトピックでは、Alibaba Cloud Simple Log Service (SLS) インテグレーションセンターを使用して、ワンクリックで OpenClaw AI エージェントのログを統合する方法について説明します。組み込みの監査および可観測性ダッシュボードを使用して、セキュリティ監査と運用監視のためのすぐに使えるソリューションを構築できます。
背景情報
OpenClaw のセキュリティリスク:統制された運用が不可欠な理由
OpenClaw は、2026 年に最も注目されたオープンソースの AI エージェントプラットフォームの 1 つです。大規模言語モデル (LLM) がファイルシステムを直接操作したり、シェルコマンドを実行したり、ウェブを閲覧したり、メッセージを送信したりすることを可能にします。この機能は、LLM の推論能力を実際のシステム操作に変換します。この「自律実行」能力は、その中核的な価値であると同時に、中核的なリスクでもあります。
業界のセキュリティインシデント:リスクは仮説ではなく現実
2026 年初頭、複数のセキュリティベンダーが OpenClaw に関連する一連の脆弱性とインシデントを公表しました。
ソース
調査結果
セキュリティ調査統計
複数の国で 40,000 を超える OpenClaw インスタンスがパブリックインターネット上でアクセス可能です。これらのうち約 15,000 はパッチが適用されていないか、デフォルト設定を使用しており、リモートコントロールのリスクがあります。公開されているインスタンスの約 93% には、深刻な認証バイパスの脆弱性があります。
GitHub Security Advisory
(GHSA-g8p2-7wf7-98mq)
コントロール UI は URL パラメーター内の gatewayUrl を信頼し、自動的に接続します。ユーザーが悪意のあるリンクをクリックすると、ゲートウェイのトークンが盗まれ、攻撃者のサーバーに送信される可能性があります。これにより、ゲートウェイがローカルマシン上でのみリッスンしている場合でも、CVSS (共通脆弱性評価システム) スコア 8.8 のワンクリックリモートコード実行 (RCE) につながります。これは v2026.1.29 で修正されました。
スキルサプライチェーン
OpenClaw スキルレジストリで 800 を超える悪意のあるスキルが発見され、これは公開されている全パッケージの約 20% を占めます。これらの悪意のあるスキルには、認証情報の窃取やバックドアの埋め込みが含まれます。未レビューのスキルをインストールすることは、エージェント権限を昇格させることと同じです。
Unit 42 などによる調査
間接プロンプトインジェクション (IDPI) が実際のシナリオで観測されています。攻撃者はウェブページのコンテンツに隠された命令を埋め込みます。エージェントがそのコンテンツをフェッチすると、誤って命令を実行してしまい、データ漏洩や不正な操作につながります。
規制と警告
複数の国の規制当局が AI エージェントのリスクに注目しています。工業情報化部 (MIIT) は、オープンソースの OpenClaw AI エージェントのセキュリティリスクについて警告を発し、タイムリーな更新とセキュリティ強化を推奨しています。
コード監査データ:OpenClaw 自身のセキュリティ修正の頻度
業界レポートは外部の脅威状況を示していますが、OpenClaw 自身のコードリポジトリの監査は別の側面を明らかにします:プロジェクト自体が頻繁にセキュリティ問題を修正しているということです。Git の履歴とコミットメッセージのセキュリティセマンティクスを分析することで、一定期間におけるセキュリティ関連のコード変更の規模と分布を定量化できます。これにより、攻撃対象領域がどこに集中しているかを判断するのに役立ちます。
OpenClaw の最近のコミットをフィルタリングして分類すると、リスクがエントリ層と実行層に非常に集中していることがわかります:
モジュール
セキュリティ修正の数
割合
主なリスク
src/tools/52
35%
コマンドインジェクション、ディレクトリトラバーサル
src/gateway/38
26%
アクセス制御、認証と認可
src/auth/18
12%
認証バイパス、CSRF
src/sandbox/15
10%
ディレクトリトラバーサル、SSRF
src/hooks/12
8%
プロンプトインジェクション、情報漏洩
ツール実行層 (
tools/) とイングレスゲートウェイ層 (gateway/) は、「自律実行」と「マルチエントリアクセス」のリスクが現れる場所です。静的コード監査はコミットされた変更しかカバーできません。ランタイムの動作のばらつき、設定の組み合わせ、または外部入力によって引き起こされる攻撃パスを考慮することはできません。ランタイム保護だけでは不十分な理由
正しく設定されていれば、OpenClaw のアーキテクチャは攻撃対象領域を効果的に減らすことができます。しかし、セキュリティエンジニアリングの観点からは、同じ信頼ドメイン内でのランタイムチェックに依存しており、これにはいくつかの固有の制限があります:
保護レイヤー
メカニズムと機能
固有の制限
ツールポリシーパイプライン
ツールが呼び出される前に、送信者、チャネル、ツール名などの要素に基づくポリシーが、許可、拒否、または手動承認の要否を決定します。ACP 承認フローをサポートします。
ポリシーの設定ミス、ルールの省略、またはポリシーのバイパス (正当なツールチェーンを介して間接的に高リスクな効果を達成するなど) は、不正な実行につながる可能性があります。ポリシー変更後の独立した監査の欠如は、インシデント後の原因特定を困難にします。
スタック/ループ検出
セッションが数ラウンドにわたって実質的な進展がない場合 (新しいユーザーやアシスタントのメッセージがなく、ツールの呼び出しが繰り返されるだけなど) を検出し、アラートまたは終了をトリガーします。
この機能は「進展のない」ループしか識別できません。論理的に一貫しているが悲惨な結果をもたらす多段階の操作チェーン (データの削除や漏洩への段階的な誘導など) を識別することはできません。誤検知と偽陰性はしきい値の調整に依存します。
コマンドの許可リスト/拒否リスト
execやshellなどのツールに対して、許可リストまたは拒否リストを使用して実行可能なコマンドをフィルタリングし、任意のコマンド実行を減らします。難読化またはエンコードされたコマンド (base64 デコードされた実行や、エイリアス化および複数行の連結など) は、歴史的にフィルターをバイパスし、対応する CVE と修正につながってきました。リストはしばしば新しい攻撃手法に遅れをとります。
コンテキストとセキュリティ命令
システムプロンプトを通じて「X をしてはいけない」や「Y をする前に承認が必要」などの制約を注入し、モデルがそれに従うことを期待します。
長い会話では、コンテキストウィンドウの圧縮、要約、または切り捨てによって、主要なセキュリティ命令が薄められたり、モデルが「忘れたり」することがあります。敵対的な入力は、これらの制約をオーバーライドまたは弱めようと試みることがあります (プロンプトインジェクション)。
したがって、ランタイム保護は城壁のように機能します。既知の攻撃パスのほとんどをブロックできますが、設定が常に正しいことを保証することはできません。また、未知のバイパスや論理的な誤用を防ぐこともできません。セキュリティアーキテクチャでは、エージェントの呼び出し元、消費量、ツール呼び出しシーケンス、および結果を継続的に観測し、監査するための補完的な「監視役」が必要です。
ソリューション概要
可観測性はこの「監視役」として機能します。ログ、メトリクス、トレースを使用してエージェントの動作を継続的に監視します。これにより、監査のトレーサビリティと使用状況のコンプライアンスがサポートされます。異常検知により、「誰が呼び出しを行ったか?」、「コストはいくらかかったか?」、「具体的に何が行われたか?」といった質問に答えるのに役立ちます。これにより、ポリシーが失敗したり、新しいタイプの攻撃が発生した場合に、影響が広がる前に早期に検出して対応できます。
可観測性の 3 つの柱を AI エージェントにマッピング
可観測性は、ログ、メトリクス、トレースの 3 つの柱に基づいています。OpenClaw のシナリオでは、これらの柱、そのデータソース、そしてそれらが答える中心的な質問の関係は次のとおりです:
柱 | OpenClaw データソース | コア質問に回答済み |
ログ (セッション監査ログ) |
| エージェントは何をしましたか?どのツールを呼び出しましたか?消費したトークン数とコストはいくらですか? |
ログ (アプリケーション運用ログ) |
| システムで何が問題になりましたか?Webhook の失敗、認証拒否、ゲートウェイの異常? |
メトリクス |
| 現在のコストとレイテンシは正常ですか?スタックしたセッションや異常なリトライはありますか? |
トレース |
| 単一のメッセージが受信から完全な応答までどのようなステップを経ましたか?呼び出しチェーンはどのように接続されていますか? |
3 つの柱はすべて不可欠です。メトリクスだけでは、コストが急増した「誰が」や「なぜ」に答えることはできません。セッションログだけでは、システム全体の健全性や異常の変曲点を評価することはできません。アプリケーション運用ログだけでは、エージェントのビジネス上の振る舞いやツール呼び出しシーケンスを見ることはできません。連携して機能することで、3 つの柱はセキュリティ監査、コスト管理、トラブルシューティング、そして運用保守 (O&M) をサポートできます。
Alibaba Cloud SLS の機能と利点
可観測性の基盤プラットフォームとして、SLS は OpenClaw のシナリオに対して以下の自然な利点を持っています:
OpenClaw の技術スタックとネイティブに連携する強力なデータインジェスト機能
LoongCollector は強力な OneAgent 収集機能を持ち、ログと OpenTelemetry Protocol (OTLP) の両方をネイティブにサポートします。エージェントのセッションログは、モデルの対話コンテキストを運ぶため、しばしば長くなります。LoongCollector は長文ログのパフォーマンス専有型収集を提供します。OpenClaw の組み込み
diagnostics-otelプラグインとシームレスに統合し、メトリクスとトレースを OTLP を使用して直接 SLS に書き込むことができます。豊富なクエリ、分析、処理オペレーター
セッションログはネストされた JSON 形式です (例:
message.content、message.usage.cost、message.toolName)。SLS は SQL + SPL コンピュートエンジンと、豊富な解析、フィルタリング、集約オペレーターを提供します。追加の抽出・変換・書き出し (ETL) 処理なしで、ネストされたフィールドをリアルタイムでインデックス化し、分析できます。セキュリティとコンプライアンス機能
Resource Access Management (RAM) アクセス制御、機密データマスキング、暗号化ストレージは、監査証跡とコンプライアンス要件を満たします。SLS はネットワークセキュリティ製品の認証を受けており、等級保護や業界のコンプライアンスシナリオに適した可観測性および監査基盤となります。アラート機能チャネルは DingTalk、テキストメッセージ、メールをサポートしており、セキュリティイベントやコスト、異常アラートのタイムリーな通知と対応を容易にします。
フルマネージド、従量課金、弾力的スケーリング
ログ分析は、収集、ストレージ、インデックス作成、クエリ、ダッシュボード、アラート機能を含むオールインワンのプロセスであり、Logstore と Metricstore によって完全に管理されます。小規模なエージェントの場合、ログ量は多くなく、従量課金のコストは低く抑えられます。トラフィックが増加すると、サービスは弾力的にスケーリングし、容量を予約したり手動でスケールアウトしたりする必要がなくなります。独自の Elasticsearch、Prometheus、またはその他のシステムを構築する必要はありません。
したがって、SLS は OpenClaw の統制された運用のための可観測性および監査基盤として非常に適しており、監査、コスト管理、異常検知、セキュリティコンプライアンス、および O&M を複数のシナリオにわたってサポートします。
SLS は現在、OpenClaw のためのワンストップ統合ソリューションを提供しています:
インテグレーションセンターを使用して、ウィザード形式で収集パスと解析メソッドを設定します。設定は自動的に生成、配信、適用されます。これにより、セッションログ、アプリケーションログ、OTLP テレメトリのための統一されたエントリポイントと統一されたプロジェクトが作成されます。このワンストップ統合により、断片化されたデータソースに関連する複雑さと O&M コストが大幅に削減されます。
単一のセッションデータセットをセキュリティ監査、コストおよび行動分析に使用でき、複数のシナリオに対応します。
監査、コスト分析、運用メトリクスのための事前構築済みダッシュボードは、統制された運用を観測するための、すぐに使えるクローズドループソリューションを提供します。
操作手順
ステップ 1:ログの取り込み (セッションログを例として)
セッションログは、セキュリティ監査のコアデータソースです。すべての会話のターン、すべてのツール呼び出し、消費されたすべてのトークンを記録します。
前提条件
プロジェクトを作成済みであること (例:
openclaw-observability)、およびLogstore を作成済みであること。OpenClaw が実行されている ECS インスタンスまたはオンプレミスサーバーに LoongCollector がインストールされていることを確認してください。
操作手順
Simple Log Service コンソールにログインします。右側のペインで、データのインポート をクリックします。統合カードで、OpenClaw-セッションログ を選択し、送信先のプロジェクトと Logstore を選択します。
サーバグループ設定 タブで、LoongCollector をインストールしたときに作成したマシングループを ソースサーバーグループ リストから選択し、適用されたサーバーグループ リストに追加します。
ハートビート異常のトラブルシューティング
Logtail構成 ページで、Simple Log Service は組み込みの収集設定を自動的に入力します。変更が不要な場合は、次へ をクリックします。
設定名 はデフォルトで設定されています。必要に応じて変更できます。
その他のグローバル設定 で、ログテーマのタイプ はデフォルトで設定されています。
トピック生成モードについて: LoongCollector はファイルパスからトピックと session_id を自動的に抽出できます。事前入力されたパスと一致しないカスタムファイルパスを使用する場合は、設定を変更する必要があります。
ファイルパス はデフォルトで自動的に入力されます。
テキストファイルパスについて: 事前入力されたファイルパスは、Linux ホスト上の非 root ユーザーによるデフォルトインストールを想定しています。実際のパスが異なる場合は、変更する必要があります。
処理モード セクションでは、処理プラグインの組み合わせがデフォルトで設定されています。
時間解析について: デフォルトでは、OpenClaw は協定世界時 (UTC)+0 タイムゾーンでログを出力します。タイムゾーンをカスタマイズした場合は、時間の不一致を避けるために、時間解析プラグインのタイムゾーンも変更する必要があります。
クエリと分析の設定 ページで、Simple Log Service は組み込みのインデックスとレポートを自動的に作成します。これらは後でクエリと分析インターフェイスおよび ダッシュボード ページで表示できます。
組み込みインデックスは次のとおりです:

ダッシュボードは次のとおりです:
OpenClaw 行動分析ダッシュボード
OpenClaw 監査ダッシュボード
OpenClaw メトリクスダッシュボード
OpenClaw トークン分析ダッシュボード
ステップ 2:監査と観測
SLS は、セキュリティ監査、コスト分析、行動分析、運用メトリクスの 4 つのディメンションをカバーする OpenClaw 用の事前構築済みダッシュボードを提供します。
Simple Log Service コンソールにログインします。プロジェクト一覧 セクションで、送信先のプロジェクトを選択します。
ログ管理 セクションで、送信先の Logstore を見つけ、検索と分析 をクリックして統合を検証し、ログ形式を確認します。
ダッシュボード で、プリセットのダッシュボードを表示します。
セキュリティ監査ダッシュボード
エージェントの行動の可視性は、システムのセキュリティとコンプライアンスリスクに直接関係します。異常な行動は、実際の損害が発生する前に兆候を示すことがよくあります。セキュリティ監査ダッシュボードは、OpenClaw の統制された運用のためのコアダッシュボードです。これは、「エージェントは何をしているのか、高リスクなアクションはあるか、誰が不正な操作を行っているのか?」という中心的な質問に答えることに焦点を当てています。行動概要、高リスクコマンド、プロンプトインジェクション、データ漏洩などのディメンションにわたって、リアルタイムの行動監視、脅威検知、インシデント後のトレーサビリティ機能を提供します。
セキュリティ監査統計概要ページ:
このページは、指定されたタイムウィンドウ内の高リスク操作の多次元カウントを中心とした、OpenClaw のセキュリティ体制の単一画面リスクスナップショットを提供します。高リスクコマンド実行、アウトバウンドウェブ要求、アウトバウンドコマンドライン操作、アウトバウンド通信ツール使用、機密ファイルアクセス、プロンプトインジェクションの 6 つのメトリクスが並べて表示されます。前日比の比較データと組み合わせることで、セキュリティチームは詳細を掘り下げることなく、現在のリスクレベルが異常であるかどうかを迅速に判断できます。
プロンプトインジェクションイベント後の高リスク操作の数には特に注意してください。通常の高リスク操作はタスクの正当なニーズから生じる可能性があります。しかし、インジェクション後にトリガーされた高リスクな行動は、強力な脅威シグナルです。これは、注入された悪意のある命令がエージェントに行動を起こさせたことを示します。誤検知があったとしても、このようなシグナルは、さらなる確認を待つのではなく、最高レベルの手動レビューをトリガーすべきです。したがって、「インジェクション後のツール呼び出しがあったセッション数」は、概要全体で最も脅威信頼度の高いシグナルです。このようなセッションが 3 つあることは、数百の通常の高リスクコマンドよりも高い優先度を持つことがよくあります。
高リスクセッションテーブルは、各ディメンションのリスクカウントをセッションごとに集約します。包括的なリスクスコアによってセッションを自動的にソートし、手動介入が最も必要なセッションを一番上に表示します。セキュリティチームはログを一つ一つふるいにかける必要はありません。最もリスクの高いセッションから直接トレーサビリティを開始でき、検出から対応までのタイムウィンドウを大幅に短縮します。
スキル使用状況分析
スキル使用状況分析は、攻撃対象領域の観点から OpenClaw の機能境界を調査します。スキルは OpenClaw のネイティブな機能拡張メカニズムであり、悪意のあるプロンプトインジェクションの主要な攻撃ベクトルでもあります。ユーザーはしばしば、セキュリティ脆弱性を持つ、または悪意のある命令が埋め込まれたスキルを意図せずインストールしてしまい、攻撃者に制御可能な機能エントリポイントを提供してしまいます。したがって、スキル呼び出しの分布は単なる使用統計ではなく、攻撃パス分析の重要な基盤でもあります。
使用状況分布の円グラフは、セキュリティチームがスキル呼び出しのベースライン理解を迅速に確立するのに役立ちます:どのスキルが高頻度の主流呼び出しで、どれがマージナルで低頻度か。珍しいスキルの割合が突然上昇したり、見たことのない新しいスキルが現れたりした場合、それはしばしばエージェントが意図しない機能パスに誘導されていることを意味し、タイムリーな調査が必要です。
新しいスキルテーブルのコンテンツは特に重要です。新しく導入されたスキルは、徹底的なセキュリティ評価を受けていません。その権限境界と行動パターンは、セキュリティチームにとって盲点です。最初の呼び出し時間の逆時系列でソートすることで、環境内で新たに出現したスキルを最も早い機会に捉え、悪用される前にレビューを完了できます。
高リスクコマンド実行監視
OpenClaw の革新的な機能の 1 つは、システムコマンドの自律実行であり、これが攻撃者にとって理想的な踏み台にもなっています。エージェントがプロンプトインジェクションを受けたり、悪意のあるスキルに制御されたりすると、攻撃者はエージェントのシステムアクセス権限を使用して、ファイルの削除、権限昇格、データ漏洩などの破壊的な操作を実行できます。これらのアクションはすべてエージェントの ID で開始されるため、通常のタスクの行動と区別するのが非常に困難です。
高リスクコマンド実行監視の核心的な価値は、ランタイム保護の外部に独立した可観測性レイヤーを確立することです。OpenClaw のツール権限システムは、すでにランタイムレベルで制御を実装しています。しかし、ポリシー設定のエラー、曖昧に定義された権限境界、またはカバーされていないエッジケースはすべて、高リスクコマンドがランタイムレベルで気づかれずに通過する原因となる可能性があります。可観測性レイヤーは保護メカニズムから独立して動作するため、ランタイムで見落としがあったとしても、高リスク操作が完全に検出されないことはありません。
タイムラインビューの重要性は、単にカウントするだけでなく、セキュリティチームが行動パターンを特定するのに役立つことです。孤立した単一の高リスクコマンドは、短期間に密集した一連の呼び出しとはリスクの意味が異なります。後者は、エージェントが制御されて体系的に悪意のある命令を実行している典型的な特徴であり、即時の介入が必要です。詳細テーブルは完全なトレーサビリティコンテキストを提供し、セキュリティチームが異常なシグナルから特定のセッションと元のコマンドまで迅速に追跡できるようにします。
プロンプトインジェクション検出
プロンプトインジェクションは、AI を有害な行動に駆り立てるための中心的な攻撃手法です。攻撃パスに関係なく、それが直接のユーザー入力であれ、スキル呼び出しからの戻り値であれ、あるいは
web_fetchやreadのようなツールによって読み取られた外部データであれ、悪意のある命令は最終的にプロンプトに組み込まれてエージェントに影響を与える必要があります。プロンプトは、すべての攻撃パスの最終的な収束点です。インジェクションソースの分布は、リスクの実際の本質を判断するのに役立ちます。直接のユーザー入力からのインジェクションは通常意図的ですが、
toolResultによって運ばれるインジェクションは、ユーザーにはしばしば知られていません。OpenClaw のようなパーソナルアシスタントタイプのエージェントにとって、間接的なインジェクションが主な脅威です。ユーザーがインストールしたスキルやアクセスした外部コンテンツはすべてインジェクションベクトルになる可能性があり、ユーザーが積極的に特定して回避することは困難です。インジェクション分類の価値は、単に異常をフラグ付けするだけでなく、攻撃の意図を特定することにあります。同じインジェクションイベントに対して、
ROLE_HIJACKとJAILBREAKは、攻撃者がエージェントの行動境界を突破しようとしていることを意味します。HIDDEN_INSTRUCTIONは、より隠密な埋め込み技術を表します。これらのタイプの対応優先度と処理方法は異なります。分類分布の変化を継続的に観測することは、特定の攻撃対象領域に対する集中的な試みを発見するのにも役立ちます。詳細テーブルは、各インジェクションイベントのトリガーとなったツール、セッションコンテキスト、および元のコンテンツを記録します。これにより、セキュリティチームは分類された統計から特定のイベントに迅速にドリルダウンでき、パターン認識からトレーサビリティと対応までの完全なループを完了できます。
機密データ漏洩検出
エージェントのコンテキストでは、データ漏洩は単一のイベントではなく、複数のステップからなる行動の連鎖であることがよくあります:エージェントが機密ファイルを読み取るように誘導され、そのコンテンツがモデルのコンテキストに入り、その後、後続のツール呼び出しを通じて外部に送信されます。いずれかのステップを単独で観測しても、脅威を判断するのは困難です。ファイルアクセスとアウトバウンドの行動を関連付けることによってのみ、攻撃の完全な意図を再構築できます。
機密データ漏洩検出は、ファネル分析アプローチを使用し、ノイズを段階的に絞り込んで真の脅威を正確に特定します。第 1 層では、資産タイプ (SSH_KEY、ENV_FILE、CREDENTIALS、CONFIG_SECRET、HISTORY) ごとに分類された機密ファイルアクセスの完全な記録を行い、アクセスベースラインを確立します。第 2 層では、チャネル (API_CALL、MESSAGE_SEND、WEB_ACCESS、EMAIL) ごとにアウトバウンドの行動を独立して追跡し、潜在的なデータ出口点を特定します。第 3 層では、時間ディメンションでこの 2 つを関連付けます。機密ファイルアクセスとアウトバウンド操作が同じセッション内で短時間のうちに連続して発生した場合、それは優先度の高い漏洩イベントとしてマークされます。
このメカニズムの核心的な価値は、単一点のアラートではなく、因果関係の特定にあります。エージェントが SSH_KEY を読み取ることは、必ずしも脅威ではありません。API_CALL を開始することも、必ずしも脅威ではありません。しかし、両方が同じセッション内で分単位の間隔で発生し、アウトバウンドのパラメーターに機密ファイルの内容が含まれている場合、脅威の信頼度は大幅に向上します。行動連鎖分析テーブルは、access_time と outbound_time の時間差と完全な呼び出しパラメーターを直接提示し、セキュリティチームがログを手動で関連付けることなくトレーサビリティと判断を完了できるようにします。
トークン分析ダッシュボード
トークンの消費は運用コストに直接関係し、その変動はしばしばシステム異常 (プロンプトインジェクションによるコンテキストの拡大など) の早期シグナルとなります。トークン分析ダッシュボードは、「お金はどこで使われているのか?」、「その支出は合理的か?」、「異常はないか?」という中心的な質問に焦点を当てています。全体概要、モデルディメンションのトレンド、セッションの観点から、使用状況の監視、コスト分析、異常検知機能を提供します。
コストデータについて: ダッシュボードの
costフィールドは、OpenClaw のusage.costに由来します。OpenClaw はネイティブで段階的課金をサポートしておらず、cacheRead + cacheWrite の計算ロジックはプロバイダーのロジックと一致させることができません。inputTokens × input + outputTokens × output + ...に基づいて単一の呼び出しのコストを見積もるだけです。したがって、ダッシュボード上のコストは、正確な請求書ではなく、コスト見積もりのベースラインと見なすべきです。costが設定されていないモデルの場合、コスト列は 0 と表示されます。Qwen3.5-Plus モデルを例にとります。Alibaba Cloud Model Studio API 呼び出しのコストについては、「モデルリスト」をご参照ください。
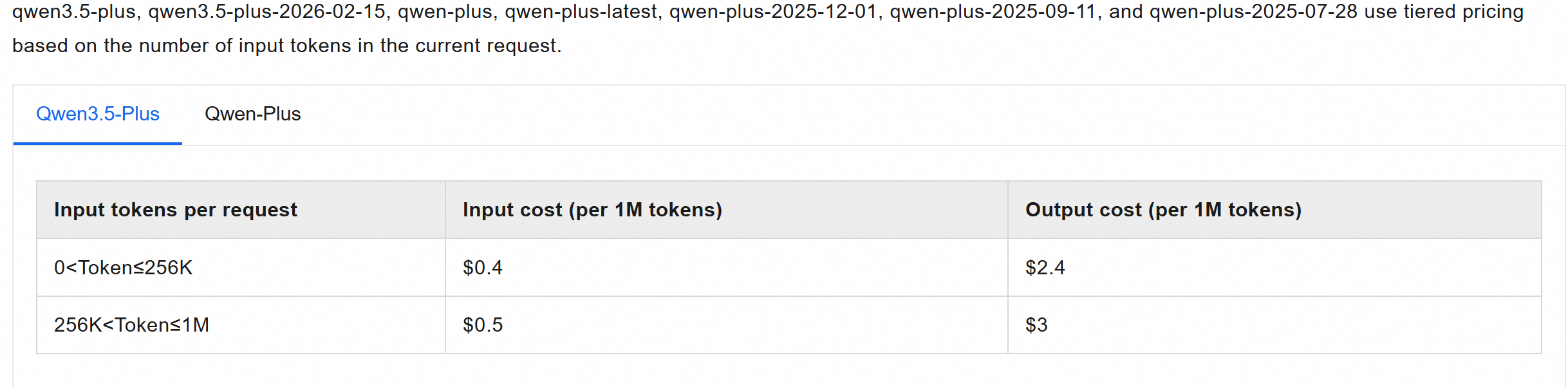
.openclaw のモデルコスト設定は次のとおりです:
{ "id": "qwen3.5-plus", "name": "Qwen3.5 Plus", "cost": { "input": 0.4, // 最低ティアの入力価格から "output": 2.4, // 最低ティアの出力価格から "cacheRead": 0.2, // 入力の半分と推定 "cacheWrite": 0 }, }全体概要とモデル分布
ダッシュボードの上部には、総トークン数と総コストの 1 日比較が表示されます:今日と昨日の使用量 (単位:1 万トークン)、今日と昨日のコスト (単位:CNY)、および前日比。これにより、使用量やコストが急増したかどうかを迅速に判断できます。前日比はコスト異常の最初のシグナルです。前日比が事前設定されたしきい値 (例:±30%) を超えた場合、通常はプロンプトの拡大、再帰呼び出し、または異常なセッションがあったことを意味し、すぐにドリルダウンして調査する必要があります。
プロバイダー/モデル別の消費トレンド (時系列)
モデルトークントレンドとモデルコストトレンドは、タイムラインと凡例を共有する 2 つの時系列グラフ (1 週間分) です。これらは、各モデルのトークン消費量とコストの変化を時間とともに示し、色で区別されます。トークンの急増には特に注意してください。これは単なるコストの問題ではなく、セキュリティと安定性のリスクシグナルであることがよくあります。プロンプトインジェクションによってコンテキストが悪意を持って埋められたり、ツール呼び出しが無限ループに陥ったり、ループ検出がトリガーされなかったためにセッションが継続的に拡大したりすると、すべてトレンドグラフのいずれかの曲線が急上昇として現れます。2 つのグラフはモデルごとに色分けされています。モデルの切り替えは色の構成の変化として直接反映され、追加の推論なしに切り替え時間と関連モデルを確認できるため、それが期待された変更であったかどうかを簡単に判断できます。
セッション別およびホスト/Pod 別のトップ消費 (縦棒グラフ)
縦棒グラフは 2×2 のレイアウトを形成し、セッションとホスト (またはコンテナシナリオでは Pod) のディメンションから「誰がお金を使っているのか?」と「どのマシンまたはコンテナがお金を使っているのか?」に答え、データを特定の責任エンティティに関連付けます:
セッション別トップトークン / セッション別トップコスト:過去 1 週間の各セッションの総トークン数とコストが降順でソートされます。実際には、エージェントのコスト分布はしばしばロングテール特性を示し、少数のセッションが消費の大部分を占めます。これらの「ヘッドセッション」を特定することが、コスト最適化の第一歩です。
ホスト別トップトークン / ホスト別トップコスト:ホスト (インスタンス) または Pod ごとに集計されたトークンとコストで、複数インスタンスのデプロイメントにおけるコスト分析とリスクの特定に使用されます。企業環境では、ホストまたは Pod は通常、特定のチーム、LOB、またはユーザーに関連付けられています。これを資産の所有者情報と組み合わせることで、消費データを特定の責任者にマッピングできます。これはコスト配分をサポートするだけでなく、インスタンスの消費が異常な場合に潜在的なリスクユーザーや制御不能なセッションを迅速に特定するのにも役立ちます。
モデルトークン詳細テーブル (コスト内訳)
詳細テーブル (1 週間分) には、各モデルについて次の項目がリストされます:
totalTokens、inputTokens、outputTokens、cacheReadTokens、cacheWriteTokens、およびそれらに対応するtotalCost、inputCost、outputCost、cacheReadCost、cacheWriteCost。ソートとフィルタリングをサポートしており、「どのモデルが最もお金を使ったか?」、「入出力はどれくらいの割合を占めたか?」に直接答えることができます。inputTokensとoutputTokensの比率は、エージェントの対話パターンを反映します:入力比率が高い場合は冗長なプロンプトやコンテキストを示唆し、出力比率が高い場合はモデルが多くの無効なコンテンツを生成している可能性があります。cacheReadTokensの比率は、キャッシュポリシーの利点を直接反映します。比率が高いほど実際の請求額は低くなり、プロンプトエンジニアリングとキャッシュチューニングの定量的な根拠を提供します。
行動分析ダッシュボード
行動分析ダッシュボードは、セッションを基本単位として使用し、OpenClaw の運用行動を記録および分類し、「現在のタイムウィンドウでエージェントは何をしたか?」という基本的かつ重要な質問に答えます。
セッション統計
上部のカウントカードは、ツール呼び出しをコマンド実行、バックグラウンドプロセス、ウェブ要求、通信ツール、ファイル読み書きなどの行動タイプ別に分類し、全体的な行動構成のクイックスナップショットを提供します。呼び出し例外は別途リストされ、システムの安定性を一目で判断しやすくします。
セッション統計テーブルはセッションごとに展開され、各行動ディメンションにおける各セッションの呼び出し数を記録します。スクリーンショットでは、最初のセッションのツール呼び出し総数は 1,925 に達し、そのうち 1,364 がコマンド実行、561 がファイル読み書きであり、他のセッションとは桁違いです。このような異常にアクティブなセッションは、優先的にレビューする価値があることが多いです。テーブルは最終アクティブ時間でソートされています。各ディメンションの呼び出し分布と組み合わせることで、異常な行動パターンを持つセッションを迅速に特定できます。
ツール呼び出し量統計とエラー分析
ツール呼び出しは、エージェントが外部と対話するための唯一のチャネルです。その呼び出し量とエラー率の変化は、エージェントの運用健全性を直接反映します。ツール呼び出しタイムラインは、各時間帯の呼び出し頻度の構成をツールタイプごとに色分けして示します。異常なスパイクは、トラブルシューティングの最初の入り口です。ツールタイプの構成の変化と組み合わせることで、どのタイプの操作が呼び出し急増を引き起こしたかを迅速に判断できます。エラー率トレンドグラフは、呼び出し量タイムラインとタイムラインを共有します。エラー率のピークは、必ずしも呼び出し量のピークと一致するわけではありません。2 つの時間差は、問題の真の原因を明らかにすることがよくあります:特定の期間中に特定のタイプのツールが継続的に失敗しているのか、それとも特定のタスクが異常な呼び出しパターンを導入したのか。
完全なツール呼び出しログは、各呼び出しのプロトコルエラー、実行ステータス、および戻り値のコンテンツを提供し、トレンドの異常から特定の失敗した呼び出しに迅速にドリルダウンして根本原因を特定できます。
外部との対話
外部との対話は、エージェントが運用中に開始したすべてのアウトバウンド行動を記録します。これには、API 呼び出し、ウェブアクセス、メッセージ送信、メール送信が含まれ、セッション、ツール名、対話タイプごとに提示および分類されます。
エージェントにとって、外部との対話はタスクを完了するための必要な手段であると同時に、潜在的なリスクの出口点でもあります。外部との対話行動の完全な記録は、一方で、チームがエージェントの実際の機能境界と使用習慣を理解するのに役立ちます。他方で、異常が発生したときに完全な行動コンテキストを提供し、クロスツール、クロスセッションの関連分析とトレーサビリティをサポートします。
ステップ 3:観測可能なデータをカスタムクエリで探索する
組み込みのダッシュボードは、汎用的な監査および観測ビューを提供します。実際のセキュリティ運用では、ダッシュボードはしばしば「問題を発見する」ための出発点であり、終点ではありません。監査ダッシュボードが高リスクセッションをフラグ付けしたり、トークントレンドグラフが異常なスパイクを示したり、運用メトリクスのアラートがトリガーされたりした場合、しばしば統計的な概要から特定のイベントへとさらにドリルダウンして、完全な行動連鎖を再構築し、根本原因を確認する必要があります。SLS のクエリと分析エンジンは、このプロセスのために柔軟なカスタム探索機能を提供します。
ログデータモデル:カスタム分析の基礎
データ構造を理解することは、カスタム探索の前提条件です。SLS 統合ソリューションは、監査分析のニーズに基づいてインデックスを事前構築しているため、ユーザーは追加の設定なしで直接クエリできます。次の 2 種類のログが、カスタム分析のコアデータソースを形成します:
セッションログ — エージェントの完全なビジネス行動を記録し、セキュリティ監査とコスト分析の主要な基盤です。これらは、ステップ 1:ログの取り込み (セッションログを例として) で取り込まれたログです。
フィールドパス
タイプ
監査分析の目的
__tag__:__session_id__text
一意のセッション識別子。セッションごとの分離と集約のためのキーフィールド。
typetext
エントリタイプ:
session(セッションメタデータ)、message(対話メッセージ)、またはcompaction(コンテキスト圧縮サマリー)。監査可能な対話レコードをフィルタリングするために使用されます。message.roletext
メッセージロール:
user(ユーザー入力)、assistant(モデル応答)、またはtoolResult(ツール戻り値)。行動主体を特定するために使用されます。message.contenttext
メッセージ本文。ユーザー入力、モデル出力、およびツールパラメーター/戻り値を含みます。インジェクション検出、機密データマッチング、および全文検索をサポートします。
message.providermessage.modeltext
モデルプロバイダーとモデル名。モデル別のコスト分析と行動統計に使用されます。
message.usage.totalTokensmessage.usage.cost.totallong / double
トークン使用量と推定コスト。異常な消費の検出とセッションレベルのコストソートに使用されます。
message.stopReasontext
応答終了理由:
stop(正常終了)、toolUse(ツール呼び出しがトリガーされ、次のエントリは通常 toolResult)、error/aborted/timeout(異常終了)。異常なセッションをフィルタリングするためのキーフィールド。message.toolNamemessage.isErrortext / bool
ツール呼び出し名と実行ステータス。
toolResultロールと組み合わせてツールレベルの監査に使用されます。id,parentIdtext
エントリ ID と親 ID。対話ツリーを構築し、メッセージの順序を復元するために使用されます。
sessionタイプのエントリのidは sessionId です。timestamptext
イベントタイムスタンプ。タイムウィンドウフィルタリング、ソート、およびアラート範囲の定義に使用されます。
ランタイムログ — ゲートウェイとさまざまなサブシステムの運用状態を記録します。これらは、トラブルシューティングとシステム健全性分析のデータ基盤です。
説明OpenClaw-実行時ログ カードを選択し、ステップ 1:ログの取り込み (セッションログを例として) の手順に従ってログを取り込みます。
フィールドパス
タイプ
監査分析の目的
_meta.logLevelNametext
ログレベル (TRACE / DEBUG / INFO / WARN / ERROR / FATAL)。異常トラブルシューティングのために ERROR と FATAL に焦点を当てるために使用されます。
_meta.pathtext
ソースコードのファイルパスと行番号。スタック分析のためにコードの場所と正確に関連付けます。
数値キー
"0"object (JSON)
構造化コンテキスト。通常、
subsystemフィールドを含みます (例:gateway、channels、telegram、またはplugins)。数値キー
"1"および後続のキーtext
ログメッセージの本文とスタックの本文。全文検索とキーワード一致をサポートします。
セッションレベルのドリルダウン:高リスクセッションから完全な行動連鎖へ
典型的なシナリオ: 監査ダッシュボードの「高リスクセッション」リストが高リスクセッションをフラグ付けします。セキュリティチームは、脅威が本物であるかを確認するために、そのセッションの完全な対話プロセスを再構築する必要があります。
複数インスタンスのデプロイメント環境では、各 OpenClaw インスタンスのログは同じ SLS Logstore に集中的に書き込まれます。カスタム探索の最初のステップは、セッション ID で分離してビューを単一のセッションに絞り込むことです。これにより、「誰がどのリクエストをトリガーし、どのツールを呼び出し、モデルがいつどのように応答したか」が明確になり、コンプライアンス証拠のための明確な境界が提供されます。
Simple Log Service コンソールにログインします。プロジェクト一覧 セクションで、送信先のプロジェクトを選択します。
ログ管理 セクションで、送信先の Logstore を見つけ、検索と分析 をクリックしてデータを探索します。クエリ
* AND __tag__:__session_id__:<Session_Id>を使用してログをフィルタリングします。<Session_Id>を実際のセッション ID に置き換えます。セッションをフィルタリングした後、Rawデータ ページの Raw Data タブに移動し、ターゲットのログを見つけて
 アイコンをクリックします。その後、コンテキストをプレビューし、セッション内の完全な行動連鎖を元の順序で再構築できます:ユーザー入力、モデル推論、ツール呼び出しリクエスト、およびツール実行結果。イベントのシーケンスが一目でわかります。この機能は、監査シナリオで特に重要です。異常な呼び出しシーケンス (機密ファイルを読み取った直後に漏洩操作を行うなど) を特定するのに役立つだけでなく、セキュリティインシデントを再現し、証拠を保全するための完全なコンテキストビューも提供します。
アイコンをクリックします。その後、コンテキストをプレビューし、セッション内の完全な行動連鎖を元の順序で再構築できます:ユーザー入力、モデル推論、ツール呼び出しリクエスト、およびツール実行結果。イベントのシーケンスが一目でわかります。この機能は、監査シナリオで特に重要です。異常な呼び出しシーケンス (機密ファイルを読み取った直後に漏洩操作を行うなど) を特定するのに役立つだけでなく、セキュリティインシデントを再現し、証拠を保全するための完全なコンテキストビューも提供します。
ランタイムのトラブルシューティング:キーワード検索と集約分析
典型的なシナリオ: 運用メトリクスダッシュボードがエラー率の急増を警告します。大量のランタイムログから障害のあるモジュールと根本原因を迅速に特定する必要があります。
SLS は、全文検索と構造化フィールド検索の組み合わせをサポートしています。時間範囲と組み合わせることで、調査範囲を段階的に絞り込むことができます。典型的なトラブルシューティングパスには 2 つのステップが含まれます:まず、範囲を絞り込み、次に分布を定量化します。
ステップ 1:段階的にフィルタリングして問題を特定する
ログレベルでフィルタリング:クエリ
_meta.logLevelName: ERROR OR _meta.logLevelName: WARN OR _meta.logLevelName: FATALを使用して、すべてのエラーログと警告ログをフィルタリングし、異常なイベントに注意を集中させます。サブシステムでドリルダウン:エラーログにフィールド条件を追加します。たとえば、
"0.subsystem": plugins。分析文は(_meta.logLevelName: ERROR OR _meta.logLevelName: WARN OR _meta.logLevelName: FATAL) AND "0.subsystem": pluginsとなります。これにより、範囲が特定のサブシステムに絞り込まれます。これらの 2 つのフィルタリングステップで、エラーログを迅速に特定できます。
ステップ 2:SQL 集約を使用してグローバルな分布を定量化する
キーワードフィルタリングは個々のイベントを特定しますが、SQL 集約分析は個々のログをグローバルな統計ビューに引き上げます。たとえば、分析文 _meta.logLevelName: ERROR OR _meta.logLevelName: WARN OR _meta.logLevelName: FATAL | SELECT "0.subsystem" AS subsystem, count(1) AS c GROUP BY subsystem を使用して subsystem フィールドをグループ化および集約すると、さまざまなサブシステムにわたるエラー分布を視覚的に提示できます。これにより、集中した異常を迅速に特定し、さらなる調査の方向性を示します。
ステップ 4:複数のデータソースを関連付けて、異常検知から根本原因分析までのクローズドループプロセスを実現する
これまで、観測可能なデータに基づいたデータインジェスト、組み込みダッシュボード、カスタム探索について紹介してきました。実際の O&M と監査では、観測可能なデータソースは単独で使用されるのではなく、固定された協調パターンに従い、段階的に収束し、相互に検証します:
OTEL メトリクス → アプリケーションログ (エラーコンテキスト) → セッション監査ログ (完全な行動連鎖)。典型的な調査パスは次のとおりです:OTEL メトリクスが異常を検出します (レイテンシの急増、トークンの急増、エラー率の急増など)。次に、対応するタイムウィンドウのアプリケーションログでエラーの詳細を特定します (Webhook のタイムアウト、認証の失敗、ゲートウェイの異常)。最後に、セッション監査ログにドリルダウンして、そのセッションの完全なツール呼び出しシーケンス、モデルの対話内容、およびコスト消費を再構築し、根本原因を確認して監査証拠を保全します。