rate および increase 関数の結果が異常に大きな値になることがあるのはなぜですか?
これらの関数は、値が時間とともに増加する、増加するメトリックデータにのみ適用されます。この異常は、Prometheus Engine のソースコードで説明できます。
以下のスクリーンショットは、rate および increase 関数がタイムウィンドウにわたって結果を計算する方法を示しています。まず、最初の 2 つの値の差が resultFloat に割り当てられます。後続の値が減少すると、前の値 (prevValue) が resultFloat に追加され、最終的に異常に大きな値になります。

トラブルシューティング
PromQL を使用して値の減少を確認します。まず、時間フィルターを異常が発生した期間に絞り、次の PromQL クエリを実行します (
xxxx_metricを実際のメトリック名に置き換えます)。結果セットにデータポイントが含まれている場合、これは「値の減少」を示します。Query: (xxxx_metric{} - xxxx_metric{} offset 1s) < 0 Step: 1s異常な値を持つ時間枠について、次のような SQL を使用して元のデータポイントを取得します。
* | select *, from_unixtime(__time_nano__/1000000.0) from "metricstore_name.prom" where __name__='metric_name' and element_at(__labels__, 'filter_labelKey')='filter_labelValue' order by __time_nano__説明SQL で複数の
element_at関数を使用して、時間枠をさらに絞り込むことをお勧めします。SQL の結果セットはタイムスタンプでソートされているため、誤った生データポイントを簡単に観察できます。
特定の Metricstore にメトリックがすでに書き込まれているのに、PromQL 文を実行してもデータがクエリされない場合はどうすればよいですか?
次のシナリオで対応する問題が存在するかどうかを確認します。
シナリオ 1: 指定された PromQL 文の構文が有効かどうかを示すために、構文解析ステータスが Metricstore の検索ボックスに自動的に表示されます。構文が無効な場合は、プロンプトに従って修正します。

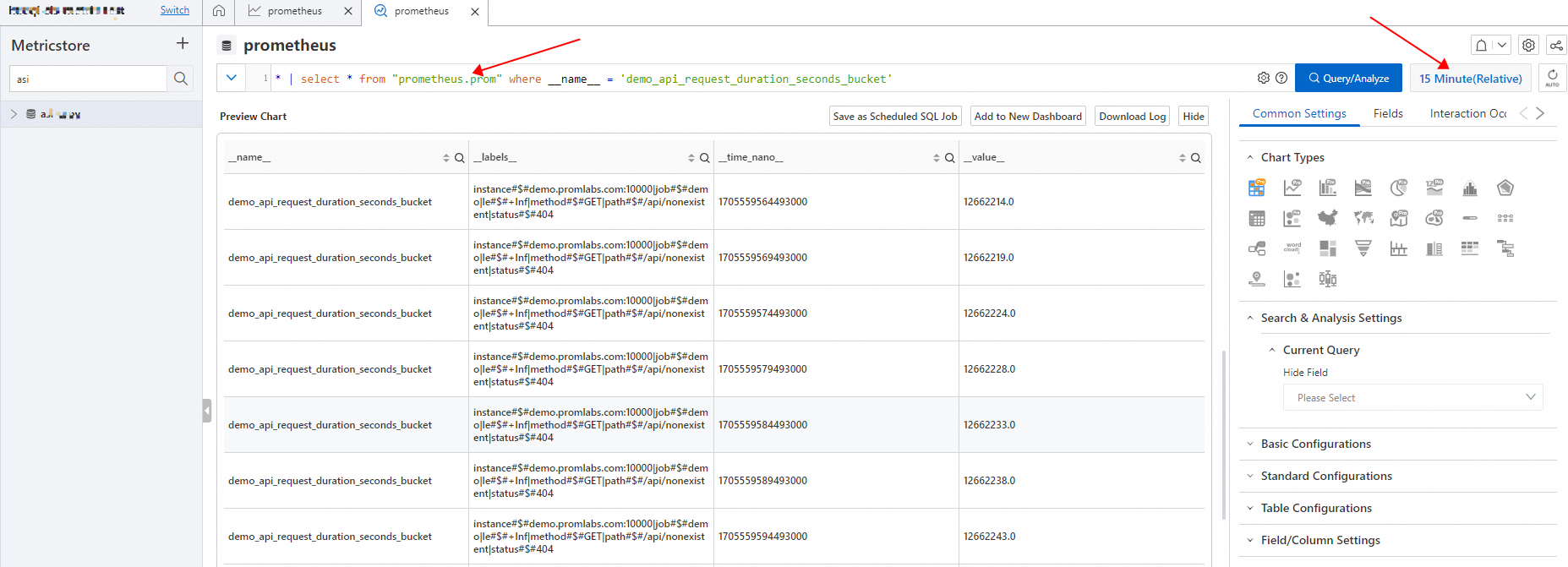
シナリオ 2: 次の図に示すように、Metricstore のカスタム分析ページに移動します。検索ボックスで、次の SQL 文を実行して、指定された期間内にデータが存在するかどうかを確認します。
SQL 文の
__name__フィールドはメトリック名を指定します。* | select * from "<Metricstore name>.prom" where __name__ = 'demo_api_request_duration_seconds_bucket'
前の 2 つのシナリオで問題が発生しない場合、このエラーは Prometheus Query コンピュートエンジンのベクター選択ロジックと lookback-delta メカニズムが原因で発生します。
Prometheus Query コンピュートエンジンは、PromQL という名前のクエリ言語を提供します。PromQL を使用してデータをクエリする場合、すべてのデータポイントが計算されるわけではありません。各クエリ操作が実行される前に、ベクター選択操作が実行されます。PromQL 構文でサポートされているすべてのオペレーターと関数は、ベクター選択プロセスに基づいて、[1m] や [1h] などの時間期間で終わる範囲ベクターセレクターと、瞬時ベクターセレクターのカテゴリに分類できます。詳細については、「Range Vector Selectors」および「Instant vector selectors」をご参照ください。
次のサンプルコードは、ベクターセレクターの使用方法の例を示しています。
RangeVectorSelector:
rate(http_requests_total[5m])
delta(http_requests_total[5m])
count_over_time(http_requests_total[5m])
InstantVector:
http_requests_total
absent(http_requests_total)
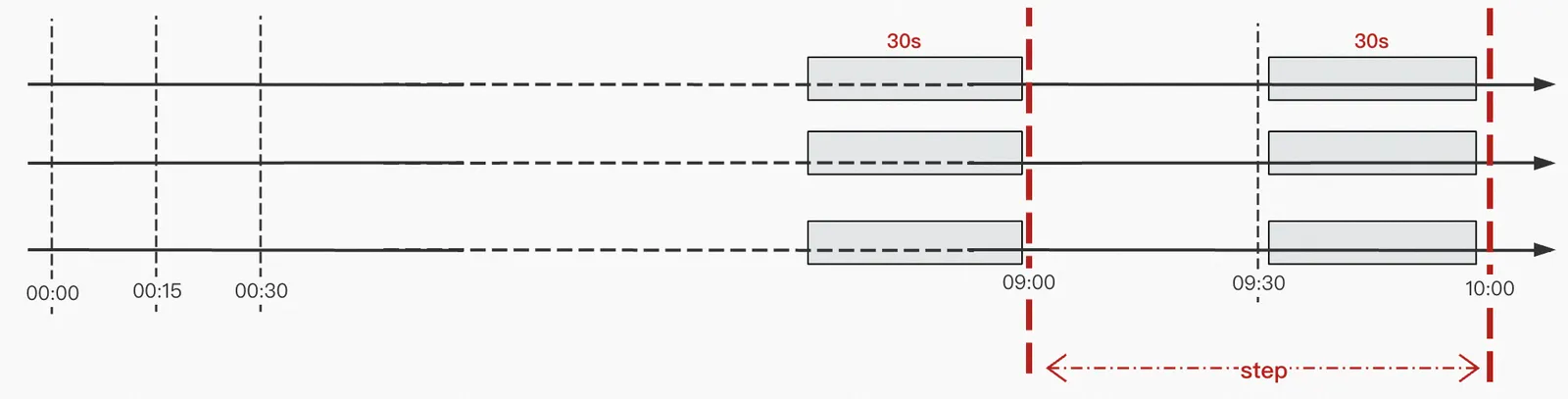
count(http_requests_total)範囲ベクターセレクターは、次の図に示すように、[xx] オペレーターで指定された時間範囲内のすべてのデータポイントを計算することによって、サンプルの範囲を選択します。オペレーター count_over_time ( up [30s] ) は、過去 30 秒以内のすべてのデータポイントが計算されることを示します。
PromQL の lookback-delta メカニズムは、瞬時ベクターセレクターに対してのみ有効です。瞬時ベクターセレクターは、lookback-delta パラメーターの値に基づいて特定の時間間隔内のデータを遡って検索し、最も近い時点のデータポイントを現在の時点の値として使用します。ほとんどの場合、生データの書き込み時間とクエリ時間は一致しません。特定の時点のデータ値をクエリする場合、選択した時点より前の n 分以内のデータポイントが遡って検索され、最も近い時点のデータポイントが現在の時点の値として使用されます。デフォルトでは、Simple Log Service は選択した時点より前の 3 分以内のデータポイントを遡って検索します。関連パラメーターの変更方法については、「メトリッククエリ API」をご参照ください。
この例では、クエリの startTime は 00:09:28 です。この時点で生のデータポイントが存在しない場合、システムは 00:09:28 より前の 3 分以内のデータを遡って検索します。00:06:28 から 00:09:28 までデータが書き込まれていない場合、00:09:28 のデータポイントは選択されません。同様に、クエリ時間 00:09:43 に対しては 00:09:40 のデータポイントが選択され、クエリ時間 00:09:58 に対しては 00:09:55 のデータポイントが選択されます。
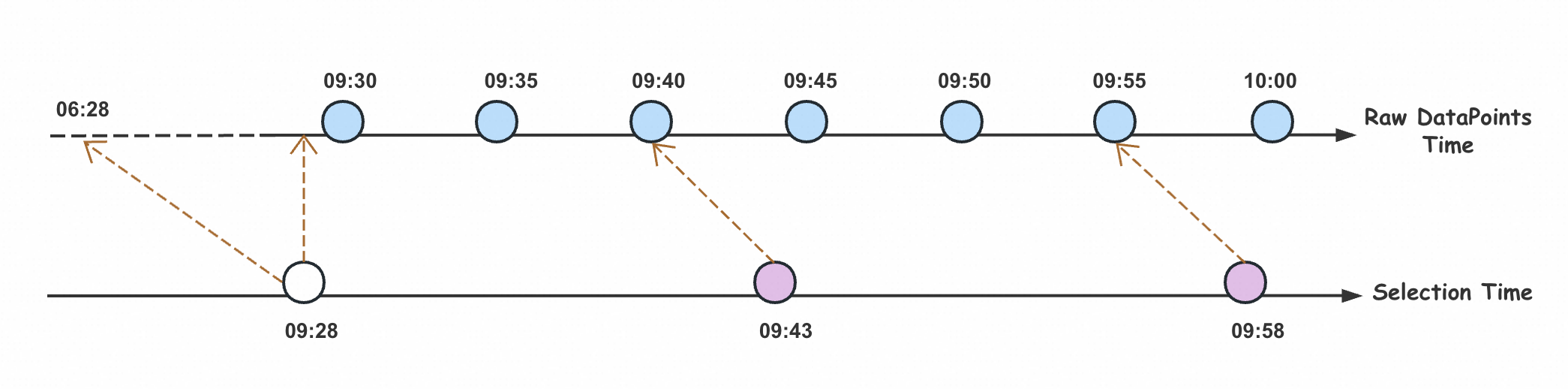
ただし、このメカニズムに基づいて次の特別なシナリオが存在します。期間内にデータポイントが存在しなくても、PromQL 文を使用して特定の期間内にデータがクエリされます。この例では、00:10:00 以降にデータは存在しません。00:10:13、00:10:28、00:10:43、および 00:12:58 にデータをクエリすると、システムは lookback-delta メカニズムに基づいてクエリ時間の 3 分前のデータを遡って検索し、先行するクエリに対して 00:10:00 のデータポイントを返します。

瞬時ベクターセレクターと範囲ベクターセレクターは、異なるベクター選択ロジックを使用します。データがクエリされない場合は、次のシナリオに基づいてエラーのトラブルシューティングを行うことができます。
RangeVectorSelector
[xx]オペレーターで指定された時間間隔が短く、stepパラメーターで指定されたステップサイズが大きい場合。この場合、各計算操作の前にセレクターによってデータポイントが選択されないことがあります。たとえば、
upメトリックの生データは毎正時に書き込まれます。次のクエリパラメーターを設定します。startTime: 10:30:00 endTime : 18:30:00 step : 1h query : count_over_time(up[10m])この例では、7 つのデータポイントを含む応答が期待されますが、実際のクエリ結果は空です。原因: 計算操作は startTime からステップごとに 1 回実行されます。データは 11:30:00、12:30:00、13:30:00、14:30:00、15:30:00、16:30:00、17:30:00、および 18:30:00 に計算されます。各計算操作の前に、セレクターは各クエリ時間の 10 分前のデータを遡って検索します。ただし、指定された時間間隔にデータポイントは存在しません。
InstantVectorSelector
lookback-deltaパラメーターの値が小さく、stepパラメーターで指定されたステップサイズが大きい場合。この場合、各計算操作の前にセレクターによって最も近いデータポイントが選択されないことがあります。たとえば、
upメトリックの生データは毎正時に書き込まれます。次のクエリパラメーターを設定します。startTime: 10:30:00 endTime : 18:30:00 step : 1h query : count(up)Prometheus では、
lookback-deltaパラメーターのデフォルト値は 5 分です。Simple Log Service Metricstores では、デフォルト値は 3 分です。この例では、データは 11:30:00、12:30:00、13:30:00、14:30:00、15:30:00、16:30:00、17:30:00、および 18:30:00 に計算されます。各計算操作の前に、セレクターは各クエリ時間の 3 分前のデータを遡って検索し、最も近い時点のデータポイントを指定されたクエリ時間の値として選択します。生データポイントの分布がまばらなため、指定された時間間隔にデータポイントが見つかりません。その結果、クエリ結果も空になります。
ソリューション
クエリパラメーターの
startTime、endTime、およびstepパラメーターを変更し、パラメーター設定をデータ書き込み時間と一致させます。これにより、指定されたデータ書き込み時間のデータポイントを選択できます。この例では、クエリに対して 7 つのデータポイントが返されます。実際のシナリオでは、メトリックポイントの書き込み時間は不規則です。そのため、クエリパラメーターの設定が常に書き込み時間と一致するとは限りません。このソリューションは採用しないことをお勧めします。
startTime: 10:00:00 endTime : 18:00:00 step : 1h query : count(up)step パラメーターに小さい値を指定します。たとえば、前述の InstantVectorSelector シナリオで step パラメーターを 3 分に設定します。これにより、選択操作がより高い頻度で実行されます。このソリューションは、生のデータポイントがまばらに分布している場合でもデータポイントを選択できるように、選択操作の数を増やします。
lookback-delta パラメーターまたは [xx] オペレーターに大きい値を指定します。これにより、選択の時間間隔が十分に大きくなり、より多くの生のデータポイントの書き込み時間を含めることができます。
特定の時点以降にデータが書き込まれていないにもかかわらず、PromQL 文を使用してその時点以降のデータがクエリされる場合はどうすればよいですか?
このエラーは、Prometheus の lookback-delta メカニズムが原因で発生します。
クエリ結果のデータポイントのタイムスタンプが書き込み時間と一致しないのはなぜですか?
このエラーは、Prometheus の lookback-delta メカニズムが原因で発生します。
同じ時間範囲でも、最新の結果と過去の結果が異なるのはなぜですか?
2 つの可能性があります。
時間フィルターが「相対時間」に設定されている場合、開始パラメーターと終了パラメーターの変更により、「lookback-delta」操作中に異なるデータポイントが選択され、結果が不整合になることがあります。この動作は Prometheus では標準であり、正常と見なされます。
2 つの実行が大幅に間隔を空けて行われ、同じ時間範囲を共有している場合、過去のクエリ中に (書き込み遅延のため) 期待されるすべてのデータポイントが Simple Log Service 側に到着していなかった可能性があります。計算に使用されるデータの違いが、不整合な結果につながることがあります。この場合、PromQL の
offset構文を使用してクエリウィンドウを後ろにずらし、書き込み遅延によるエラーを修正できます。
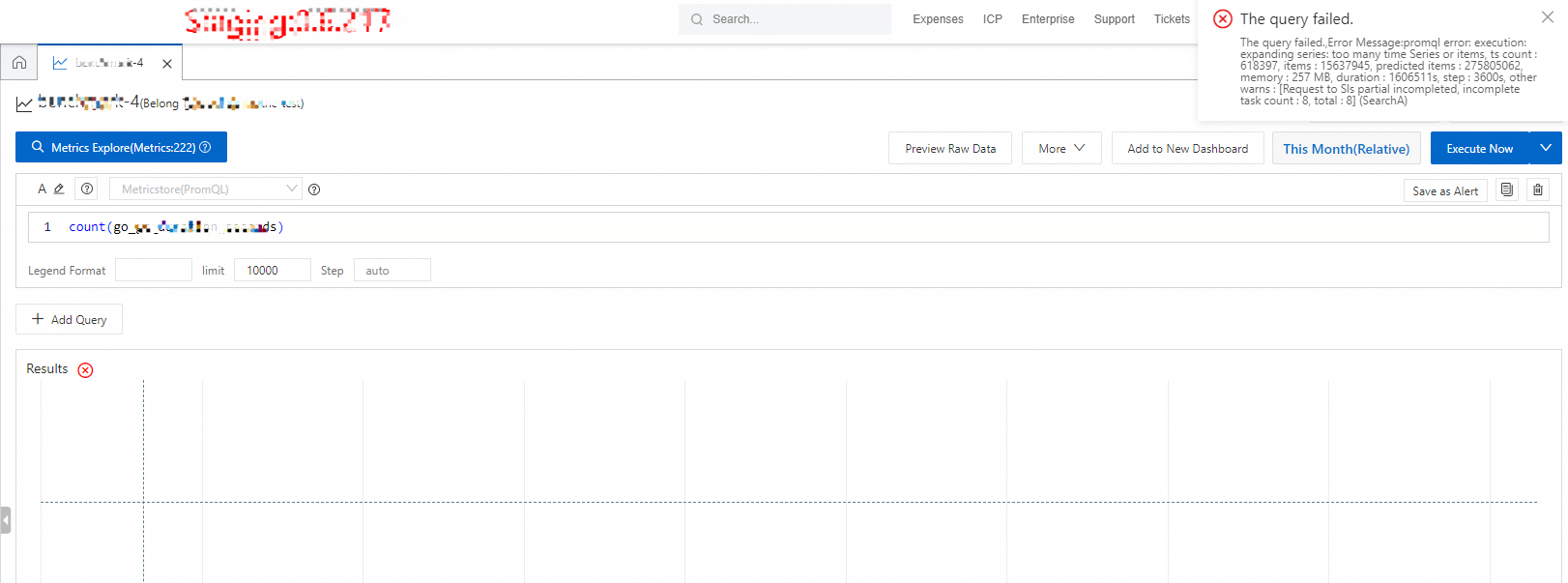
消費されたコンピュートリソースがクエリあたりの上限を超えたためにクエリリクエストが拒否された場合はどうすればよいですか?
クエリ応答に「too many time Series or items, xxxxxx」や「too many time Series or items in parallelMaster node, xxxxx」などのエラーメッセージが含まれている場合、クエリは大量のデータを読み取り、コンピューティングレイヤーでメモリ制限をトリガーしています。
ソリューション
クエリの時間範囲を小さく指定します。
実行時間が指定された時間枠に大きく依存する場合は、同時コンピューティングを有効にすることをお勧めします。
「vector cannot contain metrics with the same labelset」というエラーメッセージが表示された場合はどうすればよいですか?
原因 1:
__labels__フィールドの値のラベル名がアルファベット順にソートされていません。Metricstore に書き込まれる
__labels__フィールドの値は、複数のラベルで構成されます。各ラベルには、<ラベル名>#$#<ラベル値> の形式でラベル名とラベル値が含まれます。複数のラベルは縦棒 (|) で区切られます。メトリック識別子のラベルは、ラベル名でアルファベット順にソートする必要があります。詳細については、「メトリック識別子」をご参照ください。__labels__フィールドの値のラベル名がアルファベット順にソートされていない場合、このエラーが発生します。次の SQL 文を実行して、__labels__フィールドの値のラベル名がアルファベット順にソートされているかどうかを確認できます。* | select * from ( select __labels__, array_join(array_sort(split(__labels__, '|')), '|') as rightLabels from "<Metricstore name>.prom" where __name__!='' ) where __labels__ != rightLabels原因 2:
__labels__フィールドの値に空のラベル値が存在します。Prometheus エンジンは、空の値を持つラベルを無効と見なします。Prometheus エンジンは、計算中に無効なラベルを削除します。次の手順を実行して、
__labels__フィールドの値に空のラベル値が存在するかどうかを確認できます。クエリの時間範囲を小さく指定して、このエラーが発生するおおよその時間間隔を見つけます。
次の SQL 文を実行します。
* | select __labels__ from "<Metricstore name>.prom" where __name__!='' and regexp_like(__labels__, '.*#\$#\|.*|.*#\$#$')結果が返された場合、空のラベル値が存在します。データレポートを実装するために使用されるコードを変更して、無効なラベルを削除することをお勧めします。
生データに存在するラベル情報が PromQL 文を実行してもクエリできない場合はどうすればよいですか?
__labels__ フィールドの値のラベル名がアルファベット順にソートされていない場合、このエラーが発生します。次の SQL 文を実行して、__labels__ フィールドの値のラベル名がアルファベット順にソートされているかどうかを確認できます。
* | select * from (
select __labels__, array_join(array_sort(split(__labels__, '|')), '|') as rightLabels from "<Metricstore name>.prom" where __name__!=''
) where __labels__ != rightLabelsby または without 句を含む PromQL 文によって予期しない結果が返された場合はどうすればよいですか?
__labels__ フィールドの値のラベル名がアルファベット順にソートされていない場合、このエラーが発生します。次の SQL 文を実行して、__labels__ フィールドの値のラベル名がアルファベット順にソートされているかどうかを確認できます。
* | select * from (
select __labels__, array_join(array_sort(split(__labels__, '|')), '|') as rightLabels from "<Metricstore name>.prom" where __name__!=''
) where __labels__ != rightLabelsメトリック探索に利用できるデータがない場合はどうすればよいですか?
考えられる原因は、デフォルトのクエリ時間範囲内にデータが存在しないことです。
指定された時間範囲内にデータが存在することを確認してください。
探索の応答速度を上げるため、探索のクエリ時間範囲はデフォルトで過去 5 分間です。

クエリされたメトリックデータで多数の時系列が欠落している場合はどうすればよいですか?
Simple Log Service コンソールで Metricstore のクエリおよび分析ページでクエリ操作を実行する場合、[limit] パラメーターを使用して、SQL または PromQL 文によって返されるデータ量を制御します。このパラメーターの値を増やすことをお勧めします。

PromQL の計算結果に Warning キーワードが存在する場合はどうすればよいですか?
考えられる原因は、データプル中に最大シャード読み取り容量に達したため、指定されたクエリ時間範囲内のデータの読み取りに失敗したことです。クエリ時間範囲を小さくするか、シャードを分割して全体のスループットを向上させることをお勧めします。

「exceeded maximum resolution of 11,000 points per timeseries. Try decreasing the query resolution (?step=XX)」というエラーメッセージが表示された場合はどうすればよいですか?
Prometheus では、各時系列に最大 11,000 個のサンプルを含めることができます。(endTime - startTime)/step の最大値は 11000 です。クエリの時間範囲を小さくするか、[step] パラメーターに大きい値を指定することをお勧めします。
