CLB は、ヘルスチェックを使用してバックエンドサーバーの可用性を判断します。バックエンドサーバーが異常になった場合、CLB はそのサーバーへのリクエストの送信を停止し、正常なサーバーにリクエストを分散します。サーバーが回復すると、CLB はそのサーバーへのトラフィック転送を再開します。このヘルスチェックメカニズムにより、個々のサーバーの障害がアプリケーションに影響を与えるのを防ぎ、サービス全体の可用性を向上させます。
サービスの負荷に敏感な場合、頻繁なヘルスチェックは通常のサービストラフィックに影響を与える可能性があります。ヘルスチェックの頻度を下げたり、ヘルスチェックの間隔を長くしたり、レイヤー 7 からレイヤー 4 のヘルスチェックに切り替えたりすることで、この影響を軽減できます。ただし、継続的なサービス可用性を確保するため、ヘルスチェックを無効にしないことを推奨します。
ヘルスチェックのプロセス
ヘルスチェックは、定期的にリクエストを送信することでサーバーのステータスを確認します。
CLB はクラスターにデプロイされます。このクラスター内のノードは、データ転送とヘルスチェックの両方を実行します。バックエンドサーバーがヘルスチェックに失敗した場合、CLB はその異常なサーバーへの新しいクライアントリクエストの分散を停止します。
CLB は、ヘルスチェックに `100.64.0.0/10` の CIDR ブロックを使用します。バックエンドサーバーは、このアドレス範囲からのトラフィックをブロックしてはなりません。ECS セキュリティグループに許可ルールを追加する必要はありませんが、iptables などの他のセキュリティポリシーを設定している場合は、この CIDR ブロックからのトラフィックを許可する必要があります。`100.64.0.0/10` の範囲は Alibaba Cloud の予約済みアドレス空間であり、セキュリティリスクはありません。
バックエンド ECS のセキュリティグループ保護に関するベストプラクティス
攻撃者が CLB をバイパスしてバックエンド ECS インスタンスのパブリック IP に直接アクセスするのを防ぐため、ECS セキュリティグループのインバウンドルールを設定することを推奨します。これらのルールは、サービスポートへのトラフィックを必要な CIDR ブロックからのみ許可し、インターネットからの直接リクエストを拒否するように設定する必要があります。以下の設定を推奨します:
-
CLB のヘルスチェックとトラフィック転送に使用される `100.64.0.0/10` の CIDR ブロックは、バックエンド ECS セキュリティグループのインバウンドルールによって制限されません。CLB からバックエンド ECS インスタンスへのトラフィックは常に許可されるため、この CIDR ブロックに対して特定の許可ルールを追加する必要はありません。
-
ECS セキュリティグループのインバウンドルールで、サービスポート (80 や 443 など) へのアクセスを VPC の CIDR ブロックからのみ許可します。サービスポートへのアクセスをインターネット (`0.0.0.0/0`) から許可しないでください。
-
この設定が完了すると、セキュリティグループは ECS インスタンスのサービスポートへのインターネットからの直接リクエストをブロックします。CLB によって転送される通常のトラフィックは影響を受けません。
HTTP および HTTPS のヘルスチェック
レイヤー 7 リスナー (HTTP/HTTPS) は、`HEAD` または `GET` リクエストを使用してヘルスチェックを実行します。
HTTPS リスナーの場合、証明書は CLB によって管理されます。CLB はパフォーマンスを向上させるため、バックエンドサーバーとのデータ交換に HTTP を使用します。
レイヤー 7 リスナーのヘルスチェックは次のように機能します:
-
CLB はバックエンドサーバーに HTTP `HEAD` リクエストを送信します。
-
バックエンドサーバーは HTTP ステータスコードを返します。
-
CLB が応答タイムアウト内に応答を受信しない場合、ヘルスチェックは失敗します。
-
CLB が応答タイムアウト内に応答を受信した場合、ステータスコードを設定された正常ステータスコードと比較します。コードが一致すればチェックは成功し、そうでなければ失敗します。
デフォルトでは、CLB のヘルスチェックは HTTP 2xx および 3xx ステータスコードのみを正常と見なします。バックエンドサーバーが 4xx (400、403、404、429 など) または 5xx (500、502、503 など) のステータスコードを返した場合、ヘルスチェックは失敗します。
4xx や 5xx のコードを正常ステータスコードのリストに追加するのではなく、/health のような専用のヘルスチェックエンドポイントを作成し、HTTP 200 ステータスコードを返すようにすることを推奨します。
TCP のヘルスチェック
レイヤー 4 の TCP リスナーの場合、CLB は次の図に示すように、カスタマイズされた TCP プローブを使用してサーバーのステータスをチェックします。
TCP リスナーのヘルスチェックは次のように機能します:
-
レイヤー 4 クラスターのノードが、バックエンドサーバーの内部 IP とヘルスチェックポートに TCP `SYN` パケットを送信します。
-
リクエストを受信後、サーバーがポートで正しくリッスンしている場合、`SYN+ACK` パケットを返します。
-
レイヤー 4 クラスターのノードが応答タイムアウト内にバックエンドサーバーから応答を受信しない場合、ヘルスチェックは失敗します。その後、ノードは `RST` パケットを送信して TCP 接続を終了します。
-
レイヤー 4 クラスターのノードが応答タイムアウト内にバックエンドサーバーから応答を受信した場合、ヘルスチェックは成功します。その後、ノードは `RST` パケットを送信して TCP 接続を終了します。
このメカニズムにより、バックエンドサーバーが TCP 接続を異常とみなし、アプリケーションログに Connection reset by peer のようなエラーを記録することがあります。
回避策:
-
TCP リスナーの場合、HTTP ベースのヘルスチェックを使用します。
-
バックエンドサーバーが実際のクライアント IP を取得するように設定した後、CLB サービスのアドレスブロックからの接続エラーを無視します。
UDP のヘルスチェック
レイヤー 4 の UDP リスナーの場合、ヘルスチェックは次の図に示すように、UDP パケットプローブを使用してサーバーのステータスをチェックします。
UDP リスナーのヘルスチェックは次のように機能します:
-
レイヤー 4 クラスターのノードが、バックエンドサーバーの内部 IP とヘルスチェックポートに UDP パケットを送信します。
-
バックエンドサーバーがそのポートでリッスンしていない場合、そのオペレーティングシステムは
port XX unreachableのような ICMP エラーメッセージを返します。それ以外の場合、サーバーは応答しません。 -
レイヤー 4 クラスターのノードが応答タイムアウト内にバックエンドサーバーからこのエラーメッセージを受信した場合、ヘルスチェックは失敗します。
-
レイヤー 4 クラスターのノードが応答タイムアウト内にバックエンドサーバーから何の応答も受信しない場合、ヘルスチェックは成功します。
UDP サービスの場合、ヘルスチェックのステータスが実際のサービスステータスと常に一致するとは限りません。
バックエンドサーバーが Linux サーバーの場合、高同時実行シナリオでは Linux の ICMP フラッド保護メカニズムがトリガーされ、サーバーが ICMP メッセージを送信するレートが制限されることがあります。この場合、サービスが停止していても、サーバーは port XX unreachable ICMP エラーを返せない可能性があります。その結果、CLB が ICMP 応答を受信しないと、ヘルスチェックを誤って成功とマークしてしまいます。これにより、報告されたヘルスステータスと実際のサービスステータスの間に不一致が生じます。
回避策:
ロードバランサーがバックエンドサーバーに特定の文字列を送信し、特定の応答を受信した場合にのみチェックが成功したと見なすように設定します。このメカニズムには、バックエンドアプリケーション側のサポートが必要です。
ヘルスチェックのタイムウィンドウ
ヘルスチェックメカニズムはサービスの可用性を向上させます。しかし、頻繁なステータス変更によるシステムの不安定化を防ぐため、CLB は、ヘルスチェックのタイムウィンドウ内で指定された回数のヘルスチェックに連続して成功または失敗した後にのみ、サーバーのステータスを変更します。このタイムウィンドウは、次の 3 つの要因によって決まります:
-
ヘルスチェック間隔 (ヘルスチェックが実行される頻度)
-
応答タイムアウト (ヘルスチェックに応答するサーバーを待つ時間)
-
チェックしきい値 (ステータス変更に必要な連続成功または失敗の回数)
ヘルスチェックのタイムウィンドウは次のように計算されます:
-
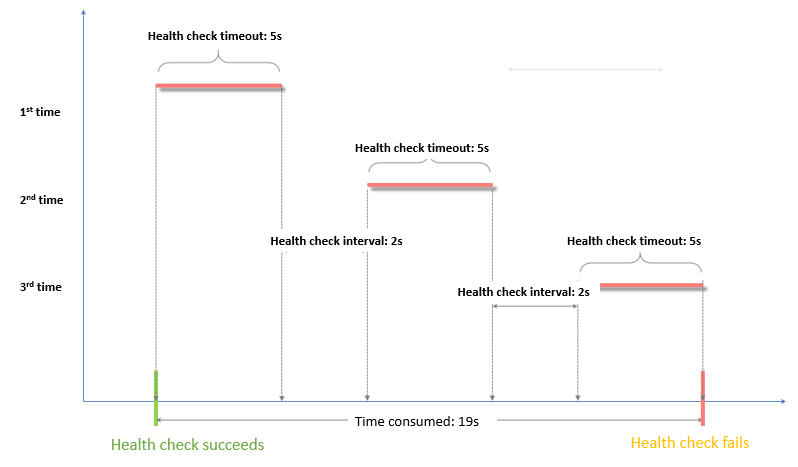
ヘルスチェック失敗のウィンドウ = 応答タイムアウト × 異常しきい値 + ヘルスチェック間隔 × (異常しきい値 - 1)
-
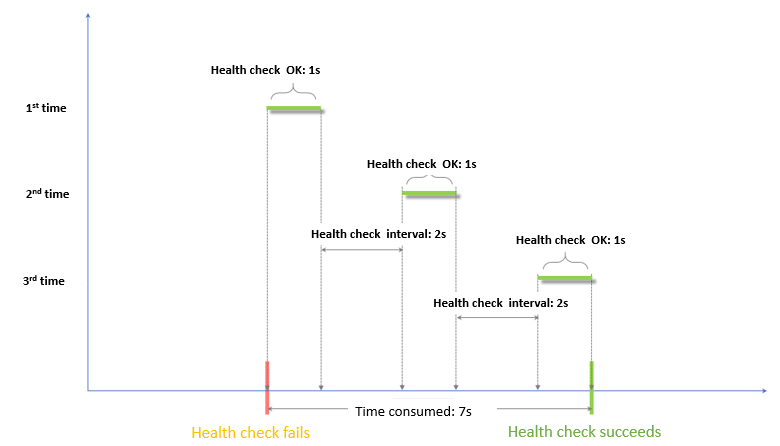
ヘルスチェック成功のウィンドウ = (ヘルスチェック成功の応答時間 × 正常しきい値) + ヘルスチェック間隔 × (正常しきい値 - 1)
説明ヘルスチェック成功の応答時間とは、ヘルスチェックリクエストを送信してから応答を受信するまでの時間です。TCP ヘルスチェックの場合、この時間はごくわずかです。HTTP ヘルスチェックの場合、この時間はサーバーのパフォーマンスと負荷に依存しますが、通常は 1 秒以内です。
ヘルスチェックのステータスは、リクエストの転送に次のように影響します:
-
ターゲットのバックエンドサーバーがヘルスチェックに失敗した場合、新しいリクエストはそのサーバーに分散されなくなります。このリダイレクトは、新しいクライアントに対して透過的です。
-
ターゲットのバックエンドサーバーがヘルスチェックに成功した場合、新しいリクエストはそのサーバーに分散され、クライアントのアクセスは正常になります。
-
バックエンドサーバーがヘルスチェックに失敗しているが、まだ異常しきい値 (デフォルトでは 3 回連続の失敗) に達していない場合、CLB はそのサーバーにリクエストを送信し続けます。これにより、クライアントリクエストが失敗する可能性があります。
ヘルスチェック設定の例
この例では、次のヘルスチェック設定を使用します:
-
応答タイムアウト: 5 秒
-
ヘルスチェック間隔: 2 秒
-
正常しきい値: 3
-
異常しきい値: 3
ヘルスチェック失敗のウィンドウは、応答タイムアウト × 異常しきい値 + ヘルスチェック間隔 × (異常しきい値 - 1) で計算されます。指定された値を使用すると、5 × 3 + 2 × (3 - 1) = 19 秒となります。これは、最初のヘルスチェック失敗の開始からサーバーが異常とマークされるまでの合計時間です。
ヘルスチェック成功のウィンドウは、(ヘルスチェック成功の応答時間 × 正常しきい値) + ヘルスチェック間隔 × (正常しきい値 - 1) で計算されます。成功の応答時間を 1 秒と仮定すると、(1 × 3) + 2 × (3 - 1) = 7 秒となります。これは、最初のヘルスチェック成功の開始からサーバーが正常とマークされるまでの合計時間です。
ヘルスチェック成功の応答時間とは、ヘルスチェックリクエストを送信してから応答を受信するまでの時間です。TCP ヘルスチェックの場合、ポートが有効かどうかをプローブするだけなので、この時間はごくわずかです。HTTP ヘルスチェックの場合、この時間はアプリケーションサーバーのパフォーマンスと負荷に依存しますが、通常は 1 秒以内です。
HTTP ヘルスチェックにおけるドメイン名
HTTP ヘルスチェックを設定する際、オプションでドメイン名を指定できます。一部のアプリケーションサーバーでは、リクエストに `host` ヘッダーが存在する必要があります。ご利用のサーバーにこの要件がある場合は、ドメイン名を設定する必要があります。CLB はこのドメイン名をヘルスチェックリクエストの `host` ヘッダーに追加します。このヘッダーがない場合、サーバーがリクエストを拒否し、ヘルスチェックが失敗する可能性があります。
したがって、アプリケーションサーバーが `host` フィールドを検証する場合は、ヘルスチェックが成功するようにドメイン名を設定してください。
参考資料
-
リスナーを追加する際にヘルスチェックを設定します。具体的な手順については、「CLB ヘルスチェックの設定と管理」をご参照ください。
-
ヘルスチェックに関するよくある質問については、「CLB ヘルスチェックに関するよくある質問」をご参照ください。