Classic Load Balancer (CLB) は、バックエンドサーバーの可用性を確認するためにヘルスチェックを実行します。ヘルスチェックが有効になっている場合、バックエンドサーバーが異常と判断されると、CLB はリクエストを他のバックエンドサーバーに分散します。異常なバックエンドサーバーが正常になると、リクエストはバックエンドサーバーにフェールバックされます。ヘルスチェックは、単一障害点(SPOF)を防ぐことができるため、アプリケーションの可用性を向上させます。
トラフィックの変動に非常に敏感なビジネスの場合、頻繁なヘルスチェックはビジネスの可用性に影響を与える可能性があります。ヘルスチェックがビジネスに及ぼす悪影響を軽減するために、ヘルスチェックの頻度を減らす、ヘルスチェックの間隔を増やす、またはレイヤー 7 ヘルスチェックをレイヤー 4 ヘルスチェックに変更することができます。業務継続性を確保するために、ヘルスチェック機能を有効にすることをお勧めします。
ヘルスチェックの仕組み
ヘルスチェックとは、バックエンドサーバーに定期的にリクエストを送信して、サーバーの状態を確認することです。
CLB インスタンスはクラスターにデプロイされます。クラスター内のノードは、ネットワークトラフィックの転送とヘルスチェックの実行を担当します。
クラスター内のノードによって実行されたヘルスチェックでバックエンドサーバーが失敗した場合、バックエンドサーバーは異常と判断されます。クラスター内のすべてのノードは、異常なバックエンドサーバーへのリクエストの配信を停止します。
CLB ヘルスチェックは CIDR ブロック 100.64.0.0/10 を使用します。これはバックエンドサーバーによってブロックすることはできません。 iptables などのセキュリティルールを構成していない限り、CIDR ブロック 100.64.0.0/10 からのアクセスを許可するセキュリティグループルールを構成する必要はありません。この CIDR ブロックは Alibaba Cloud によって予約されているため、100.64.0.0/10 を許可しても潜在的なリスクは増加しません。
CLB が HTTP および HTTPS ヘルスチェックを実行する方法
レイヤー 7 の HTTP および HTTPS リスナーの場合、ヘルスチェックは HEAD または GET メソッドを使用してバックエンドサーバーの可用性をプローブします。
HTTPS リスナーの証明書は CLB で管理されます。システムパフォーマンスを向上させるために、CLB とバックエンドサーバー間のデータは HTTP 経由で交換されます。
CLB がレイヤー 7 ヘルスチェックを実行する方法:
ノードは、ヘルスチェック構成に基づいて、バックエンドサーバーに HTTP Head リクエストを送信します。
バックエンドサーバーは HTTP ステータスコードを返します。
ノードがタイムアウト期間内に応答を受信しない場合、バックエンドサーバーは異常と判断されます。
ノードがタイムアウト期間内に応答を受信した場合、返された HTTP ステータスコードは指定された HTTP ステータスコードと比較されます。返されたステータスコードが指定されたステータスコードのいずれかと一致する場合、バックエンドサーバーは正常と判断されます。返されたステータスコードが指定されたステータスコードと一致しない場合、バックエンドサーバーは異常と判断されます。
CLB が TCP ヘルスチェックを実行する方法
TCP リスナーのヘルスチェック効率を向上させるために、CLB インスタンスは、次の図に示すように、TCP セッションを確立することにより、レイヤー 4 ヘルスチェック(TCP ヘルスチェック)を実行します。
CLB が TCP ヘルスチェックを実行する方法:
レイヤー 4 クラスター内のノードは、リスナーのヘルスチェック構成に基づいて、バックエンドサーバーの内部 IP アドレスとヘルスチェックポートに TCP SYN パケットを送信します。
バックエンドサーバーポートが稼働している場合、バックエンドサーバーは TCP-SYN パケットを受信した後、SYN-ACK パケットを返します。
レイヤー 4 クラスター内のノードがタイムアウト期間内に SYN-ACK パケットを受信しない場合、バックエンドサーバーは異常と判断されます。ノードは RST パケットを送信して TCP 接続を閉じます。
レイヤー 4 クラスター内のノードがタイムアウト期間内に SYN-ACK パケットを受信した場合、バックエンドサーバーは正常と判断されます。ノードは RST パケットを送信して TCP 接続を閉じます。
このメカニズムにより、バックエンドサーバーで誤った TCP 接続エラーが発生する可能性があります。その結果、バックエンドサーバーは、ソフトウェアログに Connection reset by peer などのエラーメッセージを記録する可能性があります。
解決策:
TCP リスナーの HTTP ヘルスチェックを構成します。
CLB エンドポイントからのリクエストによってトリガーされた接続エラーを無視するために、バックエンドサーバーでクライアント IP の保持を有効にします。
CLB が UDP ヘルスチェックを実行する方法
CLB インスタンスに UDP リスナーを追加すると、CLB は次の図に示すように、UDP パケットを送信することでバックエンドサーバーの状態を確認します。
CLB が UDP ヘルスチェックを実行する方法:
レイヤー 4 クラスター内のノードは、リスナーのヘルスチェック構成に基づいて、バックエンドサーバーの内部 IP アドレスとヘルスチェックポートに UDP パケットを送信します。
バックエンドサーバーポートが稼働していない場合、
port XX unreachableなどの ICMP エラーメッセージが返されます。それ以外の場合、ICMP エラーメッセージは返されません。レイヤー 4 クラスター内のノードがタイムアウト期間内に ICMP エラーメッセージを受信した場合、バックエンドサーバーは異常と判断されます。
レイヤー 4 クラスター内のノードがタイムアウト期間内に ICMP エラーメッセージを受信しない場合、バックエンドサーバーは正常と判断されます。
次の状況では、UDP ヘルスチェックの結果がバックエンドサーバー上のアプリケーションの実際の状態を反映していない可能性があります。
高い同時実行シナリオで Linux バックエンドサーバーが使用されている場合、Linux の ICMP フラッド保護機能は ICMP パケットの送信頻度を抑制します。この場合、アプリケーションエラーが発生した場合でも、CLB はエラーメッセージ port XX unreachable を受信していないため、バックエンドサーバーを正常と見なす可能性があります。その結果、ヘルスチェックの結果は実際のアプリケーションの状態とは異なります。
解決策:
CLB がバックエンドサーバーに指定された文字列を送信するように設定できます。バックエンドサーバーは、CLB に指定された応答を返した場合にのみ正常と見なされます。ただし、バックエンドサーバー上のアプリケーションは、応答を返すように適切に構成する必要があります。
ヘルスチェックタイムウィンドウ
ヘルスチェック機能は、サービスの可用性を向上させます。ただし、異常なバックエンドサーバーによって引き起こされる頻繁なフェールオーバーは、システムの可用性に影響を与える可能性があります。フェールオーバーを制御するために、ヘルスチェックタイムウィンドウが導入されています。フェールオーバーは、バックエンドサーバーがタイムウィンドウ内で特定の回数のヘルスチェックに連続して合格または失敗した場合にのみ実行されます。ヘルスチェックタイムウィンドウは、次の要素によって決まります。
ヘルスチェック間隔: 2 つのヘルスチェックの間の時間。
応答タイムアウト: バックエンドサーバーが応答にかかる時間。
ヘルスチェックしきい値: バックエンドサーバーがヘルスチェックに連続して合格または失敗する回数。
ヘルスチェックタイムウィンドウは、次の式に基づいて計算されます。
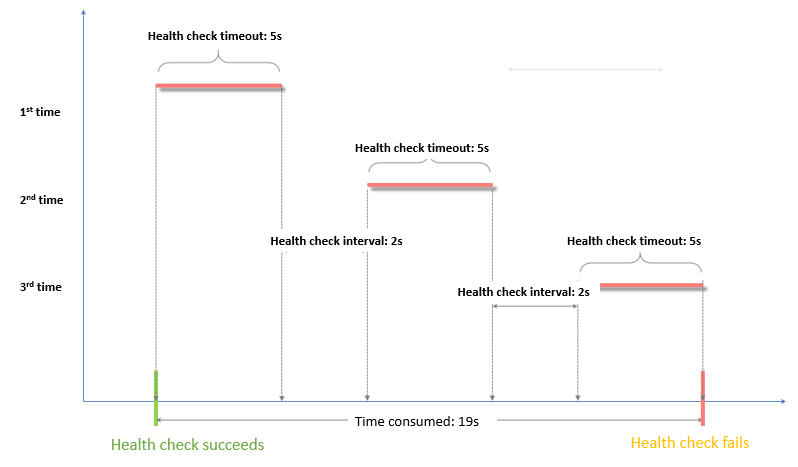
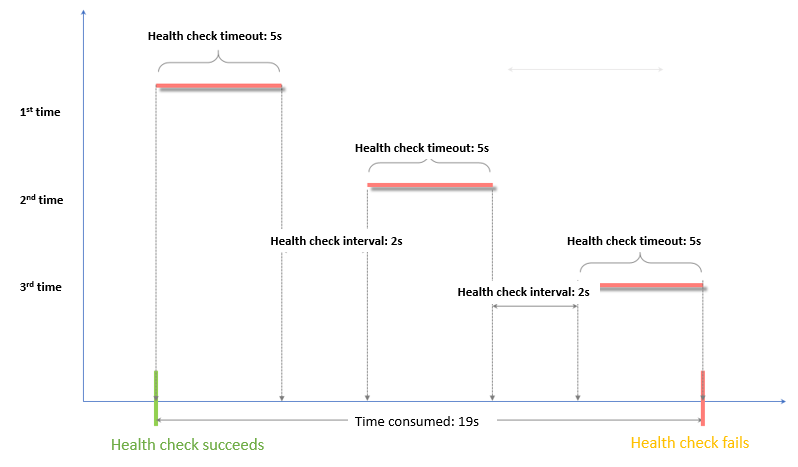
ヘルスチェック失敗のタイムウィンドウ = 応答タイムアウト × 異常しきい値 + ヘルスチェック間隔 × (異常しきい値 - 1)
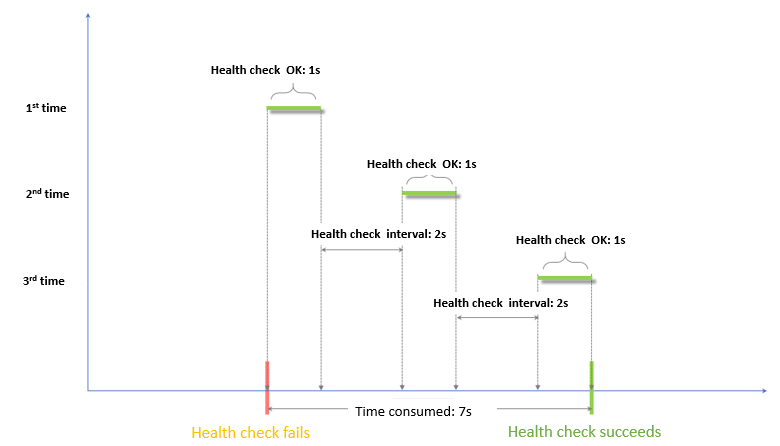
ヘルスチェック成功のタイムウィンドウ = 成功したヘルスチェックの応答時間 × 正常しきい値 + ヘルスチェック間隔 × (正常しきい値 - 1)
説明成功したヘルスチェックの応答時間は、ヘルスチェックリクエストが送信されてから応答が受信されるまでの期間です。 TCP ヘルスチェックの場合、応答時間は短く、ほとんど無視できます。 HTTP ヘルスチェックの場合、応答時間はサーバーのパフォーマンスと負荷によって異なり、通常は数秒以内です。
ヘルスチェックの結果は、リクエストの転送に次のような影響を与えます。
バックエンドサーバーがヘルスチェックに失敗した場合、新しいリクエストは他のバックエンドサーバーに分散されます。 CLB はクライアントからアクセス可能なままです。
バックエンドサーバーがヘルスチェックに合格した場合、新しいリクエストはバックエンドサーバーに分散されます。 CLB はクライアントからアクセス可能なままです。
バックエンドサーバーでエラーが発生し、ヘルスチェックに失敗したが、ヘルスチェックによって異常と判断されていない場合、リクエストはバックエンドサーバーに分散されます。ただし、バックエンドサーバーはリクエストにアクセスできません。デフォルトでは、バックエンドサーバーが 3 回連続してヘルスチェックに失敗すると、異常と判断されます。
ヘルスチェック応答タイムアウトとヘルスチェック間隔の例
この例では、次のヘルスチェック設定が使用されています。
応答タイムアウト期間: 5 秒
ヘルスチェック間隔: 2 秒
正常しきい値: 3 回
異常しきい値: 3 回
ヘルスチェック失敗のタイムウィンドウ = 応答タイムアウト × 異常しきい値 + ヘルスチェック間隔 × (異常しきい値 - 1)。この例では、タイムウィンドウは式 5 × 3 + 2 × (3 - 1) に基づいて 19 秒です。バックエンドサーバーが 19 秒間応答しない場合、バックエンドサーバーは異常と判断されます。
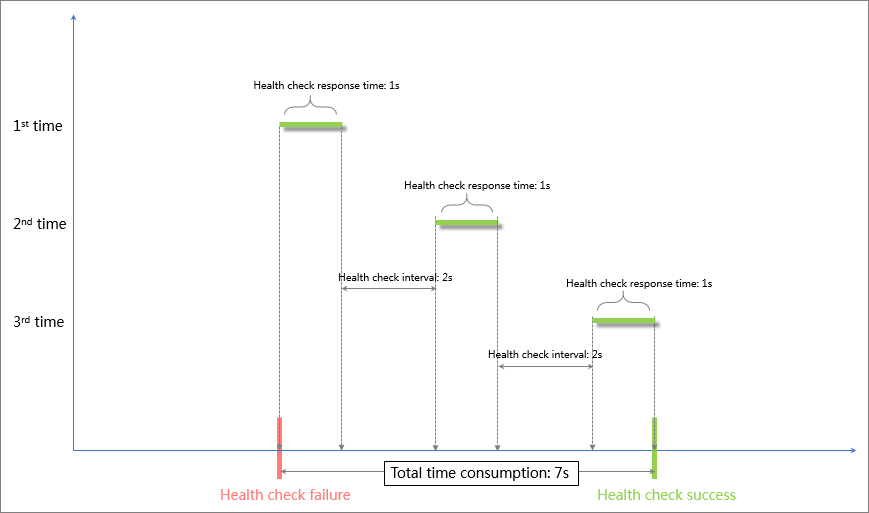
ヘルスチェック成功のタイムウィンドウ = 成功したヘルスチェックの応答時間 × 正常しきい値 + ヘルスチェック間隔 × (正常しきい値 - 1)。この例では、タイムウィンドウは式 (1 × 3) + 2 × (3 – 1) に基づいて 7 秒です。バックエンドサーバーが 7 秒以内に応答した場合、バックエンドサーバーは正常と判断されます。
成功したヘルスチェックの応答時間は、ヘルスチェックリクエストが送信されてから応答が受信されるまでの期間です。 TCP ヘルスチェックが構成されている場合、プローブ対象のポートが稼働しているかどうかのみがチェック項目であるため、応答時間は短く、ほとんど無視できます。 HTTP ヘルスチェックが構成されている場合、応答時間はアプリケーションサーバーのパフォーマンスと負荷によって異なり、通常は数秒以内です。
HTTP ヘルスチェックのドメイン名
HTTP ヘルスチェックのドメイン名を指定できます。この設定はオプションです。一部のアプリケーションサーバーは、リクエストを受け入れる前に、リクエスト内の Host ヘッダーを確認する必要があります。この場合、リクエストには Host ヘッダーが含まれている必要があります。ヘルスチェック用にドメイン名が構成されている場合、CLB は Host ヘッダーにドメイン名を挿入します。ドメイン名が構成されていない場合、ヘルスチェックリクエストはバックエンドサーバーによって拒否され、誤ったヘルスチェック結果が生じる可能性があります。
したがって、アプリケーションサーバーがリクエスト内の Host ヘッダーを確認する場合は、ヘルスチェック機能が期待どおりに機能するように、ヘルスチェック用にドメイン名を構成する必要があります。
参照
リスナーの作成時にヘルスチェックを構成する方法の詳細については、「CLB ヘルスチェックの構成と管理」をご参照ください。
ヘルスチェックに関するよくある質問 (FAQ) の詳細については、「ヘルスチェックに関する FAQ」をご参照ください。