SAE の auto scaling は、トラフィックのピークが数秒以内に到達するとアプリケーションインスタンスを自動的にスケールアウトし、ピークが終了するとスケールインして、アプリケーションのスムーズな実行を保証します。この機能は、高い信頼性、運用保守フリー、コスト効率を実現します。例えば、eコマースのプロモーションに対応するために、アプリケーションのデプロイ、auto scaling ルールの設定、リアルタイムでのポリシーの監視と調整、その後の運用保守の最適化を行うことができます。このプロセス全体を通じて、プラットフォームはユーザーのニーズに効率的かつ安定して対応できます。
auto scaling のワークフロー
SAE の auto scaling シナリオにおけるエンドツーエンドのワークフローを次の図に示します。
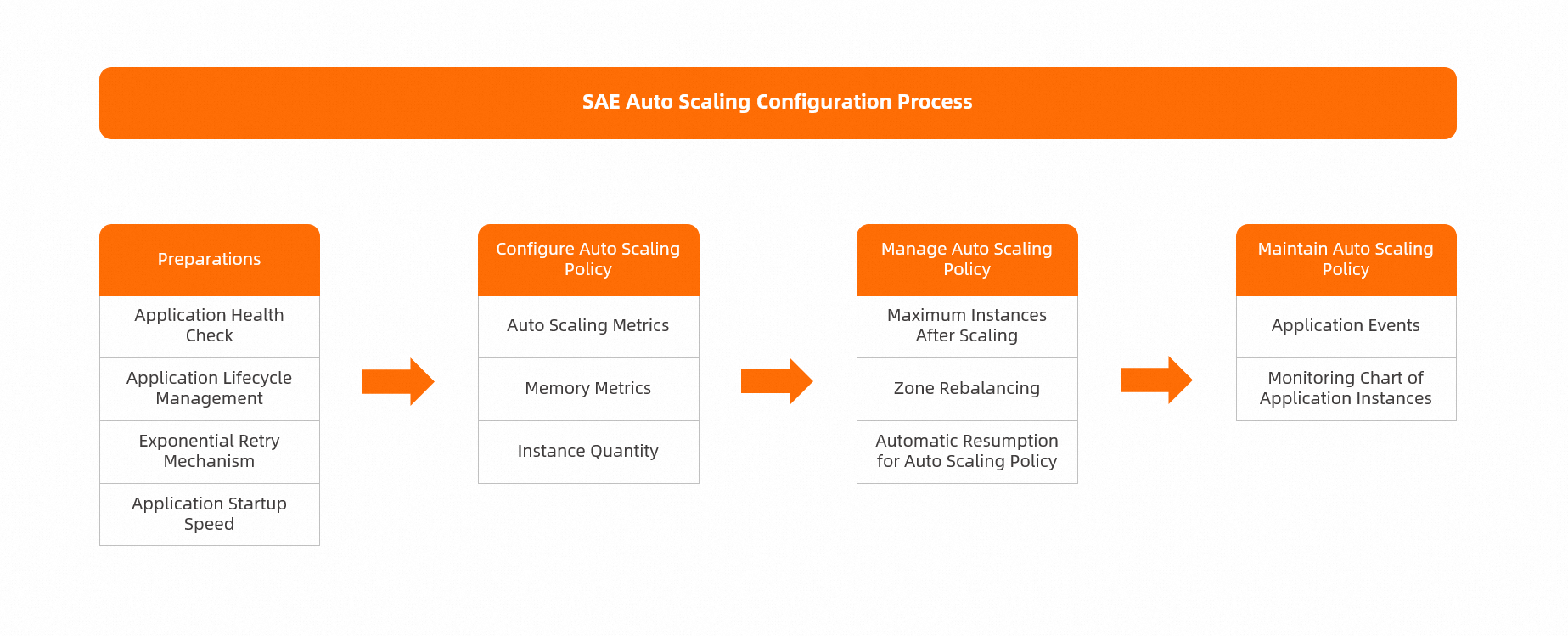
アプリケーションの準備
ヘルスチェックの設定:auto scaling 中のアプリケーション全体の可用性を確保するためです。ヘルスチェックは、インスタンスが起動し、リクエストを処理できる状態になってからトラフィックをルーティングします。詳細については、「ヘルスチェックの設定」をご参照ください。
アプリケーションライフサイクル管理の設定: PreStop Settings を設定することで、スケールインイベント中にグレースフルシャットダウンを確実に行います。 詳細については、「アプリケーションライフサイクル管理を設定する」をご参照ください。
Java アプリケーションでのエクスポネンシャルバックオフメカニズムの実装:スケーリングの遅延、起動の遅さ、またはグレースフルシャットダウンの欠如による障害を防ぎます。
アプリケーションの起動速度を最適化します。
パッケージの最適化:クラスのロードやキャッシングなどの外部要因を最小限に抑えることで、アプリケーションの起動時間を最適化します。
イメージの最適化:イメージサイズを削減することで、新規インスタンス作成時のプル時間を短縮します。オープンソースツールを使用して、イメージレイヤーの分析と効率化ができます。
Java アプリケーションの起動の最適化:SAE でアプリケーションを作成する際に Dragonwell 11 環境を選択することで、アプリケーション高速化を有効にできます。
auto scaling ポリシーの設定
スケーリングメトリクスの選択
SAE は、基本モニタリングとアプリケーションモニタリングの複数のメトリクスをサポートしています。アプリケーションが CPU 集中型、メモリ集中型、または I/O 集中型であるかに基づいて、これらのメトリクスを柔軟に設定できます。
Basic Monitoring と Application Monitoring から関連メトリックの既存データ (過去 6 時間、12 時間、1 日、または 7 日間のピーク値、P95、P99 など) を確認して、目標値を推定できます。Performance Testing Service (PTS) のような負荷テストツールを使用して、同時リクエスト数の上限、リソース要件 (CPU とメモリ) 、および高負荷時の応答動作を特定することで、アプリケーションのピークキャパシティを評価します。
auto scaling ポリシーを設定する際は、次の要素を考慮してください:
メトリクス目標値を設定する際は、可用性とコストのバランスを取ります。例:
可用性重視の戦略:メトリクス値を 40% に設定します。
バランスの取れた戦略:メトリクス値を 50% に設定します。
コスト重視の戦略:メトリクス値を 70% に設定します。
アップストリームおよびダウンストリームのサービス、ミドルウェア、データベースなどの依存関係を確認します。スケールアウトイベント中にエンドツーエンドの可用性を確保するために、対応する auto scaling ポリシーまたは速度制限と縮退のメカニズムを設定します。
auto scaling ポリシーを設定した後、それを監視および調整して、容量を実際のアプリケーションの負荷により近づけることができます。モニタリングの詳細については、「基本モニタリングデータの表示」をご参照ください。
メモリメトリクスの設定
Java アプリケーションの場合、ランタイムの最適化により、物理メモリを解放することで、メモリメトリクスとビジネス負荷との相関関係が向上します。Dragonwell ランタイムを使用し、JVM パラメーターを追加して ElasticHeap 機能を有効にすることで、Java ヒープメモリの動的スケーリングをサポートできます。これにより、ランタイムにおけるアプリケーションの物理メモリ消費量が削減されます。ElasticHeap の詳細については、「G1ElasticHeap」をご参照ください。
Dragonwell+ElasticHeap Periodic uncommit (自動) モードを推奨します。詳細な手順については、「Java アプリケーションのデプロイ」および「起動コマンドの設定」をご参照ください。
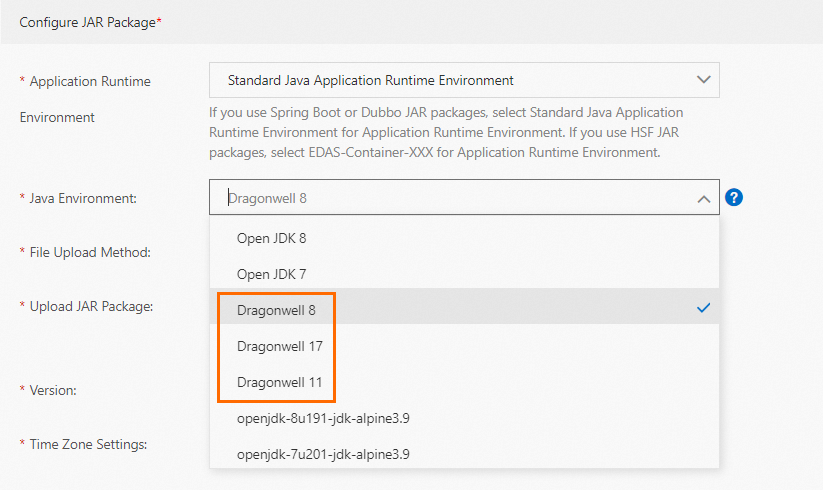
Java 環境: [JAR パッケージの構成] セクションで、[Java 環境] ドロップダウンリストから Dragonwell 構成を選択します。
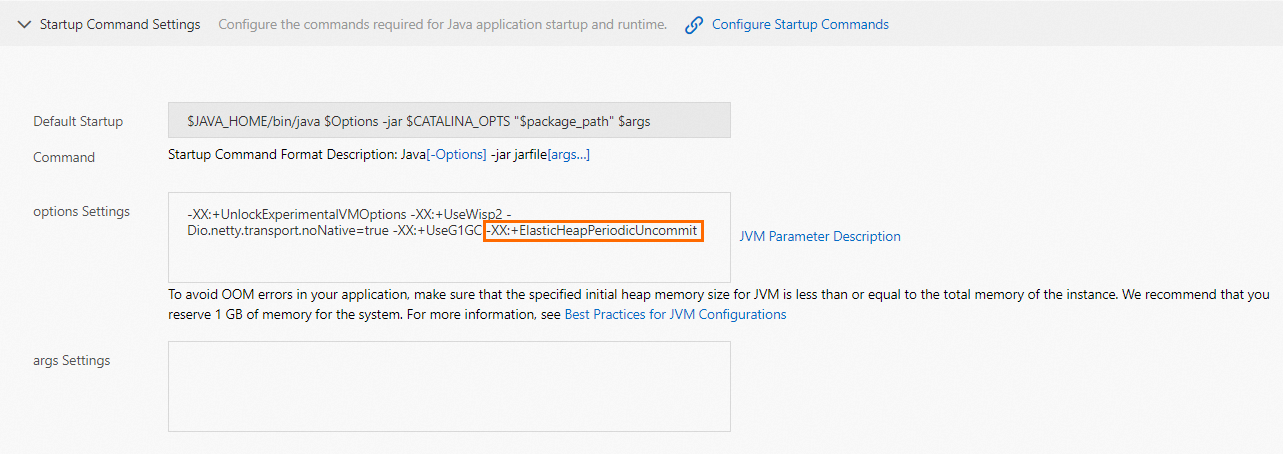
JVM パラメーター: Startup Command Settings セクションで、-XX:+ElasticHeapPeriodicUncommit を入力します。
メモリベースのスケーリングは、Java JVM のメモリ管理や Glibc の Malloc および Free 操作に依存するアプリケーションなど、動的なメモリ管理を使用する一部のアプリケーションには適していません。これらのアプリケーションがアイドル状態のメモリをオペレーティングシステムに迅速に解放しない場合、インスタンスのメモリ消費量はリアルタイムで減少しません。この遅延により、インスタンス全体の平均メモリ消費量が高いままであるため、スケールインイベントがトリガーされない可能性もあります。
インスタンス数の設定
最小インスタンス数
最小インスタンス数を 2 以上に設定し、複数のゾーンにまたがって vSwitch を設定します。この設定により、基盤となるノードの障害によるインスタンスの退去や、ゾーン内で利用可能なインスタンスがない場合に、アプリケーションのダウンタイムを防ぐことができます。
最大インスタンス数
最大インスタンス数が vSwitch で利用可能な IP アドレスの数以下であることを確認してください。これにより、IP アドレスの不足によるスケールアウトの失敗を防ぎます。
Basic Information ページの Application Information セクションで、現在のアプリケーションで利用可能な IP アドレスの数を確認します。この数が少ない場合は、vSwitch を置き換えるか、追加します。
auto scaling プロセスの監視
最大インスタンス数制限
アプリケーションのOverviewページで、auto scaling のステータスを確認できます。最大インスタンス数に達したアプリケーションを監視し、auto scaling 設定を再評価してください。
単一のアプリケーションで 50 を超えるインスタンスにスケールアウトする必要がある場合は、DingTalk グループ (グループ ID: 32874633) に参加して、許可リストへの追加を申請してください。
ゾーンリバランス
スケールイン イベント後、インスタンスがゾーンに不均等に分散されることがあります。アプリケーションのBasic Informationページのインスタンス リストで、各インスタンスのゾーンを確認できます。分散が不均衡な場合、インスタンスでRestartを実行することで、ゾーン リバランスをトリガーできます。

自動再開
アプリケーションのデプロイなどの変更オーダーを実行すると、SAE は競合を防ぐために、そのアプリケーションの auto scaling ポリシーを一時的に停止します。変更オーダーの完了後にポリシーが復元されるようにするには、Deploy Application ページで Automatic を選択します。

auto scaling のメンテナンス
アプリケーションイベント
対象アプリケーションの Application Events ページで、スケーリングアクションの時間やタイプなど、SAE auto scaling の動作を確認できます。この情報を使用して、auto scaling ポリシーの有効性を評価し、必要に応じて調整を行うことができます。詳細については、「アプリケーションイベントの表示」をご参照ください。

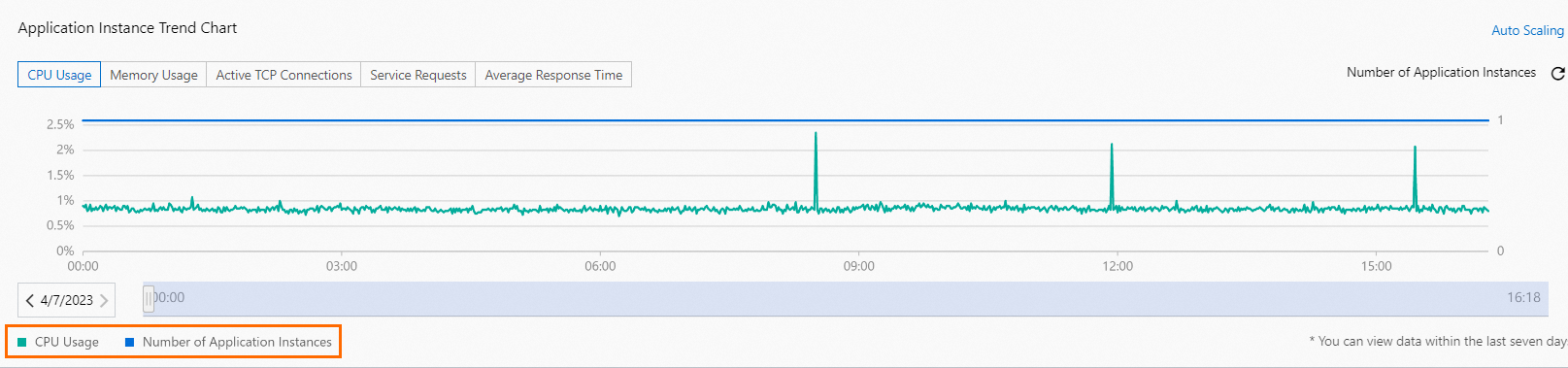
アプリケーションインスタンストレンドチャート
アプリケーションの Basic Information ページの Basic Information タブにある Application Instance Trend Chart には、CPU 使用率、メモリ使用量、アクティブな TCP 接続、サービスリクエスト、平均応答時間など、過去 7 日間の監視メトリクスが表示されます。