Serverless App Engine (SAE) は、さまざまなモニタリングメトリックとデータソースタイプを提供します。デフォルトでは、これらのモニタリングメトリックは Alibaba Cloud Managed Service for Prometheusと統合されており、Managed Service for Grafana と統合されています。SAE モニタリングデータについては、Managed Service for Grafana Shared Edition のプリセットダッシュボードを表示するか、有料の Grafana ワークスペースを作成して二次開発を行うことができます。
前提条件
SAE がアクティブ化され、SAE アプリケーションが作成されていること。詳細については、「アプリケーションのデプロイ」をご参照ください。
注意事項
基本モニタリングダッシュボードと Application Real-Time Monitoring Service (ARMS) アプリケーションモニタリングダッシュボードを含む、単一アプリケーションの SAE プリセット Grafana ダッシュボードにアクセスできます。
ビジネス要件に基づいてカスタムモニタリングダッシュボードを構成できます。たとえば、すべてのアプリケーション、ジョブ、インスタンス、変更オーダーのすべてのメトリックの統計と上位 N 個のダッシュボードを含む、Grafana 可観測性ダッシュボードにアクセスして構成できます。この機能により、1 人で数百または数千のアプリケーションの O&M を効率的に実装できます。
Prometheus を使用してすべての SAE メトリックのアラート ルールを構成し、サービスの継続性と高可用性を確保できます。
詳細については、「Managed Service for Grafana とは」および「Grafana」をご参照ください。
機能ポータルのアクセス
SAE コンソール にログインします。左側のナビゲーションウィンドウで、 を選択します。[アプリケーション] ページで、上部のナビゲーションバーでリージョンを選択し、[名前空間] ドロップダウンリストから名前空間を選択して、目的のアプリケーション名をクリックします。

アプリケーション詳細ページの左側のナビゲーションウィンドウで、[基本モニタリング] をクリックします。ページ上部のプロンプトメッセージで、[詳細の表示] をクリックします。
基本モニタリングダッシュボード: [詳細の表示] をクリックすると、基本 Grafana モニタリングダッシュボードが表示されます。詳細については、「単一アプリケーションの基本 Grafana モニタリングダッシュボードへのアクセス」をご参照ください。
アプリケーションモニタリングダッシュボード: 基本 Grafana モニタリングダッシュボードで、左側のナビゲーションウィンドウの
 アイコンをクリックします。Grafana 検索ページが表示されます。アプリケーションのアプリケーションモニタリングダッシュボードを表示するには、
アイコンをクリックします。Grafana 検索ページが表示されます。アプリケーションのアプリケーションモニタリングダッシュボードを表示するには、armsキーワードを検索し、arms-metrics-<アプリケーションが存在するリージョン>-で始まるディレクトリを見つけ、ディレクトリを展開して、特定のモニタリングメトリックを表示します。詳細については、「ARMS を使用して監視される単一アプリケーションの Grafana ダッシュボードへのアクセス」をご参照ください。
単一アプリケーションの基本 Grafana モニタリングダッシュボードへのアクセス
ダッシュボードには、すべてのインスタンスと単一アプリケーションのモニタリングメトリックが表示されます。これには、次のメトリックが含まれます。
CPU 使用率
平均システム負荷
メモリ使用量
受信および送信ネットワークレート
ネットワークパケット
ディスク使用量
ディスク IOPS
ディスクスループットレート
TCP 接続数
ARMS を使用して監視される単一アプリケーションの Grafana ダッシュボードへのアクセス
SAE の組み込み ARMS は Java アプリケーションに適しています。
このダッシュボードには、API、アプリケーション、データベース、マシンのモニタリングメトリックが表示されます。メトリックの説明については、「アプリケーションモニタリングメトリック」をご参照ください。
API (アプリケーション概要ビュー)
アプリケーション概要ビューには、リクエスト数、応答時間、エラー数など、アプリケーションとアップストリームおよびダウンストリームリンクのモニタリングメトリックが表示されます。
アプリケーション (アプリケーション詳細ビュー)
アプリケーション詳細ビューには、サービスコール (提供および呼び出しサービス)、Java 仮想マシン (JVM)、インスタンスのモニタリングメトリックが表示されます。
データベース (アプリケーションに関連付けられたデータベースのビュー)
データベースビューには、リクエスト数、エラー数、応答時間、接続プール関連のメトリックなどのモニタリングメトリックが表示されます。
マシン (アプリケーションインスタンスビュー)
アプリケーションインスタンスビューには、CPU、メモリ、負荷、ディスク、ネットワークトラフィック、ネットワークパケットなど、アプリケーションの特定のインスタンスのモニタリングメトリックが表示されます。
複数アプリケーションのグローバル Grafana 可観測性ダッシュボードの構成
Grafana ワークスペースの作成には料金が発生します。詳細については、「請求ルール」をご参照ください。
基本およびアプリケーションモニタリングダッシュボードが要件を満たしていない場合は、グローバル可観測性ダッシュボードを構成して、包括的で詳細なデータを調整できます。これは、現在の問題を迅速に特定し、潜在的なリスクを防ぎ、将来のトレンドをグローバルな視点から分析するのに役立ちます。
Grafana ワークスペースを作成します。詳細については、「Grafana ワークスペースの作成と管理」をご参照ください。
作成されたワークスペースは、[ワークスペース管理] ページで表示できます。
[ワークスペース管理] ページで、目的のワークスペースの名前をクリックします。[クラウドサービス統合] セクションの [ワークスペース情報] ページで、SAE データソースを統合します。
基本モニタリングデータと SAE プラットフォーム関連データを含む、SAE データソースを統合します。
クラウドサービス統合リストで、[managed Service For Prometheus] をクリックし、特定のリージョンのクラウドサービスの自己監視データソースを統合します。
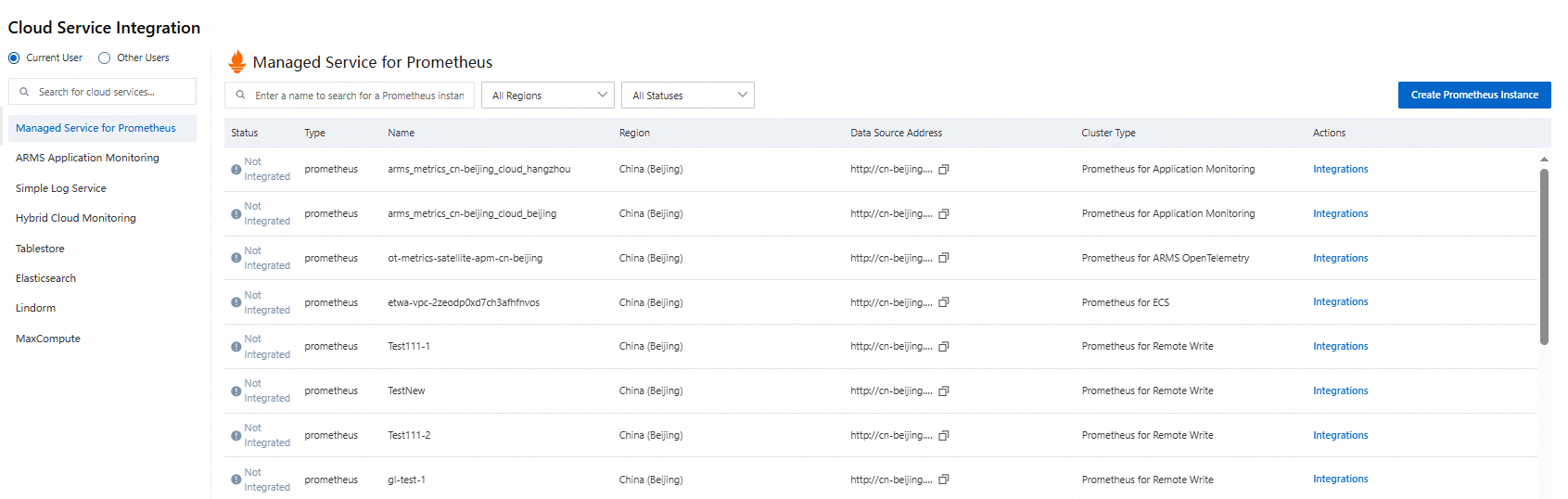
SAE アプリケーションモニタリングデータを含む ARMS データソースを統合します。
クラウドサービス統合リストで、[ARMS アプリケーションモニタリング] をクリックし、特定のリージョンのデータソースを統合します。
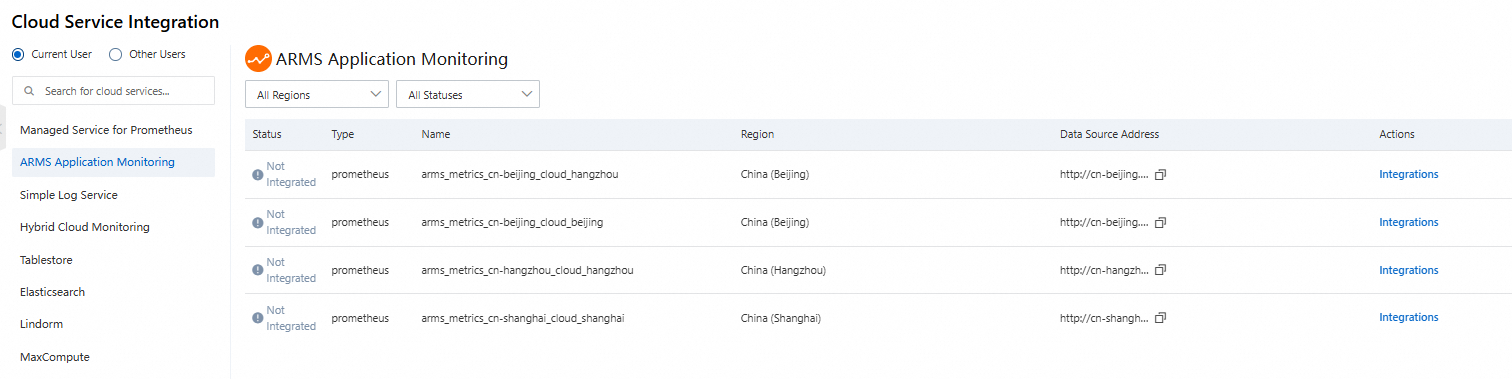
SAE イベントを含む Simple Log Service データソースを統合します。
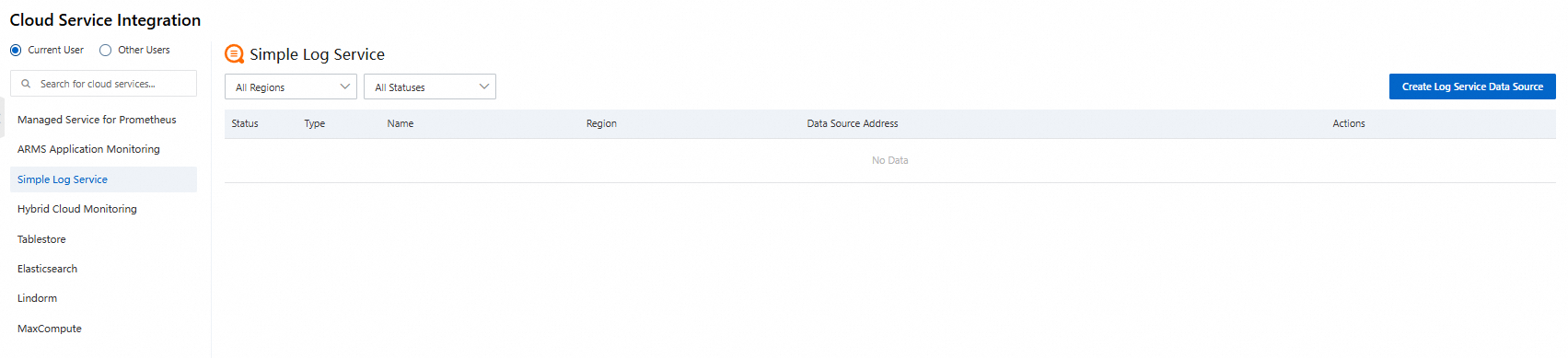
クラウドサービス統合リストで、[simple Log Service] をクリックし、必要なデータソースを統合します。詳細については、「クラウドサービスの統合」をご参照ください。
データソースを作成するときは、[プロジェクト] パラメーターを
aliyun-product-data-{userId}-{regionId}に設定し、[ログストア] パラメーターをsae_eventに設定します。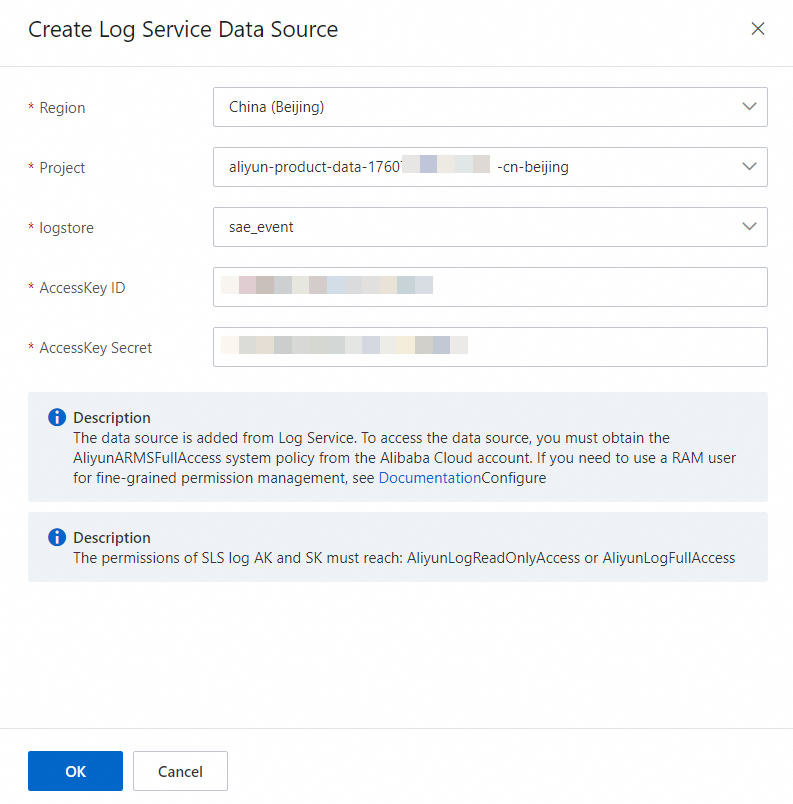 説明
説明2023 年 4 月 28 日より前にデプロイされていないアプリケーションは、データを生成するために再デプロイする必要があります。
Grafana でダッシュボードテンプレートをインポートします。
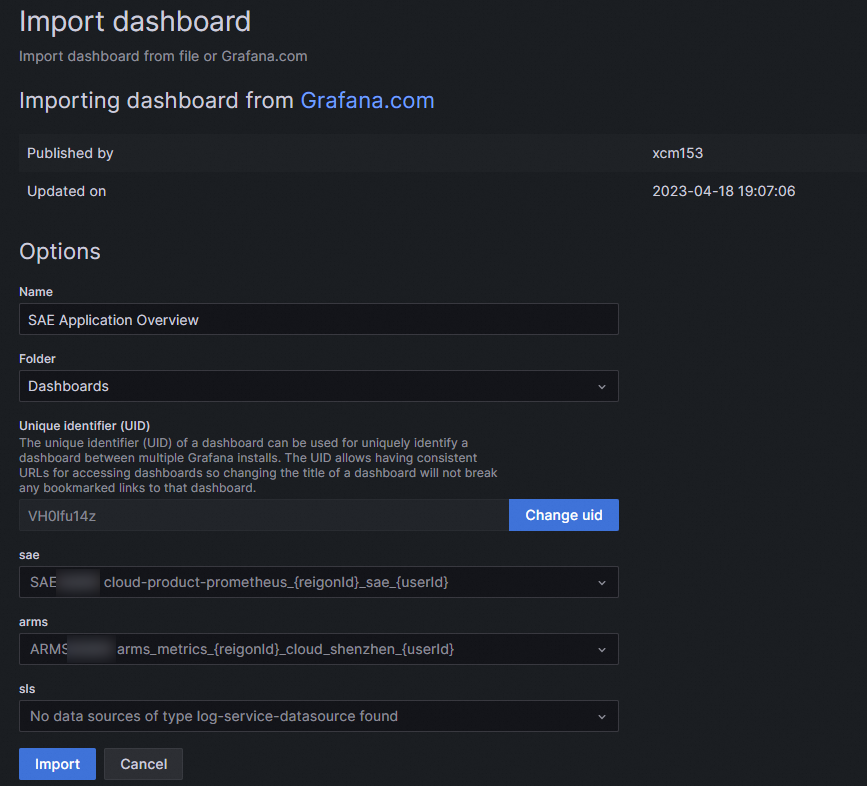
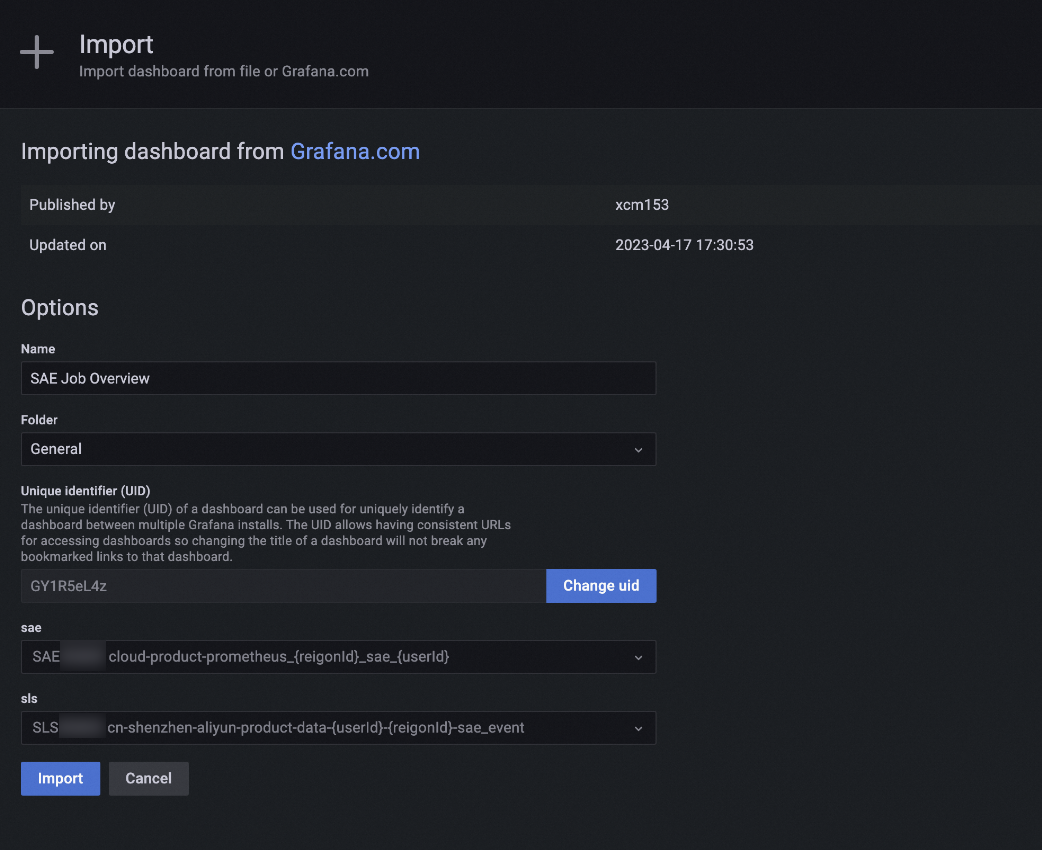
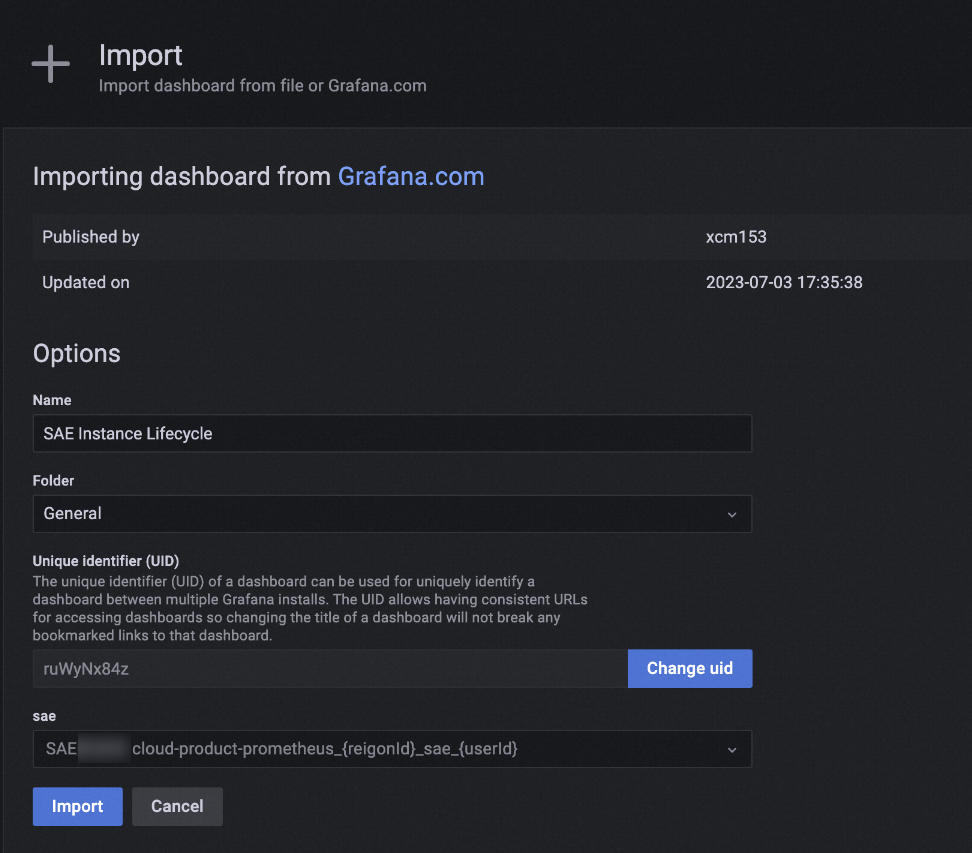
Prometheus を使用した SAE メトリックのアラート ルールの構成
Grafana ワークスペースの作成には料金が発生します。詳細については、「請求ルール」をご参照ください。
SAE データソースを Managed Service for Prometheus に統合することで、アプリケーション、ジョブ、インスタンス、変更オーダーに関して主要な SAE メトリックのモニタリングアラートを構成し、サービスの継続性と高可用性を確保できます。
サポートされている SAE メトリック
次の表は、Prometheus のプリセット SAE メトリックについて説明しています。
アラート ルールの構成
SAE データソースを統合します。
Grafana ワークスペースを作成します。詳細については、「Grafana ワークスペースの作成と管理」をご参照ください。
作成されたワークスペースは、[ワークスペース管理] ページで表示できます。
[ワークスペース管理] ページで、目的のワークスペースの名前をクリックします。[クラウドサービス統合] セクションの [ワークスペース情報] ページで、SAE データソースを統合します。
基本モニタリングデータと SAE プラットフォーム関連データを含む、SAE データソースを統合します。
クラウドサービス統合リストで、[managed Service For Prometheus] をクリックし、特定のリージョンのクラウドサービスの自己監視データソースを統合します。
アラート ルールを構成します。
SAE データソースを統合した後、Prometheus コンソール にログインし、アラートルールを作成します。詳細については、「Prometheus インスタンスのアラートルールを作成する」をご参照ください。