AI エージェントは、マルチターン対話において継続的にコンテキストを追跡する必要があります。このタスクには、メモリレイヤーから低レイテンシおよび高い同時実行性が求められます。本記事では、「タオバオ・フラッシュセール」における「一文注文」を事例として取り上げ、Tair のデータ構造、分散ロック、弾力的スケーリング機能を活用して、AI エージェント向け高性能短期記憶システムを構築する方法を解説します。
背景情報
タオバオ・フラッシュセールの AI エージェントは、自然言語を用いて、商品のレコメンデーションからチェックアウト、支払いに至るまでの注文プロセス全体をユーザーが完遂できるようにします。その目標は、従来の 3~5 分かかる注文時間を 30 秒未満に短縮することです。
ユーザーが「チャジーの白鴉絶鮮を、糖分少なめ・氷抜きで、私のオフィスへ配達してください」と発話した場合、裏側で動作する AI エージェントは、数秒以内にインテント認識、住所解析、商品検索、仕様マッチング、カートへの追加、注文確定といった一連の操作を完了させる必要があります。各ステップは、それ以前の対話内容を正確に記憶していることに依存しています。
「一文注文」プロジェクトは、タオバオ・フラッシュセールと千問(Qianwen)の共同取り組みであり、Tair が AI エージェントの短期記憶レイヤーの中核を担っています。この実際のビジネスケースに基づき、本記事では、Tair を用いた AI エージェントのメモリ管理に関する主要な実践手法(データモデル設計および同時実行制御を含む)を紹介します。
適用範囲
本記事で紹介する設計パターンは、以下の AI エージェントのユースケースに適用可能です:
カスタマーサポートボット、ショッピングアシスタント、パーソナルアシスタントなど、マルチターン対話においてコンテキストを維持する必要がある対話型エージェント。
エンドツーエンドレイテンシに敏感で、ミリ秒単位のメモリ読み書き操作を要求するリアルタイムインタラクティブなシナリオ。
AI エージェントが複数のツールを同時に呼び出すなど、並列書き込みのリスクがあるマルチツール呼び出しシナリオ。
トラフィック変動が激しく、弾力的スケーリングを必要とするオンラインサービス。
なぜメモリシステムに Tair が必要か
AI エージェントのメモリシステムは、レイテンシに対して極めて敏感です。リトルの法則(同時実行数 ≈ QPS × レイテンシ)によると、メモリアクセスレイテンシが 5 ms から 50 ms に増加すると、処理中のリクエスト数は 10 倍に膨らみます。これにより、接続、スレッド、キューなどのリソースが急速に枯渇する可能性があります。また、各対話ターンでは複数回のメモリ読み書きが発生するため、レイテンシは累積し、キューイング、タイムアウト、さらにはカスケード障害を引き起こすおそれがあります。
5 ms と 50 ms の差は、単なるユーザーエクスペリエンスの最適化ではなく、安定的にスケール可能なシステムと、そうでないシステムを分ける分水嶺です。 これが、タオバオ・フラッシュセールの AI エージェントがメモリレイヤーに Tair を採用した根本的な理由です。Tair は独自のマルチスレッドカーネルを備えており、安定した低レイテンシを実現します。これにより、メモリアクセスが安全なしきい値内に保たれ、高同時実行時における性能劣化の悪循環を根本的に防止します。
全体アーキテクチャ
タオバオ・フラッシュセールの AI エージェントにおけるメモリレイヤー(Memory Service)は、エージェントオーケストレーターと下位のツールサービスの間に位置し、Tair を用いてセッションレベルの状態を管理します。
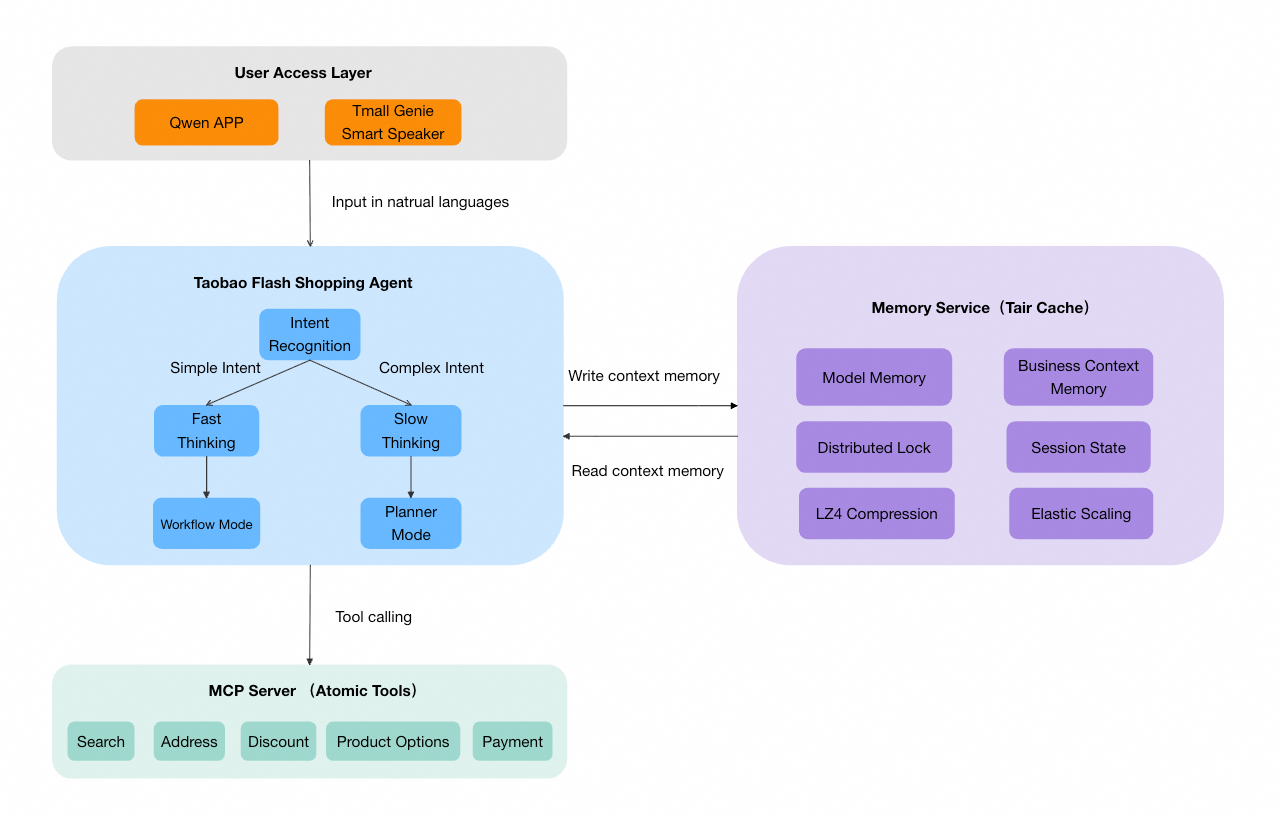
メモリの分類とデータモデル
タオバオ・フラッシュセールの AI エージェントが短期記憶ストレージエンジンとして Tair を選択した主な理由は以下のとおりです:
低レイテンシ:エージェントの対話フローは応答時間に対して極めて敏感です。Tair の独自マルチスレッドカーネルにより、マイクロ秒単位の読み書き性能が実現され、リアルタイムインタラクションの要件を満たします。
豊富なデータ構造:Tair を用いると、異なる種類のメモリをそれぞれに最も適したデータ構造にマッピングでき、アプリケーション開発を簡素化できます。
弾力的スケーリング:Tair はシームレスなクラスタスケーリングおよびバースト帯域幅をサポートしており、トラフィックピーク時に業務運用への影響を及ぼさずに迅速な拡張が可能です。
TTL ライフサイクル管理:セッションメモリは自然に有効期限が切れるため、TTL 機構により期限切れデータが自動的に削除されます。
短期記憶は、2 つの主要なカテゴリに分けられ、それぞれ異なる Tair データ構造にマッピングされます:
モデルメモリ — List
モデルメモリは、大規模言語モデル(LLM)が処理するための対話履歴を格納します。各ターンにおいて、エージェントはユーザーの入力および自身の応答を記録し、次回のモデル推論時にコンテキストとして渡します。
この履歴は、Tair の List に格納され、セッションごとに 1 つのキーが使用されます:
Key: memory:model:{sessionId}
Type: List
Example data:
[
{"role": "user", "content": "ミルクティーを注文したいです。"},
{"role": "assistant", "content": "近くにあるミルクティー店を 3 件見つけました...", "cards": [...]},
{"role": "user", "content": "この店で、糖分少なめ・氷抜きにしてください。"},
{"role": "assistant", "content": "選択しました:白鴉絶鮮、糖分少なめ、氷抜き、大サイズ..."}
]主な操作:
# 各対話ターン終了後に、新しい対話レコードを追加
RPUSH memory:model:{sessionId} "{Conversation Record JSON}"
# モデル推論前に、直近 N ターンの履歴をコンテキストとして読み取り
LRANGE memory:model:{sessionId} -{N} -1
# セッションの有効期限(例:30 分)を設定
EXPIRE memory:model:{sessionId} 1800システムは、テキストおよびカードなどのリッチメディアを含む生の対話データを、モデルがより容易に理解できる自然言語形式に変換します。これにより、トークン消費量を削減します。
ビジネスコンテキストメモリ — Hash
ビジネスコンテキストメモリは、ビジネスプロセスから得られる構造化された状態情報を格納します。エージェントのツールレイヤーおよびインテントプロセッサは、ビジネスロジックを実行する際に、この情報を照会および更新します。
このメモリは、ビジネスドメインごとに 6 つのサブモジュールに分割され、Tair の Hash に格納されます:
Key: memory:context:{sessionId}
Type: Hash
Field structure:
{
"session": "{セッションメタデータ:ユーザー ID、チャネル、セッションステージなど}",
"search": "{検索ステータス:現在のクエリ、検索結果、おすすめ商品リストなど}",
"order": "{注文ステータス:ショッピングカートの内容、選択 SKU、数量など}",
"conversation": "{対話ステータス:現在のインテント、前回のインテント、インテント切り替えフラグなど}",
"coupon": "{クーポン情報:利用可能なクーポン、選択済みクーポンなど}",
"bizState": "{ビジネスステート:配送先住所、配送方法、支払いステータスなど}"
}主な操作:
# 単一サブモジュールの更新(例:ユーザーが配送先住所を確定した場合)
HSET memory:context:{sessionId} bizState "{Updated Business State JSON}"
# 特定サブモジュールの読み取り
HGET memory:context:{sessionId} order
# 全コンテキストの一括読み取り(インテント認識など、グローバル情報が必要なシナリオ向け)
HGETALL memory:context:{sessionId}
# 有効期限の設定
EXPIRE memory:context:{sessionId} 1800Hash データ構造のフィールド単位での読み書き機能により、各ビジネスモジュールが互いに干渉せずに独立して更新できます。これにより、完全な JSON オブジェクトに対する読み取り→変更→書き込み(read-modify-write)パターンに伴う競合状態を回避します。たとえば、検索モジュールが商品推薦を更新しても、ショッピングカートへのデータ書き込みを同時に行う注文モジュールには影響しません。
データ構造の比較
メモリ種別 | データ構造 | 選択理由 |
対話履歴 | List | 対話は時系列データであり、List データ構造は順序付き追加(RPUSH)および範囲読み取り(LRANGE)をサポートします。 |
ビジネスコンテキストメモリ | Hash | メモリはドメインごとに複数のフィールドに分割されます。Hash データ構造は、独立したフィールド単位の読み書きを可能にし、競合状態を防止します。 |
セッションステートフラグ | String | String データ構造は、セッションステージなど、シンプルな操作を要する原子的なステートフラグに適しています。 |
分散ロック | String | SET NX EX を用いて実装され、同時実行時の安全性を確保します。 |
同時実行安全性:分散ロック
実際のアプリケーションでは、同一セッションに対する並列書き込みが発生する可能性があります。たとえば、ユーザーが連続してメッセージを送信したり、ストリーミング応答中に新たな入力を提供したりした場合、複数のリクエストが同一セッションのメモリデータを同時に変更しようとする可能性があります。
タオバオ・フラッシュセールの AI エージェントでは、Tair の分散ロックを用いて、メモリの読み書き整合性を保護します。このロックは、個別のセッション単位で適用されます:
# セッション単位の分散ロックの取得(デッドロック防止のため 3 秒のタイムアウトを設定)
SET lock:memory:{sessionId} {requestId} NX EX 3
# ロック取得後に、メモリの読み書き操作を実行
HSET memory:context:{sessionId} order "{Updated Order Status}"
RPUSH memory:model:{sessionId} "{New Conversation Record}"
# 操作完了後にロックを解放(Lua スクリプトを用いて、ロック所有者のみが解放可能であることを保証)
EVAL
if redis.call('GET', KEYS[1]) == ARGV[1] then
return redis.call('DEL', KEYS[1])
else
return 0
endロックの粒度はセッションレベル(sessionId)であり、グローバルロックではありません。つまり、異なるユーザーのセッション間でロック競合が発生せず、システム全体のスループットへの影響を回避できます。ロックのタイムアウトは数秒に設定されており、ロック保持プロセスが予期せず終了した場合でも長時間のブロッキングを防ぎます。
トラフィックスパイクへの対応
千問(Qianwen)の春節レッドパケットイベント期間中、タオバオ・フラッシュセールの AI エージェントは、予測ピークの 10 倍以上の同時実行負荷を処理しました。各ユーザー対話は、履歴読み取り、状態更新、ロック操作など数十回の Tair 操作をトリガーし、エージェントの並列リクエストを、Tair 操作数としては桁違いに多い量に増幅します。
タオバオ・フラッシュセールの AI エージェントのメモリレイヤーは、Tair(Redis 互換)上に構築されています。自己管理型 Redis デプロイメントと比較して、Tair のカーネル性能、弾力的スケーリング、運用面での優位性が、このトラフィックスパイクへの対応において決定的な役割を果たしました。
Tair カーネル性能
Tair は マルチスレッドモデルを採用しており、同一仕様のオープンソース Redis インスタンスと比較して、最大 3 倍の読み書き性能を実現します。これは、同一サイズのインスタンスにおいて、Tair がオープンソース Redis の 3 倍の操作スループットを処理できることを意味します。
この性能上の優位性は、AI エージェントのユースケースにおいて特に重要です。単一のユーザー対話は、対話履歴の読み取り、ビジネスコンテキストの更新、分散ロックの取得/解放など、数十回の Tair 操作をトリガーします。オープンソース Redis のシングルスレッドモデルでは、高同時実行時にデータベースが容易にボトルネックとなり得ますが、Tair のマルチスレッドカーネルにより、単一ノードがマルチコア CPU リソースを十分に活用でき、ノード数を増やすことなくより高い同時実行性を処理できます。
弾力的かつシームレスなスケーリング
エージェントの対話フローにおいて、メモリデータは典型的な 読み取り重視 パターンを示します:各推論ラウンドの前に、エージェントは完全な対話履歴およびビジネスコンテキストを読み取る必要があります(読み取り操作)、一方で書き込み操作は各ターン終了時に新規レコードを追加するのみです。読み取りと書き込みの比率は通常 5:1 ~ 10:1 です。
Tair は 読み書き分離を備えたクラスタアーキテクチャ をサポートしています。Tair は、読み取りリクエストを自動的に読み取り専用レプリカに分散し、書き込みリクエストはプライマリノードにルーティングします。読み取り専用レプリカの数は 1~9 で柔軟に調整可能であり、クラスタのシャード数は 2~256 まで水平方向にスケールできます。トラフィックピーク前に読み取り専用レプリカまたはシャードを追加することで、スループットを線形に向上させ、ピーク後にはコスト削減のために縮小できます。
例
通常トラフィック:日常的なビジネスニーズを満たすために、シャード数 8、各シャードに読み取り専用レプリカ 1 台のクラスタを使用。
春節イベント(ピークトラフィックが 5~10 倍):
オプション 1:各シャードの読み取り専用レプリカを 5 台に増やし、読み取りスループットを線形に向上。
オプション 2:シャード数を 16 に増やし、各シャードに読み取り専用レプリカを 3 台配置して、読み取りおよび書き込みの両方のキャパシティを 2 倍に拡張。
これらのスケーリング操作は、お客様のサービスに対して完全に透明です。従来の Redis クラスタでは、スロット移行中に -ASK や -TRYAGAIN などのエラーが発生することがあります。対話型エージェントのユースケースでは、リクエストの失敗は対話の中断やメモリ損失につながり得ます。Tair のクラウドネイティブ版は、カーネルレベルの最適化により シームレスなスケーリング を実現します。データはキー単位ではなく、スロット単位で原子的に移行されるため、スロット分割が発生しません。さらに、集中制御コンポーネントがクラスタの動作を調整し、より高い移行効率とより精密な意思決定を実現します。
データ移行の最終段階では、対応するスロットへの書き込みリクエストのレイテンシがわずかに増加する場合がありますが、リクエストは 失敗しません。エージェントのメモリサービスにとっては、一部のリクエストでレイテンシが若干増加するものの、データ損失やリクエストエラーは一切発生しないことを意味します。
弾力的帯域幅スケーリング
QPS の負荷に加え、イベントは著しい 帯域幅の課題 も提示しました。AI エージェントによる各メモリ読み取りは、対話履歴およびビジネスコンテキストの転送を伴うため、従来のキャッシュ用途における単純なキー・バリューリードと比較して、1 回のリクエストあたりのデータペイロードが大幅に大きくなります。業務ピーク時には、CPU やメモリよりも先に帯域幅がボトルネックとなることがあります。
Tair アーキテクチャは、2 層の弾力性を提供します:
クラスタ帯域幅の水平スケーリング:クラスタアーキテクチャでは、ロードバランサー(LB)を追加することで、インスタンスの総帯域幅を増加できます。単一 LB の帯域幅制限は 20 Gbps です。シャード数が 8 を超える場合、既存の接続を中断することなく、必要に応じて LB を追加できます。
バースト帯域幅:瞬間的なトラフィックが固定帯域幅を超えた場合、システムは 数秒で帯域幅を自動的に拡張 します(ノードあたり最大 288 MB/s)。トラフィックが収まると帯域幅は自動的に解放され、使用したバースト分のみが課金されます。バースト帯域幅は 各シャードごとに独立して動作 します。あるシャードがホットキーによって帯域幅ボトルネックを起こした場合、そのシャードの帯域幅のみが自動的に拡張され、他のシャードには影響しません。
説明バースト帯域幅は、AI エージェントのユースケースに多く見られる予測困難なトラフィックスパイクに特に適しています。高スペックの固定帯域幅パッケージを事前に購入するよりも、オンデマンドでバーストする方がコスト効率が優れています。
自動 TTL クリーンアップ
すべてのセッションキーに適切な TTL(例:30 分)を設定することで、トラフィックピーク後のメモリ使用量が手動介入なしに自動的に減少します。Tair の弾力的スケーリングと組み合わせることで、ピーク時のスケールアウト、トラフィック低下時のスケールイン、および期限切れデータの自動クリーンアップを含む、完全自動化されたリソース管理が実現します。
その結果、春節期間中のトラフィック急増時にも、メモリサービス全体が安定して稼働し、P99 レイテンシは一貫してミリ秒レベルで制御されました。
まとめと今後の展望
タオバオ・フラッシュセールにおける「一文注文」ユースケースでは、Tair が AI エージェントの短期記憶レイヤーの中核ストレージとして機能し、以下の主要な機能を提供しました:
機能 | 実装方法 | 解決された課題 |
低レイテンシアクセス | Tair を用いたインメモリ読み書き | エージェントの対話フローにおけるリアルタイム要件を満たします。 |
柔軟なデータモデリング | List、Hash、String データ構造の組み合わせ | 対話履歴やビジネスコンテキストなど、異なるメモリ種別に対応できます。 |
ライフサイクル管理 | TTL による自動有効期限切れ | セッション終了後にデータを自動的に削除し、運用コストを削減します。 |
同時実行安全性 | 分散ロック(SET NX EX) | 複数リクエストからの並列書き込み時におけるデータ整合性を保証します。 |
弾力的な回復力 | 読み書き分離およびバースト帯域幅 | 春節イベントにおける 10 倍のピークなど、大規模なトラフィックスパイクに、シームレスな弾力性で対応します。 |
AI エージェント技術の進化に伴い、メモリ管理もより深いレベルへと進化しています。今後の計画として、ユーザーのプリファレンスや過去の行動パターンを保存する長期記憶機能の構築が予定されています。これにより、エージェントは「今回の対話で何が話されたか」だけでなく、「このユーザーが誰で、何を好むのか」も記憶できるようになります。
AI エージェントのメモリシステムは、「対話レベル」から「ユーザー単位」へと進化しており、Tair はこの進化において引き続き重要な役割を果たします。