このトピックでは、条件付きフィルタリング、ベクトル検索、全文検索の任意の組み合わせを実装する TairVector ベースのハイブリッド検索ソリューションについて説明します。
背景情報
大規模言語モデル (LLM) は、テキスト、画像、音声、動画などの非構造化データをベクトルを使用してセマンティックに表現することを可能にします。ベクトルベースの k近傍 (kNN) 検索は、セマンティック検索、パーソナライズされた商品推薦、インテリジェント Q&A などの分野で主要な役割を果たすと期待されています。通常、ほとんどのベクトルデータベースサービスは、条件付きフィルタリング、全文検索、ベクトル検索という検索メソッドのうち、1つまたは2つの組み合わせをサポートしています。これらのメソッドには、それぞれ明確な長所と短所があります。
条件付きフィルタリング:ブール式を使用してデータをフィルタリングし、データセットとその使用法に厳格な制約を課すため、特定のシナリオにのみ適しています。
全文検索:クエリをトークン化してドキュメントの関連性を計算し、クエリに最も関連性の高い結果のリストを返します。このメソッドは、入力エラーや文法の問題が発生しやすいテキストベースのクエリに限定されます。
ベクトル検索:セマンティックエンコーディングを実行し、ベクトル間の類似度を計算してから、最も類似した結果のリストを返します。このメソッドは、さまざまなシナリオでドキュメント、画像、音声、動画など、複数の種類の非構造化データを処理できます。ただし、このメソッドは LLM に大きく依存しており、企業固有のデータを処理する際に不正確な結果を返す可能性があります。
TairVector を使用すると、関連するデータベース内で前述の検索メソッドの任意の組み合わせを実現できます。これら 3つの検索メソッドを 1つのステートメントで組み合わせることができます。このステートメントでは、画像、テキスト、音声、動画を使用してベクトル検索を実装し、テキストを使用して全文検索を実装し、ブール式を使用して条件付きフィルタリングを実装できます。さらに、TairVector はこれらのメソッドの結果を重みでソートし、最終的な候補リストを返します。
これにより、単一の検索メソッドの限界を超えて、データ取得のヒット率を高めることができます。具体的には、`hybrid_ratio` パラメーターを使用して、特定のリクエストに基づいて異なる検索メソッドに割り当てられる重みを調整できます。詳細については、「Vector」をご参照ください。
ソリューション概要
この例では、オープンソースの fashion-product-images-small データセットを使用して、さまざまなソリューションのパフォーマンスを実証します。
オープンソースのデータセットを使用する場合は、関連する契約、法律、規制を遵守する必要があります。
データの説明
このデータセットには、44,000 件の商品データエントリが含まれています。次の表にデータ形式を示します。
id (int64) | gender (string) | masterCategory (string) | subCategory (string) | articleType (string) | baseColour (string) | season (string) | year (float64) | usage (string) | productDisplayName (string) | image (dict) |
15,970 | "Men" | "Apparel" | "Topwear" | "Shirts" | "Navy Blue" | "Fall" | 2,011 | "Casual" | "Turtle Check Men Navy Blue Shirt" | { "bytes": [ 255, 216, 255, ... ], "path": null } |
39,386 | "Men" | "Apparel" | "Bottomwear" | "Jeans" | "Blue" | "Summer" | 2,012 | "Casual" | "Peter England Men Party Blue Jeans" | { "bytes": [ 255, 216, 255, ...], "path": null } |
59,263 | "Women" | "Accessories" | "Watches" | "Watches" | "Silver" | "Winter" | 2,016 | "Casual" | "Titan Women Silver Watch" | { "bytes": [ 255, 216, 255, ...], "path": null } |
データの変換
TairVector は、シンプルで直感的な Tair vector index Key-Key-(Key-Value) ストレージ構造を使用します。まず、hybrid_index のようなベクトルインデックスを作成して、すべての商品データを格納します。次に、テーブルのデータ構造を変換します。フィールドは 4つのカテゴリに分類されます:
id を TairVector での検索用のプライマリキーに変換します。このフィールドを使用してポイントクエリを実装できます。ポイントクエリは少量のデータのみをスキャンします。
image フィールドのデータを LLM を使用してエンコードされたベクトルに変換します。これらのベクトルに基づいて検索を実装できます。
productDisplayName フィールドのデータを、対応する image フィールドのデータの説明に変換します。この説明を使用して全文検索を実装できます。
その他のフィールド を TairVector の最下層のキーと値のペアに変換します。これらのキーと値のペアの数に制限はありません。これらのキーと値のペアを使用して、属性による従来のフィルタリングを実装できます。
次の図は、TairVector のデータ構造を示しています。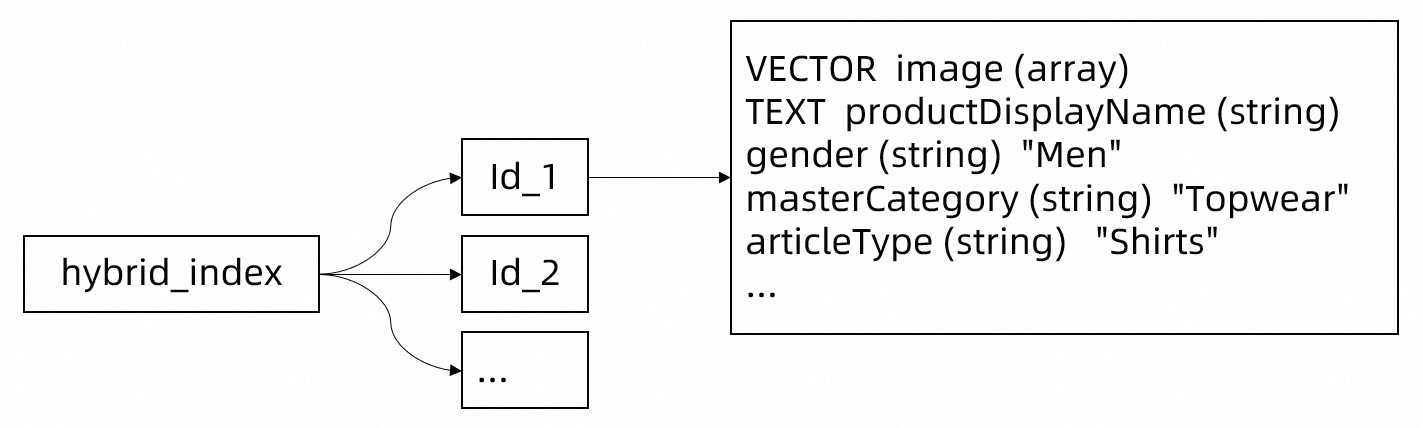
手順とサンプルコード
この例の手順:
データセットをロードします。
Tair 環境を準備します。
データセットを Tair にインポートします。
さまざまなソリューションを使用してデータをクエリします。
詳細については、「Hybrid search コードプロジェクト」をご参照ください。
このコードは .ipynb ファイルです。使用する前に、pip install jupyter コマンドを実行して必要な依存関係をインストールできます。
クエリの表示
次のコードは、さまざまな検索ソリューションを使用したクエリの実行方法とその結果を示しています。クエリの例は Green Kidswear です。テストは、`hybrid_ratio` パラメーターを調整して 4つのシナリオで実行されます。`hybrid_ratio` パラメーターはベクトル検索の重みであり、全文検索の重みは 1-hybrid_ratio です。
ベクトル検索:`hybrid_ratio` パラメーターを 0.9999 に設定します。
topk = 20 text = "Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.9999} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)結果:

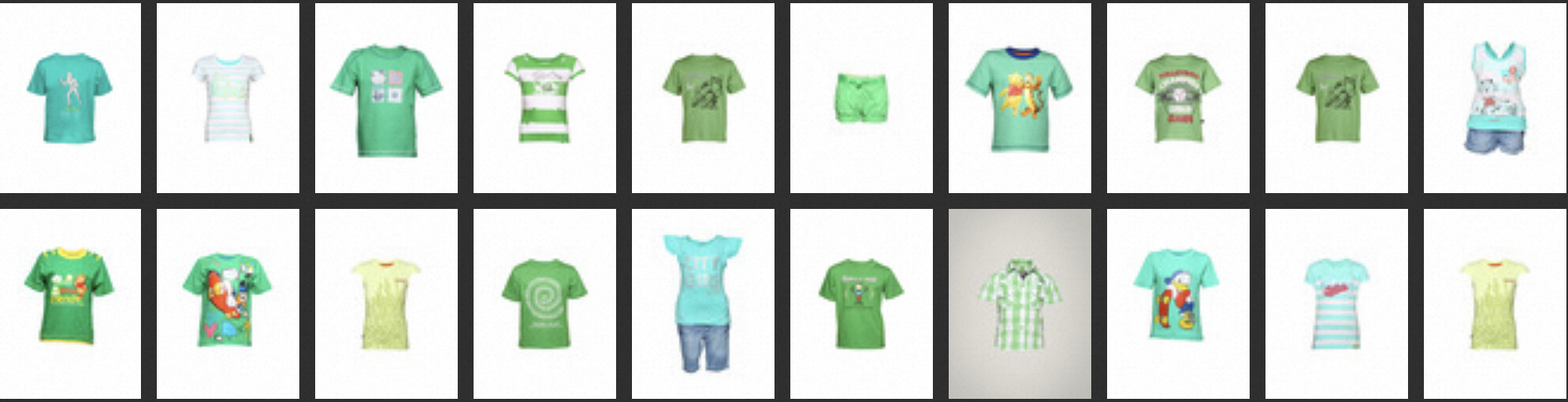
全文検索:`hybrid_ratio` パラメーターを 0.0001 に設定します。
topk = 20 text = ""Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.0001} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)結果:
ベクトル検索と全文検索を組み合わせたハイブリッド検索:`hybrid_ratio` パラメーターを 0.5 に設定します。
topk = 20 text = ""Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.5} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)結果:

ベクトル、全文、条件付きフィルターのハイブリッド検索:`hybrid_ratio` パラメーターを 0.5 に設定し、
subCategory == "Topwear"条件付きステートメントを追加します。topk = 20 text = "Green Kidswear" vector = model.encode([text])[0] filter_str = "subCategory == \"Topwear\"" kwargs = {"TEXT" : text, "hybrid_ratio" : 0.5} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) print(result) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)結果:

まとめ
上記の結果に基づくと、ベクトル検索と全文検索の両方がクエリ要件を満たすことができます。上位にランク付けされた候補セットに基づくと、全文検索のパフォーマンスはベクトル検索よりもわずかに高くなっています。
ハイブリッド検索ソリューションの場合、ある商品が 2つの検索メソッドで取得されると、その商品は他の商品よりも上位にランク付けされます。
`hybrid_ratio` パラメーターを使用して、ハイブリッドソリューションにおける検索メソッドの重みを調整できます。これにより、結果を再ランキングして、より正確な結果を得ることができます。
条件付きフィルタリングを使用して特定の候補セットを除外することで、ベクトル検索のヒット率を向上させることができます。