ApsaraDB RDS for SQL Server は、クラウドへの増分バックアップデータ移行を提供します。自己管理型 SQL Server インスタンスからの完全バックアップファイルを Object Storage Service (OSS) バケットに保存し、ApsaraDB RDS コンソールを介して ApsaraDB RDS for SQL Server インスタンスに復元できます。その後、差分バックアップファイルまたはログバックアップファイルをインポートして、クラウドへの増分バックアップデータ移行を実装できます。この移行方法により、ダウンタイムが数分に短縮されます。
シナリオ
このトピックの移行方法は、次のシナリオに適しています:
論理モードではなく物理モードで RDS インスタンスにデータを移行します。
説明物理移行では、物理バックアップファイルを使用してデータを移行できます。論理移行では、実行されたデータ操作言語 (DML) 文を RDS インスタンスに書き込むことができます。
物理移行は、自己管理データベースとターゲットデータベース間の 100% のデータ整合性を保証します。論理移行では 100% のデータ整合性を保証できません。たとえば、インデックスの断片化や統計情報が移行後に変更される可能性があります。
数分レベルのダウンタイムでデータを移行します。
説明アプリケーションがダウンタイムに敏感でなく (たとえば、2 時間のダウンタイムを許容できる)、データベースが 100 GB 未満の場合は、クラウド移行のための完全バックアップファイルを使用することをお勧めします。
前提条件
RDS インスタンスが次の要件を満たしていること:
RDS インスタンスは SQL Server 2012 以降、またはクラウドディスクを備えた SQL Server 2008 R2 を実行していること。
RDS インスタンス上の既存のデータベースの名前が、自己管理型 SQL Server インスタンス上のソースデータベースの名前と異なること。
RDS インスタンスの利用可能なストレージが、移行したいデータファイルのサイズよりも大きいこと。利用可能なストレージが不十分な場合は、移行を開始する前に RDS インスタンスのストレージ容量を拡張する必要があります。
自己管理型 SQL Server インスタンスが
FULL復元モデルを使用していること。説明自己管理型 SQL Server インスタンスから RDS インスタンスに増分バックアップデータを移行する場合、トランザクションログのバックアップが必要です。自己管理型 SQL Server インスタンスが SIMPLE 復元モデルを使用している場合、トランザクションログはバックアップできません。
差分バックアップファイルのサイズが大きい場合、増分バックアップデータの移行に必要な時間が増加する可能性があります。
Resource Access Management (RAM) ユーザーを使用する場合、次の条件を満たす必要があります:
RAM ユーザーに AliyunOSSFullAccess および AliyunRDSFullAccess 権限が付与されていること。RAM ユーザーに権限を付与する方法の詳細については、「RAM を使用した OSS 権限の管理」および「RAM を使用した ApsaraDB RDS 権限の管理」をご参照ください。
Alibaba Cloud アカウントが、ApsaraDB RDS サービスアカウントに OSS リソースへのアクセス権限を付与していること。
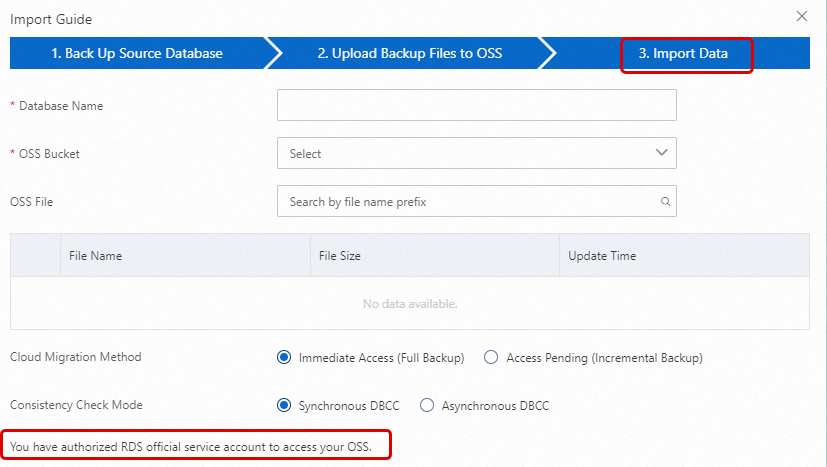
ApsaraDB RDS インスタンスの [バックアップと復元] ページに移動し、[OSS バックアップからの復元] をクリックします。
[データインポートウィザード] で、[次へ] を 2 回クリックして、ステップ [3. データインポート] に進みます。
ページの左下隅に [公式 RDS サービスアカウントに OSS リソースへのアクセスを承認しました] というメッセージが表示されている場合、権限付与は完了しています。そうでない場合は、ページの [権限付与 URL] をクリックして権限を付与します。
Alibaba Cloud アカウントは、手動でアクセスポリシーを作成し、そのポリシーを RAM ユーザーにアタッチする必要があります。
準備
自己管理データベースで DBCC CHECKDB 文を実行し、allocation errors または consistency errors が発生しないことを確認します。割り当てエラーまたは整合性エラーが発生しない場合、次の実行結果が返されます:
...
CHECKDB found 0 allocation errors and 0 consistency errors in database 'xxx'.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.使用上の注意
移行レベル: このトピックの移行方法は、単一のデータベースの移行のみをサポートします。複数のデータベースまたはすべてのデータベースを移行する場合は、「自己管理型 SQL Server インスタンスから ApsaraDB RDS for SQL Server インスタンスへのデータ移行」をご参照ください。
バージョンの互換性: 新しい SQL Server バージョンから古い SQL Server バージョンへの移行はサポートされていません。
権限管理: ApsaraDB RDS のサービスアカウントに OSS バケットへのアクセスを承認すると、Resource Access Management (RAM) に
AliyunRDSImportRoleという名前のロールが作成されます。このロールを変更または削除しないでください。そうしないと、移行が失敗します。このロールを変更または削除した場合は、移行ウィザードを使用してサービスアカウントを再承認する必要があります。アカウント管理: 移行が完了した後、自己管理型 SQL Server インスタンスのアカウントは使用できません。ApsaraDB RDS コンソールで RDS インスタンスのアカウントを作成する必要があります。
OSS ファイルの保持: 移行が完了するまで、OSS バケットからバックアップファイルを削除しないでください。そうしないと、移行が失敗します。
バックアップファイルの要件:
ファイル名の制限: バックアップファイルの名前に特殊文字 (
!@#$%^&*()_+-=など) を含めることはできません。そうしないと、移行が失敗します。ファイルのサフィックス: バックアップファイルの名前には、
.bak(完全バックアップファイル)、.diff(差分バックアップファイル)、.trn、または.log(ログバックアップファイル) のサフィックスを付ける必要があります。システムは他のファイルタイプを認識できません。説明実際のビジネスシナリオでは、バックアップファイルが異なる形式で保存されることがあります。たとえば、
.bakのサフィックスが付いたファイルは、完全バックアップファイル、差分バックアップファイル、またはログバックアップファイルである可能性があります。バックアップファイルが、(このトピックのステップ 1 の公式スクリプトで生成された
.bakバックアップファイルではなく) ApsaraDB RDS コンソールでダウンロードされた自己管理型 SQL Server インスタンスのログバックアップファイルである場合、ダウンロードされたバックアップファイルのデフォルト形式は.zip.logです。ダウンロードされたバックアップファイルは、ファイル形式を変換した後にクラウド移行に使用できます。処理方法: ファイルの拡張子を
.zipに変更して展開し、展開されたdatabase_name.lbakファイルを.bakのサフィックスが付いたファイルに名前を変更し、その後.bakファイルを増分ログバックアップファイルとして OSS バケットにアップロードしてクラウド移行を行います。
操作フローの例
移行フェーズ | ステップ | 説明 |
完全データ移行ステージ | ステップ 1. 00:00 前 | 次の準備を完了します:
|
ステップ 2. 00:01 | ソースデータベースで完全バックアップを実行します。所要時間: 約 1 時間。 | |
ステップ 3. 02:00 | 完全バックアップファイルを OSS バケットにアップロードします。所要時間: 約 1 時間。 | |
ステップ 4. 03:00 | ApsaraDB RDS コンソールで、完全バックアップファイルから RDS インスタンスにデータを復元します。所要時間: 約 19 時間。 | |
増分フェーズ | ステップ 5. 22:00 | ソースデータベースでログバックアップを実行します。所要時間: 約 20 分。 |
ステップ 6. 22:20 | ログバックアップファイルを OSS バケットにアップロードします。所要時間: 約 10 分。 | |
ステップ 6. 22:30 |
| |
データベースのオープン | ステップ 8. 22:34 | 最後の LOG バックアップファイルのクラウドへの増分アップロードが完了しました。所要時間は 4 分でした。現在、データベースをオンラインにする作業を開始しています。 |
ステップ 9. 22:35 | RDS インスタンスでターゲットデータベースを開きます。非同期モードで DBCC 文を実行する場合、ターゲットデータベースは 1 分で開くことができます。 |
上記の移行は、ダウンタイムを最小限に抑える方法の例を示しています。アプリケーションは実行を継続でき、最後のログバックアップまでアプリケーションを停止する必要はありません。この例では、アプリケーションのダウンタイムは 5 分を超えません。
1. ソースデータベースのバックアップ
バックアップスクリプトをダウンロードし、SQL Server Management Studio (SSMS) を使用して開きます。
次のパラメーターを設定します:
パラメーター
説明
@backup_databases_list
バックアップするソースデータベースの名前。複数のデータベースを指定する場合は、データベース名をセミコロン (;) またはカンマ (,) で区切ります。
@backup_type
バックアップのタイプ。有効な値:
FULL: 完全バックアップ
DIFF: 差分バックアップ
LOG: ログバックアップ
@backup_folder
自己管理データベースにバックアップファイルを保存するために使用されるディレクトリ。指定したディレクトリが存在しない場合、システムは自動的に作成します。
@is_run
バックアップを実行するか、チェックを実行するかを指定します。有効な値:
1: バックアップを実行します。
0: チェックのみを実行します。
バックアップスクリプトを実行します。
実行後、指定したバックアップタイプに関係なく、
.bakファイルが自動的に生成されます。
2. バックアップファイルの OSS へのアップロード
バックアップファイルを OSS にアップロードする前に、OSS にバケットを作成する必要があります。
OSS にバケットが既に存在する場合、バケットが次の要件を満たしていることを確認してください:
OSS にバケットが存在しない場合は、作成する必要があります。 (OSS をアクティベートしていることを確認してください)
OSS コンソールにログインし、[バケット] をクリックし、次に [バケットの作成] をクリックします。
次のパラメーターを設定します。他のパラメーターはデフォルト値のままにします。
重要バケットは主にこのデータ移行に使用され、主要なパラメーターのみを設定する必要があります。移行が完了したら、データ漏洩を防ぎ、関連コストを回避するためにバケットを削除できます。
バケットを作成する際にデータ暗号化を有効にしないでください。
パラメーター
説明
例
バケット名
OSS バケットの名前。名前はグローバルに一意であり、設定後に変更することはできません。
命名規則:
名前には小文字、数字、ハイフン (-) のみを含めることができます。
名前は小文字または数字で開始および終了する必要があります。
名前の長さは 3〜63 文字である必要があります。
migratetest
リージョン
OSS バケットのリージョン。Elastic Compute Service (ECS) インスタンスから内部ネットワーク経由で OSS バケットにデータをアップロードし、その後内部ネットワーク経由で RDS インスタンスにデータを復元する場合は、OSS バケット、ECS インスタンス、および RDS インスタンスが同じリージョンにあることを確認してください。
中国 (杭州)
ストレージクラス
[標準] を選択します。このトピックで説明されているクラウド移行操作は、他のストレージクラスのバケットでは実行できません。
標準
バックアップファイルを OSS バケットにアップロードします。
自己管理データベースがバックアップされた後、バックアップファイルを RDS インスタンスと同じリージョンにある OSS バケットにアップロードします。OSS バケットと RDS インスタンスが同じリージョンにある場合、内部ネットワークを介して相互に通信できます。これにより、インターネットトラフィック料金の発生を防ぎ、データアップロードを高速化します。次のいずれかの方法を使用できます:
ossbrowser をダウンロードします。
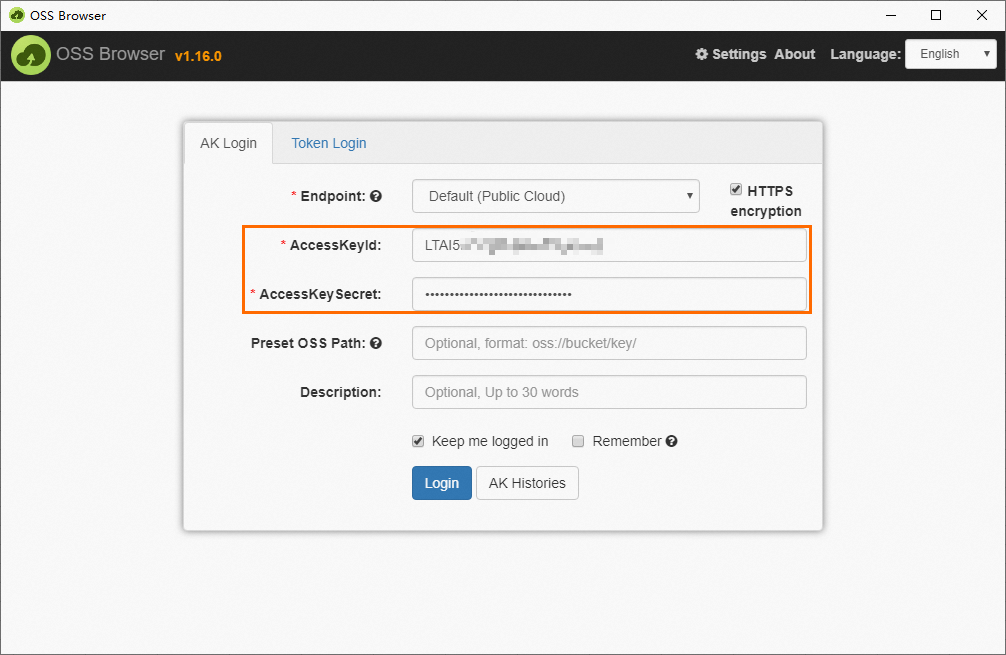
たとえば、オペレーティングシステムが Windows x64 の場合、ダウンロードした
oss-browser-win32-x64.zipパッケージを展開し、oss-browser.exeアプリケーションをダブルクリックします。ログイン方法として [AK] を使用し、[AccessKeyId] および [AccessKeySecret] パラメーターを設定し、他のパラメーターはデフォルト値のままにして、[ログイン] をクリックします。
説明AccessKey は、データセキュリティを確保するための ID 検証に使用されます。AccessKey は安全に保管してください。
ターゲットバケットをクリックしてストレージスペースに移動します。

 をクリックし、アップロードするバックアップファイルを選択し、[開く] をクリックしてローカルファイルを OSS にアップロードします。
をクリックし、アップロードするバックアップファイルを選択し、[開く] をクリックしてローカルファイルを OSS にアップロードします。
説明バックアップファイルのサイズが 5 GB 未満の場合は、OSS コンソールでバックアップファイルをアップロードすることをお勧めします。
OSS コンソールにログインします。
[バケット] をクリックし、ターゲットバケットの名前をクリックします。
[ファイル] セクションで、[アップロード] をクリックします。
バックアップファイルを [アップロードするファイル] セクションにドラッグアンドドロップするか、[ファイルを選択] をクリックしてアップロードするバックアップファイルを選択できます。
ページ下部の [アップロード] をクリックして、ローカルバックアップファイルを OSS にアップロードします。
3. クラウド移行タスクの作成
インスタンスページに移動します。上部のナビゲーションバーで、RDS インスタンスが存在するリージョンを選択します。次に、RDS インスタンスを見つけて、インスタンスの ID をクリックします。
左側のナビゲーションウィンドウで、[バックアップと復元] をクリックします。
ページの上部にある [OSS バックアップデータのクラウドへの復元] をクリックします。
[インポートガイド] ウィザードで、[次へ] を 2 回クリックしてデータをインポートします。
説明OSS ベースの移行ウィザードを初めて使用する場合、ApsaraDB RDS のアカウントに OSS バケットへのアクセスを承認する必要があります。この場合、[承認] をクリックして承認を完了する必要があります。そうしないと、データインポートステップの [OSS バケット] ドロップダウンリストが空になります。
次のパラメーターを設定し、[OK] をクリックします。
移行タスクが完了するまで待ちます。[更新] をクリックして、移行タスクの最新のステータスを表示できます。移行タスクが失敗した場合は、エラーメッセージに基づいて問題をトラブルシューティングします。詳細については、このトピックの「一般的なエラー」をご参照ください。
パラメーター
説明
データベース名
RDS インスタンス上のターゲットデータベースの名前を入力します。ターゲットデータベースは、自己管理型 SQL Server インスタンスのソースデータベースから移行されたデータを保存するために使用されます。ターゲットデータベースの名前は、オープンソース SQL Server の要件を満たす必要があります。
重要移行前に、ターゲット RDS インスタンス上のデータベースの名前が、指定されたバックアップファイルを使用して復元するデータベースの名前と異なることを確認する必要があります。さらに、指定されたバックアップファイルを使用して復元するデータベースと同じ名前のデータベースファイルが、ターゲット RDS インスタンス上のデータベースに追加されていないことを確認してください。両方の要件が満たされている場合、バックアップセット内のデータベースファイルを使用してデータベースを復元できます。データベースファイルは、復元するデータベースと同じ名前である必要があることに注意してください。
バックアップファイルで指定されたデータベースと同じ名前のデータベースが宛先インスタンスに既に存在する場合、または同じ名前のアタッチされていないデータベースファイルがある場合、復元操作は失敗します。
OSS バケット
完全バックアップファイルを保存する OSS バケットを選択します。
OSS ファイルリスト
右側の虫眼鏡ボタンをクリックして、バックアップファイル名のプレフィックスに基づいてあいまい一致でバックアップファイルを検索します。システムは、各バックアップファイルの名前、サイズ、および更新時刻を表示します。クラウドに移行するバックアップファイルを選択します。
クラウド移行方法
[データベースを作成しない] を選択します。
即時アクセス (完全バックアップ): この方法は、クラウドへの完全データ移行に適しています。 完全バックアップファイルのみを移行する場合は、この移行方法を選択します。この場合、CreateMigrateTask 操作で次のパラメーター設定が有効になります:
BackupMode = FULLおよびIsOnlineDB = True。アクセス保留 (増分バックアップ): この方法は、クラウドへの増分データ移行に適しています。 完全バックアップファイルとログまたは差分バックアップファイルを移行する場合は、この移行方法を選択します。この場合、CreateMigrateTask 操作で次のパラメーター設定が有効になります:
BackupMode = UPDFおよびIsOnlineDB = False。
4. ログまたは差分バックアップファイルのインポート
自己管理型 SQL Server インスタンスのソースデータベースの完全バックアップファイルが RDS インスタンスのターゲットデータベースにインポートされた後、ログまたは差分バックアップファイルをインポートする必要があります。
インスタンスページに移動します。上部のナビゲーションバーで、RDS インスタンスが存在するリージョンを選択します。次に、RDS インスタンスを見つけて、インスタンスの ID をクリックします。
左側のナビゲーションウィンドウで、[バックアップと復元] をクリックします。表示されたページで、[バックアップデータのクラウド移行記録] タブをクリックします。
ターゲットデータベースを見つけ、[タスクアクション] 列の [増分ファイルのアップロード] をクリックします。増分ファイルを選択し、[OK] をクリックします。
説明複数のログバックアップファイルがある場合は、同じ方法を使用してログバックアップファイルを 1 つずつアップロードする必要があります。
最後のログまたは差分バックアップファイルのサイズが 500 MB を超えないようにしてください。これにより、移行を完了するために必要な時間が最小限に抑えられます。
最後のログまたは差分バックアップファイルが生成される前に、自己管理データベースへのデータ書き込みを停止する必要があります。これにより、自己管理データベースと RDS インスタンス上のターゲットデータベースとの間のデータ整合性が確保されます。
5. データベースのオープン
すべてのバックアップファイルを RDS インスタンスのターゲットデータベースにインポートした後、ターゲットデータベースは 回復中 または 復元中 の状態になります。RDS インスタンスが RDS High-availability Edition を実行している場合、ターゲットデータベースは 回復中 の状態になります。RDS インスタンスが RDS Basic Edition を実行している場合、ターゲットデータベースは 復元中 の状態になります。これらの場合、ターゲットデータベースで読み取りまたは書き込み操作を実行することはできません。読み取りおよび書き込み操作を実行する前に、ターゲットデータベースを開く必要があります。
インスタンスページに移動します。上部のナビゲーションバーで、RDS インスタンスが存在するリージョンを選択します。次に、RDS インスタンスを見つけて、インスタンスの ID をクリックします。
左側のナビゲーションウィンドウで、[バックアップと復元] をクリックします。表示されたページで、[バックアップデータのクラウド移行記録] タブをクリックします。
ターゲットデータベースを見つけ、[タスクアクション] 列の [データベースを開く] をクリックします。
整合性チェックモードを選択し、[OK] をクリックします。
説明ApsaraDB RDS は、次の整合性チェックモードを提供します:
非同期 DBCC: DBCC CHECKDB 文は、ターゲットデータベースが開かれた後に実行されます。これにより、ターゲットデータベースを開くのに必要な時間が短縮され、アプリケーションのダウンタイムが最小限に抑えられます。ターゲットデータベースが大きい場合、DBCC CHECKDB 文の実行に長時間を要します。アプリケーションがダウンタイムに敏感であるが、DBCC CHECKDB 文の結果に敏感でない場合は、この整合性チェックモードを選択することをお勧めします。この場合、CreateMigrateTask 操作で次のパラメーター設定が有効になります:
CheckDBMode = AsyncExecuteDBCheck。同期 DBCC: DBCC CHECKDB 文は、ターゲットデータベースが開かれると同時に実行されます。DBCC CHECKDB 文の結果に基づいて自己管理データベースとターゲットデータベースの間の整合性エラーを特定したい場合は、この整合性チェックモードを選択することをお勧めします。ただし、ターゲットデータベースを開くのに必要な時間が増加します。この場合、CreateMigrateTask 操作で次のパラメーター設定が有効になります:
CheckDBMode = SyncExecuteDBCheck。
6. インポートされたバックアップファイルの詳細の表示
RDS インスタンスの左側のナビゲーションウィンドウから [バックアップと復元] ページに移動します。表示されたページで、[バックアップデータのクラウド移行記録] タブをクリックして、バックアップ移行記録を表示します。対応するタスクの [タスクアクション] 列にある [ファイル詳細の表示] をクリックして、そのタスクに関連するすべてのバックアップファイルの詳細を表示します。
クラウド移行が完了すると、システムは RDS インスタンスの自動バックアップポリシーで指定されたバックアップ時間に基づいてデータをバックアップします。生成されたバックアップセットには、クラウドに移行されたデータが含まれます。詳細は RDS インスタンスの [バックアップと復元] ページで確認できます。バックアップ時間は手動で調整できます。
指定されたバックアップ時間に達していないが、クラウドにバックアップファイルが必要な場合は、手動バックアップをトリガーできます。
一般的なエラー
完全バックアップデータの移行中に発生する可能性のある一般的なエラーの詳細については、完全バックアップデータの移行に関するトピックの「一般的なエラー」をご参照ください。
増分バックアップデータの移行中に、次のエラーが発生する可能性があります:
ターゲットデータベースを開けません
エラーメッセージ: データベース xxx を開けませんでした。
原因: 自己管理型 SQL Server インスタンスで一部の高度な機能が有効になっています。ただし、これらの高度な機能は RDS インスタンスではサポートされていません。たとえば、自己管理型 SQL Server インスタンスが SQL Server の Enterprise Edition を実行しており、RDS インスタンスが SQL Server の Web Edition を実行している場合です。自己管理型 SQL Server インスタンスでデータ圧縮およびパーティション機能が有効になっている場合、RDS インスタンスでターゲットデータベースを開くとこのエラーが報告されます。
解決策:
自己管理型 SQL Server インスタンスの高度な機能を無効にし、再度データをバックアップしてから、OSS を使用してデータを移行します。
自己管理型 SQL Server インスタンスと同じ SQL Server エディションを実行する RDS インスタンスを購入します。購入方法の詳細については、「ApsaraDB RDS for SQL Server インスタンスの作成と使用」をご参照ください。
説明詳細については、「異なる SQL Server バージョンと RDS エディションを実行する ApsaraDB RDS インスタンスの機能」をご参照ください。
バックアップチェーン内のログシーケンス番号 (LSN) が連続していません
エラーメッセージ: このバックアップセットのログは LSN XXX から始まりますが、これはデータベースに適用するには新しすぎます。RESTORE LOG は異常終了しています。
原因: ログまたは差分バックアップファイル内の LSN が、復元に使用された前のバックアップファイルの LSN と異なります。
解決策: 対応する LSN バックアップファイルを選択して、増分バックアップファイルをアップロードします。各バックアップ操作の時間に基づいて、時系列で増分アップロードを実行できます。
DBCC CHECKDB 文を非同期モードで実行できません
エラーメッセージ: 非同期 DBCC checkdb が失敗しました: CHECKDB はテーブル 'XXX' (オブジェクト ID XXX) で 0 個の割り当てエラーと 2 個の整合性エラーを検出しました。
原因: 非同期 DBCC 整合性チェックモードを選択して RDS インスタンスにデータが復元された後、ApsaraDB RDS は DBCC CHECKDB 文を実行します。ターゲットデータベースが整合性チェックに失敗した場合、自己管理データベースで整合性エラーが発生します。
解決策:
ターゲットデータベースで次の文を実行します:
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)重要この文を実行してエラーを修正すると、データが失われる可能性があります。
自己管理データベースで次の文を実行してエラーを修正し、再度データを移行します:
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)
選択されたバックアップファイルは完全バックアップファイルです
エラーメッセージ: バックアップセット (xxx) はデータベースの完全バックアップです。トランザクションログまたは差分バックアップのみを受け付けます。
原因: 完全バックアップファイルを使用して RDS インスタンスにデータが復元された後、ログまたは差分バックアップファイルのみを選択できます。再度完全バックアップファイルを選択すると、このエラーが報告されます。
解決策: ログまたは差分バックアップファイルを選択します。
指定されたソースデータベースの数が上限を超えています
エラーメッセージ: データベース (xxx) の移行は、データベース数の制限により失敗しました。
原因: 指定されたソースデータベースの数が上限を超えると、このエラーが報告されます。
解決策: ソースデータベースのデータを別の RDS インスタンスに移行します。そうでない場合は、不要なデータベースを削除します。
RAM ユーザーに必要な権限がありません
Q1: クラウド移行タスクの作成のステップ 5 を実行する際、すべてのパラメーター値が正しく設定されているにもかかわらず、[OK] ボタンが選択不可になっているのはなぜですか?
A1: ボタンが選択不可になっているのは、必要な権限を持たない RAM ユーザーを使用しているため可能性があります。このトピックの前提条件セクションを参照して、必要な権限が付与されていることを確認してください。
Q2: RAM ユーザーを使用して
AliyunRDSImportRole権限を付与する際にno permissionエラーを解決するにはどうすればよいですか?A2: Alibaba Cloud アカウントを使用して、RAM ユーザーに一時的に
AliyunRAMFullAccess権限を付与します。RAM ユーザーに権限を付与する方法の詳細については、「RAM を使用して ApsaraDB RDS 権限を管理する」をご参照ください。
関連 API 操作
API | 説明 |
OSS から ApsaraDB RDS for SQL Server インスタンスにバックアップファイルを復元し、データ移行タスクを作成します。 | |
ApsaraDB RDS for SQL Server データ移行タスクのデータベースを開きます。 | |
ApsaraDB RDS for SQL Server インスタンスのデータ移行タスクのリストを照会します。 | |
ApsaraDB RDS for SQL Server データ移行タスクのファイル詳細を照会します。 |