このトピックでは、列ストアのスナップショットのスナップショットポイントを生成する方法と、スナップショットポイントが生成された後に、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシにこれらのスナップショットポイントがどのように影響するかについて説明します。
サポートされているバージョン
3 桁のバージョン番号 | コンピュートノードのバージョン | 推奨バージョン | データノード データベースエンジンのバージョン |
5.4.20 | すべてのバージョン | 5.4.20-20250328 以降(列ストア スナップショット最適化) | MySQL 5.7 または MySQL 8.0 |
5.4.19 | 5.4.19-20250305 以降 | - | MySQL 5.7 または MySQL 8.0 |
インスタンスのバージョンの命名規則については、「リリースノート」をご参照ください。
インスタンスのバージョンを表示する方法については、「インスタンスのバージョンを表示および更新する」をご参照ください。
スナップショットポイントを手動で生成する
次の関数を 実行して、インスタンスレベルのスナップショットポイントを生成します。
CALL polardbx.columnar_flush();説明CALL polardbx.columnar_flush()関数はスナップショットポイントを生成し、スナップショットポイントのバージョン(タイムゾーンに依存しないタイムスタンプ)を表すunsigned long型の値を返します。次の関数を 実行して、指定された CCI のスナップショットポイントを生成します。
CALL polardbx.columnar_flush(schema_name, table_name, index_name); -- 例えば、実際のサフィックスをインデックス名に追加するかしないか(SHOW COLUMNAR STATUS 文を使用してサフィックスを表示できます)。 CALL polardbx.columnar_flush('db1', 'tb1', 'cci'); CALL polardbx.columnar_flush('db1', 'tb1', 'cci_$09a9');説明index_nameは CCI の名前です。index_name値を取得する方法の詳細については、「SHOW COLUMNAR STATUS」をご参照ください。CCI レベルのスナップショットは、インスタンス全体の整合性のあるスナップショットですが、単一のテーブルの整合性のあるスナップショットではありません。これは、インスタンスレベルのスナップショットポイントと同等です。
スナップショットポイントを自動的に生成する
次の関数を 実行して、定期的にスナップショットポイントを生成します。
-- データが生成される間隔。単位:分。
CALL polardbx.columnar_config(cci_id, 'auto_gen_columnar_snapshot_interval', 10);また、次の文を実行して、CRON 式に基づいてインスタンスレベルのスナップショットポイントの作成をスケジュールすることもできます。
バージョンの要件:
3 パートバージョン番号 | コンピュートノードバージョン | データノードコンポーネントバージョン(エンジンバージョン) |
5.4.20 | 5.4.20-20250328 以降 | MySQL 5.7、MySQL 8.0 |
5.4.19 | 5.4.19-20250305 以降 | MySQL 5.7、MySQL 8.0 |
# 1 時間ごとにスナップショットが作成されるようにスケジュールします。
CALL polardbx.columnar_auto_snapshot_config('ENABLE', '0 0 * * * ?', '+08:00');
# スケジュールされたスナップショット設定を表示します。
CALL polardbx.columnar_auto_snapshot_config('SHOW');
# スケジュールされたスナップショット機能を無効にします。
CALL polardbx.columnar_auto_snapshot_config('DISABLE');スナップショットポイントをクエリする
INFORMATION_SCHEMA.COLUMNAR_SNAPSHOTS ビューをクエリして使用可能なスナップショットポイント(手動および自動で生成されたスナップショットポイントを含む)を取得するには、次の文を実行します。
SELECT * FROM INFORMATION_SCHEMA.COLUMNAR_SNAPSHOTS;結果の例:
+------------------------+------------+------------+---------------------+
| SCHEMA_NAME | TABLE_NAME | INDEX_NAME | TSO |
+------------------------+------------+------------+---------------------+
| test_columnar_snapshot | tb1 | cci_$09a9 | 7249374192586457152 |
| polardbx | __global__ | __global__ | 7249332223843762240 |
| polardbx | __global__ | __global__ | 7249374271451955264 |
+------------------------+------------+------------+---------------------+次の表にパラメータを示します。
パラメータ | 説明 |
| スキーマの名前。 |
| CCI の物理名。インデックスの作成時に指定された論理名と比較して、 |
| CCI に対応する論理テーブルの名前。 |
SHOW COLUMNAR STATUS 文を使用して、
SCHEMA_NAME、TABLE_NAME、INDEX_NAME、およびTSOの値を取得することもできます。多数のスナップショットポイントが生成された場合は、
SCHEMA_NAME、TABLE_NAME、INDEX_NAME、およびTSO列を使用してフィルタリングすることをお勧めします。そうしないと、インスタンスのパフォーマンスに影響を与える可能性があります。
パフォーマンスへの影響をテストする
CALL polardbx.columnar_flush() 関数を実行してスナップショットポイントを生成する場合、行ストアインスタンスの読み取りおよび書き込み操作は影響を受けません。ただし、CALL polardbx.columnar_flush() 関数を頻繁に呼び出すと、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシが増加する可能性があります。
テスト環境
テストデータのサイズ
テストは 1,000 のウェアハウスに基づいて実行されます。次のリストは、各主要テーブルのデータ量を示しています。
bmsql_order_lineテーブルには 3 億行のデータが含まれています。bmsql_stockテーブルには 1 億行のデータが含まれています。bmsql_customer、bmsql_history、およびbmsql_oorderテーブルには、それぞれ 3,000 万行のデータが含まれています。
テストのインスタンス仕様
ノード名
ノード仕様
ノード数
コンピュートノード
4 コア、16 GB メモリ
2
データノード
4 コア、16 GB メモリ
4
カラムナエンジン
4 コア、32 GB メモリ
2
ECS インスタンスの仕様
ecs.hfg6.4xlarge(16 コア、64 GB メモリ) ECS インスタンスの購入方法の詳細については、「ECS コンソールの [カスタム起動] タブでインスタンスを作成し、インスタンスを管理する」をご参照ください。
テスト手順
TPC-C テストの環境をセットアップします。詳細については、「TPC-C テスト」をご参照ください。
次の文を実行して、
bmsql_stock、bmsql_customer、およびbmsql_order_lineテーブルの列ストア スナップショットを個別に作成します。CREATE CLUSTERED COLUMNAR INDEX cci ON `bmsql_stock`(s_i_id) PARTITION BY KEY(s_w_id) COLUMNAR_OPTIONS='{ "type":"snapshot", "snapshot_retention_days":"30", "auto_gen_columnar_snapshot_interval":"-1" }'; CREATE CLUSTERED COLUMNAR INDEX cci ON `bmsql_customer`(c_id) PARTITION BY KEY(c_w_id) COLUMNAR_OPTIONS='{ "type":"snapshot", "snapshot_retention_days":"7", "auto_gen_columnar_snapshot_interval":"-1" }'; CREATE CLUSTERED COLUMNAR INDEX cci ON `bmsql_order_line`(ol_i_id) PARTITION BY KEY(ol_w_id) columnar_options='{ "type":"snapshot", "snapshot_retention_days":"365", "auto_gen_columnar_snapshot_interval":"-1" }';コンピュートノードとデータノードの CPU 使用率が 50% に近くなったら、
CALL polardbx.columnar_flush()関数をさまざまな頻度で実行してスナップショットポイントを生成し、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシを観察します。
テスト結果
CALL polardbx.columnar_flush()関数を 1 分間に 60 回実行してスナップショットポイントを生成する場合の、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシを次の図に示します。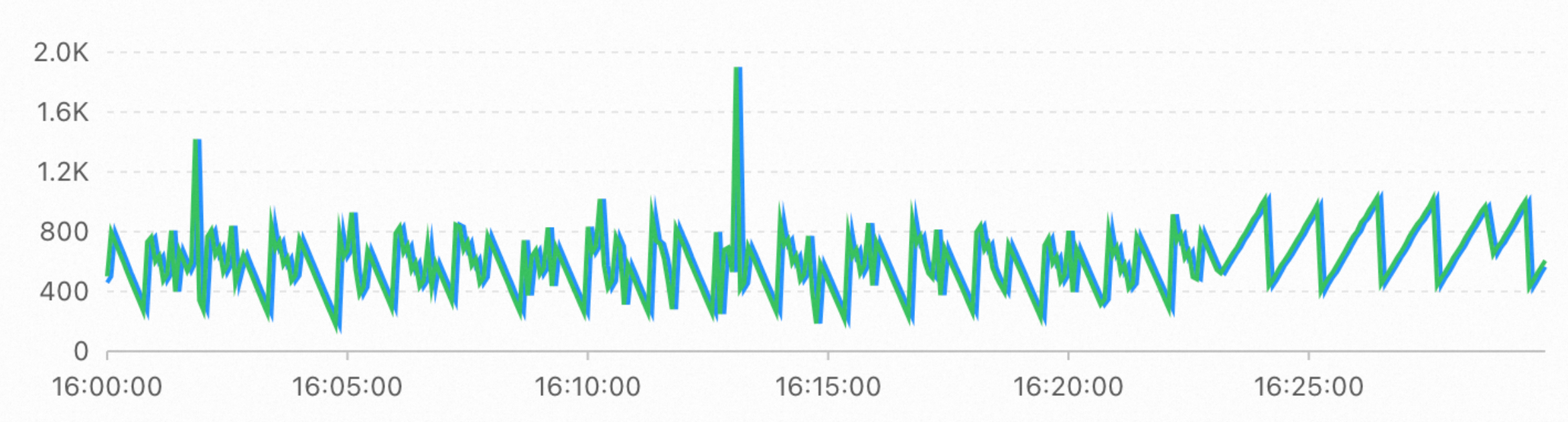
CALL polardbx.columnar_flush()関数を 1 分間に 480 回実行してスナップショットポイントを生成する場合の、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシを次の図に示します。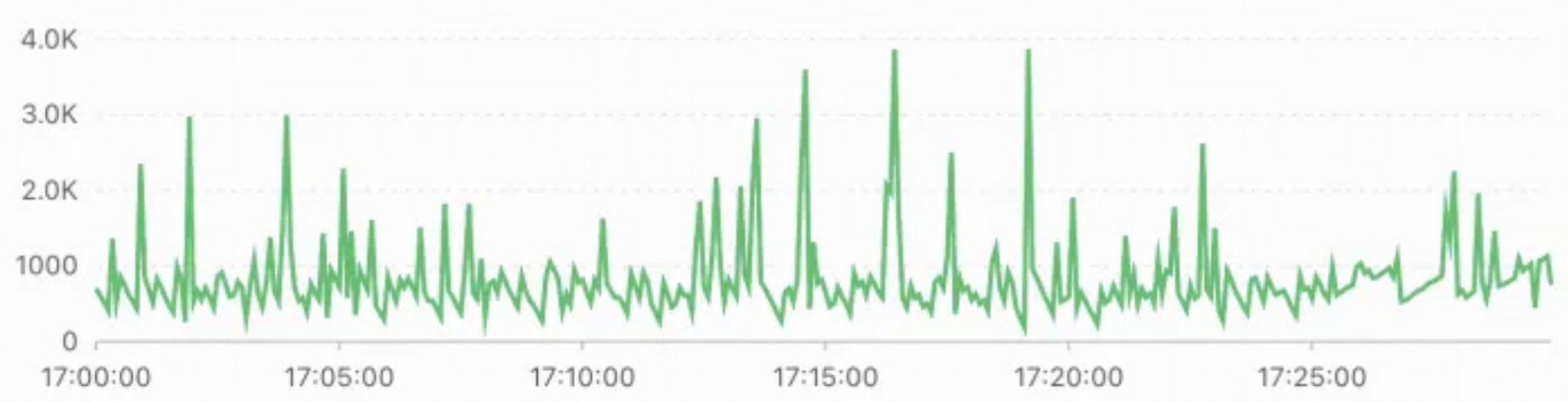 説明
説明データ同期のレイテンシは約 1 秒のままで、最大は約 4 秒です。
CALL polardbx.columnar_flush()関数を 1 分間に 960 回実行してスナップショットポイントを生成する場合の、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシを次の図に示します。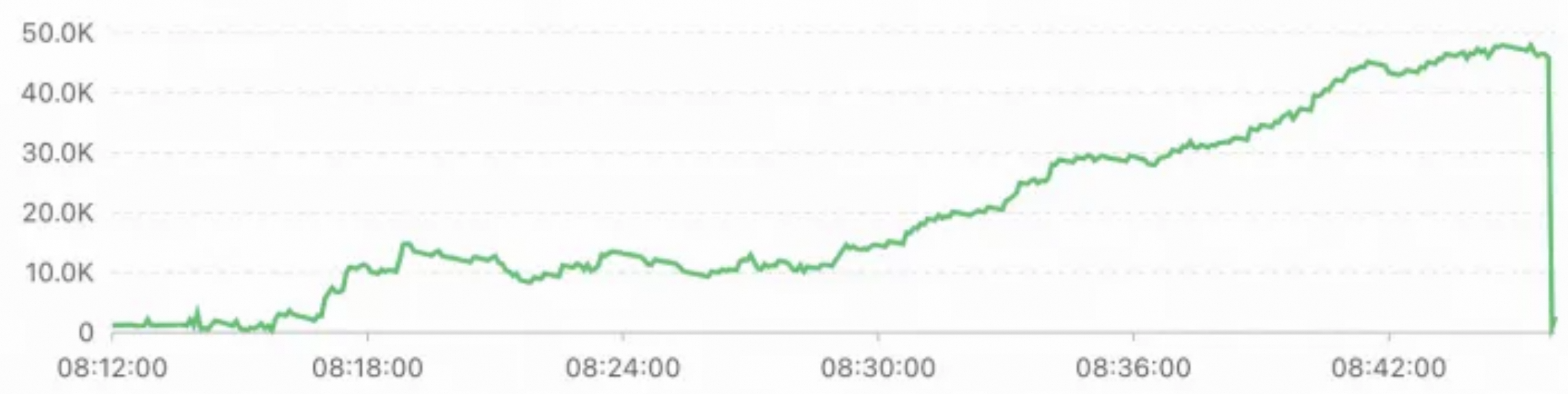 説明
説明この場合、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシが大幅に増加し、最大 50 秒になります。
結論
上記のテストでは、CALL polardbx.columnar_flush() 関数を 1 分間に 500 回未満の頻度で実行する場合、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシは大幅に増加しません。ただし、CALL polardbx.columnar_flush() 関数を 1 分間に約 1000 回の頻度で実行すると、読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシが大幅に増加します。実際のビジネス環境では、CALL polardbx.columnar_flush() 関数の実行頻度が読み取り専用カラムナインスタンスとプライマリインスタンス間のデータ同期のレイテンシにどのように影響するかは、実際のビジネストラフィックと列ストア スナップショットの数に密接に関係しています。したがって、CALL polardbx.columnar_flush() 関数の実行頻度を 1 秒間に 1 回以下に設定することをお勧めします。関数を 1 秒間に 1 回以上呼び出す必要がある場合は、十分なテストを実行する必要があります。