このトピックでは、PolarDB for PostgreSQL および の先行書き込みログ (WAL) 並列リプレイ機能について説明します。
適用範囲
この機能は、PolarDB for PostgreSQL の以下のバージョンで利用できます。
マイナーエンジンバージョンが 2.0.18.0.1.0 以降の PostgreSQL 18。
マイナーエンジンバージョンが 2.0.17.2.1.0 以降の PostgreSQL 17。
PostgreSQL 16 (マイナーエンジンバージョン 2.0.16.3.1.1 以降)
PostgreSQL 15 (マイナーエンジンバージョン 2.0.15.7.1.1 以降)
PostgreSQL 14 (マイナーエンジンバージョン 2.0.14.5.1.0 以降)
PostgreSQL 11 (マイナーエンジンバージョン 2.0.11.9.17.0 以降)
マイナーエンジンバージョンは、PolarDB コンソールで表示するか、SHOW polardb_version; 文を実行して確認できます。ご利用のクラスターのマイナーエンジンバージョンが要件を満たしていない場合は、マイナーエンジンバージョンをアップグレードする必要があります。
背景情報
PolarDB for PostgreSQL または クラスターは、1 つの書き込みノードと複数の読み取りノードを持つアーキテクチャを採用しています。実行中の読み取り専用ノード (レプリカノード) では、LogIndex バックグラウンドワーカープロセスとバックエンドプロセスが LogIndex データを使用して、個別のバッファーで WAL レコードをリプレイします。このメソッドにより、WAL レコードの並列リプレイが実現されます。
WAL リプレイは、PolarDB クラスターの高可用性 (HA) にとって重大です。標準のログリプレイパスに並列リプレイメソッドを適用することは、効果的な最適化です。
WAL の並列リプレイは、少なくとも 3 つのシナリオで利点があります。
プライマリデータベース、読み取り専用ノード、セカンダリデータベースのクラッシュリカバリープロセス。
読み取り専用ノード上の LogIndex BGW プロセスによる WAL レコードの継続的なリプレイ。
セカンダリデータベース上の Startup プロセスによる WAL レコードの継続的なリプレイ。
用語
Block:データブロック。
WAL:先行書き込みログ (Write-Ahead Logging)。
Task Node:並列実行フレームワークにおけるサブタスク実行ノード。1 つのサブタスクを受信して実行できます。
Task Tag:サブタスクの分類識別子。同じタグを持つサブタスクは、順番に実行する必要があります。
Hold List:並列実行フレームワークの各子プロセスがリプレイサブタスクをスケジュールして実行するために使用する連結リスト。
仕組み
概要
単一の WAL レコードは、複数のデータブロックを変更する可能性があります。WAL リプレイプロセスは、以下のように定義できます。
i番目の WAL レコードの LSN がLSN<sub>i</sub>であり、m個のデータブロックを変更すると仮定します。i番目の WAL レコードによって変更されるデータブロックのリストは、Block<sub>i</sub>=[Block<sub>i,0</sub>,Block<sub>i,1</sub>,...,Block<sub>i,m</sub>]として表されます。最小のリプレイサブタスクは
Task<sub>i,j</sub>=LSN<sub>i</sub>−>Block<sub>i,j</sub>と定義されます。このサブタスクは、データブロックBlock<sub>i,j</sub>上でi番目の WAL レコードをリプレイすることを表します。したがって、
m個のブロックを変更する WAL レコードは、m個のリプレイサブタスクのコレクションとして表すことができます:TASK<sub>i,∗</sub>=[Task<sub>i,0</sub>,Task<sub>i,1</sub>,...,Task<sub>i,m</sub>]。さらに、複数の WAL レコードは、一連のリプレイサブタスクコレクションとして表すことができます:
TASK<sub>∗,∗</sub>=[Task<sub>0,∗</sub>,Task<sub>1,∗</sub>,...,Task<sub>N,∗</sub>]。
リプレイサブタスクのコレクション
Task<sub>∗,∗</sub>において、あるサブタスクの実行は、必ずしも先行するサブタスクの結果に依存するわけではありません。リプレイサブタスクのコレクションが
TASK<sub>∗,∗</sub>=[Task<sub>0,∗</sub>,Task<sub>1,∗</sub>,Task<sub>2,∗</sub>]であると仮定します。ここで、Task<sub>0,∗</sub>=[Task<sub>0,0</sub>,Task<sub>0,1</sub>,Task<sub>0,2</sub>]Task<sub>1,∗</sub>=[Task<sub>1,0</sub>,Task<sub>1,1</sub>]Task<sub>2,∗</sub>=[Task<sub>2,0</sub>]
Block0,0=Block1,0、Block0,1=Block1,1、および Block0,2=Block2,0 であると仮定します。
この場合、並列でリプレイできるサブタスクのコレクションは [Task0,0,Task1,0]、[Task0,1,Task1,1]、および [Task0,2,Task2,0] の 3 つです。
まとめると、リプレイサブタスクのセット内には、最終結果の整合性に影響を与えることなく並列実行できる多くのサブタスクシーケンスが存在します。PolarDB は、この概念を並列タスク実行フレームワークで活用し、WAL リプレイプロセスに適用しています。
並列タスク実行フレームワーク
共有メモリのセグメントは、同時実行プロセス数に基づいて均等に分割されます。各セグメントはサーキュラーキューとして機能し、1 つのプロセスに割り当てられます。各サーキュラーキューの深さは、パラメーターを設定することで構成できます。
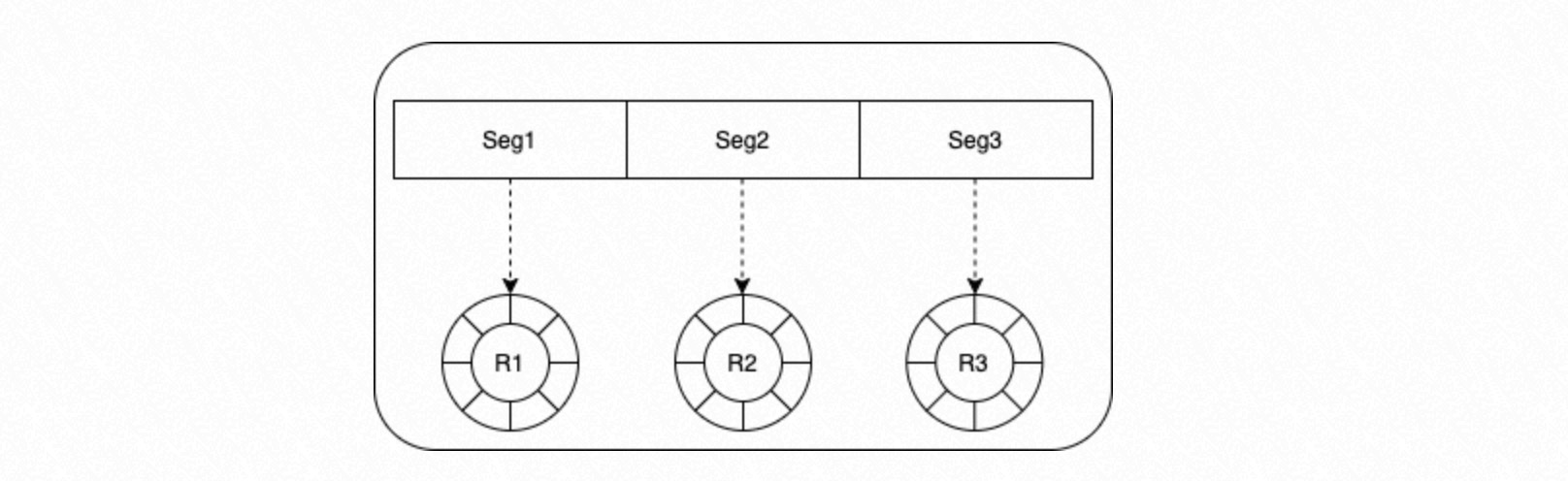
ディスパッチャープロセス。
タスクを指定されたプロセスにディスパッチすることで、同時実行スケジューリングを制御します。
完了したタスクをキューから削除します。
プロセスグループ。
グループ内の各プロセスは、対応するサーキュラーキューからタスクを取得し、タスクの状態に基づいて実行します。
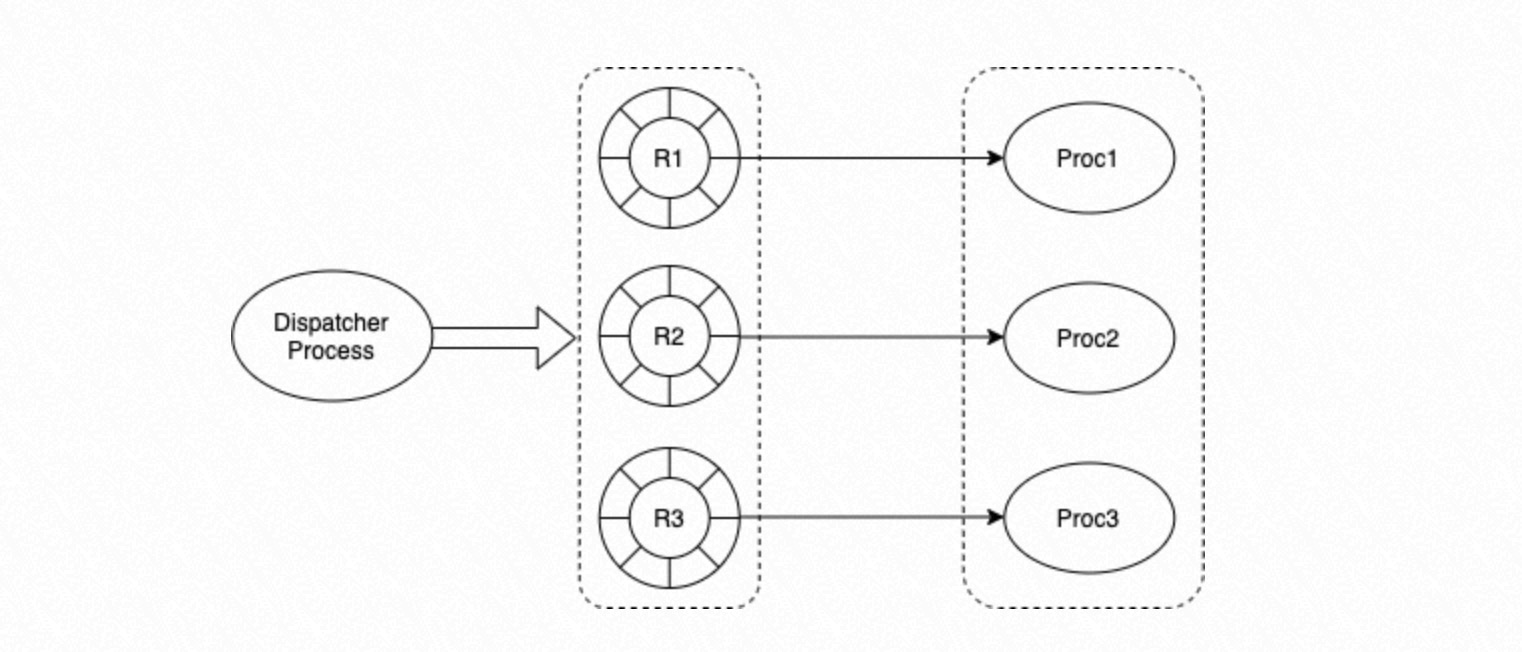
タスク
サーキュラーキューはタスクノードで構成されます。各タスクノードには、Idle、Running、Hold、Finished、Removed の 5 つの状態のいずれかがあります。
Idle:タスクノードにタスクが割り当てられていません。
Running:タスクノードにタスクが割り当てられており、実行待機中または実行中です。
Hold:タスクノード内のタスクは先行タスクに依存関係があり、そのタスクが完了するのを待つ必要があります。
Finished:プロセスグループ内のすべてのプロセスがタスクを完了しました。
Removed:ディスパッチャープロセスがタスクが Finished 状態であると判断した場合、そのすべての前提条件タスクも Finished である必要があります。その後、ディスパッチャープロセスはタスクの状態を Removed に変更します。この状態は、ディスパッチャープロセスが管理構造体からタスクとその前提条件を削除したことを示します。これにより、ディスパッチャープロセスが依存タスクの結果を正しい順序で処理することが保証されます。
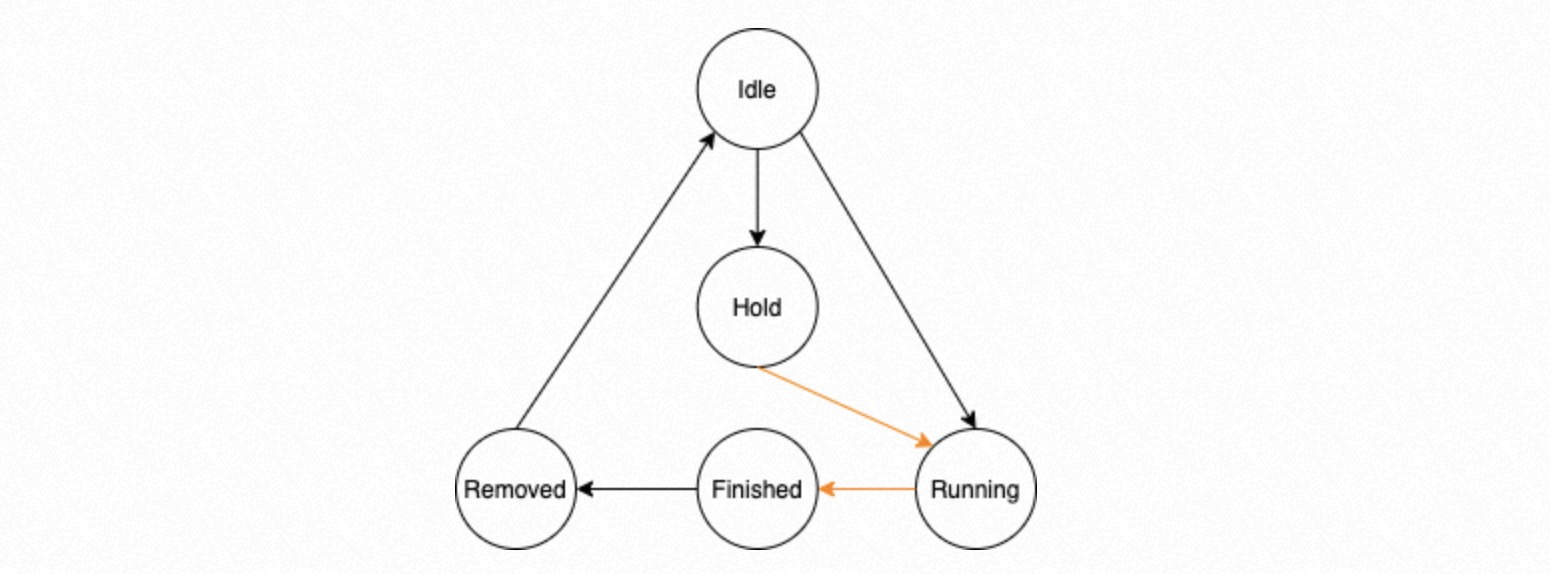 上記の状態機械の遷移において、黒い線でマークされた遷移はディスパッチャープロセスによって実行されます。オレンジ色の線でマークされた遷移は、並列リプレイプロセスグループによって実行されます。
上記の状態機械の遷移において、黒い線でマークされた遷移はディスパッチャープロセスによって実行されます。オレンジ色の線でマークされた遷移は、並列リプレイプロセスグループによって実行されます。ディスパッチャープロセス
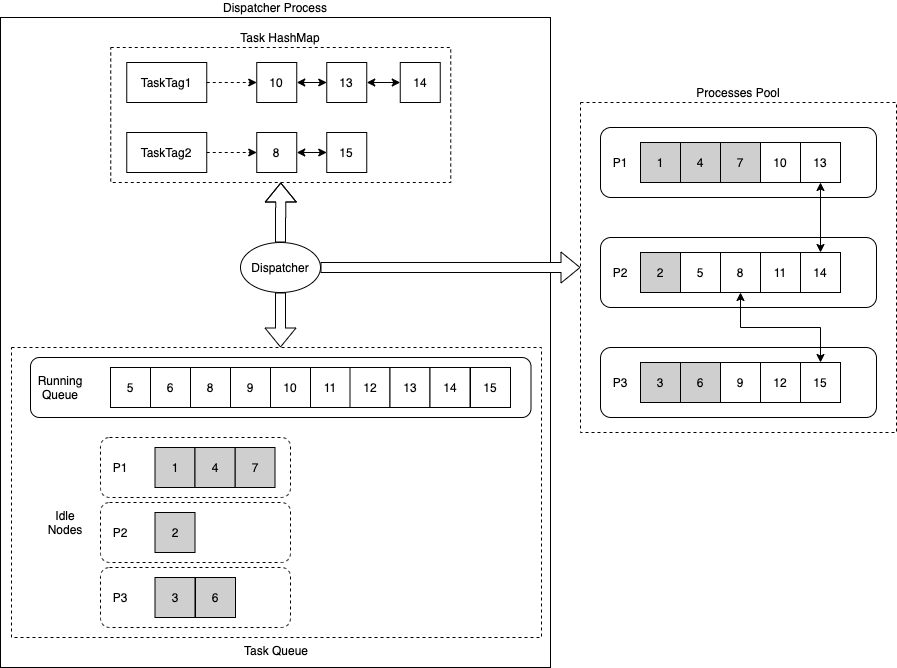
ディスパッチャープロセスは、タスクハッシュマップ、タスク実行キュー、タスクアイドルノードの 3 つの主要なデータ構造を使用します。
タスクハッシュマップ:タスクタグとそれに対応するタスク実行リストとの間のハッシュマッピングを記録します。
各タスクには特定のタスクタグがあります。2 つのタスクに依存関係がある場合、それらは同じタスクタグを共有します。
タスクがディスパッチされる際、タスクに前提条件がある場合、その状態は Hold とマークされます。タスクは、その前提条件が実行されるのを待つ必要があります。
タスク実行キュー:現在実行中のタスクを記録します。
タスクアイドルノード:プロセスグループ内の異なるプロセスに対して、現在
Idle状態にあるタスクノードを記録します。
ディスパッチャーは、以下のスケジューリングポリシーを使用します。
新しいタスクと同じタスクタグを持つタスクがすでに実行中の場合、新しいタスクは、そのタスクタグの連結リストの最後のタスクを処理しているプロセスに優先的に割り当てられます。このポリシーは、依存タスクを同じプロセスで実行することで、プロセス間同期のオーバーヘッドを削減します。
優先プロセスのキューが満杯であるか、同じタスクタグを持つタスクが実行中でない場合、プロセスグループから順次プロセスが選択されます。その後、そのプロセスのキューから
Idle状態のタスクノードが取得され、タスクがスケジュールされます。このポリシーは、タスクをすべてのプロセスにできるだけ均等に分散させます。
プロセスグループ
この並列実行は、同じタスクノードデータ構造を共有する同じタイプのタスクに適用されます。プロセスグループの初期化中に、
SchedContextが構成され、特定のタスクを実行する関数ポインターが指定されます。TaskStartup:プロセスがタスクを実行する前に初期化を実行します。
TaskHandler:受信したタスクノードに基づいて特定のタスクを実行します。
TaskCleanup:プロセスが終了する前にクリーンアップを実行します。

プロセスグループ内のプロセスは、サーキュラーキューからタスクノードを取得します。タスクノードの状態が
Holdの場合、プロセスはそれをホールドリストの末尾に挿入します。状態がRunningの場合、プロセスはTaskHandlerを呼び出してタスクを実行します。TaskHandlerが失敗した場合、システムはタスクノードにリトライ回数 (デフォルトは 3) を設定し、タスクノードをホールドリストの先頭に挿入します。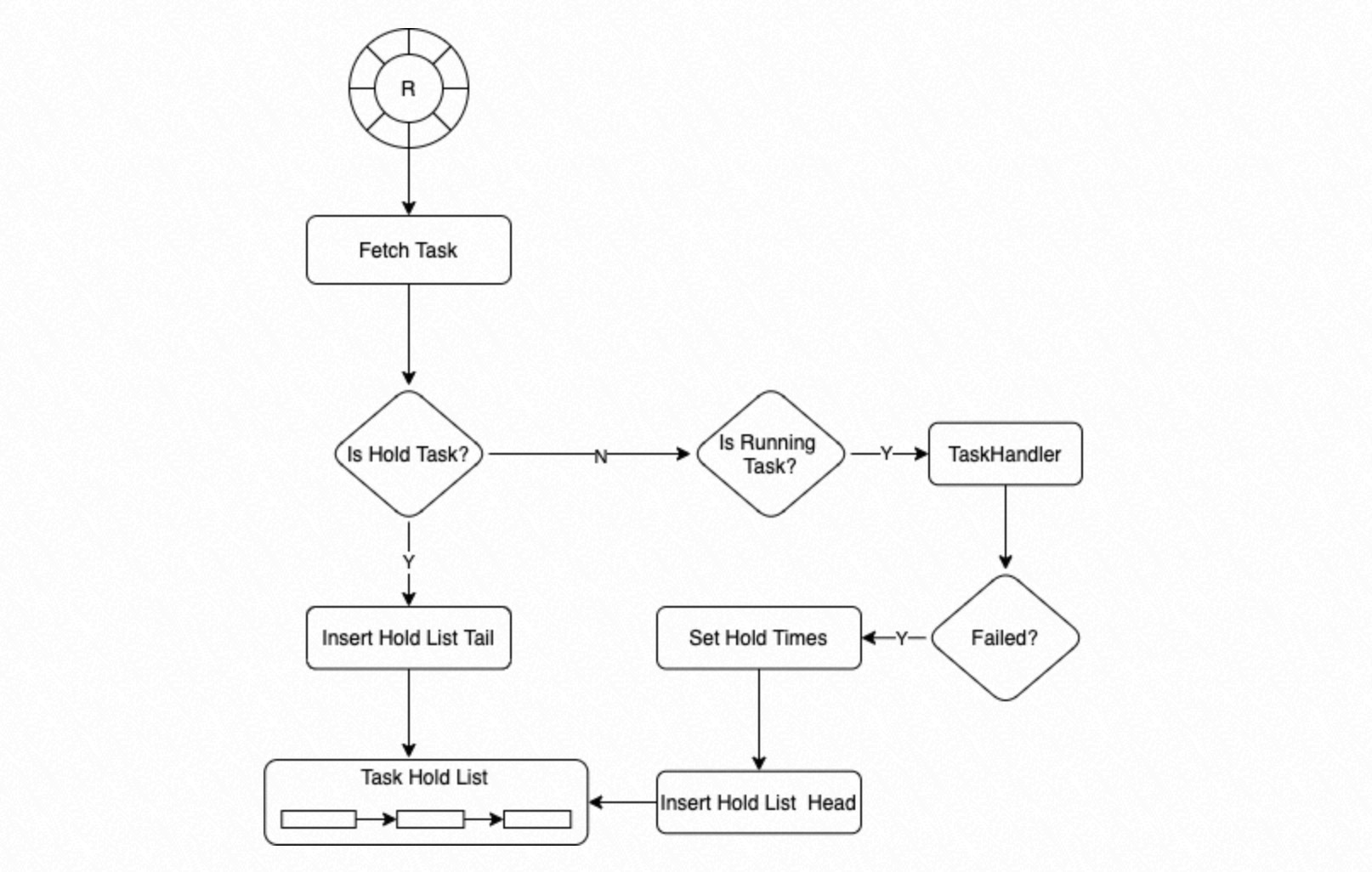
プロセスは、
ホールドリストを先頭から検索して、実行可能なタスクを探します。タスクの状態がRunningで待機カウントが 0 の場合、プロセスはタスクを実行します。タスクの状態がRunningで待機カウントが 0 より大きい場合、プロセスは待機カウントを 1 減らします。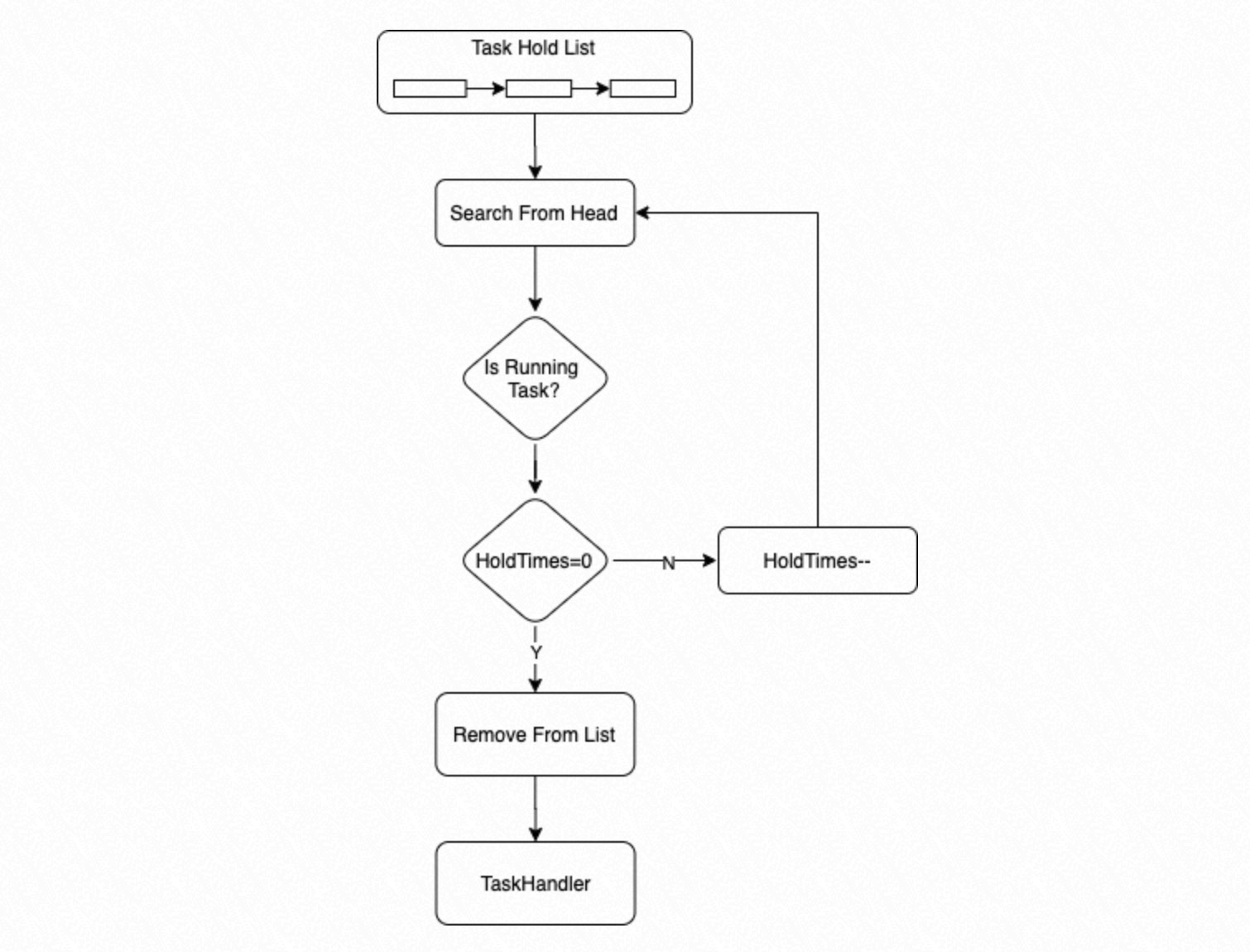
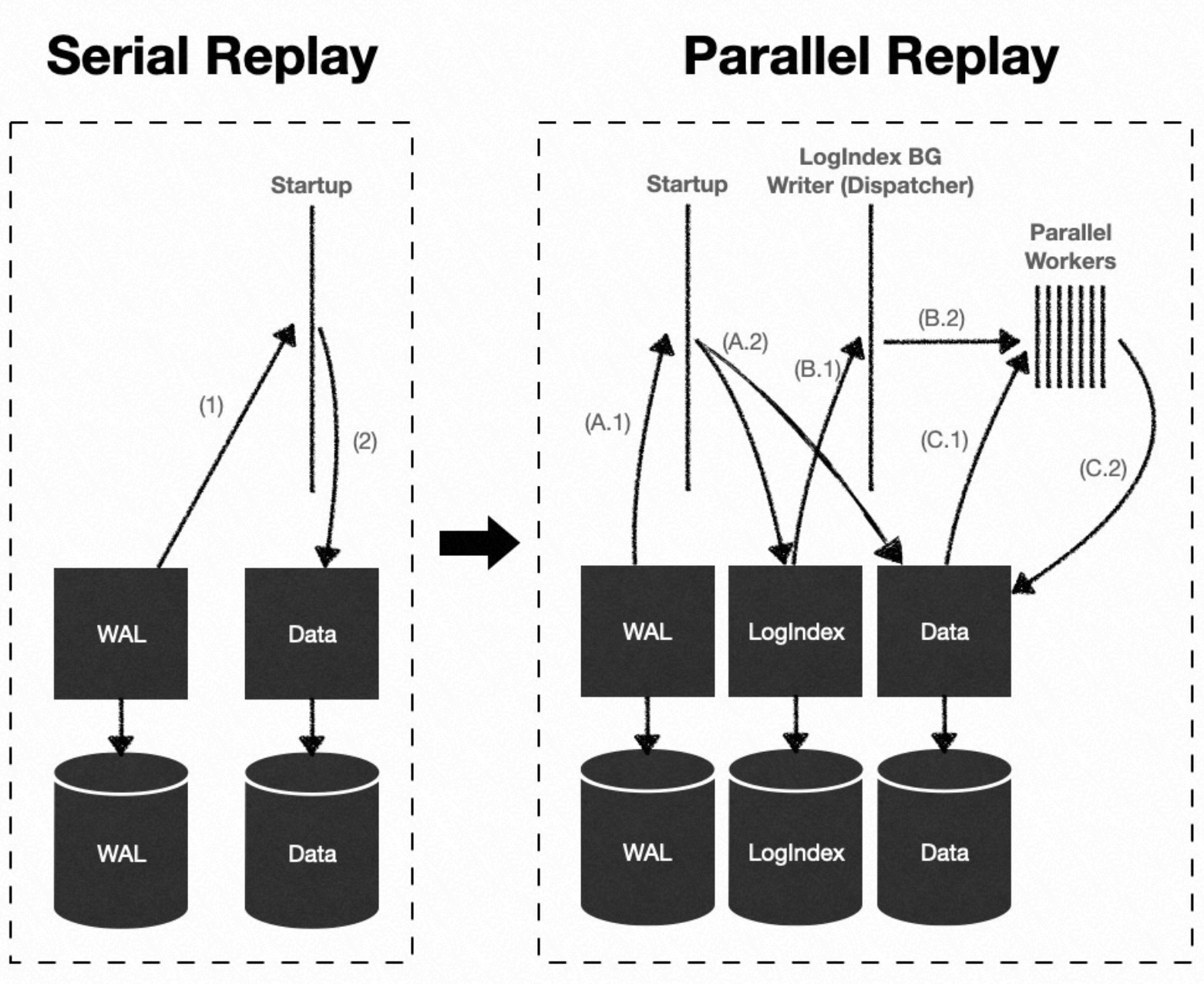
[WAL 並列リプレイ]
LogIndex データは、先行書き込みログ (WAL) レコードと、それらが変更するデータブロックとの間のマッピングを記録します。また、LSN による取得もサポートしています。スタンバイノードで WAL レコードを継続的にリプレイする際、PolarDB は並列実行フレームワークを使用します。このフレームワークは、LogIndex データを使用して WAL リプレイタスクを並列化し、スタンバイノードでのデータ同期を高速化します。
ワークフロー
Startup プロセス:WAL レコードを解析し、WAL レコードをリプレイせずに LogIndex データを構築します。
LogIndex BGW リプレイプロセス:並列実行フレームワークのディスパッチャープロセスとして機能します。このプロセスは LSN を使用して LogIndex データを取得し、リプレイサブタスクを構築し、それらを並列リプレイプロセスグループに割り当てます。
並列リプレイプロセスグループ内のプロセス:リプレイサブタスクを実行し、データブロック上で単一の WAL レコードをリプレイします。
バックエンドプロセス:データブロックを読み取る際、プロセスは PageTag を使用して LogIndex データを取得します。ブロックを変更した WAL レコードの LSN の連結リストを取得し、データブロック上で WAL レコードチェーン全体をリプレイします。
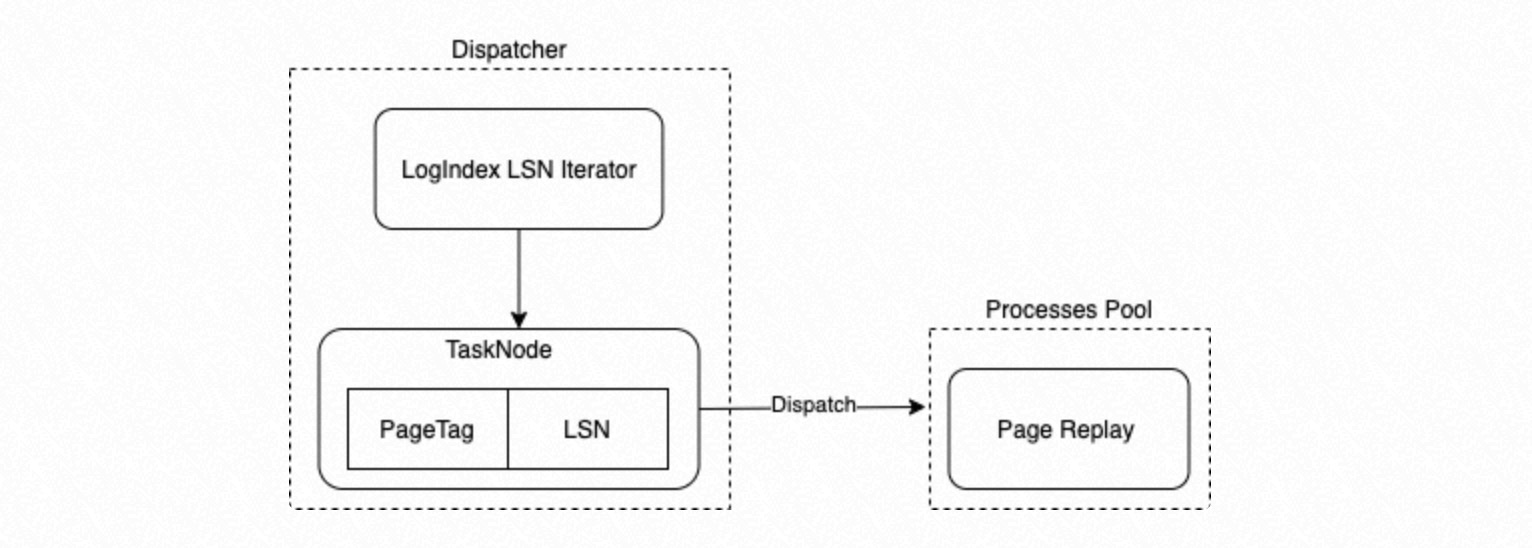
ディスパッチャープロセスは LSN を使用して LogIndex データを取得します。LogIndex の挿入順に PageTag とそれに対応する LSN を列挙して、タスクノードとして機能する
{LSN -> PageTag}マッピングを構築します。PageTag は、タスクノードのタスクタグとして機能します。
ディスパッチャープロセスは、列挙されたタスクノードを並列実行フレームワークのプロセスグループの子プロセスにディスパッチしてリプレイさせます。
使用ガイド
WAL 並列リプレイ機能を有効にするには、スタンバイノードの postgresql.conf ファイルに次のパラメーターを追加します。
polar_enable_parallel_replay_standby_mode = ON