PASE(PostgreSQL ANN search extension)は、PolarDB for PostgreSQL 向けの高性能ベクトル類似検索プラグインです。IVFFlat および階層型ナビゲーブル・スモールワールド(HNSW)という 2 種類の近似最近傍(ANN)アルゴリズムを実装しており、データベースから直接高速に高次元ベクトルの類似検索を実行できます。
PASE は特徴ベクトルの抽出や出力を行いません。まず対象エンティティの特徴ベクトルを取得し、その後 PASE を用いて大規模なベクトルデータセットに対する類似検索を実行してください。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
PolarDB for PostgreSQL クラスター
特権アカウント(本トピックで示す SQL ステートメントを実行するために必要)
機械学習の基本概念およびベクトル検索に関する基礎知識
注意事項
インデックスの肥大化:
select pg_relation_size('index_name');を実行し、その結果をテーブルサイズと比較します。インデックスサイズがテーブルサイズより大きく、クエリの応答速度が低下している場合は、インデックスを再構築してください。更新後のインデックスドリフト: データの頻繁な更新により、インデックス精度が低下する場合があります。100 % の再現率(recall)を要求する場合は、定期的にインデックスを再構築してください。
IVFFlat の内部クラスタリング: 内部重心を用いた IVFFlat インデックスを作成するには、
clustering_type = 1を設定したうえで、インデックス作成前にテーブルへデータを挿入してください。マルチノード弾性並列クエリ: マルチノード弾性並列クエリでは、高次元ベクトルに対しては逐次検索のみがサポートされています。
アルゴリズムの選択
PASE は 2 種類の ANN アルゴリズムをサポートしています。適切なアルゴリズムの選択は、データセットのサイズ、レイテンシ目標、および再現率要件によって異なります。
| IVFFlat | HNSW | |
|---|---|---|
| 推奨ユースケース | 高精度が求められる用途(例:画像比較) | 大規模データセットかつ低レイテンシが求められる用途 |
| クエリレイテンシ目標 | 最大 100 ms | 最大 10 ms |
| データセットサイズ | 任意のサイズ | 数千万ベクトル以上 |
| 100 % 再現率 | はい(クエリベクトルが候補データセット内にある場合) | いいえ。精度が頭打ちになり、チューニングによってそれ以上向上させることはできません。 |
| 構築時間 | 高速 | 遅め |
| ストレージオーバーヘッド | 低 | 大きい(近接グラフの隣接ノードを格納) |
| 精度制御 | パラメーターによる完全制御が可能 | しきい値を超えると制御範囲が限定される |
IVFFlat
IVFFlat は IVFADC アルゴリズムの簡略化版です。k 平均法(k-means)を用いてベクトルをクラスタリングし、クエリベクトルに最も近いクラスターのみを検索することで、遠方のクラスターをスキップして検索を高速化します。精度は検索対象となるクラスター数に比例するため、直接チューニング可能です。
IVFFlat の動作原理:
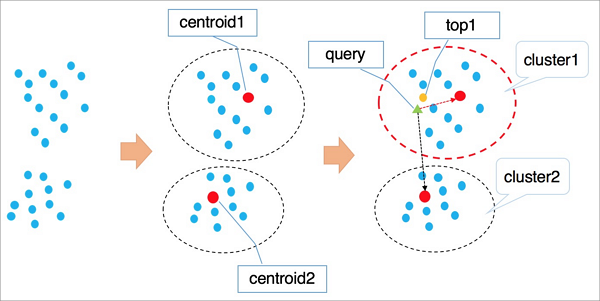
IVFFlat は k 平均法を適用してベクトルをクラスターにグループ化し、各クラスターに重心(centroid)を割り当てます。
クエリベクトルに最も近い
n個の重心を特定します。これらの
n個のクラスター内のすべてのベクトルを走査・順位付けし、最も近いk個のベクトルを返します。
n の値を大きくすると精度は向上しますが、計算負荷も増加します。IVFADC とは異なり、IVFFlat はフェーズ 2 で積量子化(product quantization)を用いず、力まかせ探索(brute-force search)を採用するため、精度とパフォーマンスのトレードオフを直接制御できます。
HNSW
HNSW は、ナビゲーブル・スモールワールド(NSW)アルゴリズムを用いて階層的なマルチレイヤーグラフを構築します。各レイヤーは下位レイヤー全体を俯瞰する「パノラマ」および「スキップリスト」として機能し、大規模データセットにおける高速な走査を可能にします。
HNSW の動作原理:
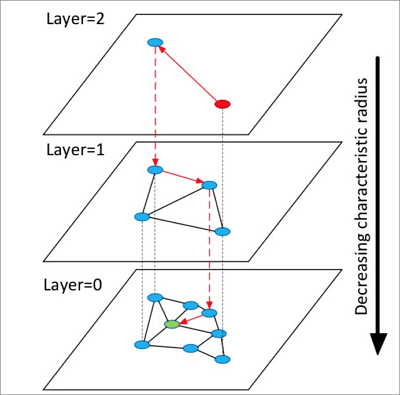
HNSW は複数のレイヤー(グラフ)からなる構造を構築します。各レイヤーはその直下のレイヤーのパノラマおよびスキップリストです。
最上位レイヤーのランダムな要素から開始し、HNSW は隣接ノードを特定し、距離に基づいてソートされた固定長の動的リストに追加します。
隣接ノードの拡張を継続し、各追加後にリストを再ソートし、上位
k個のみを保持します。リストが安定したら、上位要素を起点として次のレイヤーへ降下します。最下位レイヤーでの検索が完了するまでこの処理を繰り返します。
精度がある一定レベルに達すると、パラメーターの再構成によってさらに向上させることはできません。また、HNSW は近接グラフの隣接ノードを永続化するために追加のストレージを必要とします。
PASE の有効化
以下のステートメントを実行して、PASE 拡張機能をインストールします。
CREATE EXTENSION pase;ベクトル類似度の算出
インデックスを作成する前に、<?> オペレーターを用いてベクトル類似度を直接算出できます。PASE では 2 種類の構築方法がサポートされています。
左側のベクトルはfloat4[]型、右側のベクトルはPASE型である必要があります。両ベクトルのディメンション数が一致しない場合、類似度算出エラーが発生します。
PASE 型構築
<?> オペレーターはベクトル間の類似度を算出します。PASE データ型は最大 3 つのパラメーターを受け入れます。
パラメーター 1: 右側ベクトル(
float4[])パラメーター 2: 予約済み;
0を指定してくださいパラメーター 3: 類似度算出方式 —
0:ユークリッド距離、1:ドット積(内積)
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[]) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;文字列ベース構築
文字列ベース構築では、関数引数ではなくコロン(:)を用いてパラメーターを区切ります。
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1'::pase AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0'::pase AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0:1'::pase AS distance;'3,1,1:0:1' では、最初のセグメントがベクトル、2 番目が予約済みパラメーター(0)、3 番目が類似度算出方式(0 = ユークリッド距離、1 = ドット積)です。
正規化の要件
ユークリッド距離: 正規化は不要です。
ドット積またはコサイン類似度: 元のベクトルを事前に正規化してください。正規化済みベクトルでは、ドット積の値はコサイン値と等しくなります。たとえば、元のベクトルが
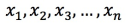 の場合、
の場合、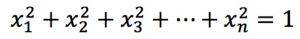 を満たす必要があります。
を満たす必要があります。
インデックスの作成
IVFFlat インデックス
CREATE INDEX ivfflat_idx ON vectors_table
USING
pase_ivfflat(vector)
WITH
(clustering_type = 1, distance_type = 0, dimension = 256, base64_encoded = 0, clustering_params = "10,100");パラメーター
| パラメーター | 必須 | デフォルト値 | 説明 |
|---|---|---|---|
clustering_type | はい | — | クラスタリングモード。0:外部クラスタリング(clustering_params で指定された重心ファイルを読み込み)1:内部 k 平均法クラスタリング。初回利用時は、内部クラスタリング(1)から始めることを推奨します。 |
distance_type | いいえ | 0 | 類似度算出方式。0:ユークリッド距離。1:ドット積(正規化が必要;ドット積の順序はユークリッド距離と逆になります)。PolarDB はネイティブでユークリッド距離をサポートしています。ドット積を利用する場合は、ベクトルを事前に正規化してください。 |
dimension | はい | — | ディメンション数。最大値:512。 |
base64_encoded | いいえ | 0 | ベクトルエンコーディング。0:float4[]。1:Base64 エンコード済み float[]。 |
clustering_params | はい | — | 外部クラスタリングの場合:重心ファイルのディレクトリ。内部クラスタリングの場合:clustering_sample_ratio,k。以下を参照してください。 |
内部クラスタリング(clustering_type = 1)向け clustering_params
形式:clustering_sample_ratio,k
clustering_sample_ratio:分母が 1,000 のサンプリング比率。範囲:(0, 1000]。たとえば1は 1/1000 のサンプリング比率を意味します。値が大きいほど精度は向上しますが、インデックス作成時間が長くなります。サンプリング対象レコード総数は 100,000 未満に保ってください。k:重心の数。値が大きいほど精度は向上しますが、インデックス作成時間が長くなります。推奨範囲:[100, 1000]。
HNSW インデックス
CREATE INDEX hnsw_idx ON vectors_table
USING
pase_hnsw(vector)
WITH
(dim = 256, base_nb_num = 16, ef_build = 40, ef_search = 200, base64_encoded = 0);パラメーター
| パラメーター | 必須 | デフォルト値 | 説明 |
|---|---|---|---|
dim | はい | — | ディメンション数。最大値:512。 |
base_nb_num | はい | — | 要素ごとの隣接ノード数。値が大きいほど精度は向上しますが、インデックス作成時間が長くなり、ストレージ使用量も増加します。推奨範囲:[16, 128]。 |
ef_build | はい | — | インデックス作成時のヒープ長。ヒープ長が長いほど精度は向上しますが、作成時間が長くなります。推奨範囲:[40, 400]。 |
ef_search | はい | 200 | クエリ実行時のヒープ長。値が大きいほど精度は向上しますが、クエリパフォーマンスは低下します。クエリ実行時に上書き可能です。初期値は 40 とし、所望の精度に達するまで段階的に増加させてください。 |
base64_encoded | いいえ | 0 | ベクトルエンコーディング。0:float4[]。1:Base64 エンコード済み float[]。 |
クエリーベクター
IVFFlat インデックスを用いたクエリ
IVFFlat インデックスのクエリには <#> オペレーターを使用します。ORDER BY 句が必須であり、インデックスが有効になるための条件です。結果は距離の昇順でソートされます。
SELECT id, vector <#> '1,1,1'::pase AS distance
FROM vectors_ivfflat
ORDER BY
vector <#> '1,1,1:10:0'::pase
ASC LIMIT 10;クエリ文字列 '1,1,1:10:0' はコロンで区切られた 3 つのパラメーターで構成されます。
| 位置 | 値 | 説明 |
|---|---|---|
| 1 | 1,1,1 | クエリベクトル |
| 2 | 10 | クエリ精度 — 範囲:(0, 1000]。値が大きいほど精度は向上しますが、クエリパフォーマンスは低下します。 |
| 3 | 0 | 類似度算出方式:0:ユークリッド距離、1:ドット積(正規化が必要;ドット積の順序はユークリッド距離と逆になります)。 |
HNSW インデックスを用いたクエリ
HNSW インデックスのクエリには <?> オペレーターを使用します。ORDER BY 句が必須であり、インデックスが有効になるための条件です。結果は距離の昇順でソートされます。
SELECT id, vector <?> '1,1,1'::pase AS distance
FROM vectors_ivfflat
ORDER BY
vector <?> '1,1,1:100:0'::pase
ASC LIMIT 10;クエリ文字列 '1,1,1:100:0' はコロンで区切られた 3 つのパラメーターで構成されます。
| 位置 | 値 | 説明 |
|---|---|---|
| 1 | 1,1,1 | クエリベクトル |
| 2 | 100 | クエリ精度 — 範囲:(0, ∞)。値が大きいほど精度は向上しますが、クエリパフォーマンスは低下します。初期値は 40 とし、段階的に増加させてください。 |
| 3 | 0 | 類似度算出方式:0:ユークリッド距離、1:ドット積(正規化が必要;ドット積の順序はユークリッド距離と逆になります)。 |
付録
ドット積(内積)の算出
正規化済みベクトルのドット積はコサイン値と等しいため、以下の関数はドット積およびコサイン類似度の両方の検索に使用できます。HNSW インデックスを用います。
CREATE OR REPLACE FUNCTION inner_product_search(query_vector text, ef integer, k integer, table_name text) RETURNS TABLE (id integer, uid text, distance float4) AS $$
BEGIN
RETURN QUERY EXECUTE format('
select a.id, a.vector <?> pase(ARRAY[%s], %s, 1) AS distance from
(SELECT id, vector FROM %s ORDER BY vector <?> pase(ARRAY[%s], %s, 0) ASC LIMIT %s) a
ORDER BY distance DESC;', query_vector, ef, table_name, query_vector, ef, k);
END
$$
LANGUAGE plpgsql;外部重心ファイルからの IVFFlat インデックス作成
これは高度な機能です。外部重心ファイルを指定されたサーバーのディレクトリにアップロードし、clustering_params で参照してください。ファイル形式は以下のとおりです。
ディメンション数|重心数|重心ベクトルデータセット例:
3|2|1,1,1,2,2,2参考資料
Hervé Jégou, Matthijs Douze, Cordelia Schmid. Product quantization for nearest neighbor search. IEEE.
Yu.A.Malkov, D.A.Yashunin. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. IEEE.