ハッシュインデックスは、等価クエリにのみ使用されます。 ハッシュインデックスにはハッシュ値のみが格納され、インデックスキー値は格納されません。 したがって、ハッシュインデックスは、フィールドの長さが長く、フィールドの多くの有効な値が利用可能な等価クエリシナリオに適しています。
インデックス構造
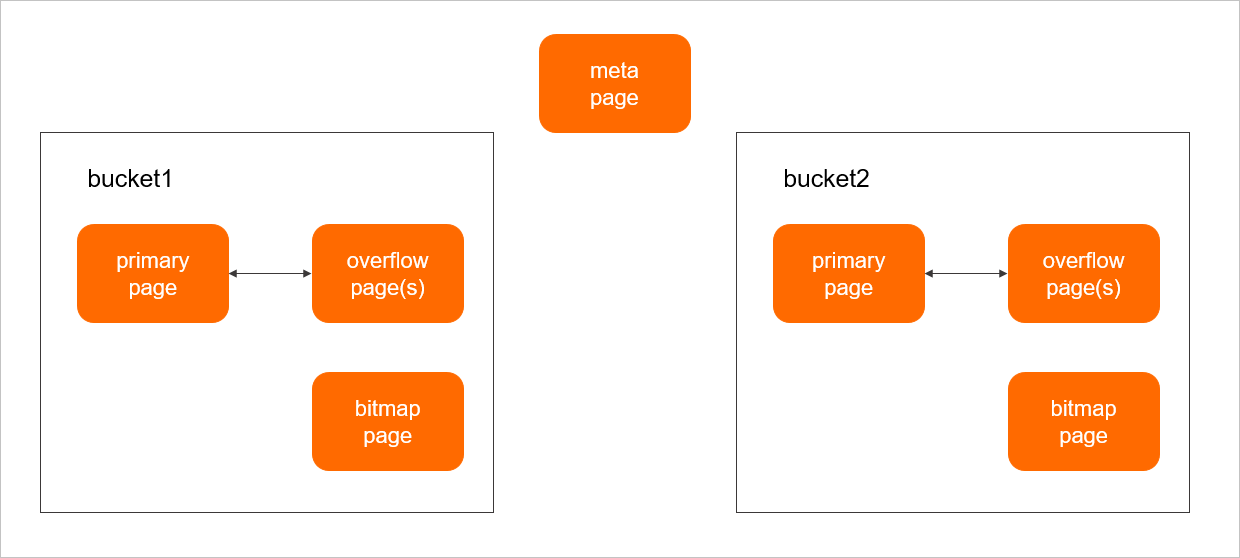
- ハッシュ値は変換され、バケットにマップされます。
- バケットの数は2のN乗である。
- メタページには、インデックスに関する関連する内部情報が含まれます。
- 各バケットには、少なくとも1つの主ページが必要です。
- ページはハッシュ値を格納します。
- データがバケットに書き込まれる前に、データは最初に主ページに書き込まれる。 正ページのスペースが不十分である場合、データはオーバーフローページに書き込まれる。
- ビットマップページは、クリーンオーバーフローページを追跡するために使用されます。
演算子
ハッシュインデックスは、等号演算子 (=) のみをサポートします。 これは、ハッシュインデックスが平等クエリにのみ適していることを示しています。
- データの照会
select * from test where id=1; - ハッシュインデックスを作成します。
ハッシュ (id) を使用してインデックスONテストを作成します。 - 実行計画を表示します。
postgres=# explain select * from test where id=1; クエリ計画 ------------------------------------------------------------------------- テスト時にtest_id_idxを使用したインデックススキャン (コスト=0.00 .. 8.02行=1幅=10) Index Cond :( id = 1) (2行)
例
- テーブルを作成します。
テーブルa(id int,name text) を作成します。 - データを挿入します。
insert into test select id,md5(id::text)| | md5(id::text)| | md5(id::text)| | md5(id::text) from generate_series(1,3000000) t(id); - ハッシュインデックスを作成します。
hash (name) を使用してインデックスidx_test_hash ON testを作成します。 - B-treeインデックスを作成します。
test(name) にインデックスidx_test_btreeを作成します。 - データの照会
select * from test where name='c4ca4238a0b923820dcc509a6f75849bc4ca4238a0b923820dcc509a6f75849bc4ca4238a0b923820dcc509a6f75849bc4ca4238a0b923820dcc509a6f75849b';
| インデックスタイプ | インデックスサイズ | クエリ期間 |
| ハッシュインデックス | 224 MB | 0.029 ms |
| B-treeインデックス | 491 MB | 0.103 ms |