メモリ内列インデックス (IMCI) が複雑なクエリを処理する機能を向上させるために、IMCIオプティマイザは、変換ルールをテーブル内の各列の統計と組み合わせて、コストに基づいて効率的な実行計画を生成します。 このトピックでは、IMCIクエリ最適化機能について説明します。
制御ポリシー機能の動作
SQLは宣言型クエリ言語であり、SQLステートメントのクエリプランを具体的に記述するものではありません。 SQL文の正しい結果を得るために、いくつかのクエリプランを使用することができる。 例:
SELECT * FROM t0, t1, t2, t3 WHERE t0.a = t1.a AND t1.a = t2.a AND t2.a = t3.a AND t3.b = t1.b;上記のSQL文では、次の2つのクエリプランを使用して、正しいクエリ結果を取得できます。 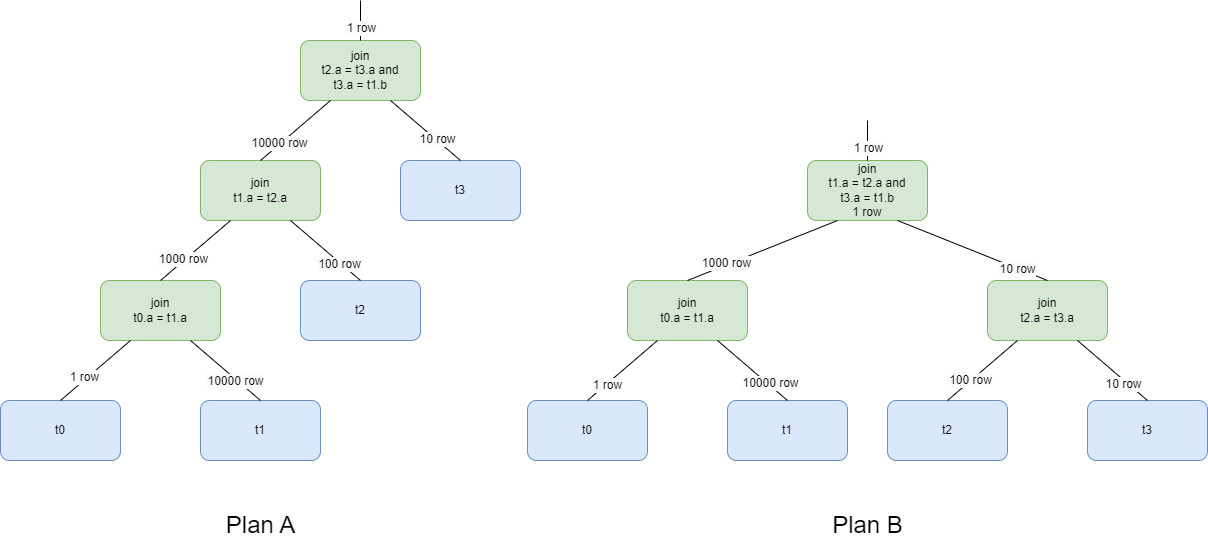 プランAとプランBは同等のクエリプランです。 検索フレームワークとして、クエリオプティマイザは、あるクエリプランを別の等価クエリプランに変換することによって、現在のSQLステートメントに対応する等価クエリプランを検索する。 たとえば、
プランAとプランBは同等のクエリプランです。 検索フレームワークとして、クエリオプティマイザは、あるクエリプランを別の等価クエリプランに変換することによって、現在のSQLステートメントに対応する等価クエリプランを検索する。 たとえば、t1 INNER JOIN t2とt2 INNER JOIN t1は同等のクエリプランです。 クエリオプティマイザは、同等のクエリプランを変換することで、t1 INNER JOIN t2をt2 INNER JOIN t1に変換できます。 オプティマイザによるこの変換は、クエリ変換ルールと呼ばれる。
クエリオプティマイザは次のように機能します。
SQL文を解析して取得した初期クエリプランを開始します。
クエリ変換ルールを使用して、初期状態のクエリプランから同等のクエリプランを生成します。
統計とコストモデルを組み合わせて、同等のクエリプランから実行コストが最も低いクエリプランを選択し、最終的な実行プランとして実行レイヤーに送信します。
クエリ最適化機能は、最良のクエリプランを決定するためのカーディナリティ推定およびコスト計算を実行するために統計に依存する。 IMCIでは、テーブルの統計には次の項目が含まれます。
ヒストグラム。異なる列の値の分布を示し、主に単一のテーブル上の値の範囲と同等の述語の選択率を推定するために使用されます。
主に
Group Byのグループ数を推定するために使用され、同等の述語の選択率を推定するのにも使用できます。他の制約 (列に一意のインデックスがあるかどうか、または列に他の列との外部キー制約があるかどうかなど) 。
クエリオプティマイザは、次の項目に基づいて、クエリプランの各ノード演算子のコストを計算します。
クエリプランで演算子によって処理された行の総数。 統計を使用して、行の総数を推定できます。
クエリプランの各演算子で使用されるアルゴリズムの複雑さ。
クエリプラン内の演算子によって処理される行の総数は、アルゴリズム複雑度関数のパラメータである。 クエリプラン全体の実行コストは、すべてのノードの演算子コストの合計です。 上の図の2つのクエリプランで、結合実行アルゴリズムとしてハッシュ結合を使用する場合、コスト式は次のようになります。
コスト参加 =カードインナー + カードアウター
2つの実行計画のコストは次のとおりです。
コストA ==10000 + 1 + 1000 + 100 + 10000 + 10=21111
コストB =10000 + 1 + 100 + 10 + 1000 + 10=11121
プランBの実行コストは低くなります。 したがって、クエリオプティマイザは、プランBを最終実行プランとして選択します。
前提条件
PolarDBクラスターでは、次のいずれかのバージョンを使用します。
リビジョンバージョンが8.0.1.1.31以降のPolarDB for MySQL 8.0.1のクラスター。
リビジョンバージョンが8.0.2.2.12以降のPolarDB for MySQL 8.0.2のクラスター。
制限事項
次の条件は、カーディナリティ推定に大きなエラーをもたらす可能性があり、したがって、オプティマイザに次善のクエリ計画を選択させる。 ヒントを使用して、最適なクエリプランを生成するようにオプティマイザに指示できます。
述語を含むクエリの場合、比較演算子はテーブルのさまざまな列をクエリするために使用されます。 例:
t1.c1>t1.c2述語を含むクエリの場合、クエリステートメントで使用される演算子は、推定に統計を使用できません。 例:
t1.c1 MOD 2=1およびt1.c2 LIKE '% ABC %述語を含むクエリの場合、クエリ文には式があり、最適化機能は計算に使用できません。 例:
t1.c1 + t1.c3>100クエリ文の演算子に含まれる列には、述語の選択率を推定するための統計がありません。 例:
SELECT a, SUM(b) FROM t1 HAVING SUM(b) > 10複数の述語は、
AND演算子を使用して結合されます。 例:t1.c1>10 AND t1.c3<5クエリ文には、多くのネストされたレイヤーが含まれます。
クエリステートメントは、多くのテーブルを結合します。
loose_imci_max_enum_join_pairsパラメーターの値を変更して、IMCIオプティマイザが使用できる結合の数を指定できます。
パラメーター
IMCIクエリ最適化機能を有効にして使用するには、PolarDBコンソールで次の表に示すパラメーターを設定します。 PolarDBコンソールでパラメーターを設定する方法の詳細については、「クラスターパラメーターとノードパラメーターの設定」をご参照ください。
パラメーター | 説明 |
loose_imci_optimizer_switch | IMCIクエリ最適化機能を有効にするかどうかを指定します。 有効な値:
|
loose_imci_auto_update_statistic | 統計が最新でない場合に、IMCIクエリオプティマイザーが統計を再収集するかどうかを指定します。 有効な値:
|
loose_imci_max_enum_join_pairs | IMCIおよびjoin reorder機能が有効になっている場合に、IMCIクエリオプティマイザーが取得できる同等の実行プランの数。 有効な値: 0 ~ 4294967295 デフォルト値: 2000。 |
Usage
IMCIクエリ最適化機能を使用するには、まず選択した情報収集ポリシーに基づいて統計を収集する必要があります。 情報が収集されたら、IMCIクエリ最適化機能を有効にして、クエリ文を実行します。
統計を収集します。
次の情報収集ポリシーに基づいて統計を収集できます。
IMCIクエリ最適化機能を使用して最新の統計を作成するテーブルを含むデータベースで、
ANALYZE TABLEステートメントを定期的に実行します。(推奨) IMCIが新しく作成されたテーブルでは、読み取り専用ノードで
ANALYZE tableステートメントを実行して、初期統計を作成します。 次に、loose_imci_auto_update_statisticパラメーターをASYNCに設定して、統計を自動的に更新します。
IMCIクエリ最適化機能を有効にします。
PolarDBコンソールで
loose_imci_optimizer_switchパラメーターをONに設定して、IMCIクエリ最適化機能を有効にすることができます。クエリ文を実行します。
クエリ結果の比較
次の例では、TPCH-Q8を使用します。 クエリステートメントには複数のテーブルが含まれ、集計関数が含まれます。
SELECT
o_year,
SUM (
CASE
国=「ブラジル」のボリューム
ELSE 0
END
) / SUM (ボリューム) AS mkt_share
から
(
SELECT
エキス (
year
FROM
o_orderdate
) o_yearとして、
l_extendedprice * (1 - l_discount) ASボリューム、
n2.n_名AS国家
FROM
lineitem,
注文、
部分,
サプライヤー,
顧客、
国家n1,
国家n2,
region
WHERE
p_partkey = l_partkey
AND s_suppkey = l_suppkey
AND l_orderkey = o_orderkey
AND o_custkey = c_custkey
AND c_nationkey = n1.n_nationkey
AND n1.n_regionkey = r_regionkey
AND r_name = 'AMERICA'
AND s_nationkey = n2.n_nationkey
および日付 '1995-01-01 'の間のo_orderdate
そして日付「1996-12-31」
AND p_type = 'ECONOMY ANODIZED STEEL'
) AS all_nations
によるグループ
o_year
注文によって
o_year; 次の図は、IMCIクエリ最適化機能が無効になっている場合のクエリプランを示しています。
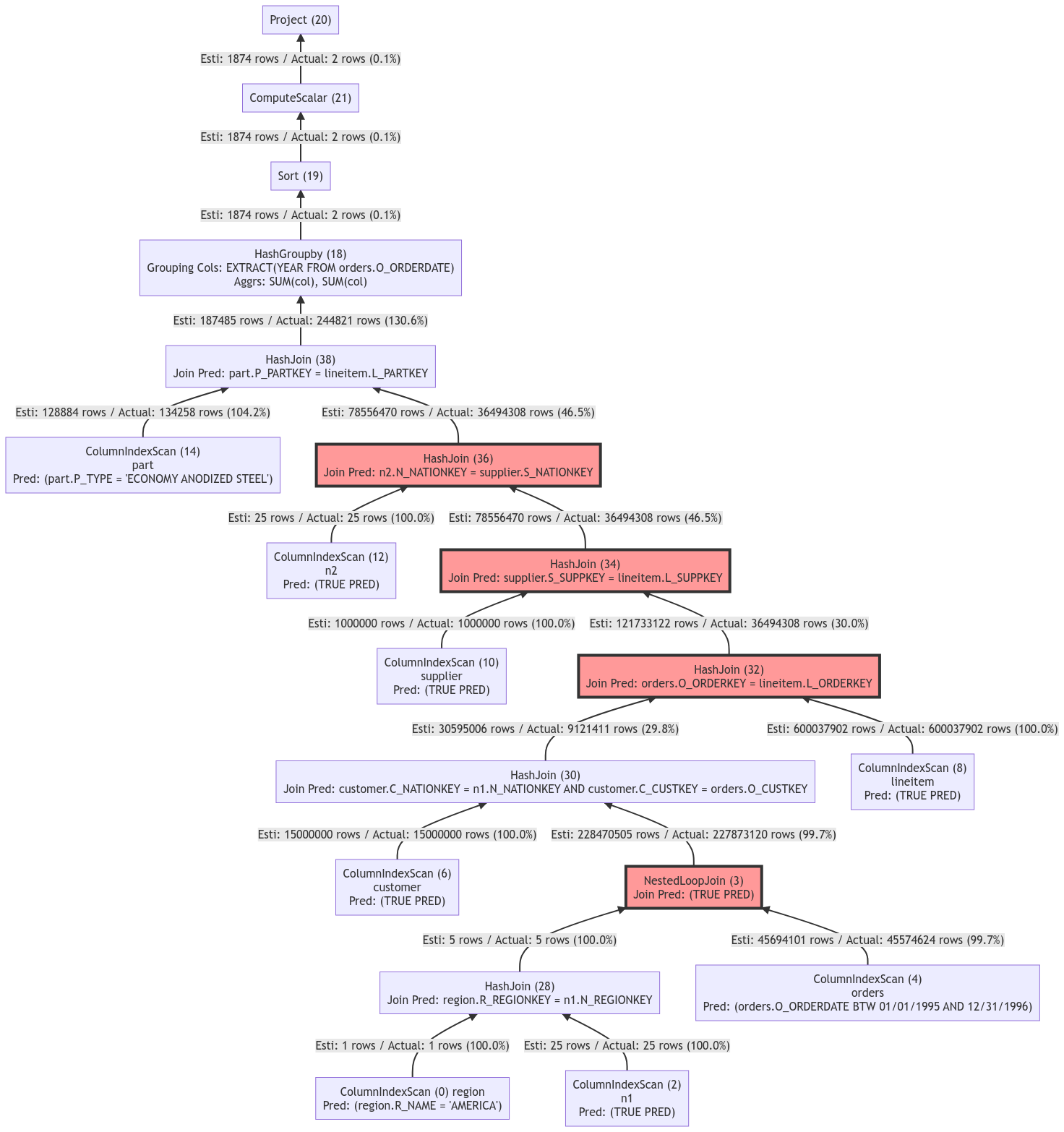 クエリプランには複数の結合が含まれ、大きな結果セットが生成されます。 これにより、オペレータが処理するデータ行と処理コストが増加し、レイテンシが長くなります。 テストでは、32コアクラスタとTPCH SF100データが使用されます。 クエリ期間は7,017ミリ秒です。
クエリプランには複数の結合が含まれ、大きな結果セットが生成されます。 これにより、オペレータが処理するデータ行と処理コストが増加し、レイテンシが長くなります。 テストでは、32コアクラスタとTPCH SF100データが使用されます。 クエリ期間は7,017ミリ秒です。 次の図は、IMCIクエリ最適化機能が有効になっている場合のクエリプランを示しています。
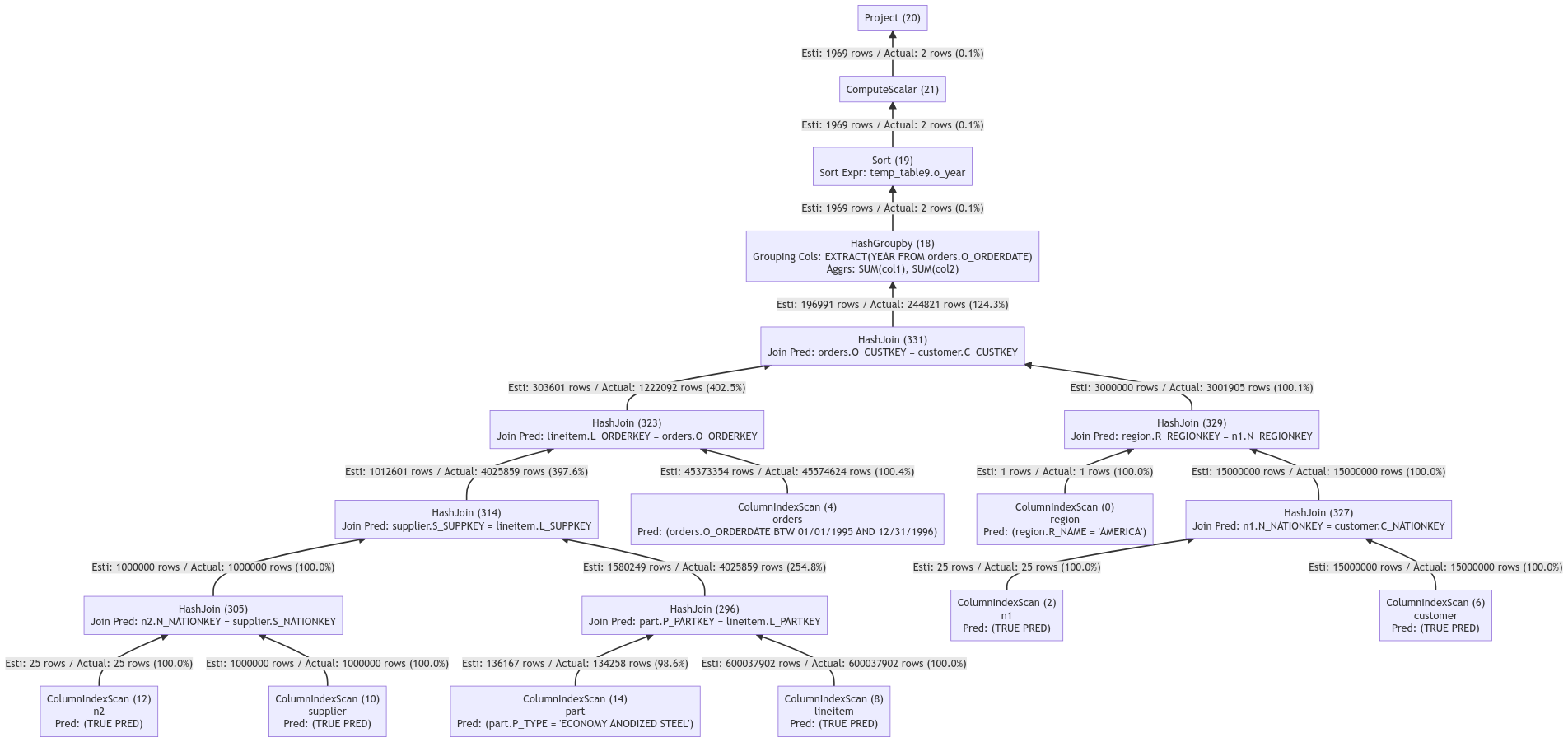 クエリオプティマイザは結合を再ソートして、ほぼすべての結合演算子の出力データを数百万行に減らします。 これにより、後続のオペレータの処理コストが削減される。 テストでは、32コアクラスタとTPCH SF100データが使用されます。 クエリ期間は1,900ミリ秒です。 クエリの期間は、IMCIクエリ最適化機能が無効になっている場合よりも73% に短くなります。
クエリオプティマイザは結合を再ソートして、ほぼすべての結合演算子の出力データを数百万行に減らします。 これにより、後続のオペレータの処理コストが削減される。 テストでは、32コアクラスタとTPCH SF100データが使用されます。 クエリ期間は1,900ミリ秒です。 クエリの期間は、IMCIクエリ最適化機能が無効になっている場合よりも73% に短くなります。