ハッシュ結合は、MySQL Community Edition 8.0 で導入された結合実行メソッドです。大規模なテーブルを結合する分析クエリでは、逐次的な結合処理がボトルネックとなることがよくあります。PolarDB for MySQL 8.0 では、シンプルハッシュ結合とシャッフルハッシュ結合という 2 種類の並列ハッシュ結合戦略をサポートしており、複数のワーカーに結合処理を分散させることでクエリの遅延を低減します。その他の並列実行ポリシーも開発中であり、今後リリースされる予定です。
戦略の選択
| 戦略 | 最小リビジョン | 最適なケース |
|---|---|---|
| シンプルハッシュ結合 | 8.0.2.1.0 | ハッシュテーブルがメモリに収まる結合 |
| シャッフルハッシュ結合 | 8.0.2.2.0 | ハッシュテーブルがディスクにスワップアウトする結合 |
シンプルハッシュ結合で大規模なハッシュテーブルによりディスク I/O が発生する場合は、シャッフルハッシュ結合を使用してください。
PolarDB では、アクティブなハッシュ結合戦略を確認するためにEXPLAIN FORMAT=TREEのみがサポートされています。他のEXPLAINフォーマットでは、ハッシュ結合の使用状況は表示されません。
シンプルハッシュ結合
前提条件
作業を開始する前に、以下の要件を満たしていることを確認してください。
リビジョンバージョン 8.0.2.1.0 以降の PolarDB for MySQL 8.0 Cluster Edition クラスター
リビジョンバージョンの確認方法については、「エンジンバージョンの照会」をご参照ください。
仕組み
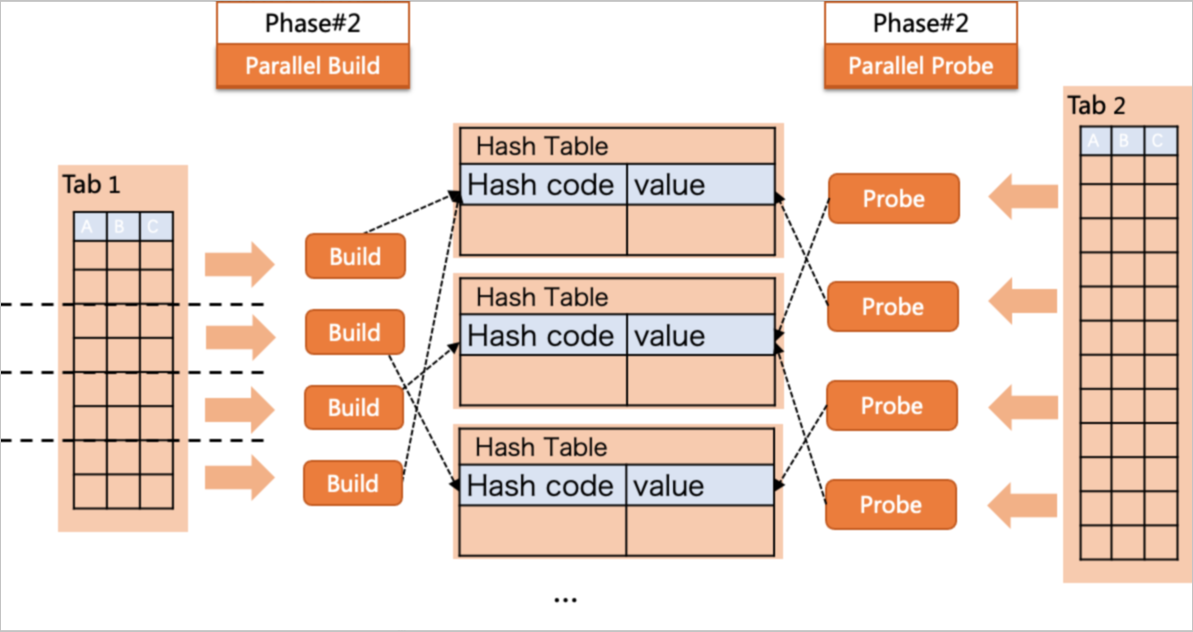
並列処理の次数 (DOP) が 4 の場合、4 つのワーカーが並列でテーブル t1 をスキャンします。各ワーカーは、自身が担当する t1 のデータ部分からローカルハッシュテーブルを構築し、そのハッシュテーブルに対して t2 の行をプローブします。リーダーノードが Gather 操作を実行して、すべてのワーカーから結果を収集・マージします。
この戦略は、ハッシュテーブルがメモリ内に収まる場合に効果的です。ハッシュテーブル全体が大きくなりすぎてディスク I/O がトリガーされる場合は、代わりにシャッフルハッシュ結合を使用してください。
シンプルハッシュ結合の使用確認
例
2 つのテーブルを作成し、それぞれに 1,000 行を挿入します。
CREATE TABLE t1 (c1 INT, c2 INT);
CREATE TABLE t2 (c1 INT, c2 INT);
INSERT t1(c1, c2)
WITH RECURSIVE seq AS (
SELECT 1 AS a, 1 AS b
UNION ALL
SELECT a + 1, b + 1 FROM seq WHERE a < 1000
)
SELECT a, b FROM seq;
INSERT INTO t2 SELECT * FROM t1;EXPLAIN FORMAT=TREE を PQ_DISTRIBUTE ヒントとともに実行し、シンプルハッシュ結合が選択されていることを確認します。
EXPLAIN FORMAT=TREE SELECT /*+ PQ_DISTRIBUTE(t1 PQ_NONE) PQ_DISTRIBUTE(t2 PQ_NONE) */ * FROM t1 JOIN t2 ON t1.c1 = t2.c2;期待される出力:
EXPLAIN FORMAT=TREE
EXPLAIN
-> Gather (slice: 1; workers: 4) (cost=10.82 rows=4)
-> Parallel inner hash join (t2.c2 = t1.c1) (cost=0.57 rows=1)
-> Parallel table scan on t2, with parallel partitions: 1 (cost=0.03 rows=1)
-> Parallel hash
-> Parallel table scan on t1, with parallel partitions: 1 (cost=0.16 rows=1)実行計画の読み方
| ノード | 役割 |
|---|---|
Parallel table scan on t1 | 各ワーカーが t1 のパーティション(ビルド側)をスキャン |
Parallel hash | 各ワーカーが自身の t1 パーティションからローカルハッシュテーブルを構築 |
Parallel inner hash join | 各ワーカーが自身のハッシュテーブルに対して t2 の行(プローブ側)をプローブ |
Gather (workers: 4) | リーダーが 4 つのワーカーから結果を収集 |
シャッフルハッシュ結合
前提条件
作業を開始する前に、以下の要件を満たしていることを確認してください。
リビジョンバージョン 8.0.2.2.0 以降の PolarDB for MySQL 8.0 Cluster Edition クラスター
リビジョンバージョンの確認方法については、「エンジンバージョンの照会」をご参照ください。
仕組み
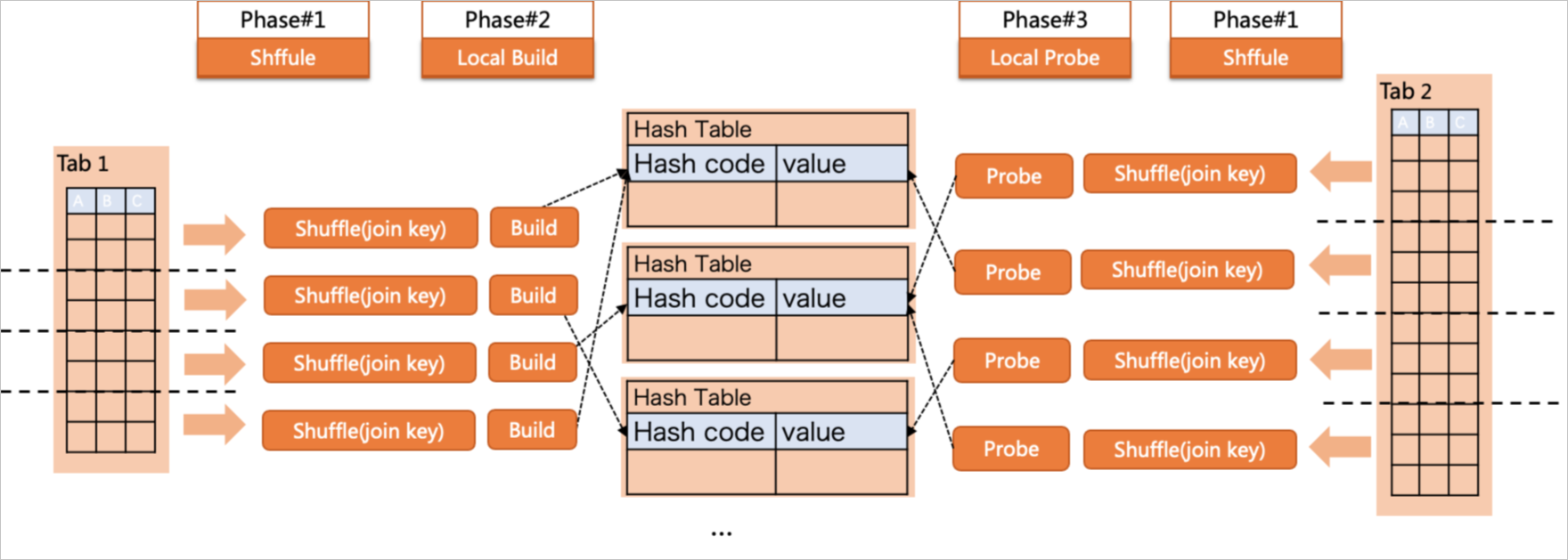
シャッフルハッシュ結合(パーティションハッシュ結合とも呼ばれる)は、シンプルハッシュ結合によるメモリ圧力を解消します。各ワーカーが完全データからハッシュテーブルを構築するのではなく、まず両方のテーブルを結合キーに基づいて再パーティションします。その後、各ワーカーが割り当てられたパーティションのみから小さなハッシュテーブルを独立して構築します。
DOP が 2 の場合、実行は次の 3 つのフェーズで進みます。
ビルドフェーズ:ワーカーが
t1をスキャンし、結合キーに基づいて行を再パーティションし、各ワーカーが割り当てられたパーティションから小さなハッシュテーブルを構築します。プローブフェーズ:ワーカーが
t2をスキャンし、同じ結合キーに基づいて行を再パーティションし、対応するハッシュテーブルのパーティションをプローブします。Gather:リーダーがすべてのワーカーから結果を収集・マージします。
各ハッシュテーブルがデータの一部のみをカバーするため、シャッフルハッシュ結合はディスクへのスワップなしで大規模データセットを処理できます。
シャッフルハッシュ結合の使用確認
例
シンプルハッシュ結合の例で作成した t1 および t2 テーブルを使用します。EXPLAIN FORMAT=TREE をヒントなしで実行すると、PolarDB は適切な場合に自動的にシャッフルハッシュ結合を選択します。
EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.c1 = t2.c2;期待される出力:
EXPLAIN FORMAT=TREE
EXPLAIN
| -> Gather (slice: 1; workers: 2) (cost=33.38 rows=4)
-> Inner hash join (t2.c1 = t1.c1) (cost=23.08 rows=2)
-> Repartition (hash keys: t2.c1; slice: 2; workers: 1) (cost=11.35 rows=2)
-> Parallel table scan on t2, with parallel partitions: 1 (cost=0.65 rows=4)
-> Hash
-> Repartition (hash keys: t1.c1; slice: 3; workers: 1) (cost=11.35 rows=2)
-> Parallel table scan on t1, with parallel partitions: 1 (cost=0.65 rows=4)実行計画の読み方
| ノード | 役割 |
|---|---|
Repartition (hash keys: t1.c1) | 結合キーに基づいて t1 の行をワーカーに再分配(ビルド側) |
Hash | 各ワーカーが割り当てられた t1 パーティションから小さなハッシュテーブルを構築 |
Repartition (hash keys: t2.c1) | 結合キーに基づいて t2 の行を対応するワーカーに再分配(プローブ側) |
Inner hash join | 各ワーカーが自身のハッシュテーブルに対して割り当てられた t2 の行をプローブ |
Gather (workers: 2) | リーダーがすべてのワーカーから結果を収集 |