このトピックでは、Compute Express Link (CXL) を使用してコンピューティング、メモリ、ストレージを分離する PolarDB for MySQL の 3階層アーキテクチャについて説明します。この技術の中核となるイノベーションは、SIGMOD 2025 で最優秀論文賞を受賞した論文「Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases」で詳述されています。PolarDB for MySQL は PolarCXLMem を使用して、パフォーマンス専有型のメモリプールを計算ノードに直接接続する分離メモリシステムを構築します。このアーキテクチャにより、CXL メモリを数秒でロードでき、シングルノードの最大メモリを 8 TB まで拡張できます。sysbench の I/O バウンドモデルでは、このアーキテクチャによりパフォーマンスが 100% 以上向上します。さらに、独自の PolarRecv 技術と CXL メモリの永続化機能を組み合わせることで、データベースのクラッシュリカバリ性能が 40 倍以上向上します。CXL ベースのメモリプーリングは、人工知能 (AI) のトレーニングや推論シナリオにも適しています。
Compute Express Link (CXL) メモリ拡張機能は現在カナリアリリース中です。この機能の使用を希望される場合、またはご質問がある場合は、チケットを送信してお問い合わせください。
適用範囲
クラスターバージョン:MySQL 8.0.2、マイナーエンジンバージョン 8.0.2.2.31.1 以降。
仕組み
従来のアーキテクチャでは、メモリリソースのスケールアウトは困難でコストがかかります。この課題に対処するため、PolarDB for MySQL は CXL 2.0 技術を利用して、革新的な PolarCXLMem 分離メモリアーキテクチャを提供します。このアーキテクチャは、CXL メモリプールを使用して DRAM を拡張します。プールは計算ノードに直接接続され、データベースエンジンはローカルメモリにアクセスするのと同じように、ネイティブの Load/Store 命令を使用して CXL メモリ内のデータを読み書きできます。
従来の Remote Direct Memory Access (RDMA) ソリューションと比較して、PolarCXLMem アーキテクチャは複雑なネットワークプロトコルスタックやデータコピーを必要としません。これにより、パフォーマンスのオーバーヘッドと書き込み増幅が回避されます。コンピューティングとメモリの真のデカップリングを実現し、DRAM に近いパフォーマンス、低コスト、大容量のメモリオプションを提供します。
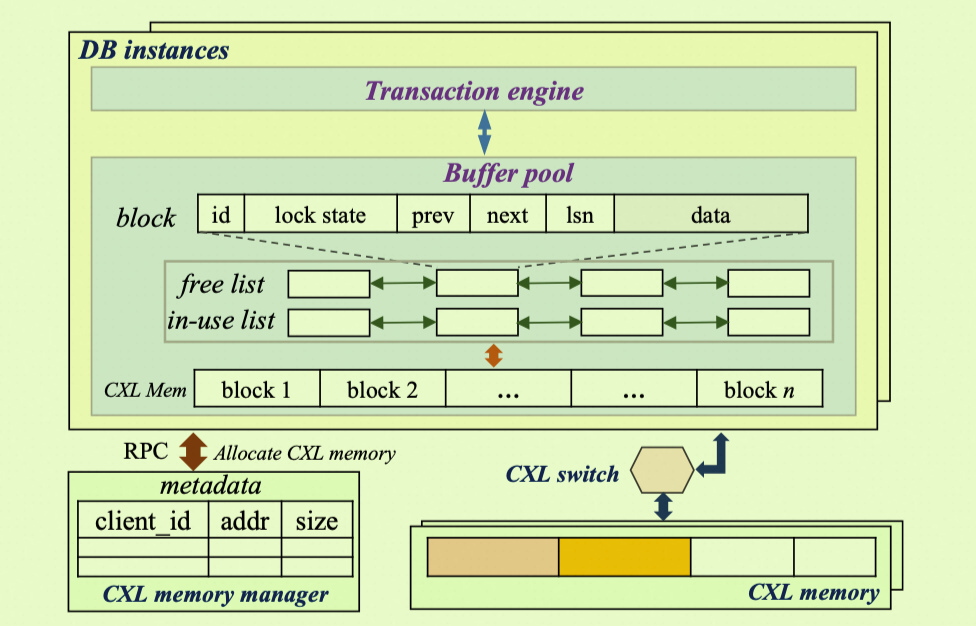
統一された非階層的なメモリ設計
PolarDB の 3階層デカップリング (RDMA) ソリューションが RDMA ネットワーク経由でリモートメモリにアクセスするのとは異なり、PolarCXLMem は CXL.mem プロトコルを使用して CXL メモリデバイスをホストの物理アドレス空間に直接マッピングします。データベースカーネルにとって、DRAM と CXL メモリは単一の非階層的なバッファプールを形成します。CPU はネイティブの
Load/Store命令を使用して、ローカル DRAM にアクセスするのと同じ方法で CXL メモリに直接アクセスします。これにより、異なるメモリ階層間でのページの入れ替えによって生じるパフォーマンスのオーバーヘッドと書き込み増幅が回避されます。ハードウェアレベルのキャッシュコヒーレンシ
CXL.cache プロトコルは、CPU キャッシュと CXL メモリ間のデータ整合性をハードウェアレベルで保証します。これにより、データベースソフトウェアが追加のキャッシュ管理を行う必要がなくなり、アーキテクチャが簡素化され、効率が向上します。
永続メモリを使用した数秒でのリストア (PolarRecv)
PolarRecv 技術は、CXL メモリの永続化機能を活用します。データベースがクラッシュした場合、CXL 永続メモリ上のバッファプールのデータは、redo ログをリプレイして回復する必要がありません。PolarRecv を使用すると、データベースは CXL メモリから直接データをロードできます。これにより、数秒でのロードが可能になり、目標復旧時間 (RTO) が秒単位に短縮されます。特定のテストシナリオでは、回復速度が 40 倍以上向上します。
メリット
大幅なコスト削減:CXL メモリのギガバイトあたりのコストはローカル DRAM よりもはるかに低く、データベースの総メモリコストを 30% から 50% 削減します。また、コンピューティングリソースとメモリリソースは、従量課金制で弾力的かつ独立してスケーリングできるため、リソースの無駄を防ぎます。
容量制限の克服:単一の物理サーバのメモリスロットの制限を克服し、単一の計算ノードのメモリ容量を 8 TB まで増加させます。これにより、非常に大規模なデータセットの分析およびクエリシナリオを効果的に処理できます。
DRAM に近いパフォーマンス:点クエリ、混合読み取り、読み書き混合など、さまざまなオンラインランザクション処理 (OLTP) ワークロードシナリオにおいて、CXL メモリを追加すると、クラスターのパフォーマンスが 20% から 112% 向上します。さらに、独自の
PolarRecv技術と CXL メモリの永続性により、データベースのクラッシュリカバリの RTO を 40 倍以上短縮できます。
利用シーン
メモリ集約型のオンラインランザクション処理 (OLTP):ソーシャルメディア、ゲーム、E コマースなどのシナリオでは、ユーザー関係、製品情報、リアルタイム注文などのコアデータをメモリ内に常駐させ、低レイテンシのアクセスを保証する必要があります。CXL メモリを使用すると、より大きなワーキングセットをコスト効率よくメモリにキャッシュし、I/O オーバーヘッドを削減できます。
大規模データ分析とレポーティング (分析処理、AP):大量のデータセットに対する複雑なクエリやリアルタイム分析を必要とするサービスでは、CXL メモリの大容量により、より多くのデータを保持できます。これにより、クエリ処理が高速化され、メモリ不足による頻繁なディスク読み取りが回避されます。
開発・テスト環境:開発・テスト環境に大容量のメモリ仕様を構成する場合、CXL メモリはコスト効率の高い選択肢です。これにより、低コストで大容量メモリの本番環境をシミュレートできます。
パフォーマンス・テストレポート
以下のパフォーマンスデータは、特定のテスト環境で得られたものであり、参考用です。実際のパフォーマンスは、クラスターの仕様、ワークロード、データパターン、パラメーター設定などの要因によって異なる場合があります。
テスト環境
クラスター仕様:8.0.2 Enterprise Edition、専用、8 コア、32 GB。
テストデータ:40 テーブル、各テーブル 10,000,000 行。
ソリューション比較
プラン A (ベースライン):8 コア、32 GB、利用可能な総メモリ 32 GB。
プラン B (CXL 拡張):8 コア、32 GB + 64 GB の CXL メモリ、利用可能な総メモリ 96 GB。
このテストは、基本仕様に CXL メモリを追加したことによるパフォーマンス向上を比較するものです。この比較は、CXL メモリと同量の純粋な DRAM とのパフォーマンス差を反映するものではありません。このテストの主な目的は、CXL によるメモリ容量の拡張がデータベースのスループットに与える影響を検証することです。
テスト結果
64 GB の CXL メモリを追加した後、クエリ/秒 (QPS) で測定したクラスター全体のパフォーマンスは最大 112% 向上しました。これは、より大きなバッファプールがより多くのデータをキャッシュでき、ディスク I/O が削減されるためです。
点クエリ (oltp_point_select)
CXL メモリプールを有効にすると、パフォーマンスが 50% から 112% 向上します。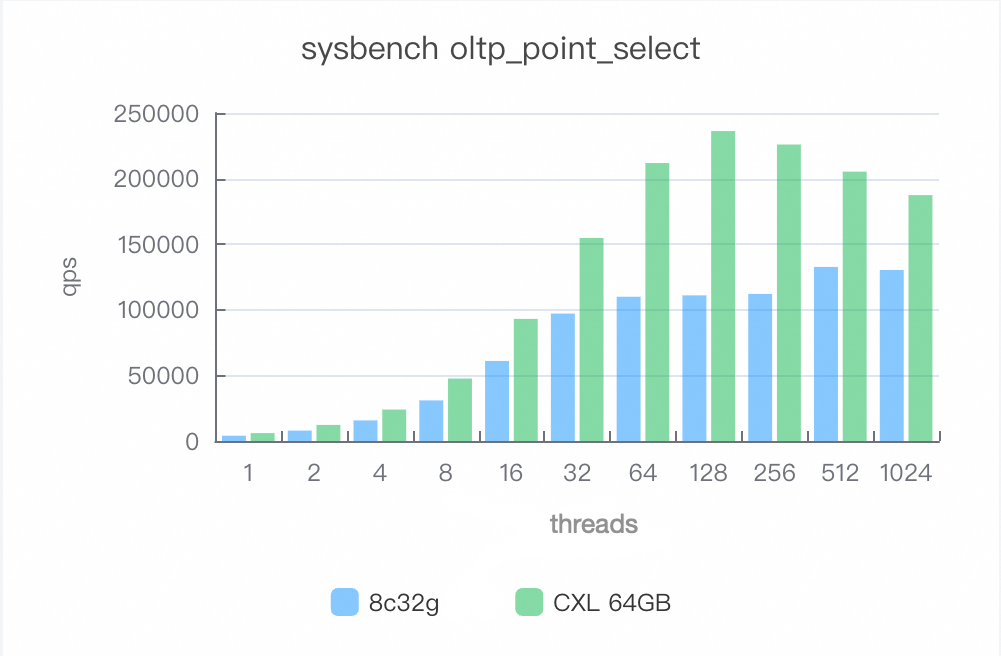
混合読み取り (oltp_read_only)
CXL メモリプールを有効にすると、パフォーマンスが 30% から 80% 向上します。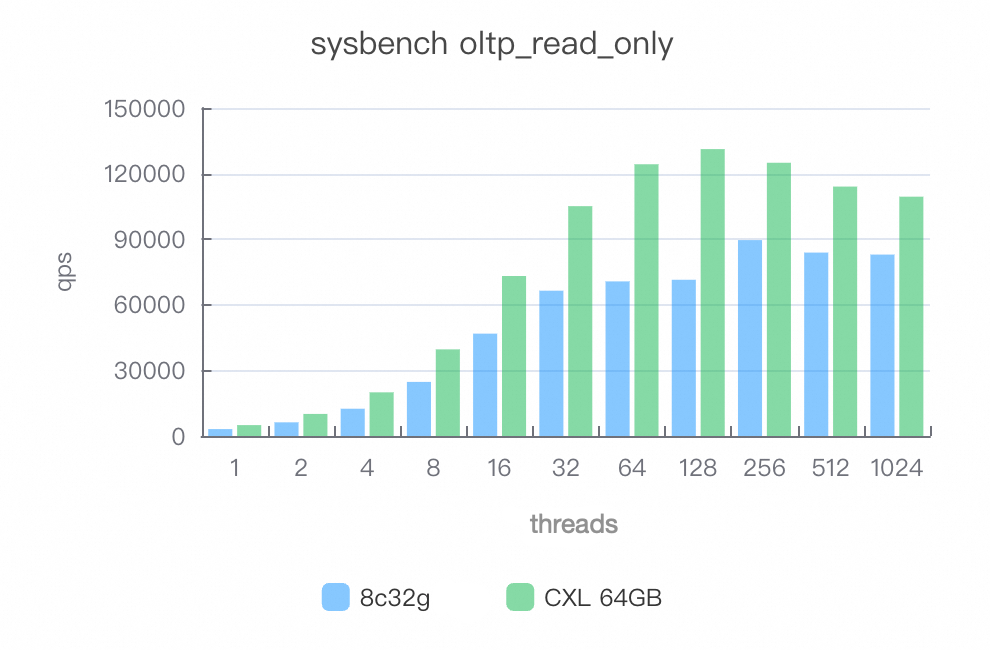
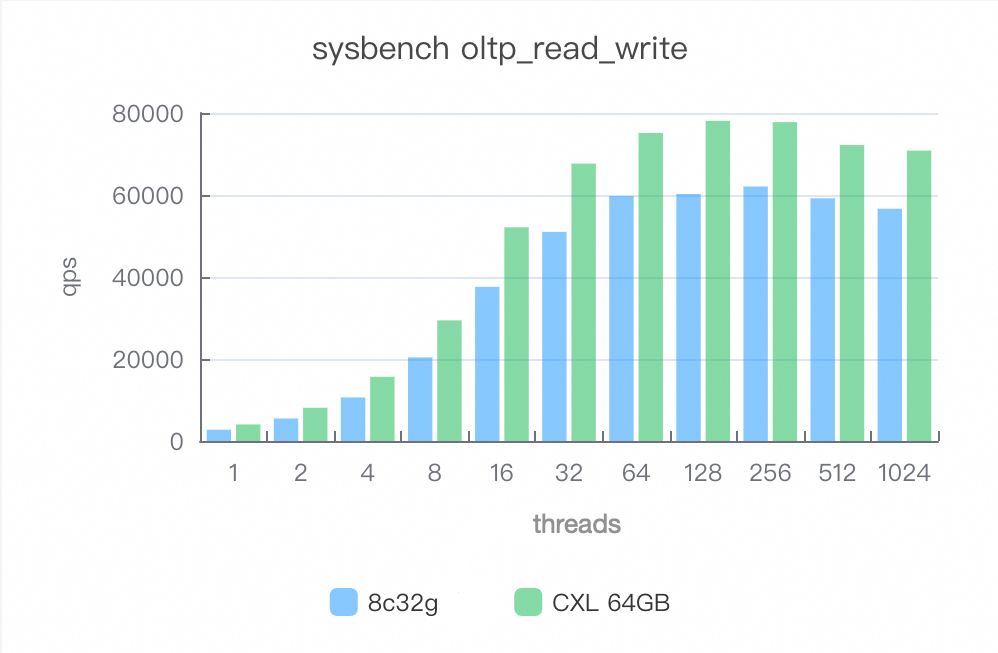
読み書き混合 (oltp_read_write)
CXL メモリプールを有効にすると、パフォーマンスが 20% から 50% 向上します。