ビジネスデータ量が急増する中、多くの企業は大規模なデータストレージコストの管理と分析効率の維持という課題に直面しています。PolarDB for MySQL では、この課題に対応するため、X-Engine カラムナーテーブル機能を提供しています。この機能は、カラムナー(列指向)ストレージ、高効率な圧縮、並列計算に基づいて構築されており、データストレージコストを元のデータサイズの 10 % まで削減し、分析クエリのパフォーマンスを桁違いに向上させます。これにより、低コストでの大規模データアーカイブおよび高性能なリアルタイム分析が可能になりながらも、MySQL エコシステムとの完全互換性を維持します。
概要
X-Engine カラムナーテーブルは、コンピュートとストレージの分離に基づくアーキテクチャを採用しています。これにより、コンピュートリソースとストレージリソースを独立かつ弾力的にスケーリングでき、ペタバイト級のデータ処理能力を実現します。ストレージレイヤーは分散ファイルシステムおよび OSS 上に構築されています。コンピュートレイヤーでは、クエリ オプティマイザー、実行演算子、ストレージエンジンを深く最適化することで、高性能な分析を提供します。
技術アーキテクチャ
PolarDB 全体アーキテクチャ
PolarDB は、分散ストレージレイヤー上に構築されたコンピュートとストレージの分離アーキテクチャを採用しています。システムは ParallelRaft プロトコルを使用してマルチレプリカの一貫性を保証し、OSS を透過的にサポートします。コンピュートノードは、1 つの読み書きノード (RW) と 1 つ以上の読み取り専用ノード (RO) で構成され、InnoDB および X-Engine の両方のエンジンをサポートします。データベースプロキシはアプリケーションとコンピュートノード間のブリッジとして機能し、読み書き分離および負荷分散を提供します。
カラムナーテーブル アーキテクチャ
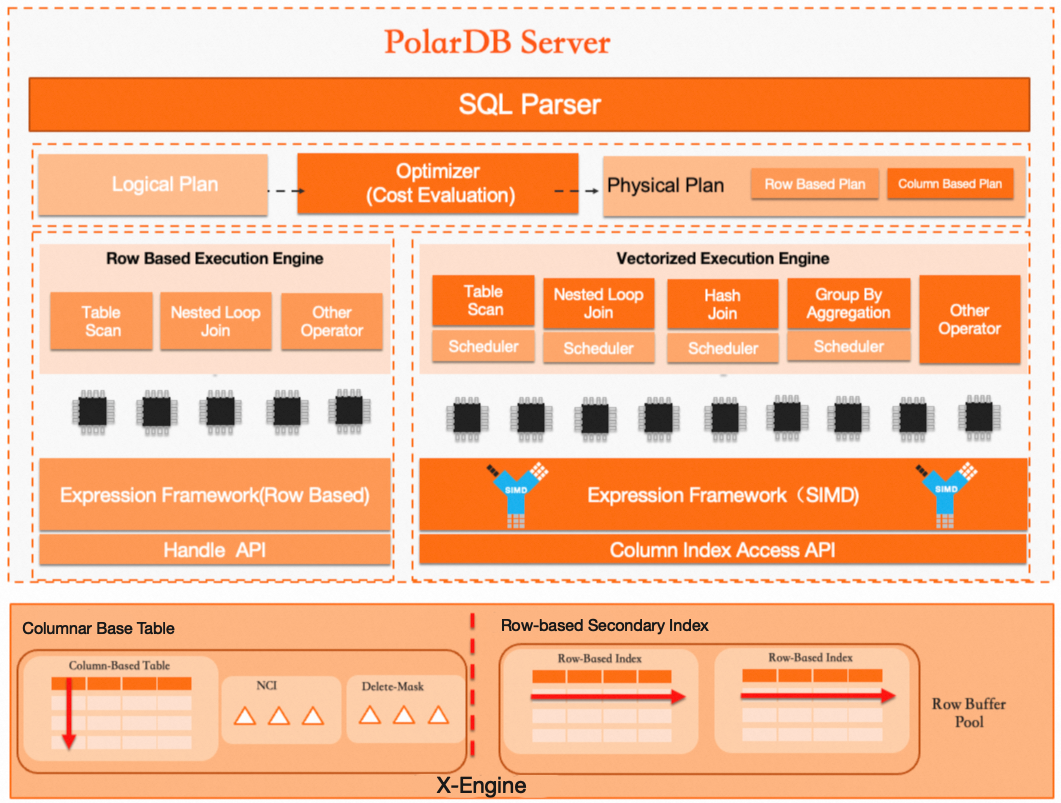
その主要な技術コンポーネントは以下のとおりです。
クエリ オプティマイザー:行指向および列指向ストレージの混在環境向けに内蔵されたコストベースオプティマイザ (CBO) です。クエリコストを推定し、行ストレージまたは列ストレージのいずれかから最適な実行計画を自動選択します。
実行演算子:列指向のベクトル化および並列実行技術を採用しています。バッチ処理により、単一テーブルおよび複数テーブル結合の両方において分析クエリを大幅に高速化します。
ストレージエンジン:リアルタイムのトランザクション更新をサポートします。主テーブルはカラムナーストレージを使用し、Non-Clustered Index (NCI) コンポーネントを活用して高速な更新機能を提供します。削除マスク機構により削除対象データにフラグを設定し、リアルタイム書き込みに影響を与えることなく効率的な並列クエリを実現します。さらに、行ストアのセカンダリインデックスにより不要なデータを迅速にフィルターでき、クエリ効率をさらに向上させます。
テーブルタイプの比較
以下の表では、従来の行指向テーブル(例:InnoDB)と PolarDB カラムナーテーブルの主な相違点を比較し、適切なタイプの選定を支援します。
項目 | 行指向テーブル (X-Engine) | 列指向テーブル |
データの組織形式 | データは行単位で隣接して格納されます。1 行のすべての列がまとめて保存されます。 | データは列単位で隣接して格納されます。1 列のすべての値がまとめて保存されます。 |
データ圧縮率 | 中程度。InnoDB と比較して、データサイズを元の 3/10 まで圧縮できます。 | 高い。カラムナーストレージおよび辞書エンコーディングなどの特殊なエンコーディングにより、InnoDB と比較してデータサイズを元の 1/10 まで圧縮できます。 |
クエリパフォーマンス | ポイントルックアップに優れています。プライマリキーまたはインデックスに基づいて単一行または少数の行を高速に読み取る Online Transaction Processing (OLTP) シナリオに適しています。 | 分析に強みがあります。クエリは必要な列のみを読み取るため、I/O が大幅に削減されます。ベクトル化された並列計算と組み合わせることで、分析パフォーマンスは行指向テーブルの桁違いに高くなります。 |
更新・削除パフォーマンス | 高い。行を直接特定して変更します。 | やや低めですが、リアルタイム更新をサポートします。NCI コンポーネントにより、変更対象レコードを迅速に特定できます。 |
利用シーン | Online Transaction Processing (OLTP)。たとえば、高同時実行の挿入、削除、更新、クエリ操作など。 | オンライン分析処理 (OLAP)。たとえば、データアーカイブ、レポート生成、アドホッククエリ、大規模集計データ分析など。 |
メリット
コスト効率:カラムナーストレージ、高効率なエンコーディング、高圧縮アルゴリズム、OSS などの低コストストレージメディアを組み合わせることで、大規模データセットのストレージおよび処理コストを最大 90 % 削減します。
高性能なリアルタイム分析:書き込まれたデータは即座に分析クエリに利用可能です。マルチコア並列処理、ベクトル化、Massively Parallel Processing (MPP) 技術を活用することで、クエリパフォーマンスは専用分析データベースと同等となり、厳しいリアルタイム分析要件を満たします。
MySQL 100 % 互換:MySQL と一貫したデータ型システムおよびプロトコルを提供し、柔軟な型変換をサポートします。既存のアプリケーションおよびツールを変更せずに接続できます。
独立した弾力的スケーリング:コンピュートとストレージの分離により、ビジネスピークおよびデータ増加に対応して、コンピュートノードおよびストレージ容量をオンデマンドで独立してスケーリングできます。
強力なワイドテーブルサポート:単一テーブルで最大 10,000 列をサポートし、ワイドテーブルストレージおよび高同時実行書き込みのビジネス要件を満たします。
優れた使いやすさ:単一のデータベースエンジン内で高圧縮ストレージおよび高性能分析をサポートし、DDL および DML 操作を完全にサポートすることで、技術スタックおよび運用管理を簡素化します。
ユースケース
低コストデータアーカイブ
課題:ビジネスの成長に伴い、過去の注文、ログ、取引レコードなどの既存データがコアデータベースに急速に蓄積され、高価なストレージスペースを消費します。従来のデータ移行ソリューションではコストを削減できますが、データをオフライン化することが多く、オンラインアクセスが複雑になります。
ソリューション:カラムナーテーブルを使用してオンラインデータアーカイブを行います。行指向テーブル (InnoDB) からのコールドデータ、または既存の履歴データテーブル全体を、同一の PolarDB クラスター内のカラムナーテーブルに移行できます。
主な価値:
大幅なコスト削減:最大 10:1 の圧縮率と OSS などの低コストストレージメディアの利用により、ストレージコストを最大 90 % 削減できます。
オンラインデータ可用性:アーカイブされたデータはオンラインのまま利用可能です。複雑なデータ移行プロセスなしに、標準 SQL を使用していつでもクエリおよび分析が可能です。
シームレスなアプリケーション統合:アプリケーション側からは、カラムナーテーブルは通常の MySQL テーブルと同様に機能するため、コード変更は不要です。
専用データウェアハウス
課題:専用データウェアハウスを構築する際、企業は高額なハードウェアコスト、複雑なデータ同期パイプライン (ETL)、ClickHouse などの新技術導入に伴う急峻な運用学習曲線といった課題に直面します。
ソリューション:PolarStore の大容量ストレージ機能を活用して複数の上流ソースからデータを集約し、X-Engine カラムナーテーブルに一元的に格納します。これにより、大規模で低コストなストレージおよびリアルタイム集計分析パフォーマンスの恩恵を受けられます。
主な価値:
コストおよび複雑性の低減:高額な専用ハードウェアの購入や異種分析システムの導入なしに、馴染みのある MySQL エコシステム内でデータウェアハウスを構築できます。これにより、技術スタックが簡素化され、運用オーバーヘッドが軽減されます。
リアルタイムデータ分析:上流データをカラムナーテーブルにリアルタイムで統合して分析できるため、従来の ETL ソリューションで一般的な T+1 のデータ遅延を回避します。
大規模データ処理能力:X-Engine ストレージアーキテクチャおよび高効率な圧縮により、ペタバイト規模のデータを低コストでストレージおよび処理できます。
フェデレーテッドクエリ分析
課題:ビジネスデータはしばしば異なるシステムに分散しています。一部のデータは PolarDB などのオンラインデータベースに存在し、他のデータは OSS 上の Parquet や ORC などのオープンフォーマットで保存されています。これらの異なるデータセットを一緒に分析するには、通常、OSS データをデータベースにインポートする複雑な ETL プロセスが必要です。
ソリューション:PolarDB の外部テーブル機能を使用して、OSS 上のデータを直接クエリします。
コアバリュー:
インプレース分析:データが保存されている場所でクエリを実行します。PolarDB 内に OSS 上のファイルを指す外部テーブルを作成し、データを移動またはインポートすることなく標準 SQL で直接クエリできます。
フェデレーテッドクエリ:PolarDB 内のローカルテーブル(行指向またはカラムナー)と OSS 外部テーブルの間で
JOIN操作を簡単に実行し、オンラインおよびオフラインデータを横断した統合分析が可能です。
パフォーマンス
以下のパフォーマンスデータは特定のテスト環境で取得したものであり、カラムナーテーブル のメリットを評価するためのリファレンスとしてご利用ください。
本トピックで使用している TPC-H 実装は TPC-H ベンチマークに基づいていますが、これらのテストは TPC-H 仕様に完全には準拠していないため、公開されている TPC-H ベンチマーク結果との比較はできません。
データロードパフォーマンス
以下のデータは、32 コアおよび 256 GB メモリのテスト環境に基づき、TPC-H および Airline データセットを使用してカラムナーテーブルと ClickHouse、Doris のデータロードおよびストレージパフォーマンスを比較したものです。
ロード速度
TPC-H データセット:カラムナーテーブルのロード速度は 571 万行/秒に達し、書き込みスループットは 50 GB/分でした。これは ClickHouse の約 2.7 倍です。
Airline データセット:カラムナーテーブルのロード速度は 430 万行/秒に達し、書き込みスループットは 27 GB/分でした。これは ClickHouse の約 2 倍です。
データセット | ClickHouse (百万行/秒) | Doris (百万行/秒) | カラムナーテーブル (百万行/秒) |
TPC-H | 2.10 | 4.54 | 5.71 |
Airline | 1.40 | 2.15 | 4.30 |
ストレージ使用量
TPC-H データセット:生データ 100 GB に対して、カラムナーテーブルは 4 倍の圧縮率を達成しました。
Airline データセット:生データ 75 GB に対して、カラムナーテーブルは 18 倍の圧縮率を達成しました。
以下の表は、75 GB の Airline データセットにおけるストレージ使用量の比較です。
タイプ/製品 | ClickHouse | Doris | カラムナーテーブル |
ストレージ使用量 (GB) | 9.29 | 4.49 | 3.97 |
圧縮率 | 約 8 倍 | 約 16 倍 | 約 18 倍 |
TPC-H クエリパフォーマンス
TPC-H 100 GB データセットを使用した性能テストにおいて、カラムナーテーブルが 22 件すべてのクエリを実行するのに要した総時間は 17.994 秒でした。一方、ClickHouse は 76.9 秒でした。カラムナーテーブルの全体的なパフォーマンスは、ClickHouse の約 4.3 倍高い結果となりました。
クエリ
カラムナーテーブル (秒)
ClickHouse (秒)
Q1
1.175
2.2
Q2
0.178
0.9
Q3
0.577
1.6
Q4
0.433
1.3
Q5
0.522
3.3
Q6
0.366
0.32
Q7
0.633
1.7
Q8
0.528
1.8
Q9
2.817
12
Q10
0.935
2.3
Q11
0.218
0.66
Q12
0.535
1.4
Q13
1.255
4.4
Q14
0.442
0.3
Q15
0.889
0.42
Q16
0.553
0.6
Q17
0.738
4.2
Q18
2.381
4.3
Q19
0.759
2
Q20
0.453
0.6
Q21
1.308
29.6
Q22
0.299
1
合計
17.994
76.9
マルチノード並列分析:TPC-H 1 TB データセットを使用した性能テストにおいて、カラムナーテーブルはマルチノード並列アクセラレーションを活用し、シングルノード時の総クエリ時間 1,420.551 秒を、6 ノード構成では 167.948 秒に短縮しました。
クエリ
1 ノード (秒)
2 ノード (秒)
4 ノード (秒)
6 ノード (秒)
Q1
76.849
36.831
23.031
20.022
Q2
5.841
2.805
1.527
1.09
Q3
133.69
26.131
15.833
4.75
Q4
51.466
19.02
3.353
2.362
Q5
52.965
26.844
13.715
4.269
Q6
34.577
21.831
35.17
11.274
Q7
75.996
29.659
17.279
5.717
Q8
54.989
28.922
15.651
3.375
Q9
155.33
78.216
40.38
25.983
Q10
72.222
31.659
17.177
4.594
Q11
4.149
2.049
1.351
1.069
Q12
50.997
27.79
16.207
2.977
Q13
73.009
31.742
17.605
16.255
Q14
36.887
22.093
4.475
3.778
Q15
66.217
38.628
7.583
6.451
Q16
11.493
4.49
2.528
1.758
Q17
59.225
37.101
11.434
8.767
Q18
132.604
53.578
17.164
10.797
Q19
72.794
38.416
23.759
16.651
Q20
42.621
22.432
5.62
4.768
Q21
149.245
54.803
12.758
8.793
Q22
7.385
5.684
2.972
2.448
合計
1420.551
640.724
306.572
167.948