このベンチマークでは、1億件規模、1,000 ディメンションのベクターからなるデータセットに対する PolarDB ベクターインデックスの書き込みおよびクエリパフォーマンスを実証します。テストでは、特定のハードウェアおよびソフトウェア構成で OpenSearch プロトコルを使用します。このトピックでは、テスト環境、データセット、主要な構成パラメーター、再現手順、およびパフォーマンス結果の分析について説明します。この結果は、技術選定、容量計画、パフォーマンスチューニングに役立つデータを提供します。
適用範囲
このパフォーマンスデータは、特定のクラスター環境とデータセットに基づいています。このデータを意思決定に利用する前に、ご利用の環境が以下に説明する環境と類似していることを確認してください。
クラスターの仕様とバージョン
マスターノード:2 コア 8 GB
読み取り専用ノード:2 コア 8 GB
検索ノード:32 コア 256 GB × 3
クライアントレイテンシー:0.097 ms
PolarDB ベクトルインデックスバージョン:2.19.3
データセット
カテゴリ | 項目 | 詳細 |
ソフトウェアバージョン | PolarDB-Vector | 2.19.3 |
データセット | MSMARCO V2.1 | |
データ規模 | 総ドキュメント数 | 113,520,750 |
ベクトルディメンション | 1024 | |
クエリセットサイズ | 1677 | |
アルゴリズムパラメーター | 距離尺度 | L2 (ユークリッド距離) |
インデックスタイプ | HNSW |
テスト手順
以下の手順では、インデックス作成、データ書き込み、およびパフォーマンスストレステストを再現する方法について説明します。
テストスクリプトを入手し、このテストフローを再現するには、チケットを送信してください。
HNSW インデックスの作成とデータ書き込み
インデックスの作成:以下の構成を使用して、1億件規模のデータセット用のインデックスを作成します。この構成は、ビルド速度、メモリ使用量、クエリパフォーマンスのバランスを取るものです。
インデックススキーマと主要パラメーターの定義
number_of_shards:3つの検索ノード (合計 96 物理コア) にデータと計算ワークロードを均等に分散させるため、18 に設定します。ef_constructionとm:これらは HNSW インデックスを構築するための主要パラメーターです。このテストでは、ビルド速度とインデックス品質のバランスを取るために128と8を使用します。refresh_intervalとdurability:これらはテストパフォーマンスを最大化するための特別な最適化であり、本番環境で直接使用することは推奨されません。詳細については、「本番運用時の注意点」をご参照ください。
次のコマンドを実行してインデックスを作成します。
curl -X PUT "http://<endpoint>:<port>/msmarco" -H 'Content-Type: application/json' -d' { "mappings": { "properties": { "docid": { "type": "keyword" }, "domain": { "type": "keyword" }, "emb": { "type": "knn_vector", "dimension": 1024, "method": { "engine": "faiss", "space_type": "l2", "name": "hnsw", "parameters": { "ef_construction": 128, "m": 8 } } }, "url": { "type": "text" } } }, "settings": { "index": { "replication": { "type": "DOCUMENT" }, "refresh_interval": "0s", "number_of_shards": "18", "translog": { "flush_threshold_size": "1gb", "sync_interval": "30s", "durability": "async" }, "knn.algo_param": { "ef_search": "64" }, "provided_name": "msmarco", "knn": "true", "number_of_replicas": "0" } } } '
データ書き込み:MSMARCO V2.1 データセットを HNSW インデックスに書き込みます。
書き込みパフォーマンス
合計時間:13,523.85 秒 (約 3.75 時間)。この時間には、データネットワーク転送、translog への書き込み、バックグラウンドでの HNSW インデックス構築が含まれます。
平均書き込みスループット:8,394.11 docs/sec
クエリパフォーマンステストの実行
同時実行数と ef_search パラメーターのさまざまな組み合わせを使用して、クエリスループット (QPS)、レイテンシー、取得率をテストしました。
concurrency:1 から 128 までの同時クエリをシミュレートします。ef_search:クエリ中に HNSW グラフで検索される近傍ノードの幅。値が大きいほど理論的には取得率が高くなりますが、計算オーバーヘッドも増加するため、QPS が低下し、レイテンシーが増加します。
ストレステストコマンド
concurrency と ef_search のさまざまな組み合わせで 60 秒間のストレステストを実行するには、次のコマンドを実行します。
# コマンド例。実際のスクリプトに置き換えてください。
python benchmark.py --concurrency 1/2/4/8/16/32/64/128 --ef-search 32/64/128/256 --max-duration 60パフォーマンステスト結果
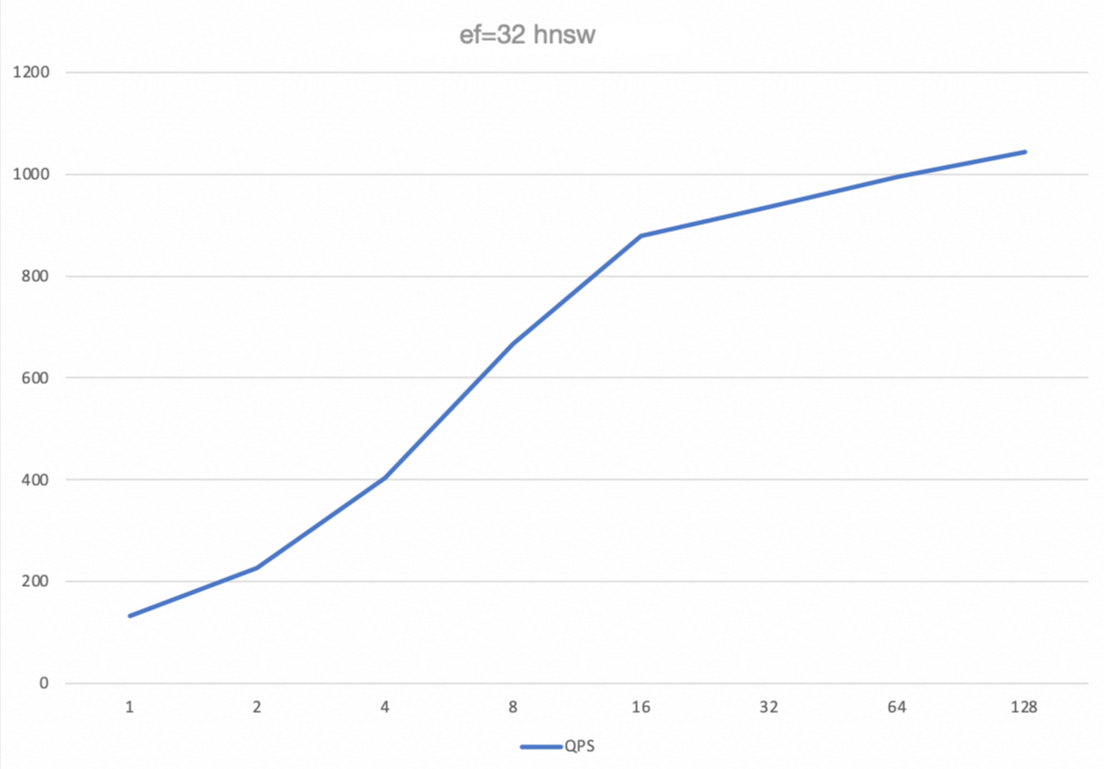
ef_search | concurrency | QPS | Avg (ms) | P99 (ms) | 再呼び出し |
32 | 1 | 132.4 | 7.53 | 8.83 | 0.9585 |
32 | 16 | 878.19 | 18.13 | 30.14 | 0.9586 |
32 | 64 | 994.43 | 63.48 | 135.83 | 0.9621 |
32 | 128 | 1043.22 | 118.53 | 256.14 | 0.9693 |
64 | 1 | 132.82 | 7.5 | 8.82 | 0.9585 |
64 | 16 | 878.44 | 18.11 | 30.35 | 0.9586 |
64 | 64 | 989.47 | 63.77 | 136.55 | 0.9622 |
64 | 128 | 1062 | 116.74 | 238.94 | 0.9696 |
128 | 1 | 132.74 | 7.51 | 8.82 | 0.9585 |
128 | 16 | 884.77 | 17.99 | 29.91 | 0.9588 |
128 | 64 | 998.4 | 63.28 | 133.64 | 0.962 |
128 | 128 | 1063.91 | 116.85 | 244.43 | 0.9695 |
256 | 1 | 132.45 | 7.52 | 8.82 | 0.9585 |
256 | 16 | 881.95 | 18.05 | 30.16 | 0.9587 |
256 | 64 | 993.25 | 63.4 | 135.17 | 0.962 |
256 | 128 | 1067.68 | 116.09 | 227.54 | 0.9697 |
パフォーマンス結果の分析
同時実行数のスケーラビリティ:QPS 曲線を見ると、同時実行数が 1 から 64 に増加するにつれて、システムスループット (QPS) はほぼ線形に増加していることがわかります。これは、PolarDB ベクトルエンジンが優れた水平スケーラビリティを持つことを示しています。同時実行数が 64 を超えると、QPS の増加は鈍化し、同時実行数 128 でピークに達します。この時点で、システムリソース (おそらく CPU) が飽和状態に近くなり、パフォーマンスのボトルネックとなっています。
レイテンシーと同時実行数の関係:平均 (Avg) および P99 レイテンシーは、同時実行数が増加するにつれて大幅に増加します。この動作は、システム負荷が増加するにつれて予想されるものです。高い QPS が要求されるシナリオでは、P99 レイテンシーがビジネス要件を満たしていることを確認してください。
取得率のパフォーマンス:すべてのテスト条件下で、取得率は 95.8% 以上で安定しています。これは、HNSW インデックスが現在のパラメーターで高い検索精度を持つことを示しています。
本番環境への適用
テスト環境の構成をそのまま本番環境で使用するとリスクがあります。以下のセクションでは、主要パラメーターの構成に関する推奨事項と、本番環境でのリソース計画に関するガイダンスを提供します。
主要パラメーターの本番環境向け推奨設定
以下のパラメーターは、最大のテストパフォーマンスを達成するために設定されたものです。本番環境で使用する前に、慎重に評価してください。
"refresh_interval": "0s"テスト目的:自動更新を無効にするため。これにより、書き込みテスト中にデータがメモリと translog にのみ書き込まれるようになります。クエリテストの前に手動で
refreshを実行し、バックグラウンドタスクからの干渉なしにクエリパフォーマンスデータを取得します。本番環境での推奨事項:本番環境では、この値を
0sに設定しないでください。データの可視性要件に基づいて、適切な値を設定してください。たとえば、1sという値は、新しいデータが書き込まれてから約 1 秒後に検索可能になることを意味します。
"durability": "async"テスト目的:非同期 translog フラッシュを使用するため。データはメモリに書き込まれ、すぐに成功応答が返されます。その後、バックグラウンドスレッドがデータを非同期にディスクに永続化します。これにより、書き込みスループットが向上します。
本番環境での推奨事項:高いデータ信頼性が要求されるシナリオでは、この設定を慎重に使用してください。サーバー障害などの極端な状況では、
asyncモードではディスクに永続化されていない最後の数秒間のデータが失われる可能性があります。高いデータ信頼性要件がある場合は、本番環境でデフォルトのrequestモードを使用してください。このモードでは、データが translog に書き込まれ、ディスクに永続化された後にのみ成功応答が返されますが、書き込みパフォーマンスは低下します。
リソース使用率評価
ピーク負荷時のシステムのリソース消費を理解することは、正確な容量計画にとって不可欠です。
書き込み集中型のシナリオ:8,394 docs/sec のピーク書き込み時、システムの主なボトルネックは CPU (インデックス構築に使用) とディスク I/O (translog 書き込みに使用) です。
クエリ集中型のシナリオ:同時実行数 128、1,067 QPS のピーククエリ時、システムのボトルネックは主に CPU 使用率です。