ChatBI は、自然言語 to SQL (NL2SQL) 技術により、自然言語でデータをクエリし、ビジネス向けのレポートを生成するのを支援します。本トピックでは、「Alixiang」レストラン管理システムを例に、ChatBI の主要な機能を順に説明します。これにより、迅速に利用を開始し、サービスを効率的に利用できます。
PolarDB for AI 機能の有効化
AI ノードを追加し、データベースアカウントを設定して AI ノードに接続します。詳細については、「PolarDB for AI 機能の有効化」をご参照ください。
説明クラスターの購入時にすでに AI ノードを追加している場合は、AI ノードのデータベースアカウントを直接設定できます。詳細については、「標準アカウントの作成」をご参照ください。
このアカウントには、対象のデータテーブルに対する読み取りおよび書き込み権限が必要です。これにより、ChatBI の変換プロセスですべてのデータベース操作を実行できます。
[Cluster Endpoint]を使用して PolarDB クラスターに接続します。詳細については、「PolarDB for AI へのログオン」をご参照ください。
説明コマンドラインからクラスターに接続する場合は、
-cオプションを追加します。DMS は、デフォルトで [メインアドレス] を使用してクラスターに接続します。手動で [Cluster Endpoint] に変更する必要があります。変更後、元の SQL ウィンドウを閉じて新しいウィンドウを開き、SQL ステートメントを実行します。
データ準備
「Alixiang」は架空のレストラン会社です。その請求管理システムには、次の 3 つのテーブルが含まれています。クリックしてダウンロードできます。
テーブルスキーマに基づいて、テーブルと列にコメントを入力できます。これにより、大規模言語モデル (LLM) がデータをよりよく認識・理解できるようになり、データ処理と分析中のモデルの精度と効率が向上します。
CREATE TABLE restaurant_info (
id INT COMMENT '店舗 ID',
position VARCHAR(128) COMMENT '店舗の場所',
PRIMARY KEY (id)
) COMMENT='店舗テーブル';
CREATE TABLE menu_info (
id INT COMMENT 'メニュー項目 ID',
name VARCHAR(64) COMMENT 'メニュー項目名',
type INT COMMENT 'メニュー項目の種類',
unit_price INT COMMENT '単価',
PRIMARY KEY (id)
) COMMENT='メニューテーブル';
CREATE TABLE bill_info (
id INT COMMENT '請求 ID',
items VARCHAR(512) COMMENT '注文品目',
actural_amount INT COMMENT '実支払額',
restaurant_id INT COMMENT '店舗 ID',
waiter VARCHAR(16) COMMENT 'ウェイター',
diner_count INT COMMENT '食事客数',
pay_time DATE COMMENT '注文時間',
PRIMARY KEY (id)
) COMMENT='請求テーブル';ChatBI の使用
次に、PolarDB for AI の NL2SQL モデルを使用して、ユーザーの質問に対応する SQL ステートメントを生成できます。
テーブルスキーマインデックスの作成
次の SQL ステートメントを使用して、schema_index という名前のテーブルスキーマインデックスを作成し、大規模言語モデル (LLM) にテーブルスキーマ情報を提供します。
/*polar4ai*/CREATE TABLE schema_index(id integer, table_name varchar, table_comment text_ik_max_word, table_ddl text_ik_max_word, column_names text_ik_max_word, column_comments text_ik_max_word, sample_values text_ik_max_word, vecs vector_768,ext text_ik_max_word, PRIMARY key (id));このテーブルはデータベースに直接表示されません。次の SQL ステートメントを実行して、情報を表示できます。
/*polar4ai*/SHOW TABLES;次に、次の SQL ステートメントを使用して、データテーブルスキーマをインデックステーブル schema_index にインポートできます。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;PolarDB for AI は、ステートメントを実行すると、デフォルトで現在のデータベース内のすべてのテーブルをベクトル化し、列の値をサンプリングします。
ステートメントを実行すると、システムはバックグラウンドタスクの task_id ( bce632ea-97e9-11ee-bdd2-492f4dfe0918 など) を返します。次の SQL を使用して、現在のタスクのステータスをクエリできます。返された taskStatus が finish の場合、インデックスの構築は完了です。
/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;NL2SQL モデルを使用した質問への回答
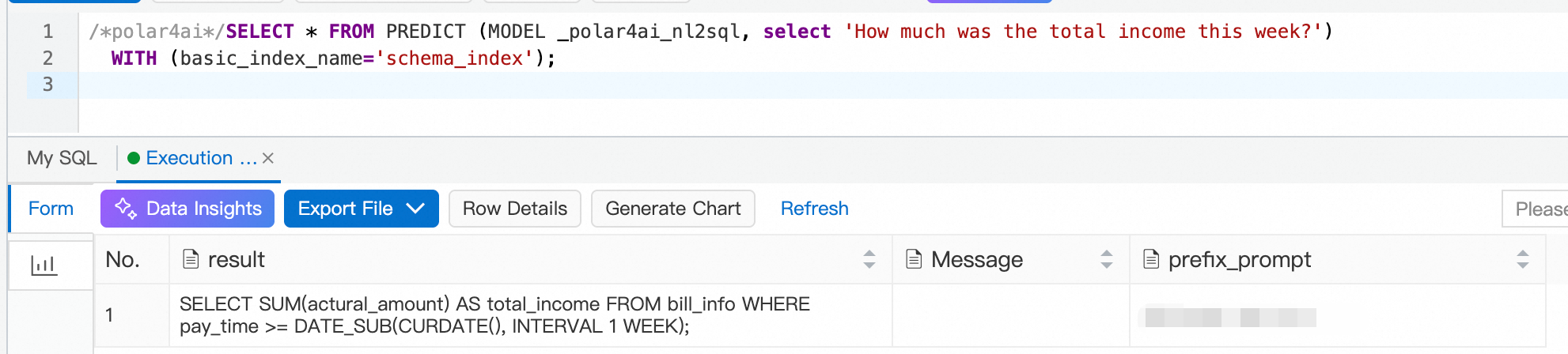
次の SQL ステートメントを実行して、LLM ベースの NL2SQL を使用できます。次の例では、ユーザーのクエリは 「今週の総収益はいくらですか?」で、使用されるテーブルスキーマインデックスは schema_index です。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'What is the total revenue for this week') WITH (basic_index_name='schema_index');LLM からの応答を受信するまで、しばらく待つ必要があります。期待される結果は次のとおりです。
上記の例に基づいて、いくつかの典型的な質問をすることもできます。これらの質問は、GROUP BY、複数テーブルの JOIN、ORDER BY、数式など、さまざまなシナリオをカバーしています。
No. | ユーザーの質問 | NL2SQL の戻り値 |
1 | 収益順に店舗を並べ替える |
|
2 | 上海で最も収益の高い店舗はどこですか? |
|
3 | 上海の一人当たりの平均支出はいくらですか? |
|
4 | どのウェイターが最も多くの注文を処理しましたか? |
|
5 | 今月の収益の前月比成長率は何パーセントですか? |
|
6 | 上海で最も顧客トラフィックが多い店舗はどこですか? |
|
ご覧のとおり、LLM ベースの NL2SQL モデルはユーザーの質問に効果的に回答できますが、一部の応答は期待どおりではありません。たとえば、2 番目の質問では、ユーザーは店舗名が返されることを期待しています。質問を 「上海で最も収益の高い店舗はどこですか?店舗名を返してください」と言い換えると、モデルは次の SQL ステートメントを返します:SELECT r.position FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position = 'Shanghai' ORDER BY b.actural_amount DESC LIMIT 1;。モデルをファインチューニングすることで、精度を向上させることもできます。次のセクションでは、これらの問題について説明します。
モデルのファインチューニング
質問テンプレートの設定
一般的な質問テンプレートを使用して、特定の知識を導入することでモデルをガイドできます。これにより、モデルはその知識に基づいて SQL ステートメントを生成できます。
次の SQL を実行して、質問テンプレートテーブル
polar4ai_nl2sql_patternを作成します。CREATE TABLE `polar4ai_nl2sql_pattern` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'プライマリキー', `pattern_question` text COMMENT 'テンプレートの質問', `pattern_description` text COMMENT 'テンプレートの説明', `pattern_sql` text COMMENT 'テンプレート SQL', `pattern_params` text COMMENT 'テンプレートパラメーター', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;テーブル名は
polar4ai_nl2sql_patternで始まる必要があり、テーブルスキーマには上記のCREATE TABLEステートメントの 5 つの列が含まれている必要があります。次に、質問テンプレートのインデックステーブル
pattern_indexを作成します。/*polar4ai*/CREATE TABLE pattern_index(id integer, pattern_question text_ik_max_word, pattern_description text_ik_max_word, pattern_sql text_ik_max_word, pattern_params text_ik_max_word, pattern_tables text_ik_max_word, vecs vector_768, PRIMARY key (id));2 番目の質問のテンプレートを設定し、ファインチューニングで店舗の住所を返すようにします。
次の SQL ステートメントを実行して、新しいパターンを追加します。
INSERT INTO polar4ai_nl2sql_pattern (id, pattern_question, pattern_description, pattern_sql, pattern_params) VALUES ( 1, "Which outlet in #{position} has the highest revenue?", "Which outlet in [location] has the highest revenue?", "SELECT r.position FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id WHERE r.position LIKE '%#{position}%' GROUP BY r.position ORDER BY SUM(b.actural_amount) DESC LIMIT 1;", '[{"table_name":"bill_info","param_info":[{"param_name":"#{position}","value":["Shanghai"]}], "explanation": "Location of consumption"}]' );このパターンでは、スロットを使用して複数の場所を照合します。
pattern_sql列に正しい SQL ステートメントを入力し、スロットを#{}でマークします。pattern_params列は、テーブル情報の追加の後処理に使用しますが、ここでは無視できます。次に、質問テンプレート情報をインデックステーブルにインポートします。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;schema_indexのインデックス構築プロセスと同様に、タスク ID も返されます。/*polar4ai*/show task 'xxx-xxx-xxx'を実行して、現在のタスクのステータスを表示できます。説明polar4ai_nl2sql_patternテーブルのデータが更新された場合は、pattern_indexを再作成し、データを再度インポートする必要があります。次の SQL ステートメントを使用して、古いインデックスを削除できます。/*polar4ai*/DROP TABLE pattern_index;問題が発生した SQL ステートメントを再実行し、
pattern_indexヒントを追加します。/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select 'Which outlet in Shanghai has the highest revenue?') WITH (basic_index_name='schema_index',pattern_index_name='pattern_index');
設定テーブルの構築
質問を前処理したり、最終的に生成された SQL を後処理したりする場合は、設定テーブルを使用できます。
語彙の意味に関するヒント
6 番目の質問では、大規模言語モデル (LLM) が「顧客トラフィック」という用語を正確に理解できないため、polar4ai_nl2sql_llm_config テーブルを設定して前処理を実行できます。
CREATE TABLE `polar4ai_nl2sql_llm_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'プライマリキー',
`is_functional` int(11) NOT NULL DEFAULT '1' COMMENT 'アクティブかどうか',
`text_condition` text COMMENT 'テキスト条件',
`query_function` text COMMENT 'クエリ処理',
`formula_function` text COMMENT '数式情報',
`sql_condition` text COMMENT 'SQL 条件',
`sql_function` text COMMENT 'SQL 処理',
PRIMARY KEY (`id`)
);関連する設定項目を挿入して、「顧客トラフィック」または「顧客フロー」を「食事客数」としてカウントするように LLM を設定します。
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
1,
1,
"customer traffic||customer flow",
"",
"Customer traffic or customer flow is calculated as the sum of the number of diners",
"",
""
);この場合、is_functional の値が 1 の場合は、設定項目が有効であることを示します。text_condition フィールドの値は「customer traffic||customer flow」で、「customer traffic」または「customer flow」を含む質問に一致します。formula_function フィールドは、テキストまたは数式を使用して専門用語を大規模言語モデル (LLM) に説明します。
この場合、インデックステーブルの構築やベクトル化を行わずに、直接 SQL 生成を実行できます。結果は次のとおりです。

あいまい検索のヒント
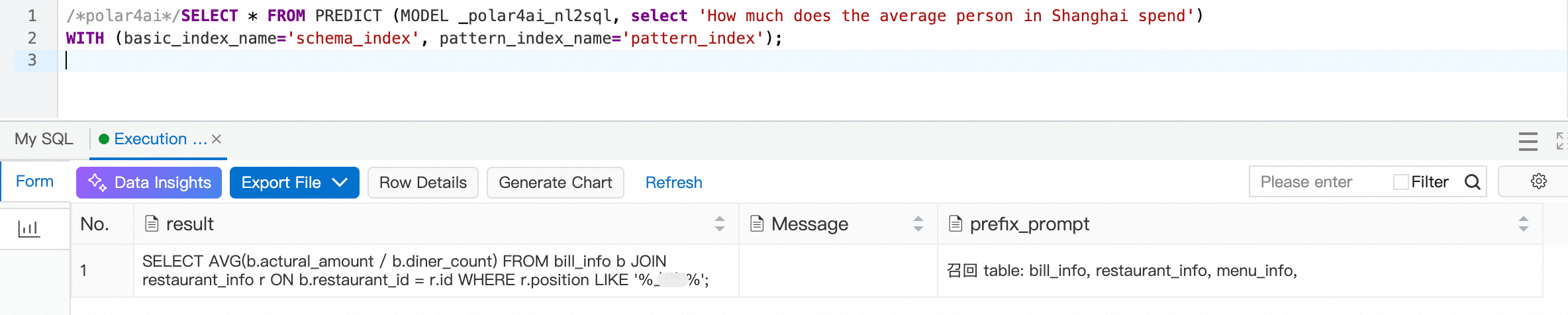
質問 3 では、= 演算子を使用して場所名を取得すると、名前が完全一致でない場合に失敗します。したがって、場所名の照合にはあいまい検索を使用する必要があります。
INSERT INTO polar4ai_nl2sql_llm_config (id, is_functional, text_condition, query_function, formula_function, sql_condition, sql_function) VALUES (
2,
1,
"",
"",
"Matching for the outlet location 'position' requires a fuzzy search",
"",
""
);text_condition が空の場合、設定項目は全体に適用されます (注意して使用してください)。
結果は下の図のとおりです。ご覧のとおり、場所の照合はあいまい検索を正常に使用しています。
同様に、質問 5 についても、polar4ai_nl2sql_llm_config 設定テーブルに前月比および前年比の計算式を追加して、生成される SQL の精度を向上させることができます。ご自身でお試しください。
チャート出力
NL2SQL で SQL ステートメントを生成した後、クエリ結果を取得し、棒グラフ、折れ線グラフ、円グラフなどのチャートで視覚的に表示できます。PolarDB の NL2Chart ソリューションは、質問に基づいて SQL ステートメントを実行し、対応するレポートを返すことができます。棒グラフ、円グラフ、折れ線グラフをサポートしています。
NL2SQL でのステートメントが次のようになっていると仮定します。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, select '店舗ごとの売上統計') WITH (basic_index_name='schema_index',pattern_index_name='pattern_index');対応する SQL ステートメントが生成されたら、そのステートメントが実行でき、意味のある空でない結果が返されることを確認してください。
SELECT r.position, SUM(b.actural_amount) AS total_sales FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id GROUP BY r.position;NL2Chart の使用:
構文
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, <SQL_statement>) WITH (usr_query = <usr_query>, result_type = <result_type>);パラメーター
パラメーター名
説明
サンプル値
usr_query
ユーザーが入力した質問で、チャート生成の要件を明確にするために使用します。
"四半期ごとの売上統計"
result_type
返される結果のタイプを指定します。現在、
'IMAGE'のみがサポートされています。'IMAGE'SQL ステートメント
NL2SQL モジュールによって生成された SQL クエリステートメント。データの取得に使用されます。
SELECT QUARTER(pay_time) as quarter, SUM(actural_amount) as sales FROM bill_info GROUP BY quarter ORDER BY quarter;例:生成された SQL ステートメントのクエリ結果をチャートに変換する
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT r.position, SUM(b.actural_amount) AS total_sales FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id GROUP BY r.position) WITH (usr_query = '店舗ごとの売上統計', result_type='IMAGE');結果は次のとおりです。
説明返されるリンクは、90 分間有効な画像 URL です。
http://db4ai-xxx-xx-xxxx-xxx-xxxx.aliyuncs.com/pc-bpze47ma2c515087l6/OSSAccessKeyId=xxxxxxx&Expires=1716130199&Signature=KvPFzfMebIEmqxPIXURurwwbsXM%3D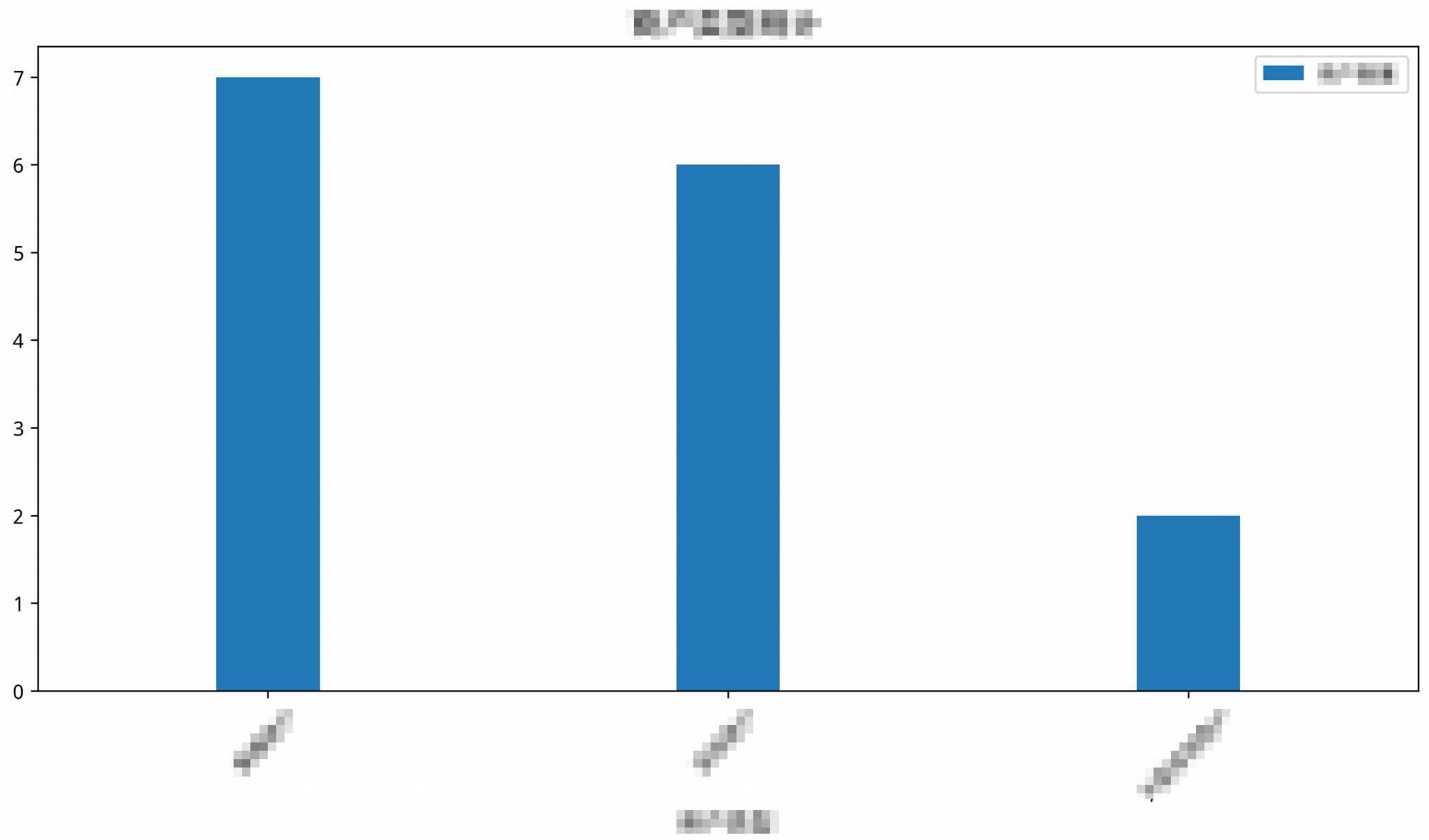
(オプション) チャートタイプの選択と強制選択
モデルは、ユーザーの質問とデータの理解に基づいて適切なチャートを選択します。ユーザーの質問を使用して、チャート生成のモデルをガイドすることを推奨します。
次の表は、質問タイプとチャートタイプのマッピングを示しています。
質問タイプ
チャートタイプ
ユーザーの質問の例
説明
数量統計
棒グラフ
「都市別の売上統計を提供してください」
数量、合計金額、頻度など、異なるカテゴリ間の数値比較を示します。
トレンドの変化
折れ線グラフ
「過去1年間のユーザー増加傾向を示してください」
時間経過または順序付けられたカテゴリにわたるデータの傾向を示し、連続性を強調します。
割合分布
円グラフ
「各製品ラインの売上比率を示してください」
全体に対する部分の割合関係を示すのに適しています。データはカテゴリ別で、明確な合計が必要です。
usr_queryパラメーターを変更して、特定のチャートタイプを強制します。usr_queryパラメーターの末尾に補足コマンドを追加します。-- 出力 SQL を nl2chart に入力して折れ線グラフを描画します /*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT r.position, SUM(b.actural_amount) AS total_sales FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id GROUP BY r.position ) WITH (usr_query = '店舗ごとの売上統計、折れ線グラフで描画', result_type='IMAGE');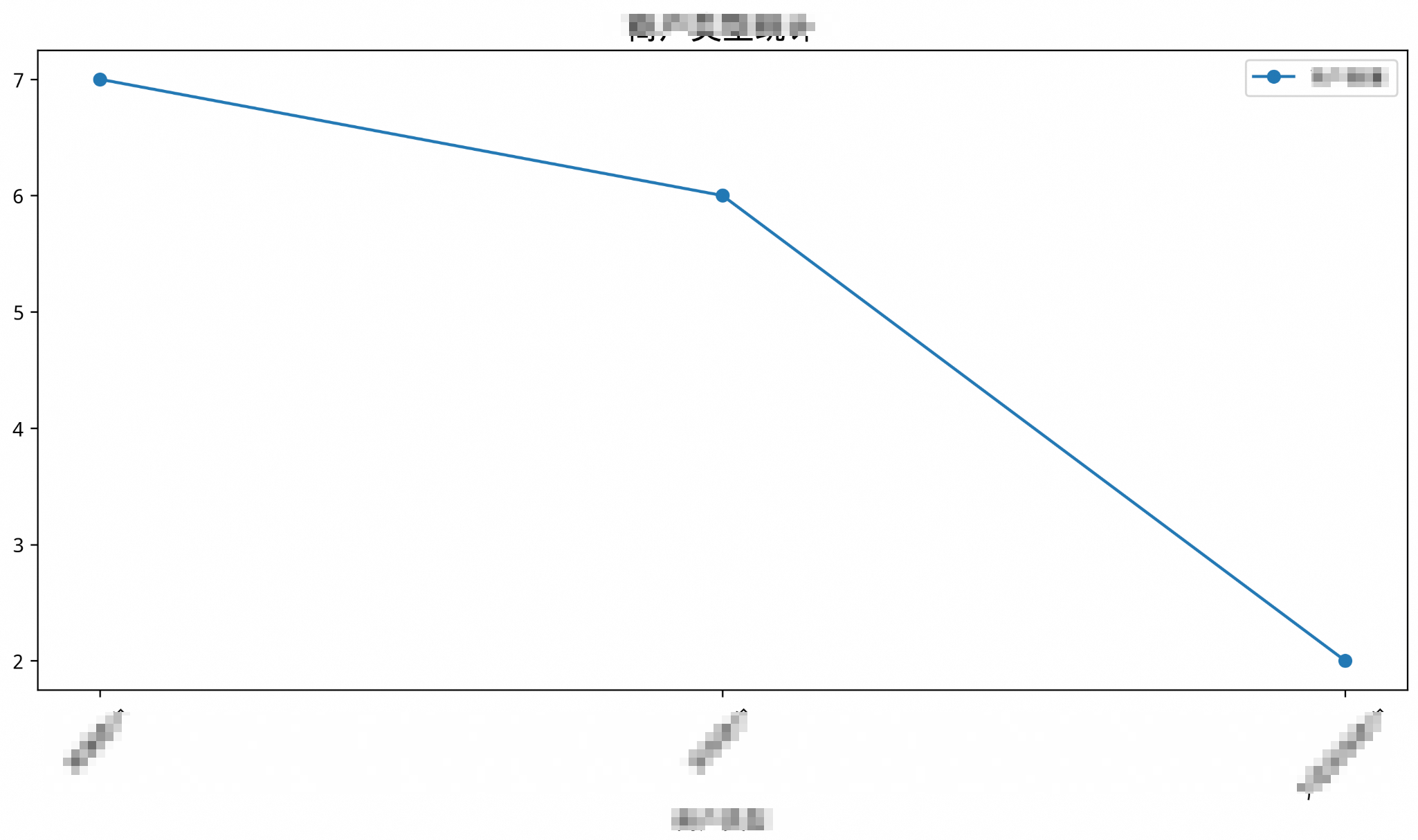
-- 出力 SQL を nl2chart に入力して円グラフを描画します /*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2chart, SELECT r.position, SUM(b.actural_amount) AS total_sales FROM bill_info b JOIN restaurant_info r ON b.restaurant_id = r.id GROUP BY r.position ) WITH (usr_query = '店舗ごとの売上統計、円グラフで描画', result_type='IMAGE');
詳細については、「NL2Chart: 自然言語からスマートチャートを生成する」をご参照ください。
モデルの再トレーニングとファインチューニング
モデルがビジネスニーズを満たさない場合は、モデルを再トレーニングし、内部パラメーターをファインチューニングして、より良い結果を得ることができます。
前提条件
この機能は、polar.mysql.x8.2xlarge.gpu 仕様 (16 コア、125 GB、GU100 x 1) の AI ノードを持つクラスターでのみ利用できます。
一度にトレーニングできるモデルは 1 つだけです。
一度にデプロイできるモデルは 1 つだけです。
手順
モデルのトレーニング
/*polar4ai*/CREATE MODEL udf_qwen14b WITH (model_class='qwen-turbo', model_parameter=(basic_index_name='schema_index', pattern_index_name='pattern_index',training_type='efficient_sft')) as (SELECT '')パラメーター
パラメーター名 | 説明 | デフォルト | 有効な値/範囲 |
model_class | モデルタイプ。現在、{'qwen-14b-chat', 'qwen-turbo'} をサポートしています。 | なし | {'qwen-14b-chat', 'qwen-turbo'} |
model_parameter | 必須およびオプションのパラメーターを含む、モデルパラメーターの設定。 | なし | なし |
basic_index_name | トレーニングデータのデータベース情報の取得元となるインデックステーブルの名前。これはデータベースのインデックステーブルである必要があります。 | なし | なし |
pattern_index_name | トレーニングデータの質問テンプレート情報の取得元となるインデックステーブルの名前。これは質問テンプレートのインデックステーブルである必要があります。 | なし | なし |
training_type | トレーニングタイプ。有効な値は {'efficient_sft', 'sft'} です。「efficient_sft」は効率的なトレーニングを示し、通常は LoRa メソッドを使用します。「sft」はフルパラメーターのトレーニングを示します。 | なし | {'efficient_sft', 'sft'} |
n_epochs | エポック数。トレーニング中にモデルがデータセットから学習する回数。推奨範囲は 1 から 3 で、必要に応じて調整できます。 | 3 | [1, 200] |
learning_rate | 学習率。データ更新ごとの増分パラメーターの重みを表します。学習率が大きいほど、パラメーターの変更が大きくなり、モデルへの影響が大きくなります。 | '3e-4' | なし |
batch_size | バッチサイズ。モデルパラメーター更新のデータステップサイズを表します。推奨されるバッチサイズは 16 または 32 です。 | 16 | {8, 16, 32} |
lr_scheduler_type | 学習率ポリシー。トレーニング中に重みを更新するときに使用される学習率を動的に変更します。 | 'linear' | {'linear', 'cosine', 'cosine_with_restarts', 'polynomial', 'constant', 'constant_with_warmup', 'inverse_sqrt', 'reduce_lr_on_plateau'} |
eval_steps | モデル検証の間隔ステップサイズ。トレーニングの精度と損失の定期的な評価に使用されます。 | 50 | [1, 2147483647] |
sequence_length | トレーニングデータのシーケンス長。1 つのサンプルの最大長。この長さを超えるデータは自動的に切り捨てられます。 | 2048 | [500, 2048] |
lr_warmup_ratio | ウォームアップに使用される総トレーニングステップの割合。 | 0.05 | (0, 1) |
weight_decay | L2 正則化。過学習の軽減に役立ちます。 | 0.01 | (0, 0.2) |
gradient_checkpointing | 勾配チェックポインティングを有効または無効にして GPU メモリを節約します。 | 'True' | {'True', 'False'} |
use_flash_attn | Flash Attention を使用するかどうかを指定します。 | 'True' | {'True', 'False'} |
lora_rank | LoRa トレーニングのランクサイズ。トレーニングデータがモデルに与える影響の度合いに影響します。 | 8 | {2, 4, 8, 16, 32, 64} |
lora_alpha | LoRa トレーニングのスケーリング係数。初期のトレーニングの重みを調整するために使用されます。 | 32 | {8, 16, 32, 64} |
lora_dropout | トレーニング中にランダムにドロップされるニューロンの比率。これにより、過学習が防止され、モデルの汎化能力が向上します。 | 0.1 | (0, 0.2) |
lora_target_modules | モデルの特定のモジュールを選択して、ファインチューニングと最適化を行います。 | 'ALL' | {'ALL', 'AUTO'} |
モデルの表示
/*polar4ai*/SHOW model udf_qwen14bモデルの削除
/*polar4ai*/DROP model udf_qwen14bすべてのモデルの表示
/*polar4ai*/SHOW modelsモデルのデプロイ
トレーニング済みのモデルは、デプロイして初めて NL2SQL で使用できるようになります。
/*polar4ai*/deploy model udf_qwen14bデプロイの表示
/*polar4ai*/SHOW deployment udf_qwen14bデプロイの削除
/*polar4ai*/DROP deployment udf_qwen14bすべてのデプロイの表示
/*polar4ai*/SHOW deploymentsデプロイ済みモデルを使用した NL2SQL
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT 'What is the content for id=1?') WITH (basic_index_name='schema_index', llm_model='udf_qwen14b')パラメーター
パラメーター | 説明 |
basic_index_name | 空にすることはできません。現在の質問に関連するデータベース情報のインデックステーブルを指定する必要があります。 |
llm_model | オプション。この項目を空のままにすると、ファインチューニングされていないモデルが自然言語から SQL への変換に使用されます。値を指定する場合は、サービング状態のデプロイの名前であることを確認してください。完全にデプロイされていないモデルはここでは使用できません。 |