このトピックでは、PAI-RAG Web UI での設定の構成方法について説明します。これらの設定には、ナレッジベース、Code sandbox、モデル、検索サービス、MCP ツールが含まれます。
モデルの構成
左下隅で、[設定] > [モデル] をクリックしてモデル構成ページに移動します。LLM タブで、モデルを追加します。
オールインワンデプロイメントを使用する場合、モデル構成レコードは自動的に生成されます。他のソースからモデルを追加することもできます。
モデル ID: 異なるモデル構成を区別します。
エンドポイント URL: モデルのサービスエンドポイント。
説明Alibaba Cloud Model Studio モデルへの呼び出しは別途課金されます。詳細については、「Alibaba Cloud Model Studio の課金」をご参照ください。
このサービスが EAS モデルサービスである場合、サービスの詳細ページで Basic Information をクリックし、次に View Endpoint Information をクリックします。注意: エンドポイント URL に
/v1を追加します。インターネットエンドポイントを使用するには、RAG サービス用に パブリックネットワークアクセスを備えた VPC を構成する必要があります。
VPC エンドポイントを使用するには、RAG サービスと LLM サービスが同じ VPC 内にある必要があります。
API キー: Alibaba Cloud Model Studio の場合、API キーを取得します。詳細については、「API キーの取得」をご参照ください。EAS サービスの場合、エンドポイント情報からトークンを入力します。
モデル名: モデルの名前を入力します。EAS に vLLM 推論エンジンでデプロイされた LLM サービスを使用する場合、特定のモデル名を入力する必要があります。
/v1/modelsAPI を使用してモデル名を取得できます。他のデプロイメントモードの場合、モデル名をdefaultに設定するだけです。マルチモーダルモデル: モデルがマルチモーダルである場合は、このオプションを選択します。このオプションはデフォルトでは選択されていません。
思考モデル: 思考モードと非思考モードの両方をサポートするモデルの場合、このオプションを使用してモデルが思考操作を実行するかどうかを制御します。このオプションはデフォルトでは選択されていません。
構成が成功した後、モデル構成をテストします。左側のナビゲーションウィンドウで、[新しいチャット] をクリックします。チャットページで、上部でモデルを選択してテスト会話を開始します。
MCP の構成
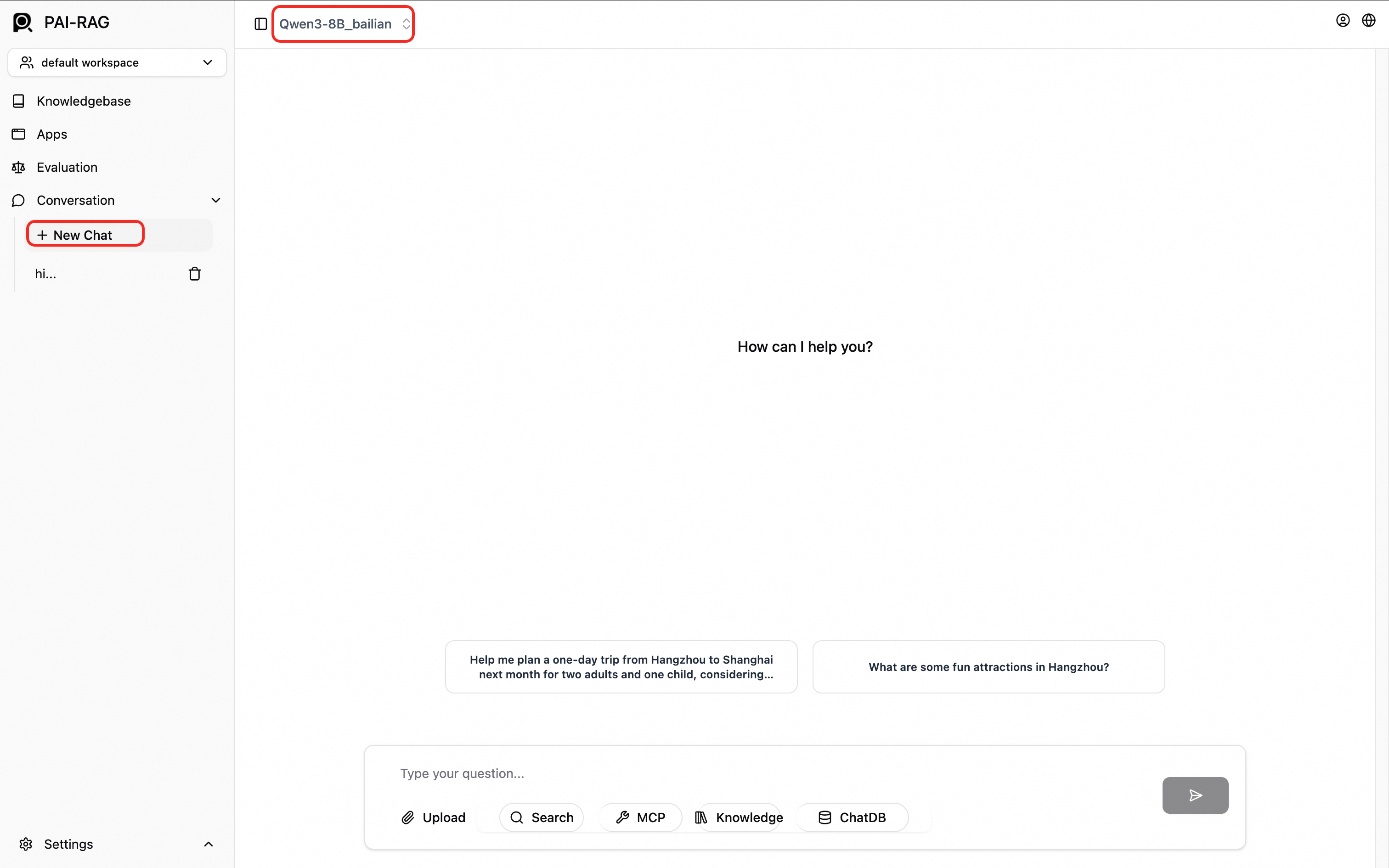
左下隅で、[設定] > [MCP] をクリックして MCP を追加します。
MCP リンク: MCP サービスの完全なエンドポイント URL。
MCP タイプ: サポートされているタイプは SSE、STDIO、および Streamable HTTP です。
ベアラートークン: (オプション) ベアラートークン認証の場合、有効なアクセストークンを入力します。
検索の構成
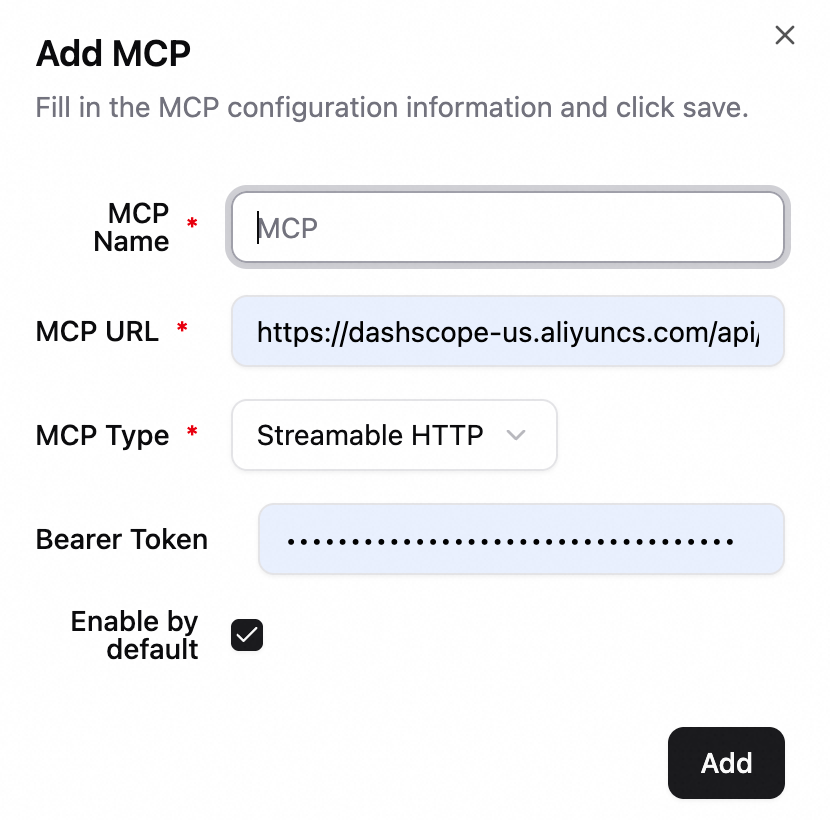
ナレッジベースのコンテンツがユーザーの質問をカバーしていない場合、またはリアルタイム情報が必要な場合、補足として検索サービス (Tavily ) を有効にできます。
左下隅で、[設定] > [検索] をクリックして検索構成ページに移動します。
Tavily 検索
Tavily 公式ウェブサイトにアクセスしてアカウントを登録し、API キーを取得します。
Code sandbox の構成
Code sandbox は、安全な Python コード実行環境を提供します。Code sandbox 機能を有効にした後、AI アシスタントはコードを実行する必要があるときに Code sandbox ツールを自動的に呼び出します。
シナリオ
データ分析: データ統計、集約、フィルタリングなどの操作を実行します。例: 「売上データを分析し、各リージョンの平均売上を計算します。」
データ可視化: チャートを生成し、トレンドグラフをプロットします。例: 「過去1年間の売上トレンドグラフをプロットします。」
数学演算: 複雑な数学演算を実行し、方程式を解きます。例: 「このシーケンスの標準偏差を計算します。」
ファイル処理: CSV や Excel ファイルなどのファイルを解析してデータを抽出し、変換します。
コード実行を必要とするその他のタスク
前提条件
Code sandbox を構成する前に、次の準備を完了します。
Function Compute をアクティブ化: Function Compute コンソールにアクセスし、プロンプトに従ってサービスをアクティブ化します。
AgentRun インタープリターを作成: AgentRun コンソールにアクセスします。左側のナビゲーションウィンドウで、[サンドボックス] を選択します。サンドボックステンプレートを作成し、タイプを Code Interpreter に設定します。注:
説明ネットワークタイプの場合、デフォルトオプションは [デフォルト NIC がパブリックネットワークにアクセスすることを許可] です。これは、RAG サービスがパブリックネットワークアクセスを持つことを必要とします。
[VPC へのアクセスを許可] を選択し、RAG サービスに同じ VPC が構成されていることを確認できます。
アクセス認証情報を取得: 構成のために Alibaba Cloud アカウント ID と サンドボックス ID を取得します。アクセス認証情報を設定している場合、API キーも必要です。
構成
左下隅で、[設定] > [Code Sandbox] をクリックし、次のパラメーターを構成します。
サンドボックスを有効にする: サンドボックス機能を有効または無効にします。
サンドボックスタイプ: 現在、Alibaba Cloud FC サンドボックスのみがサポートされています。
Alibaba Cloud ID: ご利用の Alibaba Cloud アカウント ID。
インタープリター ID: サンドボックス ID。
インタープリター名: コードインタープリターの名前。
API キー: 本人確認に使用される AccessKey ペア。
デフォルトタイムアウト (秒): コード実行の最大期間 (秒単位)。デフォルト値は 50 です。
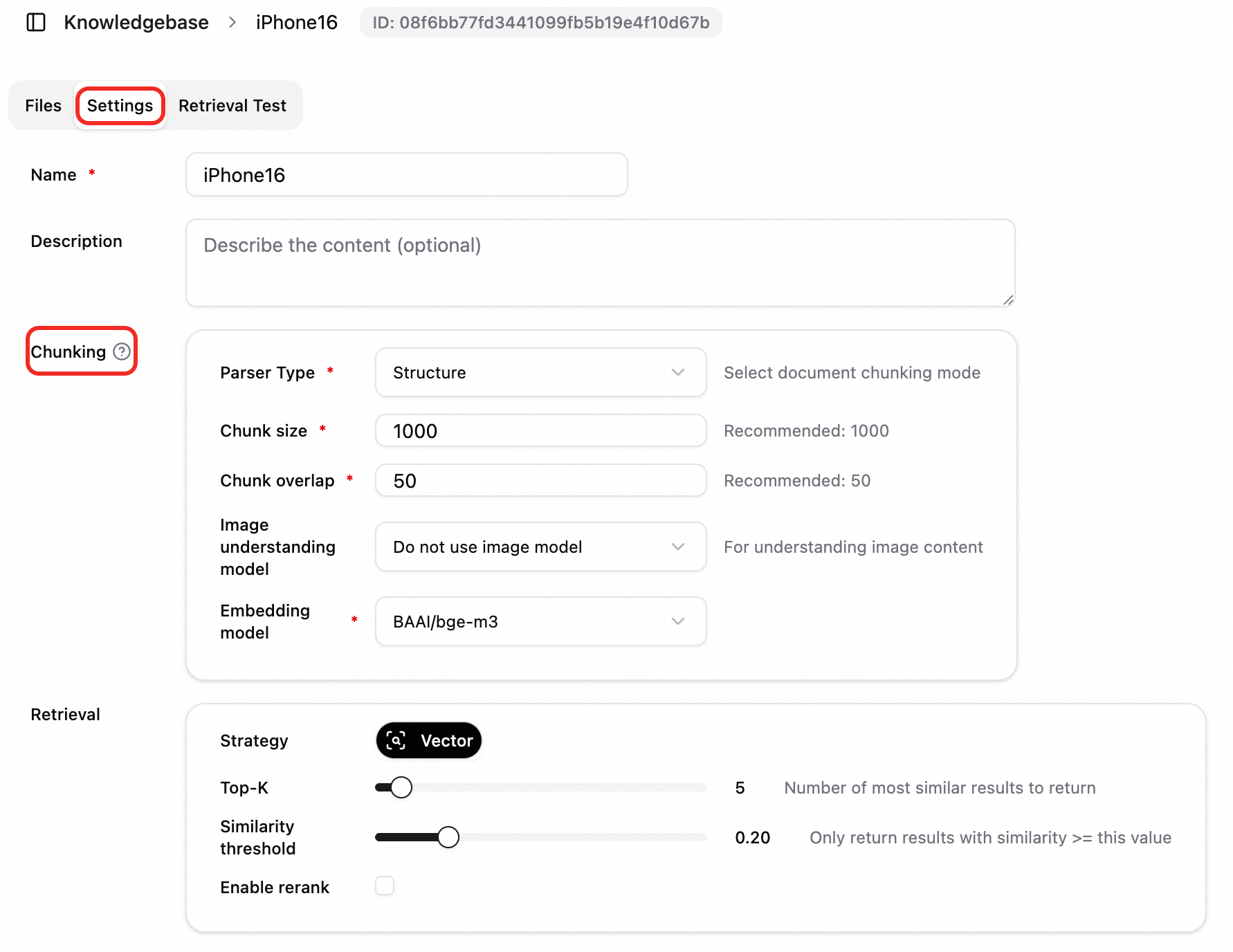
ファイルチャンクポリシーの構成
チャンク設定は、ナレッジベース内のドキュメントのチャンクメソッドを構成するために使用されます。これは、ドキュメントがその後のベクトル化と取得のためにチャンクに分割される方法を決定します。適切なチャンク設定は、取得ヒット率と回答の品質を向上させることができます。
構成はナレッジベースレベルとファイルレベルでサポートされています。
ナレッジベースのチャンク設定: ファイルをナレッジベースにアップロードするとき、ナレッジベースのチャンク設定がデフォルトでファイル解析に使用されます。
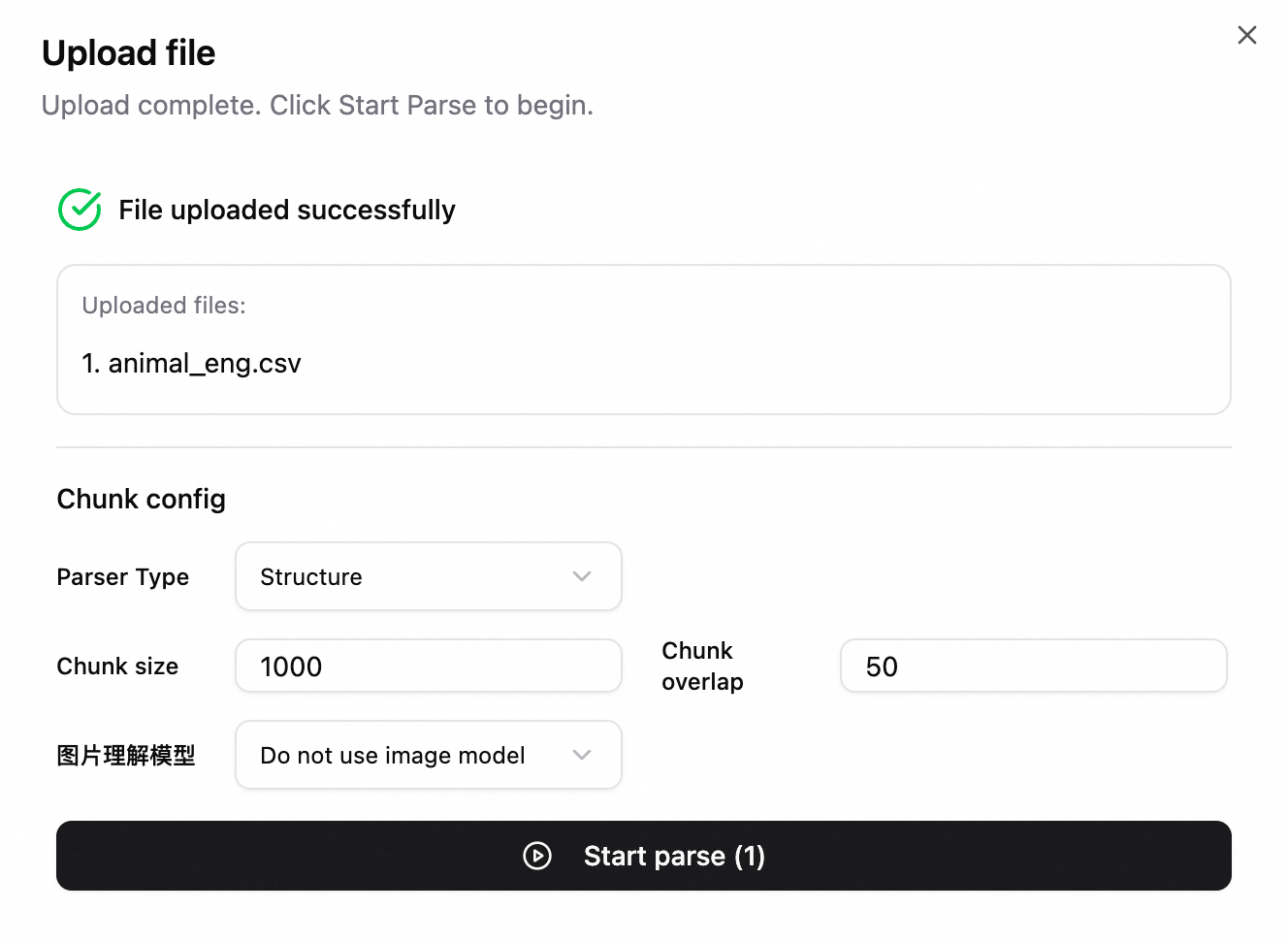
ファイルのチャンク設定を指定:
ファイルをアップロードするとき、そのファイルのチャンクパラメーターを指定できます。
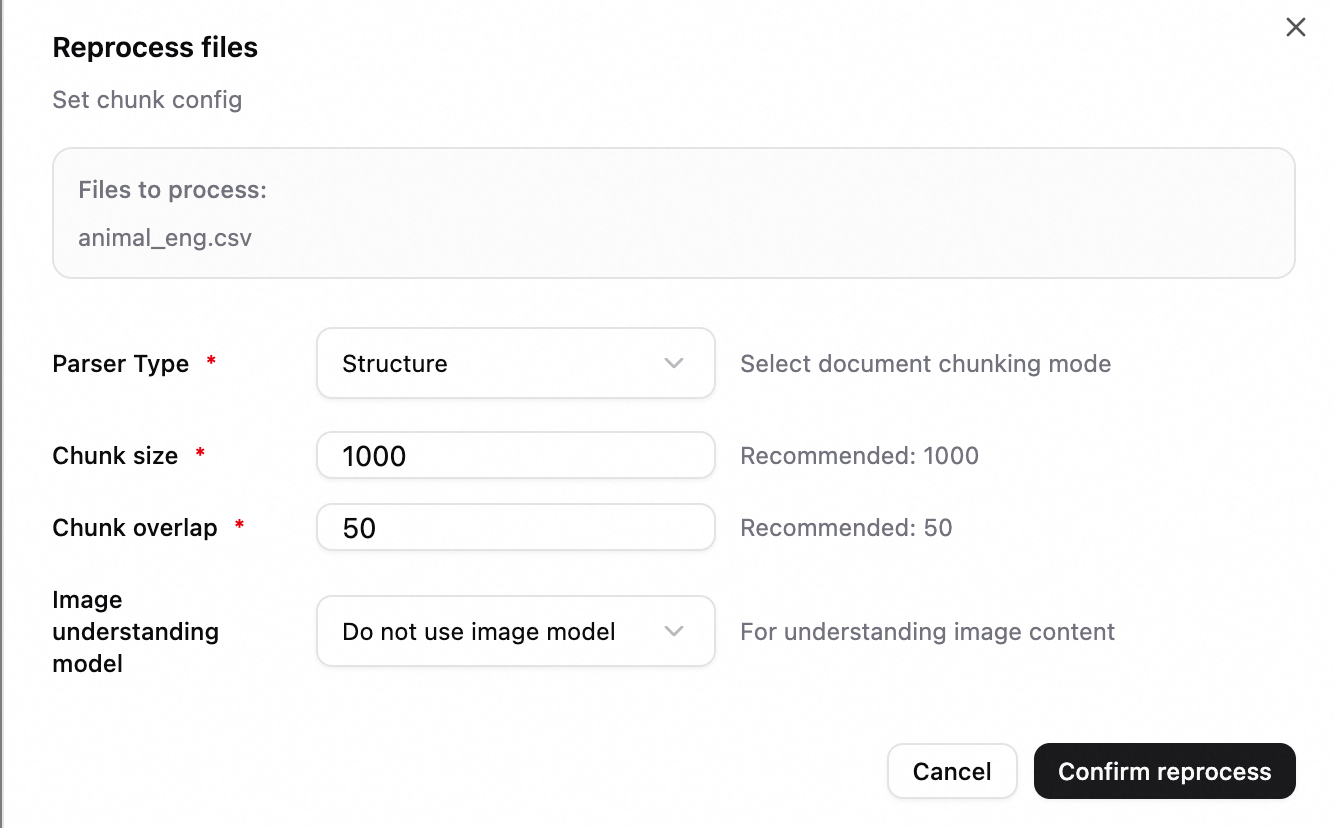
既存のファイルを再解析するとき、再処理をトリガーするためにチャンク設定を指定することもできます。
前提条件
チャンク設定を使用する前に、次のものが必要です。
ナレッジベース: システムにアクティブなナレッジベースがあります。
埋め込み構成: 少なくとも1つの埋め込みモデルがシステムに追加されています。
(オプション) マルチモーダルモデル: 画像理解モデルを使用するには、システムにビジョンモデルを構成する必要があります。
パラメーターの説明
パラメーター | 説明 |
チャンクタイプ | ドキュメントの特性に基づいてチャンクタイプを選択します。
|
チャンクサイズ | 各チャンクの最大長 (文字またはトークン単位)。チャンクタイプによって異なります。推奨値: 1000。 |
チャンク重複 | 隣接するチャンク間の重複の長さ。これにより、コンテキストを保持し、意味的な切り捨てを防ぐことができます。推奨値: 50。 重要 チャンクサイズはチャンク重複よりも大きくする必要があります。 |
画像理解モデル |
|
ベクターモデル |
|
チューニングの提案: まず、テストのためにデフォルト構成を使用していくつかのドキュメントをアップロードすることをお勧めします。評価モジュールで再現率と精度を分析し、結果に基づいてパラメーターを調整します。
使用の提案
長いドキュメントの RAG: チャンクタイプを構造化に、チャンクサイズを 1000 に、チャンク重複を 50 に設定します。これにより、コンテキストを保持しながらチャンク長を制御できます。
区切り文字による厳密なドキュメントチャンク化: 段落チャンクメソッドを使用し、カスタム区切り文字を指定します。
表形式データ: チャンクタイプをテーブルに設定します。テーブルヘッダー行と行区切り文字を構成して、Excel または CSV ファイルから行またはブロックごとにデータを取得します。[行のマージ] オプションを選択しない場合、データは行ごとにチャンク化されます。[行のマージ] オプションを選択した場合、行はチャンクサイズ制限に基づいてブロックにマージされます。
マルチモーダルドキュメント: 画像理解モデルを有効にして、PDF 内の画像や画像を含むドキュメントのコンテンツを、取得と回答生成に含めます。
アプリケーション FAQ の構成
FAQ 機能を使用すると、各アプリケーションの質問と回答のナレッジベースを維持できます。これは、製品マニュアル、カスタマーサービススクリプト、およびよくある質問に役立ちます。
アプリケーションの FAQ 機能を有効にしてエントリを構成した後、会話フローは次のようになります。
AI アシスタントはまず、ユーザーの質問に最も類似している FAQ からエントリを取得します。
一致が見つかり、類似度スコアのしきい値が満たされた場合、構成に応じて、システムはFAQ の回答を直接返すか、FAQ の結果に基づいてモデルで回答を生成します。
一致が見つからないか、直接返却オプションが有効になっていない場合、システムはナレッジベースや検索などの他の機能を使用して質問に回答します。
構成:
システムにログインし、ターゲットアプリケーションの構成ページに移動します。
FAQ を有効にする: アプリケーション構成で、[FAQ を有効にする] スイッチをオンにし、設定を保存します。
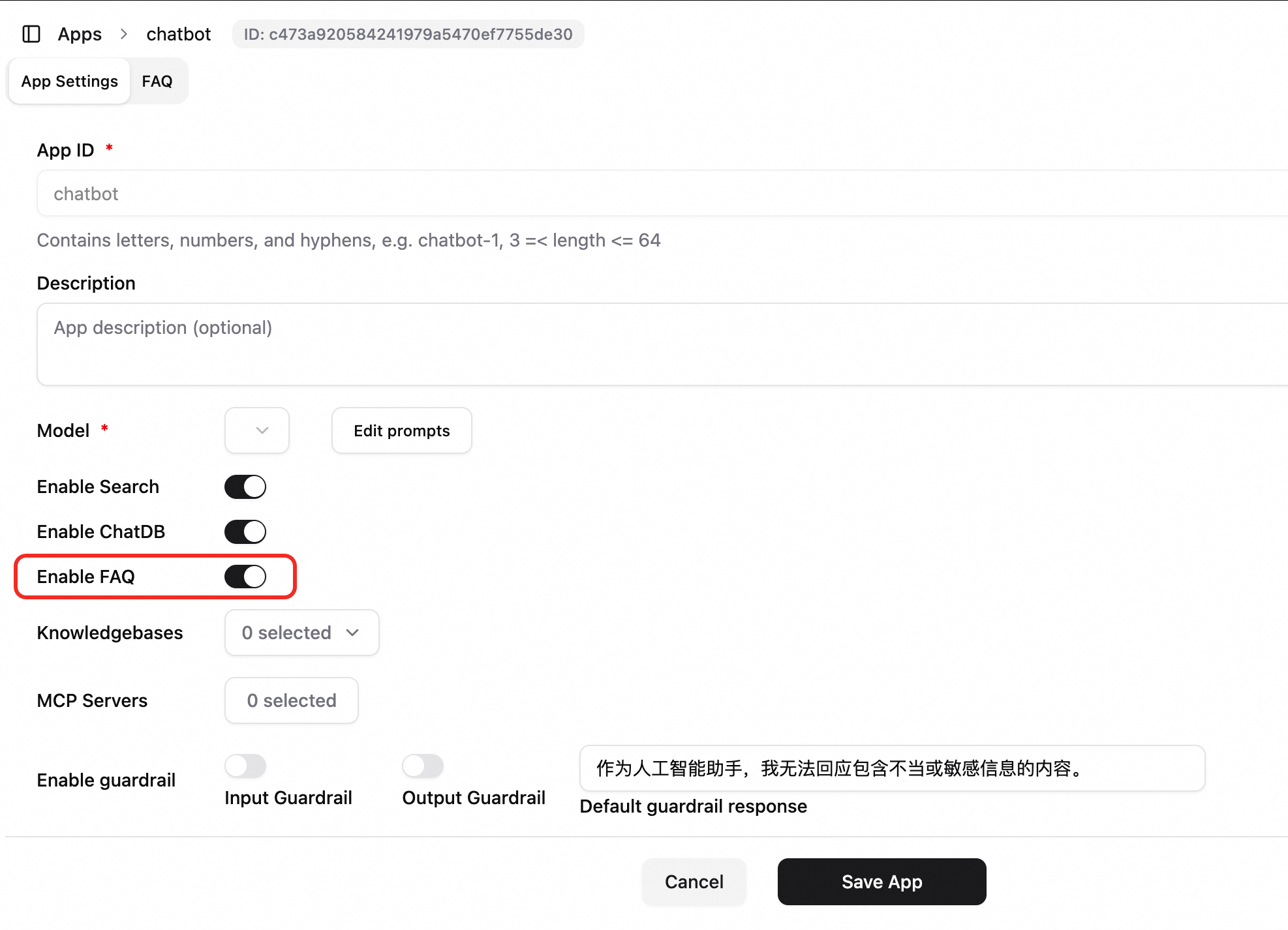
FAQ 管理ページを開きます。このページで、次の操作を実行できます。
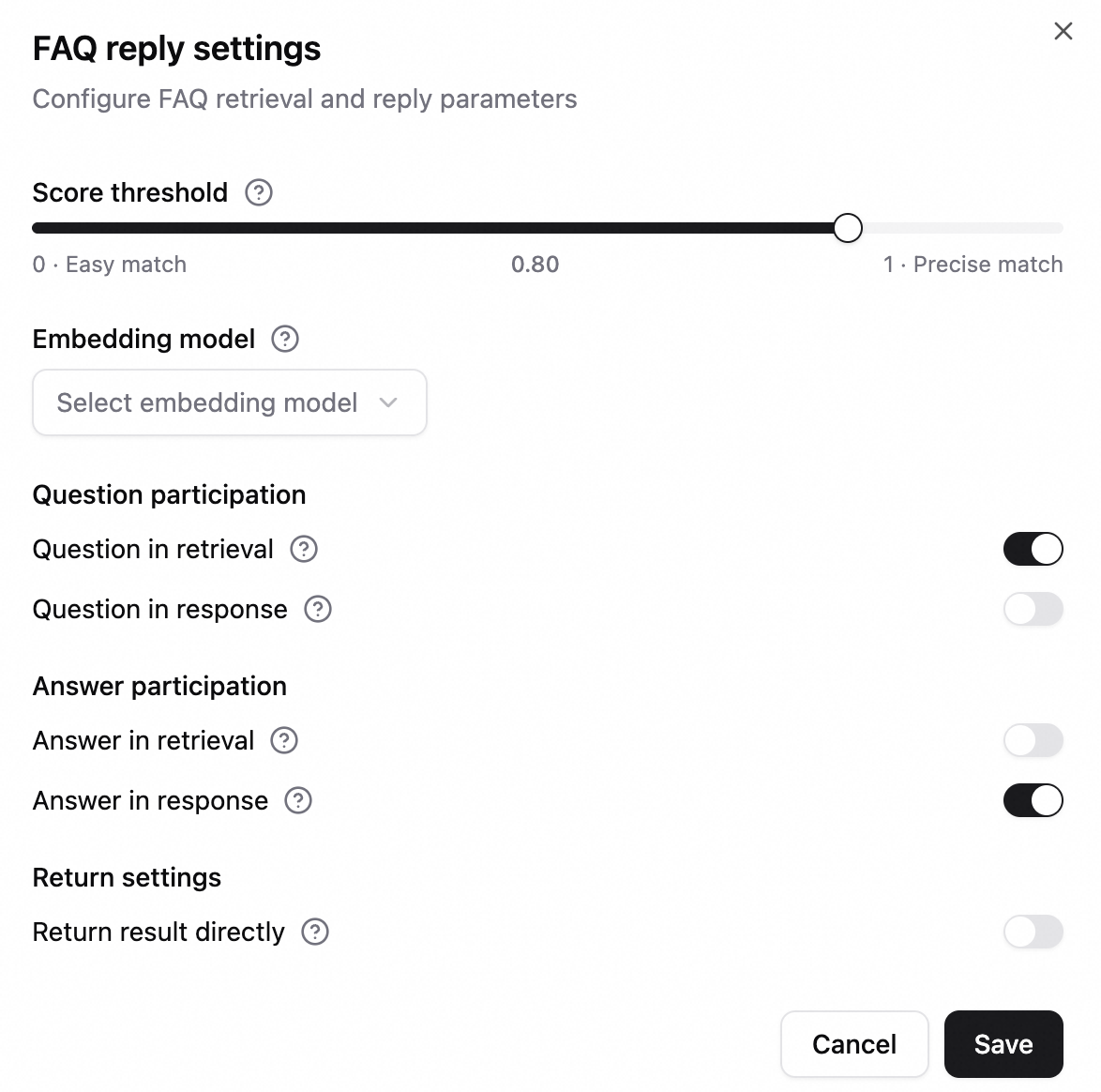
FAQ 返信設定: [設定] ボタンをクリックします。類似度スコアのしきい値 (0.8 から 1.0 の値が推奨されます)、埋め込みモデル、取得と表示に質問または回答を含めるかどうか、およびツール結果を直接返すかどうかを構成します。
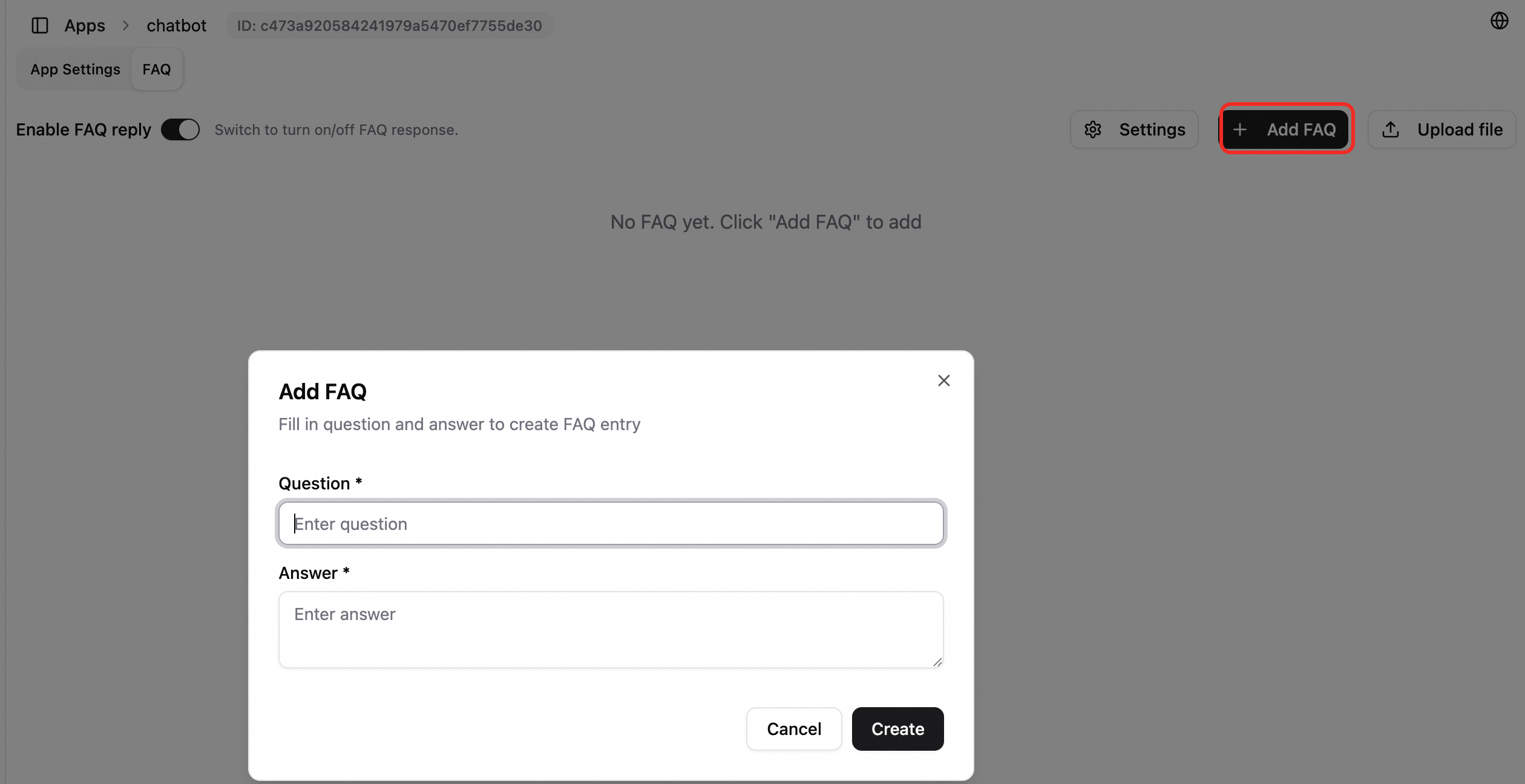
FAQ の管理:
単一の FAQ エントリを追加、編集、または削除します。
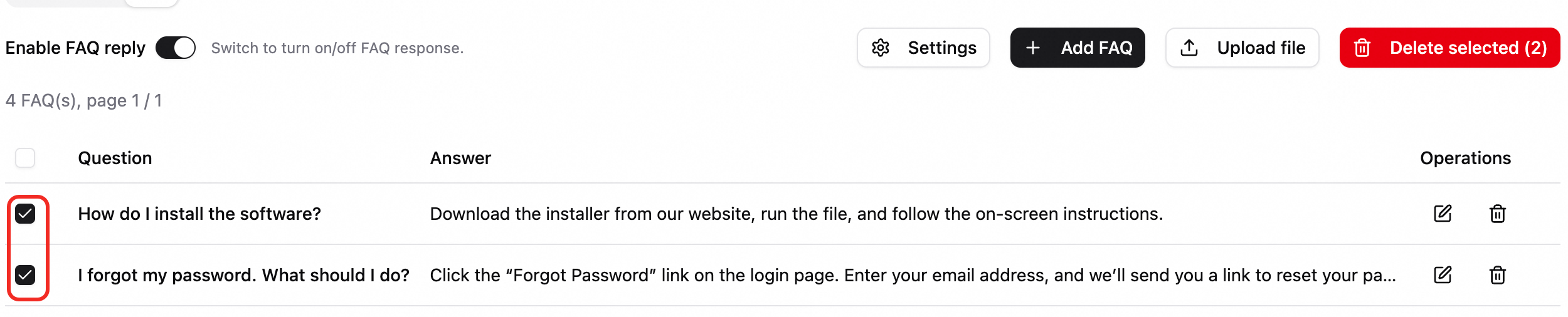
エントリを一括削除します。
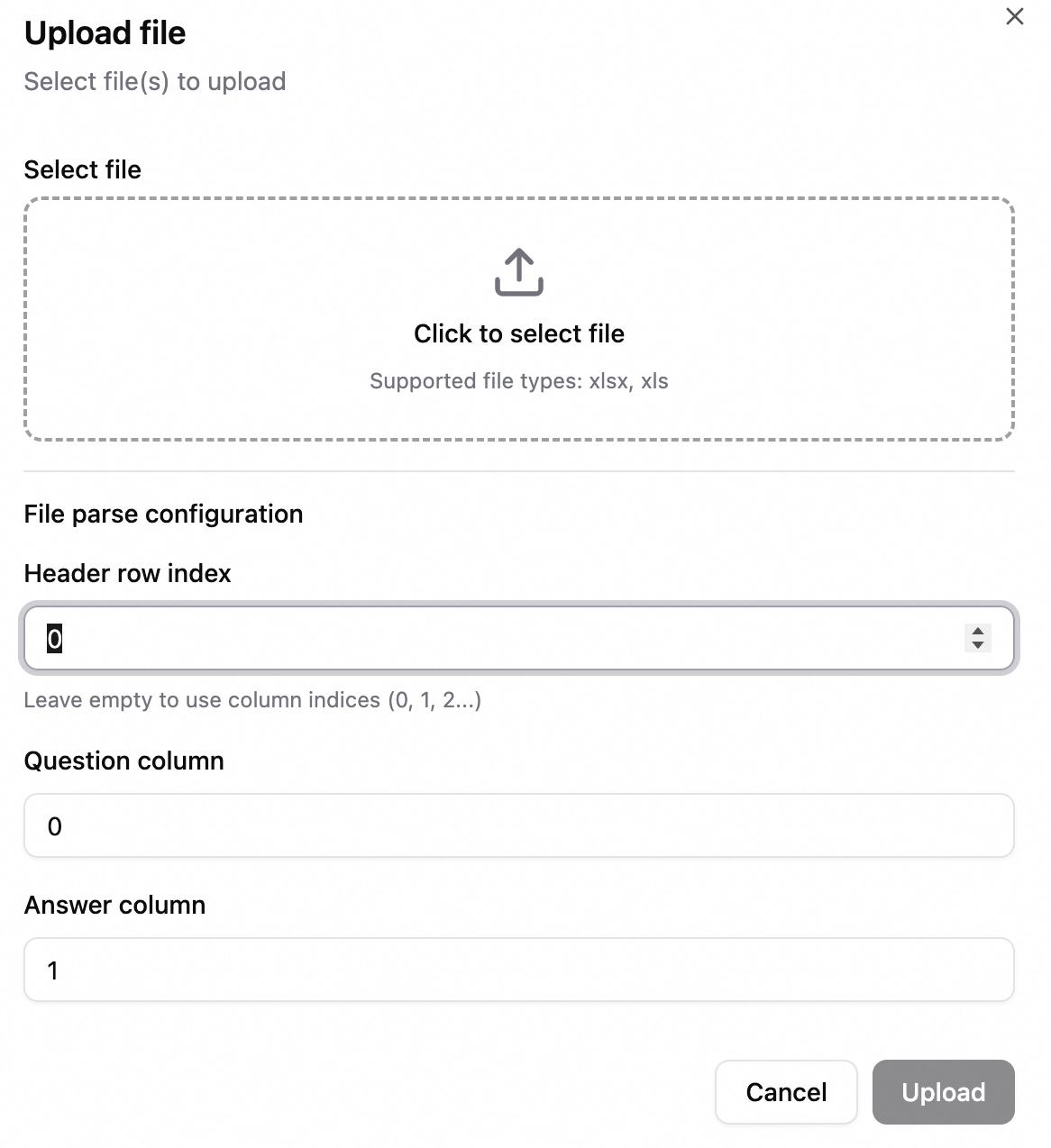
一括インポート: Excel ファイルをアップロードし、質問と回答の列をマップして、エントリをインポートします。
設定を保存した後、このアプリケーションでの会話は FAQ 取得結果を自動的に優先します。