頂点クラスタリング係数は、ノードの隣接ノード間のクラスタリングの程度を定量化するために使用されるネットワーク分析のメトリックです。 具体的には、ノードの隣接ノード間に存在するエッジの実際の数と、それらの間に存在し得るエッジの可能な総数との比を表す。 この係数の値は0〜1の範囲であり、値が高いほど、ノードの隣接ノード間の接続が密であることを示し、ネットワーク内の局所的なクラスタリング特性を反映します。
アルゴリズムの説明
無向グラフでは、ノードのクラスタリング係数は、そのノードの周りの接続の密度を表します。 スターネットワークの密度は0であり、完全に接続されたネットワークの密度は1です。
ネットワーク分析では、スターネットワークと完全接続ネットワークは2つの典型的なネットワークトポロジです。
スターネットワーク: この構造は、中央ノードと複数の周辺ノードで構成され、すべての周辺ノードは中央ノードにのみ接続されています。 スター型ネットワークの特徴は、その隣接ノード (周辺ノード) が互いに直接接続していないため、中央ノードのクラスタリング係数が0であることである。
完全接続ネットワーク: この構造では、すべてのノードが他のすべてのノードに直接接続されます。 完全に接続されたネットワークの特徴は、すべての可能な接続が各ノードとその隣接ノードとの間に存在するため、すべてのノードがクラスタリング係数1を有することである。
これらの2つの構造は、ネットワークトポロジの極端なケースを表し、スターネットワークは最低のローカルクラスタリングを有し、完全接続ネットワークは最高のローカルクラスタリングを有します。
コンポーネントの設定
方法1: パイプラインページでコンポーネントを設定する
パイプラインページでVertex Clustering Coefficientコンポーネントを追加し、次のパラメーターを設定します。
カテゴリ | パラメーター | 説明 |
フィールド設定 | Vertexを開始 | エッジテーブルの開始頂点列。 |
エンド頂点 | エッジテーブルの末尾の頂点列。 | |
パラメーター設定 | 最大頂点度 | 頂点次数がこのパラメーターの値より大きい場合、サンプリングが必要です。 デフォルト値: 500。 |
チューニング | 労働者 | 並列ジョブ実行の頂点の数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
Workerあたりのメモリサイズ (MB) | 1つのジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用済みメモリのサイズがこのパラメーターの値を超えると、 | |
データ分割サイズ (MB) | データ分割サイズ。 単位:MB。 デフォルト値: 64。 |
方法2: PAIコマンドを使用してコンポーネントを構成する
Vertex Clustering Coefficientコンポーネントは、PAIコマンドを使用して設定できます。 SQLスクリプトコンポーネントを使用してPAIコマンドを実行できます。 詳細については、「SQLスクリプト」トピックの「シナリオ4: SQLスクリプトコンポーネント内でPAIコマンドを実行する」をご参照ください。
PAI -name NodeDensity
-project algo_public
-DinputEdgeTableName=NodeDensity_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DoutputTableName=NodeDensity_func_test_result
-DmaxEdgeCnt=500;パラメーター | 必須 / 任意 | デフォルト値 | 説明 |
inputEdgeTableName | 可 | デフォルト値なし | 入力エッジテーブルの名前。 |
inputEdgeTablePartitions | 不可 | フルテーブル | 入力エッジテーブルのパーティション。 |
fromVertexCol | 可 | デフォルト値なし | 入力エッジテーブルの開始頂点列。 |
toVertexCol | 可 | デフォルト値なし | 入力エッジテーブルの末尾の頂点列。 |
outputTableName | 可 | デフォルト値なし | 出力テーブルの名前。 |
outputTablePartitions | 不可 | デフォルト値なし | 出力テーブルのパーティション。 |
lifecycle | 不可 | デフォルト値なし | 出力テーブルのライフサイクル。 |
maxEdgeCnt | 不可 | 500 | 頂点次数がこのパラメーターの値より大きい場合、サンプリングが必要です。 |
workerNum | 不可 | デフォルト値なし | 並列ジョブ実行の頂点の数。 並列性とフレームワーク通信コストの程度は、このパラメータの値とともに増加します。 |
workerMem | 不可 | 4096 | 1つのジョブで使用できるメモリの最大サイズ。 単位:MB。 デフォルト値: 4096 使用済みメモリのサイズがこのパラメーターの値を超えると、 |
splitSize | 不可 | 64 | データ分割サイズ。 単位:MB。 |
例:
SQLスクリプトコンポーネントを追加します。 [スクリプトモードの使用] および [テーブル作成文を追加するかどうか] の選択を解除します。 次のSQL文を入力します。
drop table if exists NodeDensity_func_test_edge; create table NodeDensity_func_test_edge as select * from ( select '1' as flow_out_id, '2' as flow_in_id union all select '1' as flow_out_id, '3' as flow_in_id union all select '1' as flow_out_id, '4' as flow_in_id union all select '1' as flow_out_id, '5' as flow_in_id union all select '1' as flow_out_id, '6' as flow_in_id union all select '2' as flow_out_id, '3' as flow_in_id union all select '3' as flow_out_id, '4' as flow_in_id union all select '4' as flow_out_id, '5' as flow_in_id union all select '5' as flow_out_id, '6' as flow_in_id union all select '5' as flow_out_id, '7' as flow_in_id union all select '6' as flow_out_id, '7' as flow_in_id )tmp; drop table if exists NodeDensity_func_test_result; create table NodeDensity_func_test_result ( node string, node_cnt bigint, edge_cnt bigint, density double, log_density double );データ構造
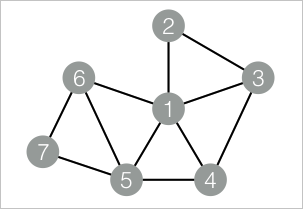
SQLスクリプトコンポーネントを追加します。 [スクリプトモードの使用] および [テーブル作成文を追加するかどうか] の選択を解除します。 次のPAIコマンドを入力し、2つのSQLスクリプトコンポーネントを接続します。
drop table if exists ${o1}; PAI -name NodeDensity -project algo_public -DinputEdgeTableName=NodeDensity_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DoutputTableName=${o1} -DmaxEdgeCnt=500;左上隅の
 をクリックしてパイプラインを実行します。
をクリックしてパイプラインを実行します。手順2で作成したSQLスクリプトコンポーネントを右クリックし、[データの表示]> [SQLスクリプトの出力] を選択してトレーニング結果を表示します。
| node | node_cnt | edge_cnt | density | log_density | | ---- | -------- | -------- | ------- | ----------- | | 1 | 5 | 4 | 0.4 | 1.45657 | | 2 | 2 | 1 | 1.0 | 1.24696 | | 3 | 3 | 2 | 0.66667 | 1.35204 | | 4 | 3 | 2 | 0.66667 | 1.35204 | | 5 | 4 | 3 | 0.5 | 1.41189 | | 6 | 3 | 2 | 0.66667 | 1.35204 | | 7 | 2 | 1 | 1.0 | 1.24696 |