トレーニング済みのテキスト要約モデルをテストし、予測結果に基づいて推論パフォーマンスを評価します。
前提条件
OSS が有効化され、Machine Learning Studio が OSS にアクセスする権限を付与されている必要があります。詳細については、「OSS の有効化」および「権限の付与」をご参照ください。
制限事項
DLC 計算リソースのみがサポートされています。
UI でのコンポーネントパラメーター設定
Designer では、UI 上でコンポーネントのパラメーターを設定します。
-
入力
入力ポート (左から右へ)
タイプ
推奨される上流コンポーネント
必須
予測データ
OSS
はい
予測モデル
コンポーネント出力
いいえ
-
コンポーネント設定
タブ
パラメーター
説明
フィールド設定
入力データ形式
入力ファイルのテキスト列。デフォルト値は target:str:1,source:str:1 です。
ソーステキスト列
入力テーブルのソーステキストの列名。デフォルト値は source です。
追加される出力列
出力テキスト列に追加する、入力ファイル内のテキスト列を指定します。複数の列名はコンマ (,) で区切ります。デフォルト値は source です。
出力列
結果テーブルの列名。デフォルト値は predictions,beams です。
予測データ出力
予測結果ファイルが格納される OSS バケットパス。
カスタムモデルの使用
直接予測にデフォルトの PAI モデルを使用するかどうか。有効値:
-
はい
-
いいえ (デフォルト)
Megatron モデルであるか
Text Summarization Train コンポーネントにリストされている `mg` プレフィックスを持つ事前学習済みモデルのみがサポートされています。有効値:
-
はい
-
いいえ (デフォルト)
モデルパス
[カスタムモデルの使用] が [はい] に設定されている場合にのみ必須です。
カスタムモデルが格納されている OSS バケットのストレージパス。
パラメーター設定
バッチサイズ
トレーニング中のバッチ処理サイズ。これは INT 型です。デフォルト値は 8 です。
マルチ GPU サーバーの場合、このパラメーターは各 GPU のバッチサイズを指定します。
テキストの最大長
シーケンス全体の最大長。これは INT 型です。値は (1, 512) の範囲内である必要があります。デフォルト値は 512 です。
言語
テキスト処理の言語:
-
zh: 中国語。
-
en: 英語。
ソースからのテキストコピー
コピーメカニズムを使用するかどうか。有効値:
-
false (デフォルト)
-
true
デコーダーの最小長
デコーダーの最小長。これは INT 型です。デフォルト値は 12 です。モデルの出力長はこの値より大きい必要があります。
デコーダーの最大長
デコーダーの最大長。これは INT 型です。デフォルト値は 32 です。モデルの出力長はこの値より小さい必要があります。
最小一意フィールド
非反復セグメント (n-gram) のサイズ。これは INT 型です。デフォルト値は 2 です。
ビームサーチサイズ
ビームサーチのサイズ。これは INT 型です。デフォルト値は 5 です。
返される候補数
返す結果の数。これは INT 型です。デフォルト値は 5 です。
重要このパラメーターは、[ビーム検索サイズ] と同じである必要があります。
実行チューニング
GPU タイプ
計算リソースの GPU タイプ。デフォルト値は gn5-c8g1.2xlarge です。
-
例
Text Summarization Predict コンポーネントを使用してワークフローを構築します。2 つのメソッドが利用可能です:
-
メソッド 1: Text Summarization Train コンポーネントによってファインチューニングされたモデルを使用します。
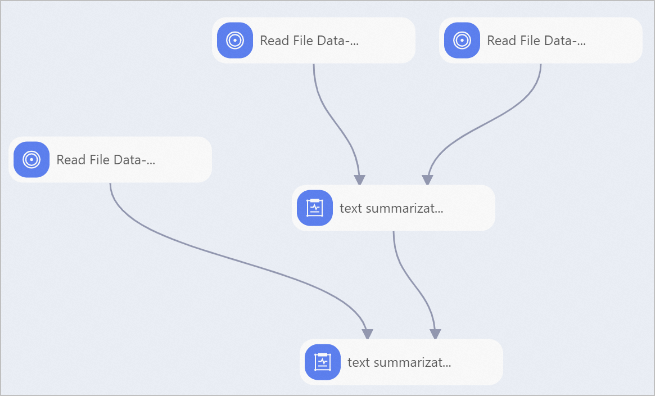
-
メソッド 2: カスタムモデルを使用します。

コンポーネントを設定し、ワークフローを実行します:
-
ワークフローを構築します。詳細については、Text Summarization Train トピックの「例」セクションをご参照ください。
-
要約するデータ (predict_data.txt) を準備して OSS バケットにアップロードします。この例のテストデータは、タブ区切りの TXT ファイルです。
CSV ファイルもサポートされています。MaxCompute クライアントの Tunnel コマンドを使用して、データセットを MaxCompute にアップロードします。MaxCompute クライアントのインストールと設定方法の詳細については、「クライアント (odpscmd) を使用した MaxCompute への接続」をご参照ください。Tunnel コマンドの詳細については、「Tunnel コマンド」をご参照ください。
-
メソッド 1 の [Read OSS Data-3] コンポーネントまたはメソッド 2 の [Read OSS Data-1] コンポーネントを使用してテストデータセットを読み取ります。[OSS データパス] パラメーターを、テストデータセットが格納されている OSS パスに設定します。
-
モデルファイルとテストデータセットを [Text Summarization Predict] コンポーネントに接続し、そのパラメーターを設定します。詳細については、「UI でのコンポーネントパラメーター設定」をご参照ください。
-
Text Summarization Train コンポーネントによってファインチューニングされたモデルの場合、[Text Summarization Train] コンポーネントのモデル出力ポートを [Text Summarization Predict] コンポーネントのモデル入力ポートに接続します。
-
カスタムモデルの場合、[フィールド設定] タブで、[カスタムモデルの使用] パラメーターを [はい] に設定し、[モデルパス] パラメーターをモデルが格納されている OSS パスに設定します。
-
-
 ボタンをクリックしてワークフローを実行します。実行が成功した後、[Text Summarization Predict] コンポーネントの [予測データ出力] パラメーターに指定された OSS パスで出力サマリーを表示します。
ボタンをクリックしてワークフローを実行します。実行が成功した後、[Text Summarization Predict] コンポーネントの [予測データ出力] パラメーターに指定された OSS パスで出力サマリーを表示します。
参考
-
Text Summarization Train コンポーネントの設定方法の詳細については、「Text Summarization Train」をご参照ください。