ComfyUI は、Stable Diffusion 向けのノードベースのユーザーインターフェースであり、ショートビデオコンテンツの生成やアニメーション制作などのタスクに対応する複雑な AIGC ワークフローを構築できます。このトピックでは、Elastic Algorithm Service (EAS) で ComfyUI をデプロイして使用する方法について説明します。
エディションガイド
シナリオ | 呼び出しメソッド | |
Standard Edition |
|
|
API Edition |
| API 呼び出し (非同期) |
Cluster Edition WebUI |
| WebUI |
Serverless Edition |
| WebUI |
API 呼び出しのタイプ (同期または非同期) は、EAS キューサービスを使用するかどうかによって決まります:
同期呼び出し:EAS キューサービスを使用せず、直接推論インスタンスにリクエストします。
非同期呼び出し:EAS キューサービスを使用して、リクエストを入力キューに送信し、サブスクリプションを通じて結果を取得します。
ComfyUI には独自の非同期キューシステムがあるため、同期呼び出しも非同期で処理されます。リクエストを送信すると、システムはプロンプト ID を返します。その後、このプロンプト ID を使用して推論結果をポーリングする必要があります。
課金
Serverless Edition:デプロイは無料です。実際の推論時間に基づいて課金されます。
その他のエディション:デプロイされたリソースと実行時間に対して課金されます。サービスが正常にデプロイされると、使用されていなくても料金が発生します。
課金の詳細については、「Elastic Algorithm Service (EAS) の課金」をご参照ください。
サービスのデプロイ
Serverless Edition は、シナリオベースのモデルデプロイ方法でのみデプロイできます。Standard、Cluster、および API エディションは、シンプルなシナリオベースのモデルデプロイ方法または、より多くの機能をサポートするカスタムモデルデプロイ方法でデプロイできます。
ComfyUI はシングルカードモード (単一マシン単一カードまたは複数マシン単一カード) のみをサポートし、複数カードの同時操作はサポートしていません。EAS インスタンスには ComfyUI プロセスが 1 つしかないため、デプロイ時に 2 × A10 のような複数の GPU 仕様を持つインスタンスを選択しても、使用される GPU は 1 つだけです。単一の画像生成タスクは高速化されません。
負荷分散:API Edition をデプロイし、非同期キューを使用して負荷分散を実装する必要があります。
方法 1:シナリオベースのモデルデプロイ (推奨)
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
[Elastic Algorithm Service (EAS)] ページで、[サービスのデプロイ] をクリックします。[シナリオベースのモデルデプロイ] で、[AI 動画生成:ComfyUI ベースのデプロイ] をクリックします。
[AI 動画生成:ComfyUI ベースのデプロイ] ページで、次のパラメーターを設定します。
[エディション]:「エディションガイド」に基づいてエディションを選択します。
[ストレージのマウント]:独自のモデルを使用したり、カスタムノードをインストールしたり、API 呼び出しを行ったりする場合は、モデルを設定する必要があります。例えば、Object Storage Service (OSS) を使用する場合、バケットとディレクトリを選択します。デプロイが成功すると、システムはバケット内に必要な ComfyUI ディレクトリを自動的に作成します。バケットが EAS サービスと同じリージョンにあることを確認してください。
[リソース構成]:GU30、A10、または T4 GPU タイプを使用することを推奨します。システムはデフォルトで に設定されており、これはコスト効率の高いオプションです。
[デプロイ] をクリックします。デプロイには約 5 分かかります。[サービスステータス] が [実行中] に変わると、デプロイは成功です。
方法 2:カスタムモデルデプロイ
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
[サービスのデプロイ] をクリックします。[カスタムモデルデプロイ] セクションで、[カスタムデプロイ] をクリックします。
[カスタムデプロイ] ページで、次の主要なパラメーターを設定します。詳細については、「カスタムデプロイのパラメーター説明」をご参照ください。
[デプロイ方法] を [イメージデプロイ] に設定し、[Web アプリケーションを有効にする] チェックボックスをオンにします。
[イメージ構成]:[公式イメージ] リストで、[comfyui] > [comfyui:1.9] を選択します。イメージタグの x.x は Standard Edition、x.x-api は API Edition、x.x-cluster は Cluster Edition を示します。
説明バージョンは急速に更新されるため、デプロイ時には最新のイメージバージョンを選択できます。
各バージョンのシナリオの詳細については、「エディションガイド」をご参照ください。
[ストレージマウント]:独自のモデルを使用したり、カスタムノードをインストールしたり、API 呼び出しを行ったりするには、ストレージをマウントする必要があります。例えば、Object Storage Service (OSS) を使用する場合、バケットとディレクトリを選択します。デプロイが完了すると、選択したディレクトリに ComfyUI に必要なディレクトリが自動的に作成されます。バケットが EAS サービスと同じリージョンにあることを確認してください。
[Uri]:
 をクリックして、既存の OSS ストレージディレクトリを選択します。例:
をクリックして、既存の OSS ストレージディレクトリを選択します。例:oss://bucket-test/data-oss/。[マウントパス]:これを
/code/data-ossに設定します。これにより、設定された OSS ファイルディレクトリがイメージ内の/code/data-ossパスにマウントされます。
コマンドの実行:
イメージバージョンを設定すると、システムは自動的に実行コマンドを
python main.py --listen --port 8000に設定します。ポート番号は 8000 です。ストレージをマウントした場合、[起動コマンド] に
--data-dirパラメーターを追加し、その値をマウントディレクトリに設定する必要があります。このマウントディレクトリは [マウントパス] と同じでなければなりません。例:python main.py --listen --port 8000 --data-dir /code/data-oss。
[リソースタイプ] を [パブリックリソース] に設定します。
[デプロイリソース]:リソース仕様は GPU タイプでなければなりません。[ml.gu7i.c16m60.1-gu30] を推奨します。これは最もコスト効率の高いオプションです。在庫が不足している場合は、[ecs.gn6i-c16g1.4xlarge] を選択できます。
[デプロイ] をクリックします。サービスのデプロイには約 5 分かかります。[サービスステータス] が [実行中] になると、サービスは正常にデプロイされています。
サービスの呼び出し
WebUI の使用
Standard、Cluster、および Serverless エディションは WebUI をサポートしています。
対象のサービス名をクリックして概要ページに移動し、右上隅の [Web アプリケーション] をクリックします。
ページの読み込みが遅い場合は、「ページのフリーズまたはリフレッシュに時間がかかる」をご参照ください。
1. テンプレートワークフローの使用
WebUI はカスタムワークフロー構成をサポートし、複数のプリセットテンプレートを提供します。 ページでテンプレートを選択できます。このトピックでは、Wan VACE Text to Video ワークフローテンプレートを例として使用します。
Serverless Edition の場合、このワークフローはテンプレートに含まれていません。別のテンプレートを使用するか、 を選択してローカルファイルシステムからワークフローをロードできます。

ワークフローがロードされた後、モデルが見つからないというエラーメッセージは無視できます。このメッセージが再度表示されないようにチェックボックスをオンにすることを推奨します。
パスの変更により、ワークフローを直接実行すると次のエラーが発生する可能性があります。
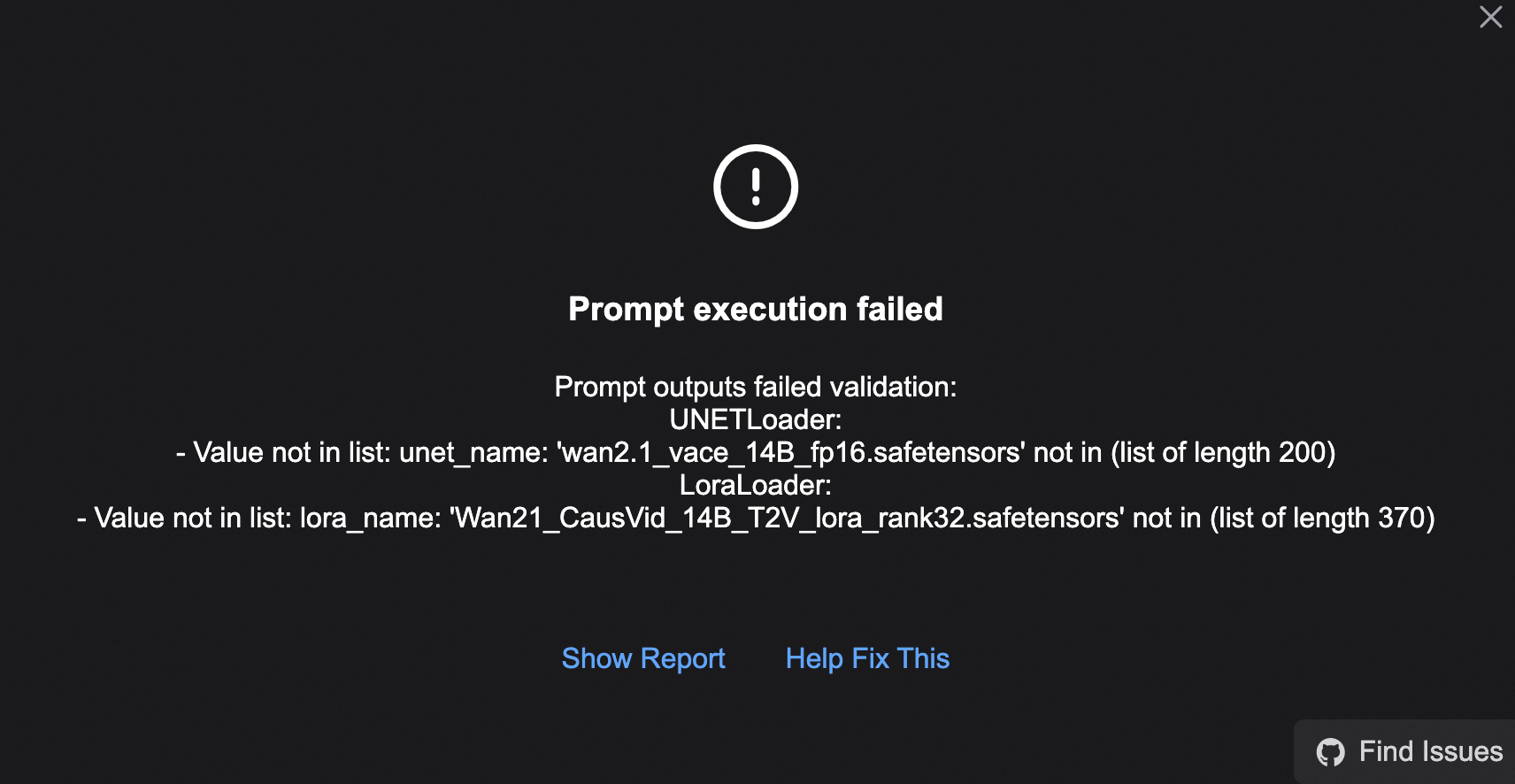
まず、[Load models here] エリアで wan2.1_vace_14B_fp16.safetensors と Wan21_CausVid_14B_T2V_lora_rank32.safetensors モデルを再選択します。

ワークフローが正常に実行されると、生成された動画が [Save Video] エリアに表示されます。
2. サードパーティモデルの使用とカスタムノード (ComfyUI プラグイン) のインストール
デプロイされた ComfyUI のバージョンが Serverless Edition でないことを確認してください。Serverless Edition は組み込みのモデルとノードしか使用できません。
サービスにはストレージマウントが設定されている必要があります。カスタムデプロイの場合、
--data-dirパラメーターを [起動コマンド] フィールドに追加してディレクトリをマウントします。詳細については、「方法 2:カスタムモデルデプロイ」をご参照ください。サービスがデプロイされると、システムはマウントされた OSS または NAS ストレージに次のディレクトリ構造を自動的に作成します。
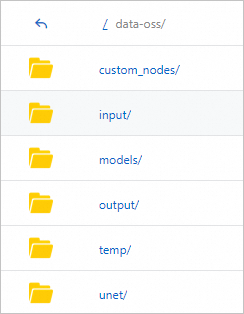
ここで:
custom_nodes:このディレクトリはノードファイルを保存するために使用されます。
models:このディレクトリはモデルファイルを保存するために使用されます。
モデルまたはノードファイルのアップロード。OSS を例にとると、コンソールで OSS にファイルをアップロードできます。大きなファイルについては、「OSS に大きなファイルをアップロードする方法」をご参照ください。
モデルファイルのアップロード:モデルを使用するノードのソースプロジェクトの指示に従って、モデルを
modelsの対応するサブディレクトリにアップロードします。例:チェックポイントローダーの場合、モデルは
models/checkpointsにアップロードする必要があります。スタイルモデルローダーの場合、モデルは
models/stylesにアップロードする必要があります。
ノードファイルのアップロード:カスタムノードをマウントされたストレージの
custom_nodesディレクトリにアップロードすることを推奨します。
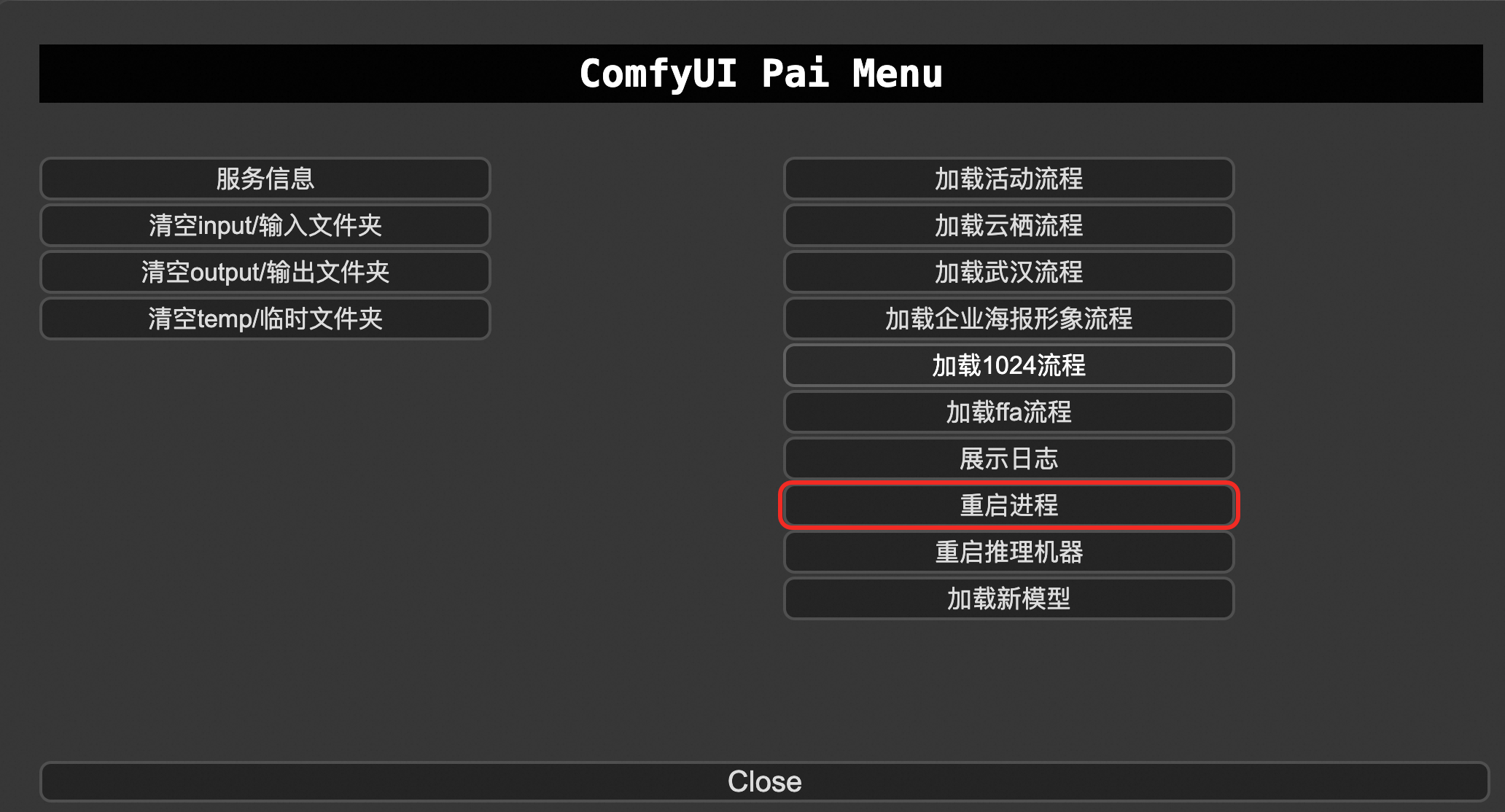
新しいモデルのロードまたはプロセスの再起動。
マウントされたバケットにモデルをアップロードした後、 をクリックします。それでもモデルが見つからない場合は、[プロセスの再起動] をクリックします。プロセスが再起動したら、ページをリフレッシュします。
ノードファイルをアップロードした後、[プロセスの再起動] をクリックします。プロセスが再起動したら、ブラウザのページをリフレッシュします。
3. ワークフローのエクスポート
ワークフローをデバッグした後、 をクリックしてワークフローを JSON ファイルとして保存します。その後、このファイルを API 呼び出しに使用できます。

API 呼び出し
Standard Edition サービスは同期呼び出しのみをサポートし、オンラインデバッグ機能を提供します。
API Edition サービスは非同期呼び出しのみをサポートし、api_prompt パスのみをサポートします。
ComfyUI の API リクエストボディはワークフローの構成に依存します。まず、WebUI からワークフローの JSON ファイルをセットアップし、エクスポートする必要があります。
同期呼び出し:リクエストボディは、ワークフロー JSON ファイルの内容を prompt キーでラップする必要があります。
非同期呼び出し:リクエストボディは、ワークフロー JSON ファイルの内容そのものです。
Wan VACE Text to Video ワークフローは時間がかかるため、テスト用に次のワークフローが提供されています。実行には約 3 分かかります。
オンラインデバッグ
[Elastic Algorithm Service (EAS)] ページで、対象のサービスを見つけ、[操作] 列の [オンラインデバッグ] をクリックします。
デバッグページの [オンラインデバッグリクエストパラメーター] セクションで、[ボディ] フィールドにリクエストボディを入力します。次に、リクエスト URL テキストボックスに
/promptを追加します。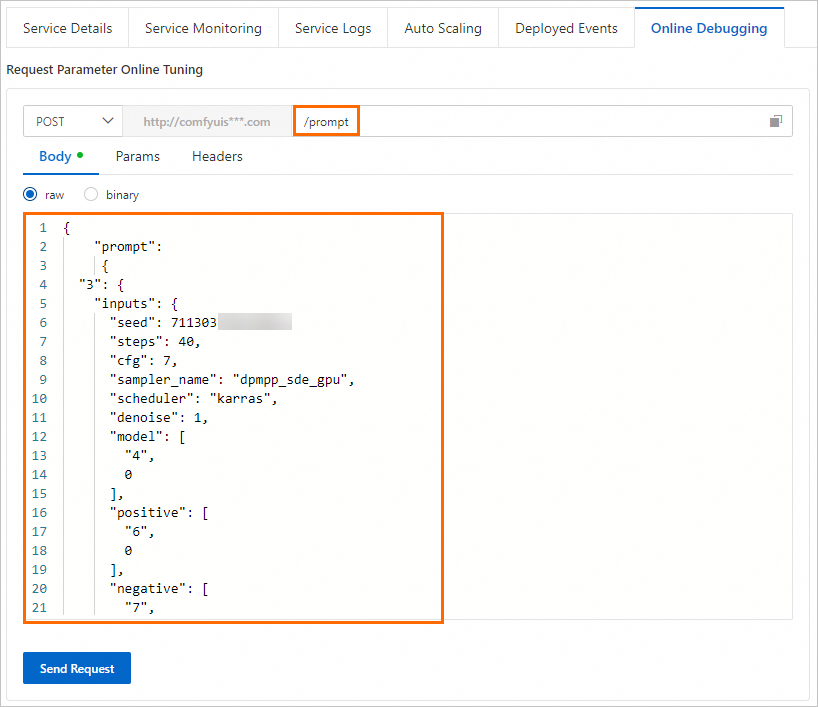
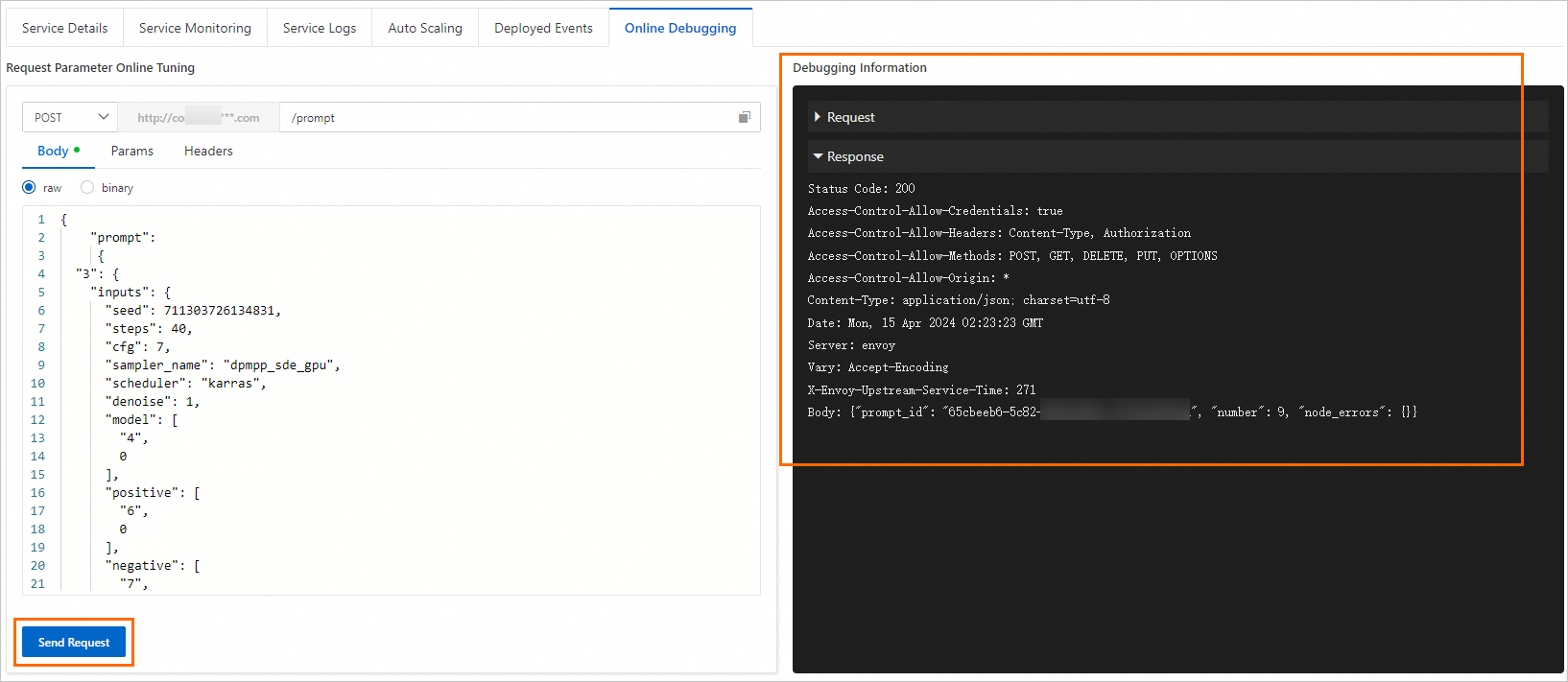
[リクエストの送信] をクリックして、[デバッグ情報] エリアでレスポンスを表示します。次の図を参照してください。
[オンライン API デバッグリクエストパラメーター] エリアで、リクエストメソッドを GET に設定し、テキストボックスに
/history/<prompt id>を入力します。次の図を参照してください。
<prompt id>を前のステップで取得したプロンプト ID に置き換えます。[リクエストの送信] をクリックして推論結果を取得します。
生成された推論結果は、マウントされたストレージの
outputディレクトリで確認できます。
同期呼び出し
[推論サービス] タブで、対象のサービス名をクリックして [概要] ページに移動します。[基本情報] セクションで、[エンドポイント情報を表示] をクリックします。
[呼び出し方法] パネルで、エンドポイントとトークンを取得します。要件に応じてインターネットまたは VPC エンドポイントを選択します。以下の例では、これらの値のプレースホルダーとして
<EAS_ENDPOINT>と<EAS_TOKEN>を使用します。
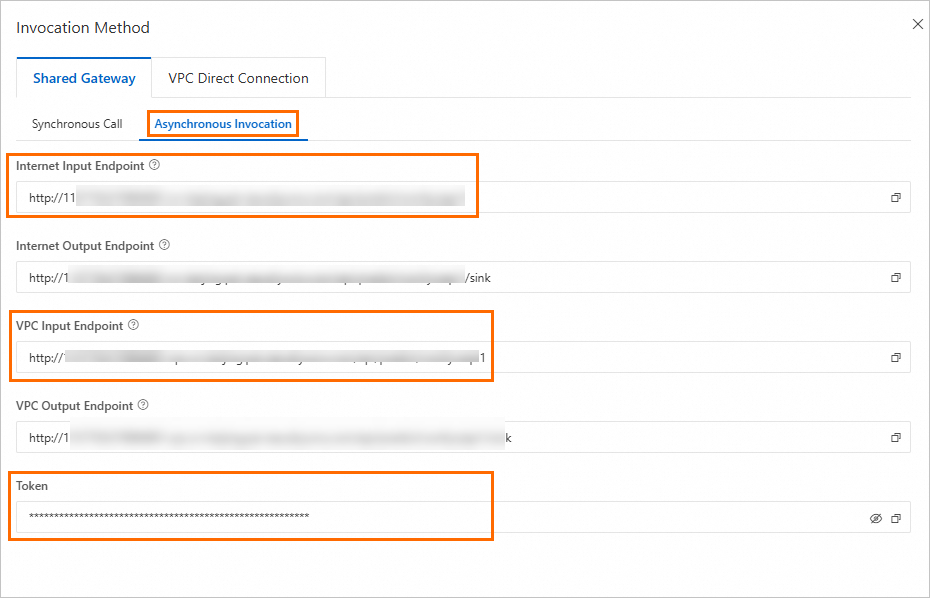
非同期呼び出し
非同期呼び出しは api_prompt パスのみをサポートします。task_id パラメーターは、リクエストと結果を識別するための重要なフラグです。各リクエストに一意の値を割り当てて、キューからの対応する結果と一致させる必要があります。リクエストパスは次のとおりです:
{service_url}/api_prompt?task_id={一意の値を割り当てる必要があります}
[推論サービス] タブで、対象のサービス名をクリックして [概要] ページを開きます。[基本情報] セクションで、[呼び出し情報を表示] をクリックします。[呼び出し情報] ダイアログボックスの [非同期呼び出し] タブで、サービスのエンドポイントとトークンを表示できます。
生成された画像や動画は、マウントされた output ディレクトリに保存されます。API 呼び出しの結果は、ファイル名とサブディレクトリ名を返します。OSS の場合、ファイルをダウンロードするには完全なファイルパスを構築する必要があります。詳細については、「Alibaba Cloud SDK を使用して OSS からファイルをダウンロードする」をご参照ください。
よくある質問
モデルとノード
1. WebUI エラー:モデルが見つかりません
問題の説明:次のエラーが報告されます:
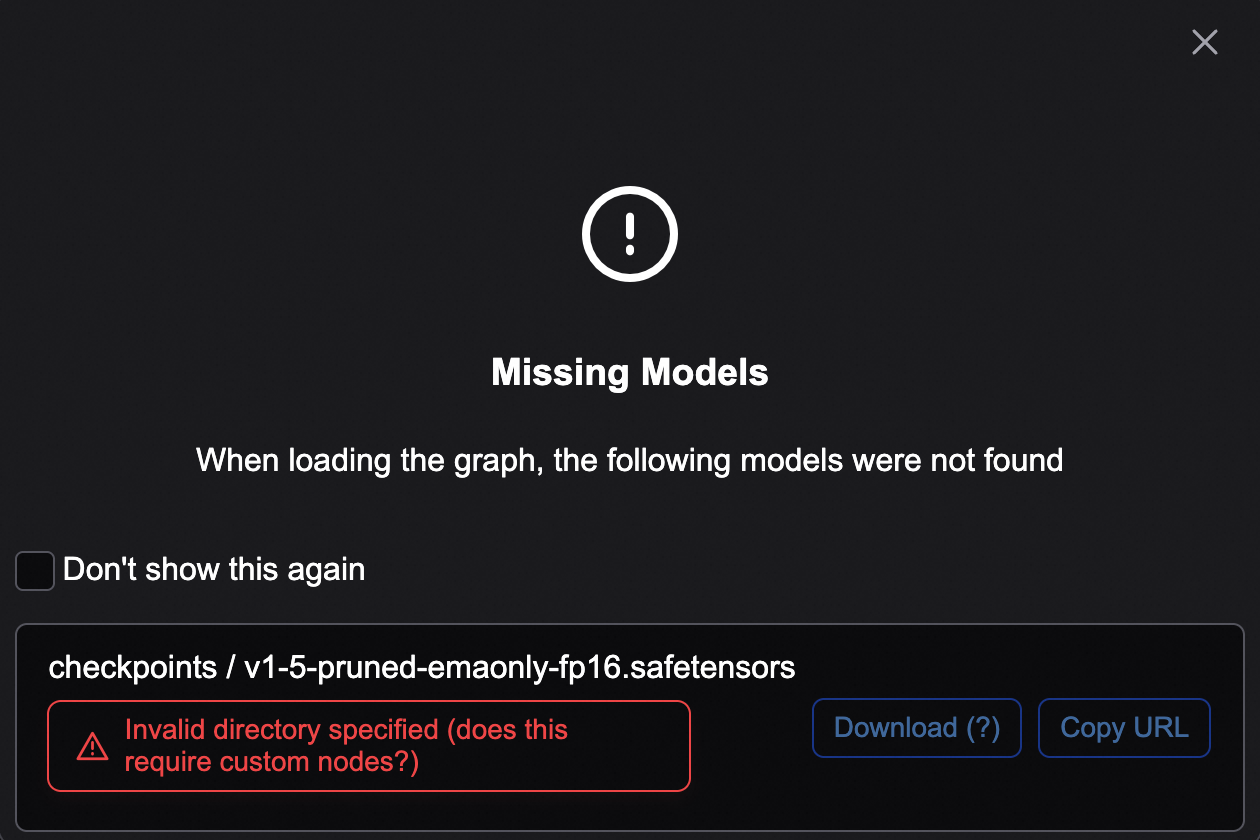
解決策:このチェックは PAI にデプロイされた ComfyUI には無効です。実行時エラーが優先されます。[このメッセージを再度表示しない] チェックボックスをオンにするか、設定でモデル検証を無効にすることを推奨します。
2. 新しいモデルをアップロードしましたが、見つかりません
まず、Serverless Edition を使用していないか確認してください。Serverless Edition は独自のモデルのアップロードをサポートしていません。Standard または Cluster Edition を使用してください。サポートされているバージョンを使用している場合は、次の手順を実行します:
ページで [PaiCustom] をクリックし、[新しいモデルのロード] を選択します。
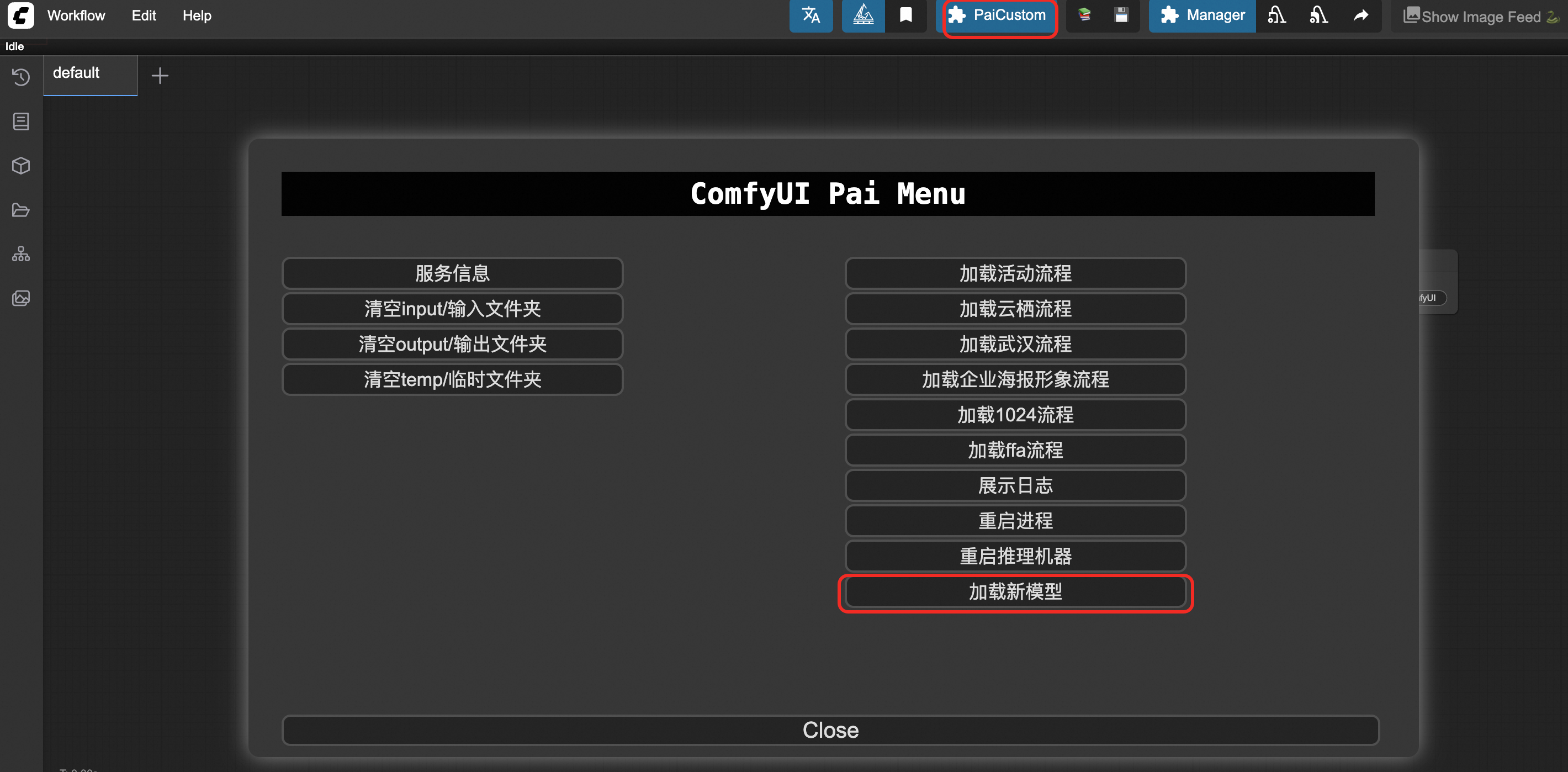
それでもうまくいかない場合は、[プロセスの再起動] をクリックします。
3. モデルローダーに「undefined」と表示される
4. ノードが見つかりません
5. ComfyUI Manager がモデルのダウンロードまたはノードのインストールに失敗する
6. 利用可能なモデルファイルとノード (ComfyUI プラグイン) のリストを表示するにはどうすればよいですか?
イメージと依存関係
1. wheel パッケージをインストールするにはどうすればよいですか?
マウント構成が完了していることを確認してください。次の例では、OSS パス Uri が oss://examplebucket/comfyui であると仮定します。

wheel パッケージをマウントされた OSS の
oss://examplebucket/comfyui/models/whlにアップロードします。whlフォルダが存在しない場合は作成します。この例では、OSS マウントパスは /mnt/data です。実行コマンドの前に
pip install /mnt/data/models/whl/xxx.whlコマンドを追加します。このコマンドでは、/mnt/data はご利用の OSS マウントパス、xxx.whl はご利用の wheel パッケージの名前です。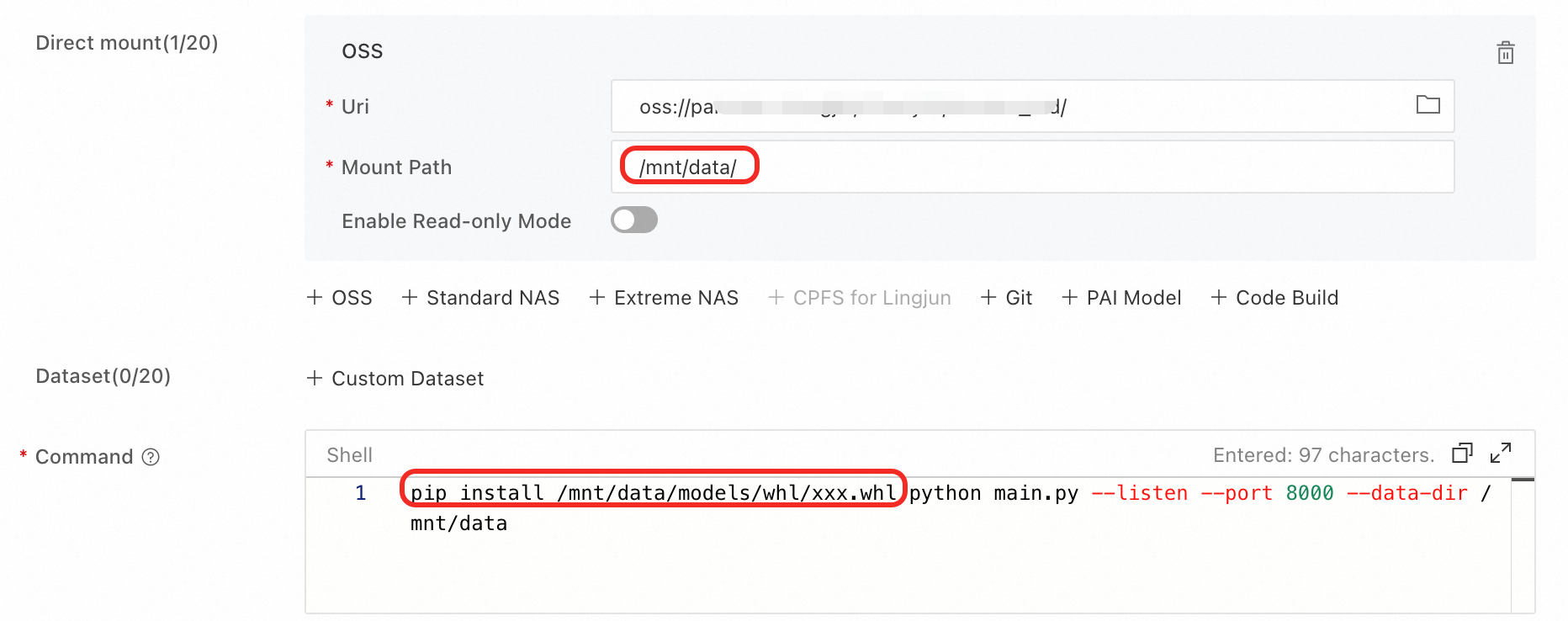
2. イメージのバージョンを更新し、インストール済みのカスタムモデルを保持するにはどうすればよいですか?
Serverless バージョンの ComfyUI イメージは更新できません。ただし、OSS または NAS ストレージがマウントされている他のバージョンでは、カスタムモデルは保持されます。これにより、サービス構成の [公式イメージ] を更新しても、カスタムモデルに影響はありません。そのためには、次の手順を実行します:
サービス詳細ページで、右上隅の [更新] をクリックします。

サービスがシナリオベースの方法でデプロイされた場合は、カスタムデプロイに切り替えます。右側で [サービス構成] をクリックし、JSON ファイルを編集して、コンテナーの image フィールドを更新します。例えば、pai-eas/comfyui:1.9 の 1.9 を必要なバージョンに変更します。
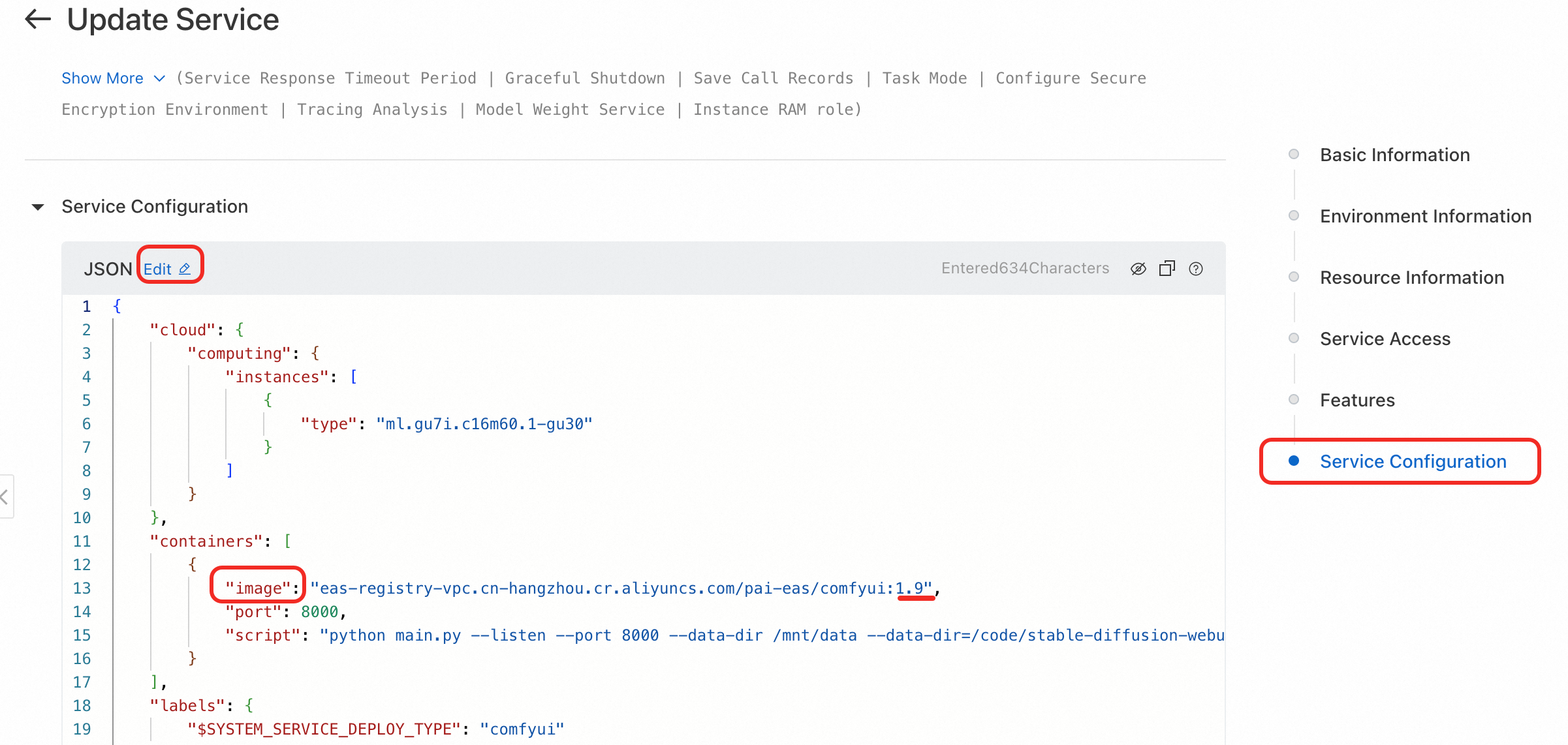
編集ウィンドウで、[直接更新] をクリックします。
3. イメージに依存関係ライブラリがありません
サードパーティライブラリを構成して、不足している依存関係をインストールします。手順は次のとおりです:
サービス詳細ページで、右上隅の [更新] をクリックします。
サービスがシナリオベースの方法でデプロイされた場合は、カスタムデプロイに切り替えます。右側で [環境コンテキスト] をクリックします。[その他の構成] セクションで、サードパーティライブラリの構成を見つけ、指定された形式で必要な依存関係を入力します。
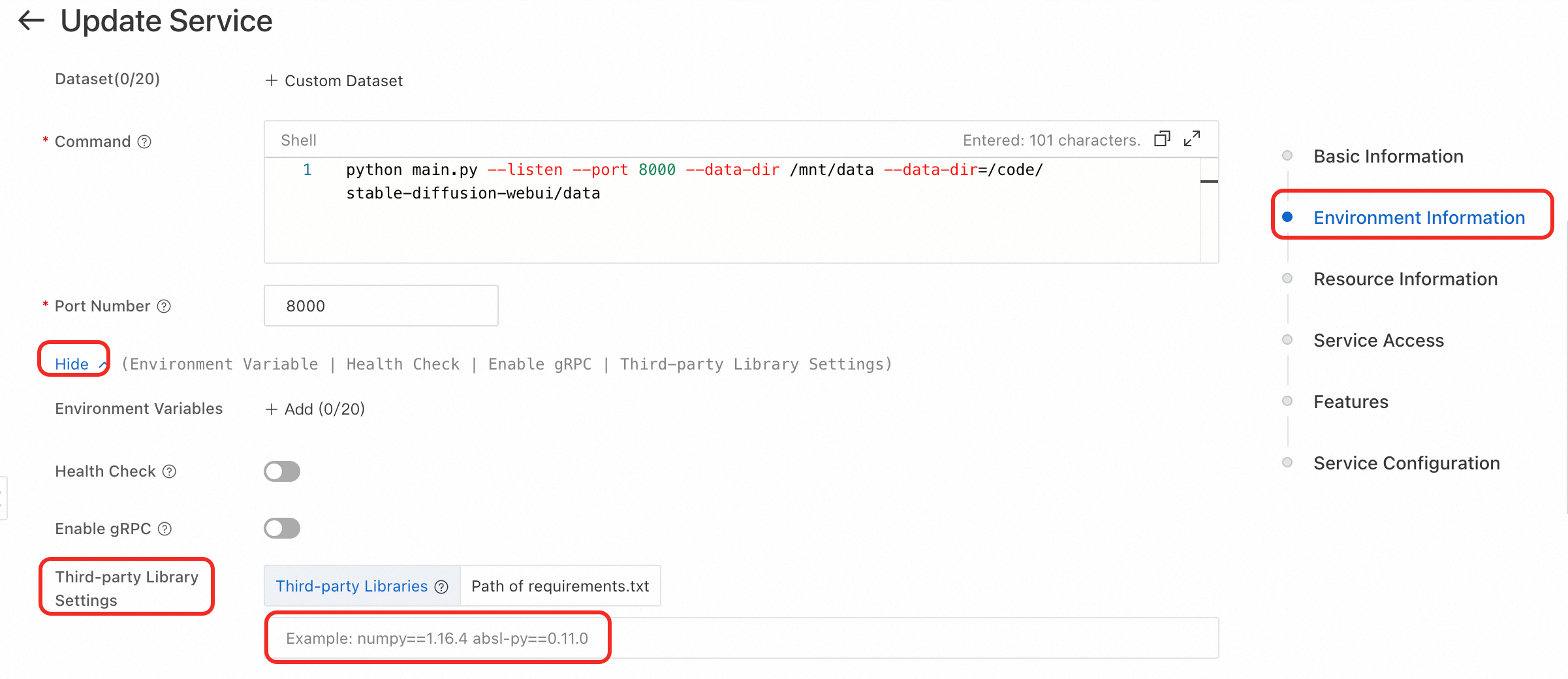
ページ下部の [更新] ボタンをクリックして、サービスの更新を完了します。
実行時の例外
1. ページのフリーズまたはリフレッシュに時間がかかりすぎる
2. ワークフローが途中で実行され、プロセスが再起動する
3. RuntimeError: CUDA error: out of memory
4. API 呼び出しエラー:「url not found」または「404 page not found」?
5. サービスが常に「待機中」状態であるか、ComfyUI が画像を生成できない
6. なぜサービスは一定期間実行された後、自動的に停止するのですか?
その他
1. ログイン不要 URL の有効期間を延長するにはどうすればよいですか?
API を使用して、指定された有効期間を持つログイン不要の Web アクセスリンクを取得できます。
DescribeServiceSignedUrl API リンクをクリックして API ページに移動します。
サービスリージョンを選択します。
サービスが配置されているリージョンとサービス名を入力します。この情報は EAS サービスの概要ページから取得できます。
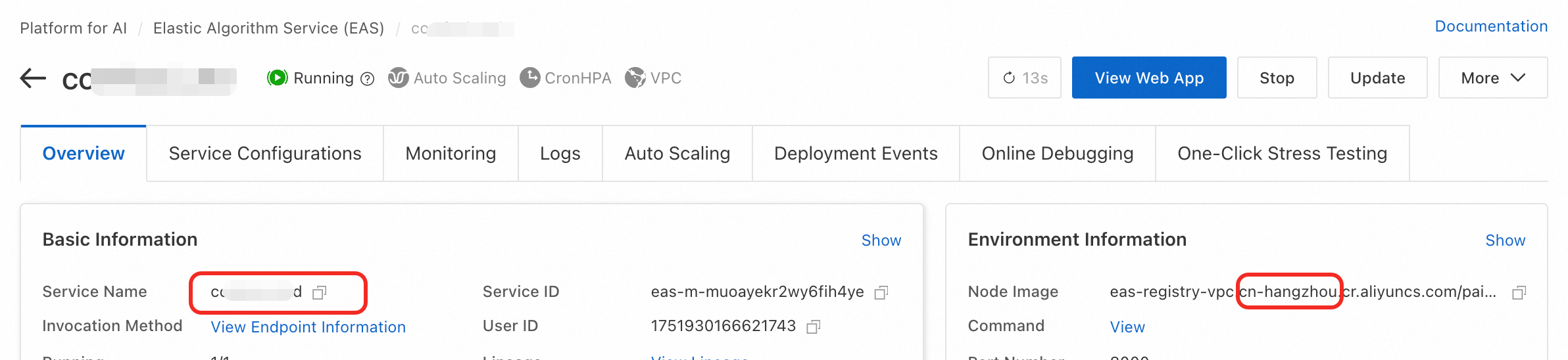
その他のパラメーターは次のとおりです:
Type page type:ドロップダウンリストから webview を選択します。
Expire time:長い有効期間を設定するには、9007199254740991 を入力します。現在の最大有効期間は 12 時間です。
それ以外の場合は、秒単位の整数値を入力します。
Internal whether it is a VPC link:VPC 呼び出しでない場合は false を選択します。それ以外の場合は true を選択します。
[呼び出しの開始] をクリックします。レスポンスの SignedUrl が、サービスのログイン不要の Web アクセスリンクです。
2. xFormers が画像生成速度に与える高速化効果
3. ComfyUI Serverless Edition をデプロイする際の EAS と Function Compute の主な違い
4. WebUI ページのデフォルト言語を切り替えるにはどうすればよいですか?
WebUI ページで、左下隅の設定ボタン
 をクリックします。
をクリックします。[設定] ダイアログボックスで、次の 2 つの場所で言語を設定します。パラメーターを設定した後、ページをリフレッシュします。
左側のナビゲーションウィンドウで、[Comfy] を選択します。右側のリージョン設定で、目的の言語を選択します。

左側のナビゲーションウィンドウで、[言語] を選択します。右側の [ロケール] セクションで、目的の言語を選択します。

付録
Cluster Edition サービスの動作原理の紹介
次の図は、実装原理を示しています:

Cluster Edition サービスは、マルチユーザーシナリオ向けに設計されています。クライアントとバックエンドの推論インスタンスを分離することで、複数のユーザーがバックエンドの推論インスタンスを共有できます。これにより、インスタンスの利用率が向上し、推論コストが削減されます。
各ユーザーは独立したバックエンド環境と作業ディレクトリを持ち、効率的な GPU 共有とファイル管理が可能です。
プロキシはクライアントプロセスと推論インスタンスを管理します。すべてのユーザー操作は自身のプロセスで処理され、ファイル操作はパブリックディレクトリと個人ディレクトリに限定されます。これにより、ユーザー間の作業ディレクトリが効果的に隔離されます。ユーザーがリクエストを処理する必要がある場合、プロキシはバックエンドから利用可能なアイドル状態のインスタンスを見つけて推論リクエストを処理します。