DLC トレーニングジョブのリソース使用量をリアルタイムでモニタリングし、しきい値を超えた場合にアラート通知を受け取ります。ジョブ、Pod、GPU カードの各レベルで、CPU、GPU、メモリ、ディスク、ネットワーク、RDMA、CPFS の各メトリクスを Cloud Monitor または ARMS を使用して確認できます。
前提条件
1 つ以上の DLC トレーニングジョブを作成します。詳細については、「トレーニングタスクの作成」をご参照ください。
制限事項
汎用コンピューティングリソースを使用する従量課金制のトレーニングジョブでは、モニタリングはサポートされていません。
必要な権限
-
Alibaba Cloud アカウント (root ユーザー):追加の権限付与なしで、すべての操作が可能です。
-
Resource Access Management (RAM) ユーザー:
-
ワークスペース内の DLC ジョブのモニタリングデータを表示する場合:
-
RAM ユーザーをワークスペースメンバーとして追加し、管理者、アルゴリズム開発者、またはアルゴリズム O&M エンジニアのロールを付与します。詳細については、「ワークスペースメンバーの管理」をご参照ください。
-
RAM ユーザーに Cloud Monitor の読み取り専用アクセス権限 (AliyunCloudMonitorReadOnlyAccess) を付与します。詳細については、「RAM ユーザーの権限管理」をご参照ください。
-
-
モニタリングデータの表示およびアラート通知の設定を行う場合:
-
RAM ユーザーをワークスペースメンバーとして追加し、管理者、アルゴリズム開発者、またはアルゴリズム O&M エンジニアのロールを付与します。詳細については、「ワークスペースメンバーの管理」をご参照ください。
-
RAM ユーザーに Cloud Monitor の管理権限 (AliyunCloudMonitorFullAccess) を付与します。詳細については、「RAM ユーザーの権限管理」をご参照ください。
-
-
利用可能なメトリクス
利用可能なメトリクスには、CPU、メモリ、ディスク、ネットワーク、RDMA、CPFS、および GPU 関連のメトリクス(メモリ使用量、計算能力、SM デバイス使用量)が含まれます。これらのメトリクスは、ジョブ、Pod、GPU カードの各ディメンションで利用可能です。完全なリストについては、「Deep Learning Containers (DLC) メトリクス」をご参照ください。
ジョブ(タスク)ディメンション
|
メトリクス |
説明 |
|
CPU 使用率(ジョブディメンション) |
指定されたジョブの CPU 使用率(パーセント)です。 |
|
メモリ使用率(ジョブディメンション) |
指定されたジョブのメモリ使用率(パーセント)です。 |
|
ディスク読み取りレート(ジョブディメンション) |
指定されたジョブのディスク読み取りレート(MiB/s)です。 |
|
ディスク書き込みレート(ジョブディメンション) |
指定されたジョブのディスク書き込みレート(MiB/s)です。 |
|
ネットワーク受信レート(ジョブディメンション) |
指定されたジョブのネットワーク受信レート(MiB/s)です。 |
|
ネットワーク送信レート(ジョブディメンション) |
指定されたジョブのネットワーク送信レート(MiB/s)です。 |
|
GPU 計算能力使用率(ジョブディメンション) |
指定されたジョブの GPU 計算能力使用率です。 |
|
GPU メモリ使用率(ジョブディメンション) |
指定されたジョブの GPU メモリ使用率です。 |
|
GPU SM デバイス使用率(ジョブディメンション) |
指定されたジョブの GPU SM デバイス使用率です。 |
|
GPU デバイス消費電力(ジョブディメンション) |
指定されたジョブの GPU デバイス消費電力です。 |
|
GPU 温度(ジョブディメンション) |
指定されたジョブの GPU 温度です。 |
|
GPU カード全体の健全性(ジョブディメンション) |
指定されたジョブ内の GPU の全体的な健全性です。100 % は正常な状態を示します。100 % 未満は、1 枚以上が異常であることを示します。 |
|
RDMA 受信レート(ジョブディメンション) |
指定されたジョブの RDMA 受信レートです。 |
|
RDMA 送信レート(ジョブディメンション) |
指定されたジョブの RDMA 送信レートです。 |
|
CPFS 書き込みレート(ジョブディメンション) |
指定されたジョブの CPFS デバイス書き込みレート(MiB/s)です。 |
|
CPFS 読み取りレート(ジョブディメンション) |
指定されたジョブの CPFS デバイス読み取りレート(MiB/s)です。 |
|
NVLink 受信データ量(ジョブディメンション) |
指定されたジョブ内の GPU デバイスが NVLink 経由で受信したデータ量です。 |
|
NVLink 送信データ量(ジョブディメンション) |
指定されたジョブ内の GPU デバイスが NVLink 経由で送信したデータ量です。 |
|
PCIe 受信データ量(ジョブディメンション) |
指定されたジョブ内の GPU デバイスが PCIe 経由で受信したデータ量です。 |
|
PCIe 送信データ量(ジョブディメンション) |
指定されたジョブ内の GPU デバイスが PCIe 経由で送信したデータ量です。 |
|
その他のメトリクスについては、「Deep Learning Containers (DLC) メトリクス」をご参照ください。 |
|
Pod(ワーカー)ディメンション
|
メトリクス |
説明 |
|
CPU 使用率(Pod ディメンション) |
指定された Pod の CPU 使用率(パーセント)です。 |
|
メモリ使用率(Pod ディメンション) |
指定された Pod のメモリ使用率(パーセント)です。 |
|
ディスク読み取りレート(Pod ディメンション) |
指定された Pod のディスク読み取りレート(MiB/s)です。 |
|
ディスク書き込みレート(Pod ディメンション) |
指定された Pod のディスク書き込みレート(MiB/s)です。 |
|
ネットワーク受信レート(Pod ディメンション) |
指定された Pod のネットワーク受信レート(MiB/s)です。 |
|
ネットワーク送信レート(Pod ディメンション) |
指定された Pod のネットワーク送信レート(MiB/s)です。 |
|
GPU 計算能力使用率(Pod ディメンション) |
指定された Pod の GPU 計算能力使用率です。 |
|
GPU メモリ使用率(Pod ディメンション) |
指定された Pod の GPU メモリ使用率です。 |
|
GPU SM デバイス使用率(Pod ディメンション) |
指定された Pod の GPU SM デバイス使用率です。 |
|
GPU デバイス消費電力(Pod ディメンション) |
指定された Pod の GPU デバイス消費電力です。 |
|
GPU 温度(Pod ディメンション) |
指定された Pod の GPU 温度です。 |
|
GPU カード全体の健全性(Pod ディメンション) |
指定された Pod 内の GPU の全体的な健全性です。100 % は正常な状態を示します。100 % 未満は、1 枚以上が異常であることを示します。 |
|
RDMA 受信レート(Pod ディメンション) |
指定された Pod の RDMA 受信レート(MiB/s)です。 |
|
RDMA 送信レート(Pod ディメンション) |
指定された Pod の RDMA 送信レート(MiB/s)です。 |
|
CPFS 読み取りレート(Pod ディメンション) |
指定された Pod の CPFS デバイス読み取りレート(MiB/s)です。 |
|
CPFS 書き込みレート(Pod ディメンション) |
指定された Pod の CPFS デバイス書き込みレート(MiB/s)です。 |
|
NVLink 受信データ量(Pod ディメンション) |
指定された Pod 内の GPU デバイスが NVLink 経由で受信したデータ量です。 |
|
NVLink 送信データ量(Pod ディメンション) |
指定された Pod 内の GPU デバイスが NVLink 経由で送信したデータ量です。 |
|
PCIe 受信データ量(Pod ディメンション) |
指定された Pod 内の GPU デバイスが PCIe 経由で受信したデータ量です。 |
|
PCIe 送信データ量(Pod ディメンション) |
指定された Pod 内の GPU デバイスが PCIe 経由で送信したデータ量です。 |
|
その他のメトリクスについては、「Deep Learning Containers (DLC) メトリクス」をご参照ください。 |
|
単一 GPU カードディメンション
|
メトリクス |
説明 |
|
GPU メモリデバイスインターフェイス使用率(カードディメンション) |
指定された Pod 内の 1 枚以上または複数枚の GPU カードにおける GPU メモリデバイスインターフェイス使用率です。 |
|
GPU SM デバイス使用率(カードディメンション) |
指定された Pod 内の 1 枚以上または複数枚の GPU カードにおける GPU SM デバイス使用率です。 |
|
GPU デバイス消費電力(カードディメンション) |
指定された Pod 内の 1 枚以上または複数枚の GPU カードにおける GPU デバイス消費電力です。 |
|
GPU 温度(カードディメンション) |
指定された Pod 内の 1 枚以上または複数枚の GPU カードにおける GPU デバイス温度です。 |
|
GPU カード全体の健全性(カードディメンション) |
指定された Pod 内の 1 枚以上または複数枚の GPU カードの全体的な健全性です。100 % は正常な状態を示します。100 % 未満は、1 枚以上が異常であることを示します。 |
|
その他のメトリクスについては、「Deep Learning Containers (DLC) メトリクス」をご参照ください。 |
|
Cloud Monitor の使用
Cloud Monitor は、Alibaba Cloud リソースおよびインターネットアプリケーション向けのエンタープライズグレードのモニタリングサービスです。PAI-DLC ジョブのモニタリングデータを表示したり、アラートを設定したり、API 経由でメトリクスをサブスクライブしたりすることで、カスタムダッシュボードを構築できます。詳細については、「Cloud Monitor とは」をご参照ください。
課金
Cloud Monitor は課金対象です。詳細については、「Cloud Monitor の課金」をご参照ください。
モニタリングデータの表示
-
Cloud Monitor コンソール にログインします。
-
左側のナビゲーションウィンドウで、 を選択します。
-
クラウドサービスダッシュボード ページで、PAI-Deep Learning Containers (DLC) を選択し、その後、モニタリングチャートを表示するための ワークスペース ID を選択または検索します。ワークスペース ID の確認方法については、「ワークスペースの管理」をご参照ください。
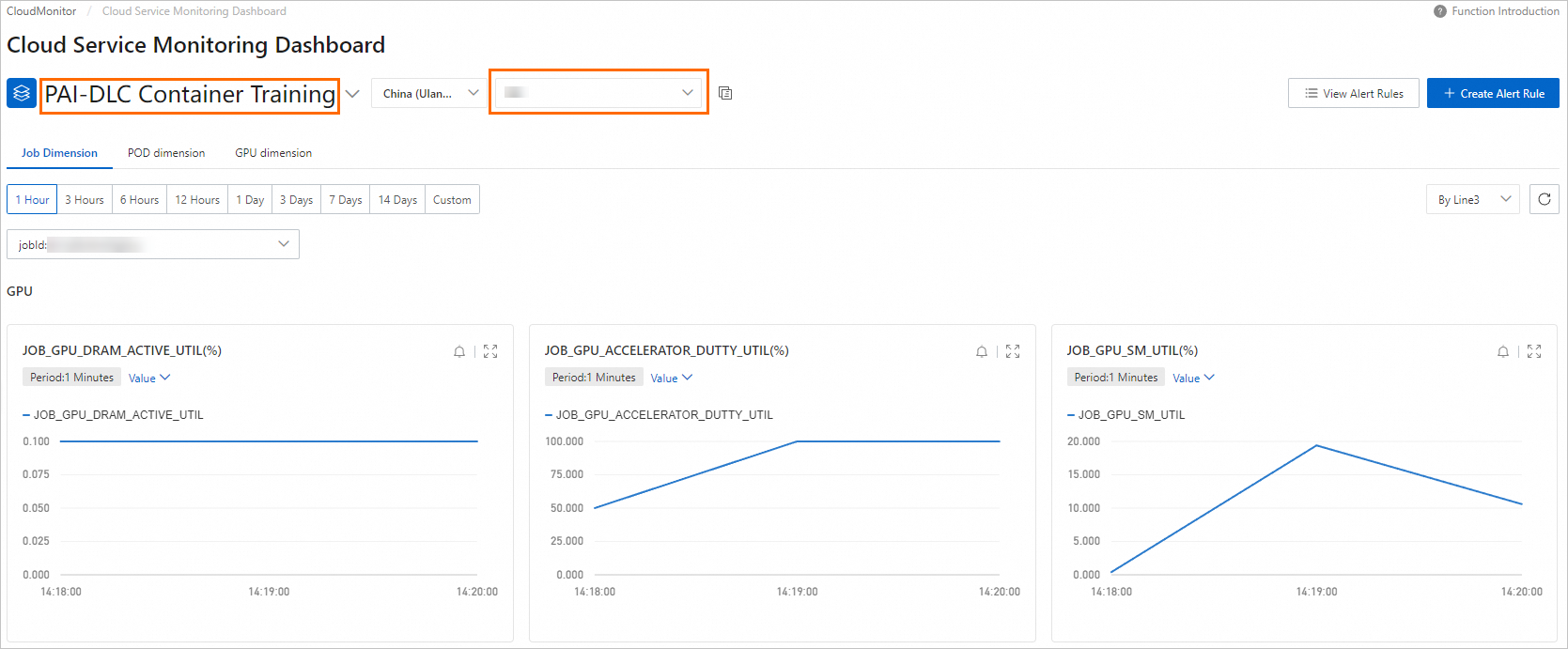 モニタリングチャートで利用可能な操作:
モニタリングチャートで利用可能な操作:-
モニタリングディメンションの切り替え:ジョブ、Pod、GPU の各レベルでメトリクスを表示します。
-
ジョブディメンション タブをクリックします。DLC ジョブ ID を選択または入力して、特定のジョブのモニタリングデータを表示します。
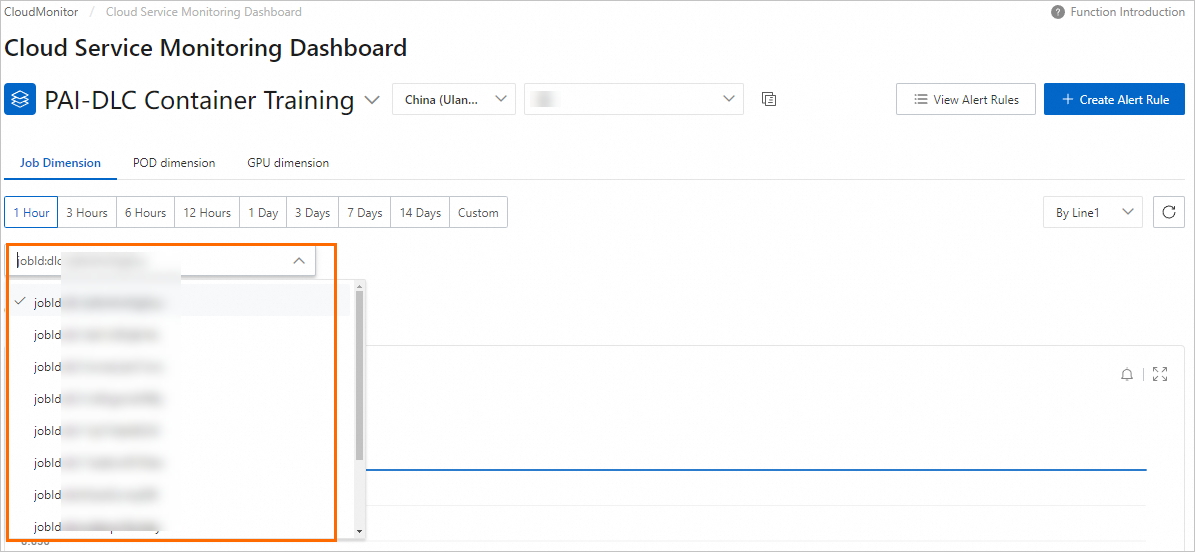
-
Pod ディメンション タブをクリックします。Pod ID を選択または入力して、特定の Pod のモニタリングデータを表示します。
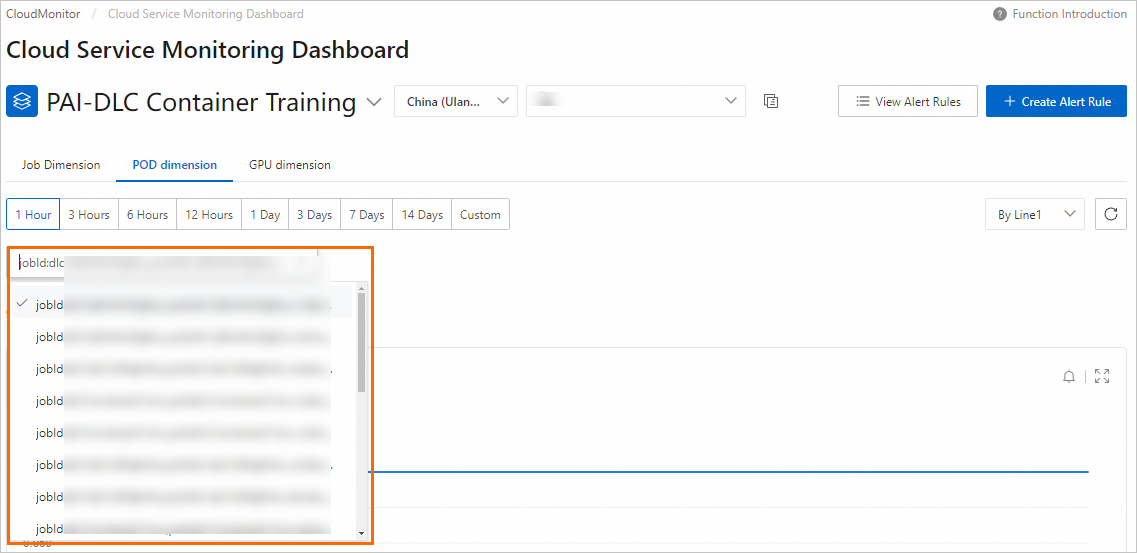
-
GPU ディメンション タブをクリックします。Pod ID を選択または入力して、指定された DLC ジョブ内の Pod に関する GPU 固有のモニタリングデータを表示します。
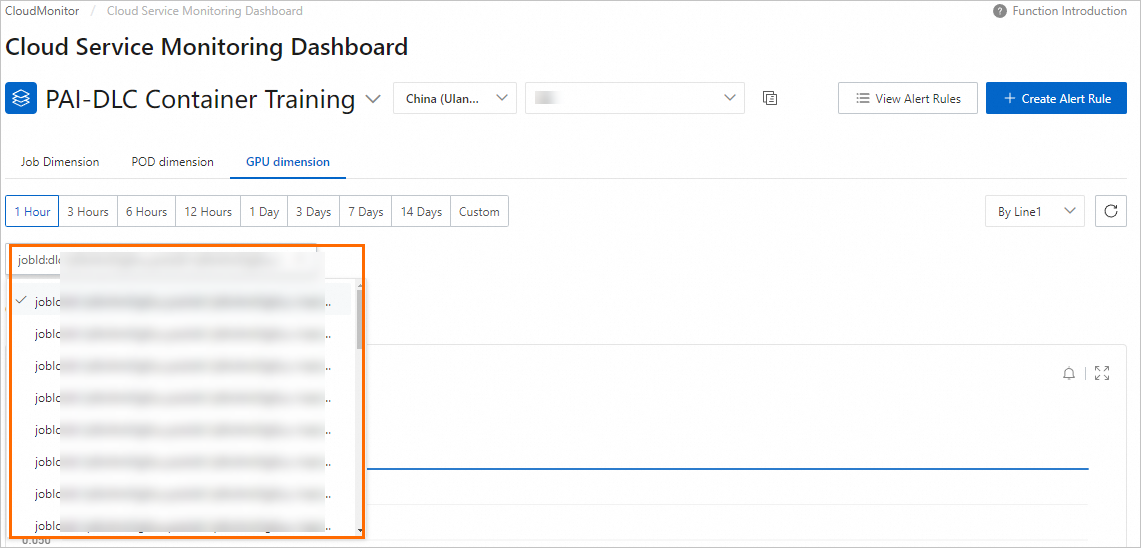
-
-
時間範囲の切り替え:

-
拡大表示:各チャートの右上隅にある拡大ボタン
 をクリックして、モニタリングデータの詳細を表示します。
をクリックして、モニタリングデータの詳細を表示します。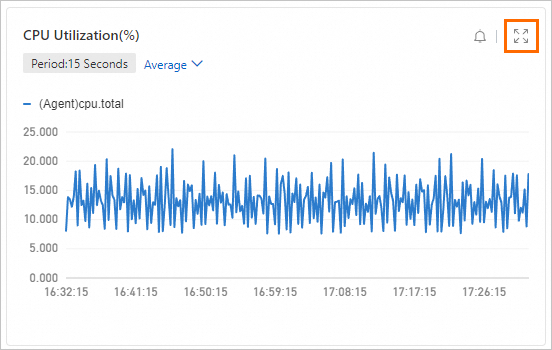
-
アラートの設定
DLC ジョブのリソース使用量をモニタリングするためのアラートルールを設定します。しきい値を超えた場合に通知を受け取れます。アラートは Cloud Monitor コンソールまたは API を使用して設定できます。
アラート連絡先の設定
-
Cloud Monitor コンソール にログインします。
左側のナビゲーションウィンドウで、 を選択します。
アラート連絡先 タブで、連絡先の作成 をクリックします。アラート連絡先の名前、携帯電話番号、メールアドレス、または Webhook URL を入力し、OK をクリックします。
アラートグループ タブで、連絡先グループの作成 をクリックします。アラート連絡先グループの名前を入力し、既存のアラート連絡先を選択します。 次に、OK をクリックします。
アラートルールの設定
-
CloudMonitor コンソールの左側にあるナビゲーションウィンドウで、を選択します。
-
「[クラウドサービスモニター]」ページで、PAI-Deep Learning Containers (DLC) を検索して移動します。
-
PAI-Deep Learning Containers (DLC) ページで、サービスが展開されているリージョンを選択し、アラートルールの作成 をクリックします。
-
アラートルールの作成 パネルで、パラメーターを設定し、確認 をクリックします。
パラメーター
説明
製品
Cloud Monitor が管理するプロダクトです。PAI-Deep Learning Containers (DLC) を選択します。
適用範囲
アラートルールの適用範囲です。「すべてのリソース」と「インスタンス」をサポートしています。
-
すべてのリソース:任意の DLC リソースがアラートルールを満たす場合にアラートが送信されます。
-
インスタンス:必要なワークスペースを 関連インスタンス に追加します。追加されたワークスペース内の DLC ジョブがアラートルールを満たした場合にのみアラートが送信されます。
ルールの説明
アラートルールの条件です。モニタリングデータが指定された条件を満たすとアラートがトリガーされます。詳細については、「アラートルールの作成」をご参照ください。
ミュート期間
アラートが解決されないまま継続している場合の、繰り返しのアラート通知の間隔です。
有効期間
アラートルールが有効となる期間です。この期間内でのみ、アラートのチェックが実行されます。
タグ
アラートルールのカスタムタグです。タグはキーと値から構成されます。
アラート連絡先グループ
通知を受信するアラートグループです。アラート連絡先が設定済みのグループを選択してください。
-
-
PAI-Deep Learning Containers (DLC) ページで、アラートルールの表示 をクリックして、詳細およびアラート履歴を確認します。必要に応じてルールを変更できます。
アラート履歴の表示、アラートテンプレートの管理、アラートルールおよびアラート連絡先の設定など、アラートサービス関連の API を呼び出して設定できます。詳細については、「Cloud Monitor API リファレンス:アラートサービス」をご参照ください。
メトリクスのサブスクライブ
Cloud Monitor の API を呼び出して DLC のモニタリングメトリクスをサブスクライブし、カスタムモニタリングシステムおよびダッシュボードを構築できます。詳細については、「クラウドサービスモニタリング API リファレンス」をご参照ください。
|
Cloud Monitor API |
説明 |
|
指定されたメトリクスの最新のモニタリングデータを照会します。 |
|
|
指定されたクラウドサービスの指定メトリクスのモニタリングデータを照会します。 |
|
|
指定されたクラウドサービスのメトリクスのモニタリングデータを照会します。 |
|
|
Cloud Monitor で利用可能なメトリクスの詳細を照会します。 |
|
|
Cloud Monitor で時系列メトリクスをサポートするクラウドサービスを照会します。 |
|
|
クラウドサービスの指定メトリクスについて最新のモニタリングデータを照会し、その後、並べ替えられたモニタリングデータを照会します。 |
この例では、DescribeMetricList API を使用して、指定された PAI-DLC メトリクスのモニタリングデータを照会します。
-
Deep Learning Containers (DLC) メトリクス ページに移動します。
-
メトリクスページで対象のメトリクスを見つけ、メトリクスデータの取得 を 操作 列からクリックします。

-
OpenAPI Explorer ページで、主要なパラメーターを設定し、その他のパラメーターはデフォルト値を使用します。パラメーターの詳細については、「DescribeMetricList」をご参照ください。
パラメーター
説明
Namespace
このパラメーターを acs_pai_dlc に設定します。
MetricName
対応するモニタリングメトリクスに設定します(例:CARD_GPU_DRAM_ACTIVE_UTIL)。
StartTime
開始時刻(例:2024-05-15 00:00:00)。
EndTime
終了時刻(例:2024-05-28 00:00:00)。
説明StartTime と EndTime の間隔は 31 日を超えてはいけません。
-
パラメーターを設定後、呼び出しの実行 をクリックして、指定された時間範囲のモニタリングデータを表示します。
ARMS の使用
ARMS は Alibaba Cloud の可観測性プラットフォームです。PAI-DLC 分散トレーニング向けに Grafana ダッシュボードをカスタマイズし、Prometheus のアラートルールを設定して、ジョブの各メトリクスを詳細にモニタリングできます。詳細については、「Application Real-Time Monitoring Service (ARMS)」をご参照ください。
課金
ARMS は課金対象です。詳細については、「ARMS の課金」をご参照ください。
モニタリングデータの取り込み
以下の手順に従ってモニタリングデータを取り込みます:
-
ARMS コンソール にログインします。ナビゲーションウィンドウで、インテグレーションセンター をクリックします。
-
インテグレーションセンター ページで、人工知能 タブをクリックし、次に Alibaba Cloud PAI-DLC 分散トレーニングサービス をクリックします。

-
プロビジョニングの開始 タブで、データ保存リージョン を選択し、インテグレーション名 を指定して、確認 をクリックします。
プロビジョニングには 1~2 分かかります。効果のプレビュー、収集されたメトリクス、または アラートルールテンプレート タブを選択して、ダッシュボード、メトリクス、アラートテンプレートを表示できます。
-
インストール完了後、プロビジョニング をクリックして環境の詳細を表示します。
Grafana ダッシュボードの表示
-
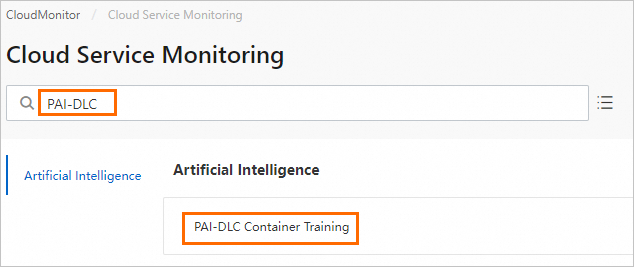
ARMS コンソール にログインします。左側のナビゲーションウィンドウで、プロビジョニング を選択します。プロビジョニング済み環境 > クラウドサービスリージョン環境 タブで、環境名をクリックします。
-
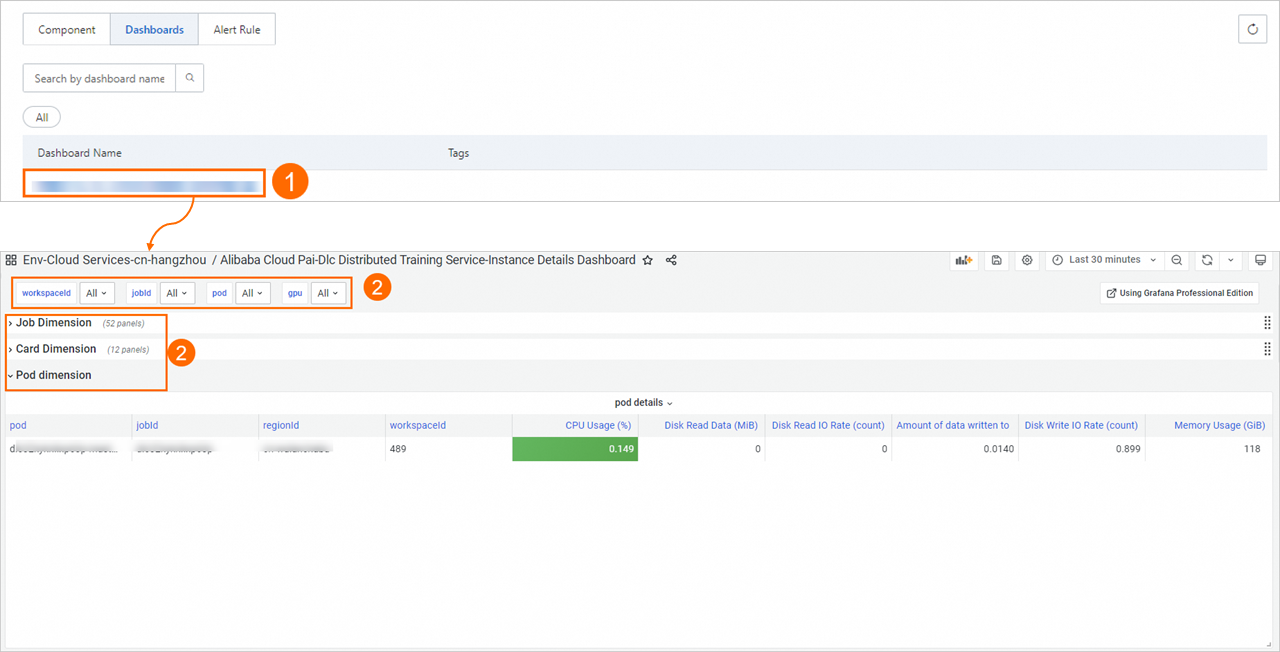
コンポーネント管理 タブの コンポーネントタイプ エリアで、Alibaba Cloud PAI-DLC 分散トレーニングサービスを選択し、ダッシュボード をクリックして、組み込みの Grafana ダッシュボードを表示します。
-
ダッシュボード名をクリックして、モニタリングダッシュボードを表示します。
Prometheus アラートの設定
Prometheus アラートを設定するには、以下の手順を実行します:
-
ARMS コンソール にログインします。左側のナビゲーションウィンドウで、プロビジョニング を選択します。プロビジョニング済み環境 > クラウドサービスリージョン環境 タブで、環境名をクリックします。
-
「[コンポーネントの種類]」リスト(「[コンポーネント管理]」タブ内)で、Alibaba Cloud PAI-DLC 分散学習サービスを選択し、「[アラートルール]」をクリックして、組み込みアラートルールを表示します。
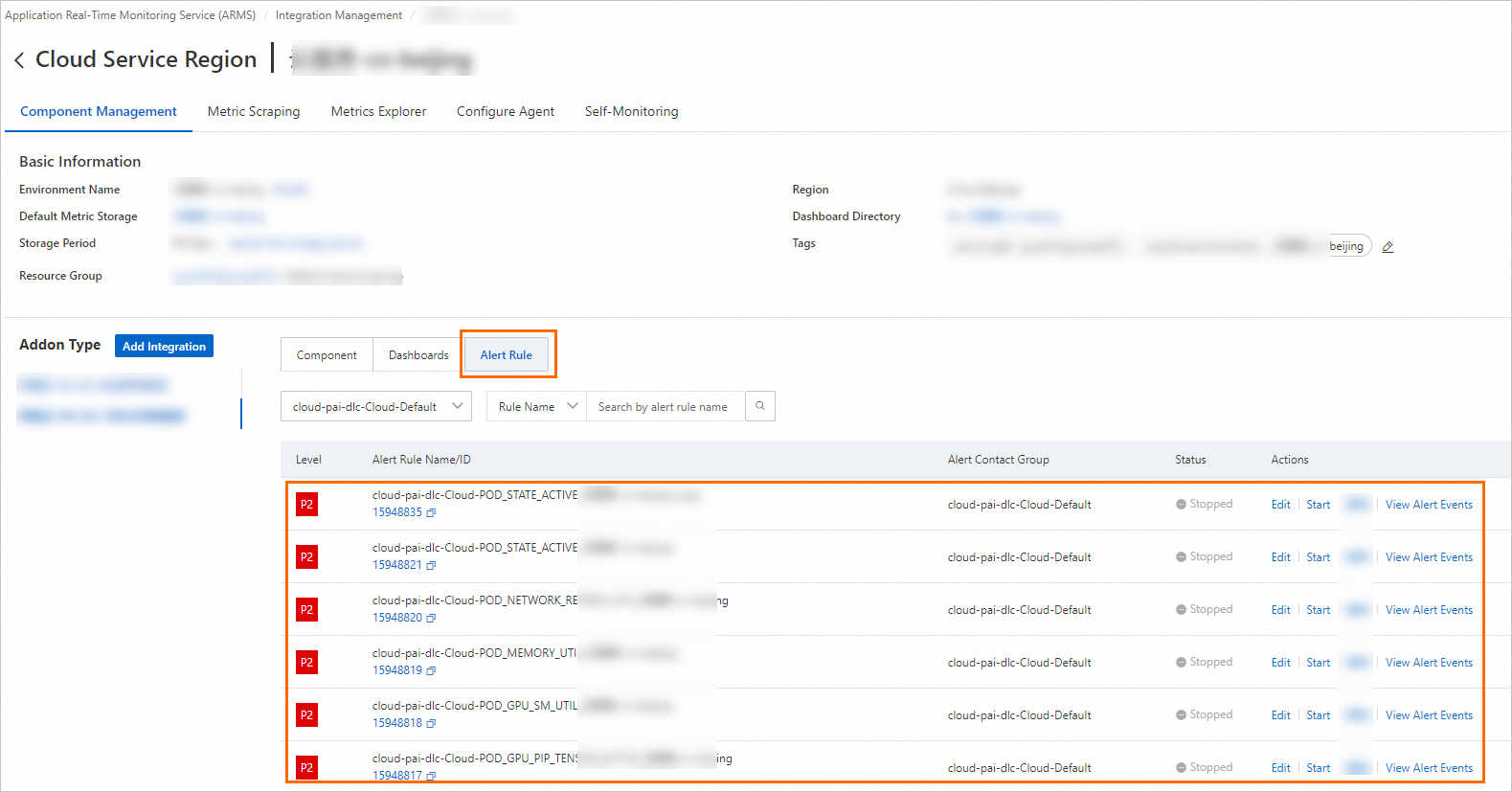
-
組み込みのアラートルールはイベントを生成しますが、通知は送信しません。メールやその他のプラットフォーム経由で通知を送信するには、以下のいずれかの方法を使用します:
-
通知ポリシーを設定して、アラートイベントに一致するルールを作成します。ルールがトリガーされると、システムは指定された受信者に対して、指定された方法でアラートを送信します。詳細については、「通知ポリシー」をご参照ください。
-
アラートルールを編集して、通知方法を設定します。
 Prometheus アラートルール編集ページで、アラート条件、持続時間、内容、通知をカスタマイズします。詳細については、「Prometheus アラートルールの作成」をご参照ください。
Prometheus アラートルール編集ページで、アラート条件、持続時間、内容、通知をカスタマイズします。詳細については、「Prometheus アラートルールの作成」をご参照ください。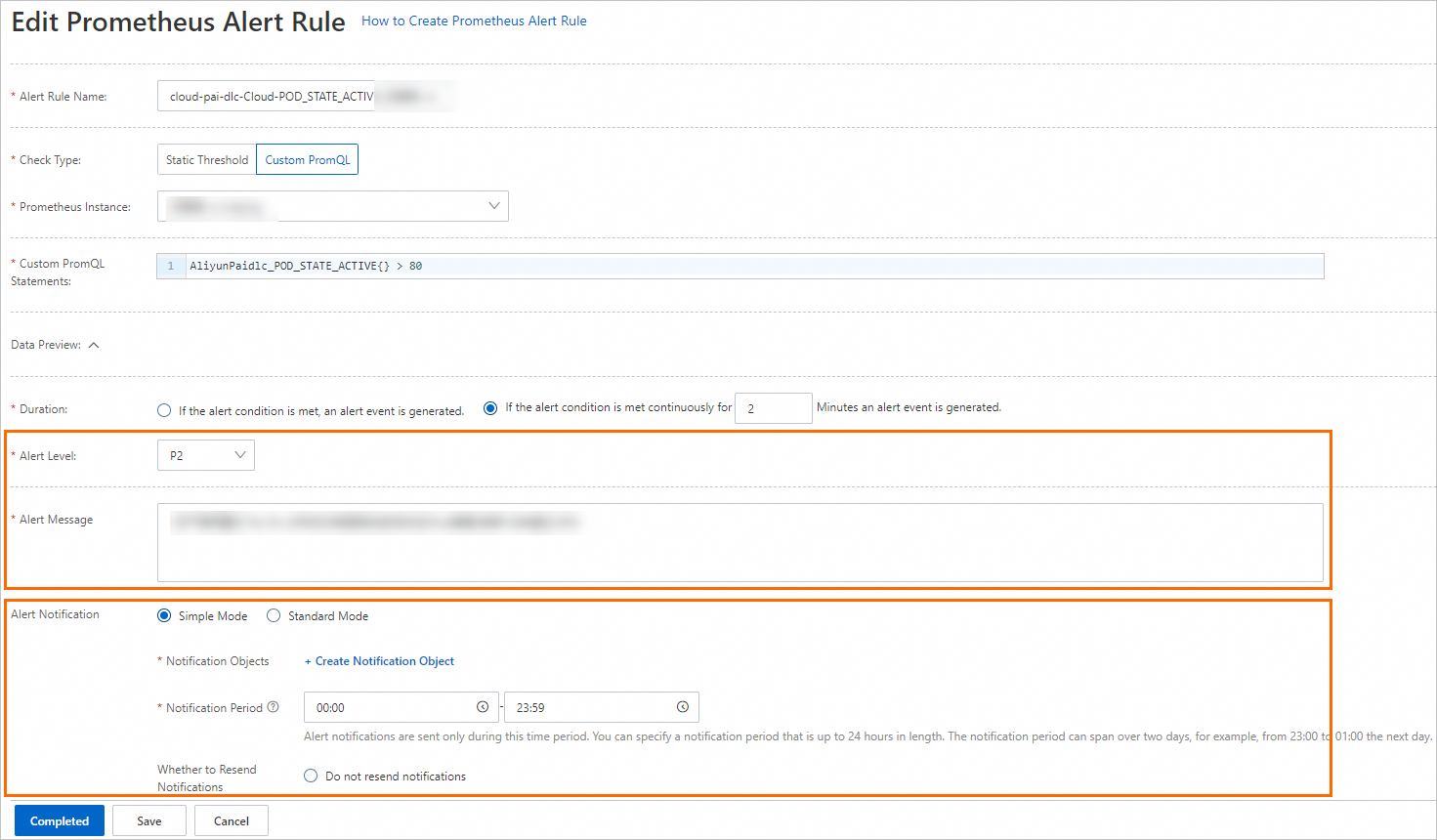
-