このドキュメントでは、DLC 上でオープンソースツール DataJuicer を使用して、大規模なマルチモーダルデータを処理する方法について説明します。
DataJuicer
DataJuicer の概要
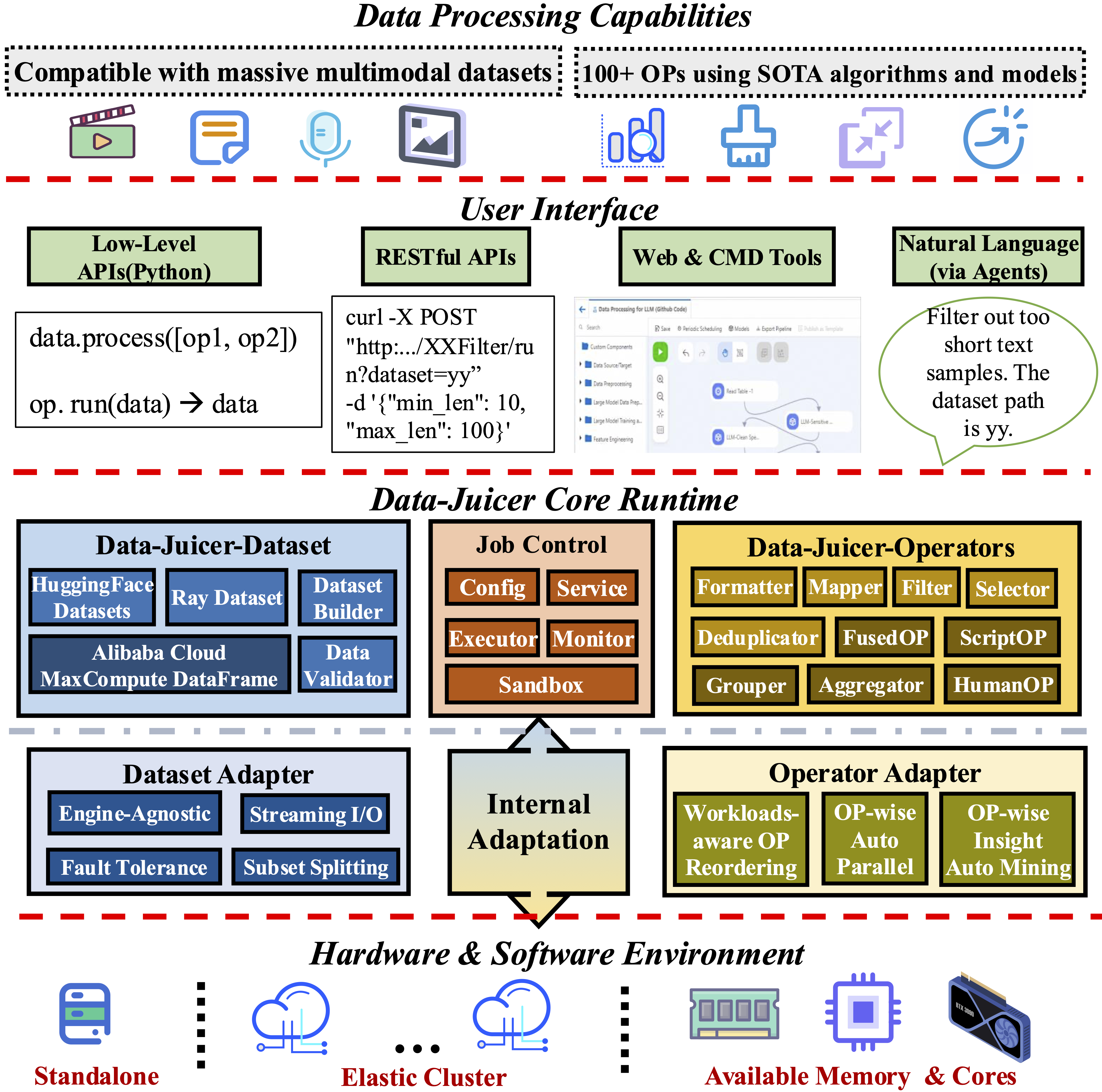
DataJuicer は、テキスト、イメージ、オーディオ、ビデオなどの大規模なマルチモーダルデータを処理するためのオープンソースツールキットです。豊富なオペレーターセット、効率的な分散処理、柔軟な構成により、データのクリーニング、変換、拡張を簡素化します。DataJuicer は、大規模言語モデル (LLM) およびマルチモーダルモデルのトレーニングデータ準備を最適化するように設計されています。
DataJuicer タスクの構成
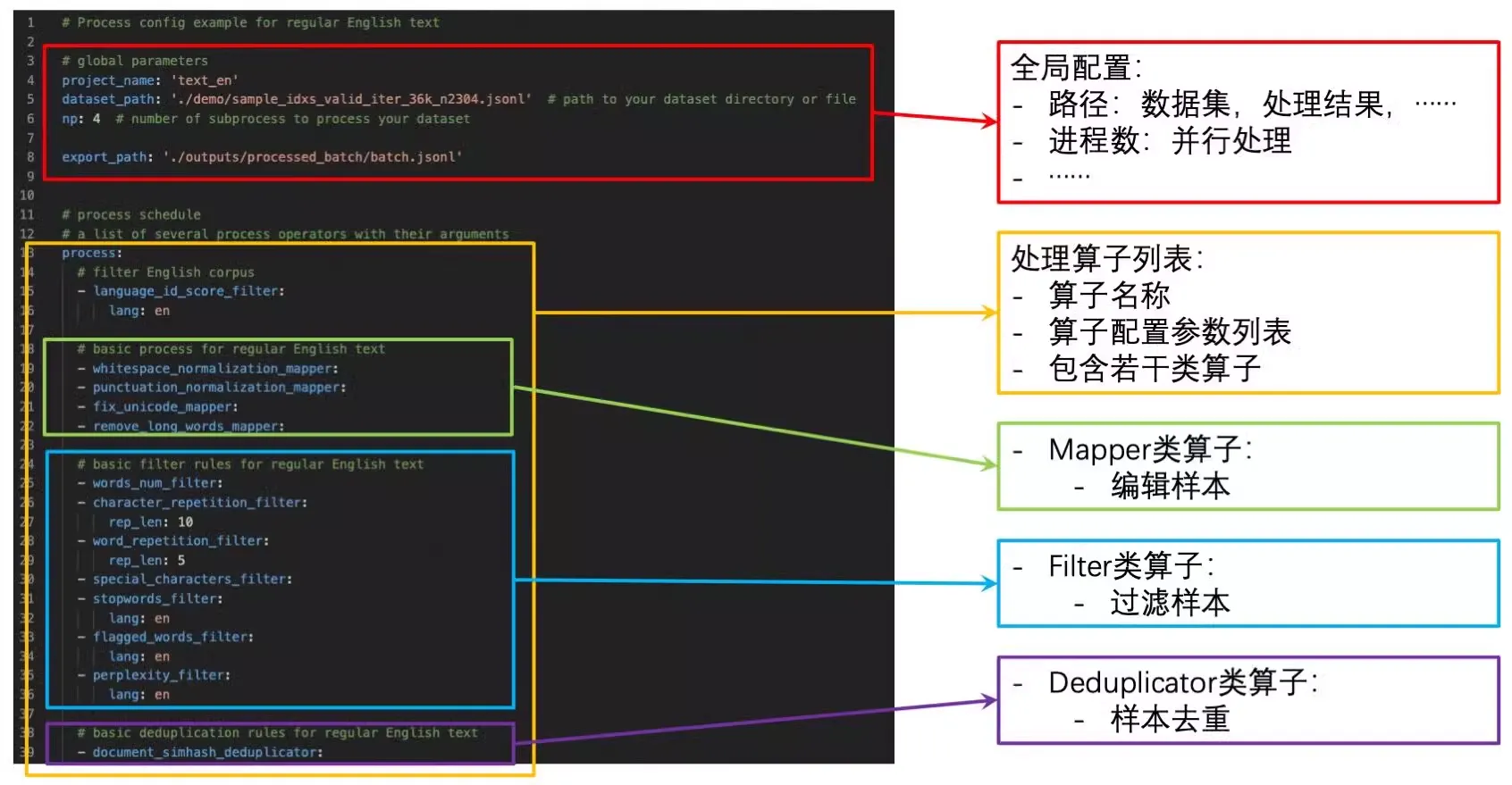
DataJuicer は YAML 構成ファイルを使用して、データ処理ワークフロー全体を整理および管理します。単一の構成ファイル内で、グローバルパラメーターと順次実行される一連のオペレーターを定義できます。
process.yaml という名前の構成ファイルの例を次に示します。
データセットを処理するには、process_data.py スクリプトまたは dj-process コマンドラインツールを実行し、構成ファイルのパスを引数として指定します。
# ソースからのインストール用
python tools/process_data.py --config configs/demo/process.yaml
# コマンドラインツールの使用
dj-process --config configs/demo/process.yaml主要なパラメーターの説明
dataset_path: 入力データへのパス。DLC タスクの場合、このパラメーターを Object Storage Service (OSS) などのデータストレージがコンテナー内にマウントされているパスに設定します。export_path: 処理結果の出力パス。分散タスクの場合、このパスは特定のファイルではなく、ディレクトリである必要があります。executor_type: エグゼキュータのタイプ。default:DefaultExecutorを使用してシングルノードで実行します。ray:RayExecutorを使用します。これは分散処理をサポートします。詳細については、「Data-Juicer 分散データ処理」をご参照ください。
オペレーター
オペレーターは、特定のデータ処理タスクを実行する DataJuicer の基本単位です。DataJuicer は、アグリゲーター、デデュプリケーター、フィルター、フォーマッター、グルーパー、マッパー、セレクターなど、100 以上のオペレーターを提供します。詳細については、「オペレータースキーマ」をご参照ください。
config_all.yaml ファイルには、すべてのオペレーターの構成が含まれています。
参考資料
タスク構成ファイルの作成方法については、「構成ファイルの作成」をご参照ください。
完全な構成ファイルについては、「config_all.yaml」をご参照ください。
詳細については、「DataJuicer 公式ドキュメント」および「DataJuicer GitHub リポジトリ」をご参照ください。
DLC で DataJuicer タスクを実行する
DLC は DataJuicer をネイティブにサポートしています。タスクを作成するときは、[フレームワーク] を DataJuicer に設定して、このタイプのタスクを作成します。
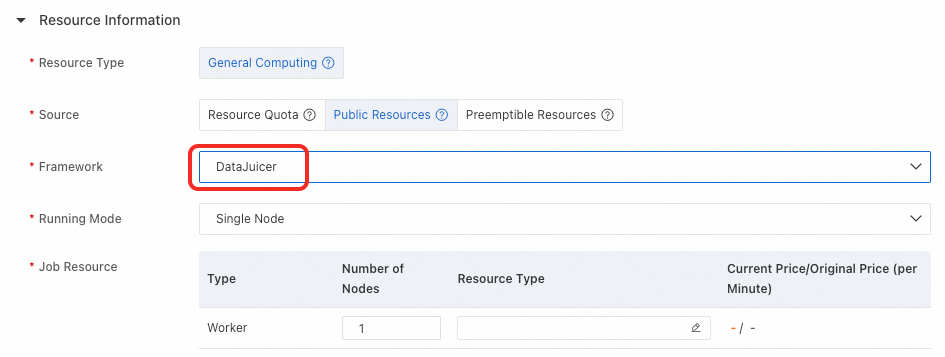
実行モード
DLC タスクを作成するときは、構成ファイルの executor_type と一致する実行モードを選択します。
シングルノードモード:
DataJuicer 構成ファイル: 構成ファイルで、
executor_typeをdefaultに設定するか、フィールドを省略します。DLC 構成:
[実行モード] を [シングルノード] に設定します。
[ノード数] を 1 に設定します。
分散モード:
DataJuicer 構成ファイル: 構成ファイルで、
executor_typeをrayに設定します。DLC 構成:
[実行モード] を [分散] に設定します。
ノード数: Head ノードの数は 1 である必要があり、Worker ノードの数は 1 以上である必要があります。
リソース仕様: Head ノードには 8 GB 以上のメモリが必要です。Worker ノードのリソースは必要に応じて構成できます。
フォールトトレランスと診断 (オプション): 同じ VPC (virtual private cloud) 内の Redis インスタンスを選択して、ヘッドノードのフォールトトレランス を構成できます。
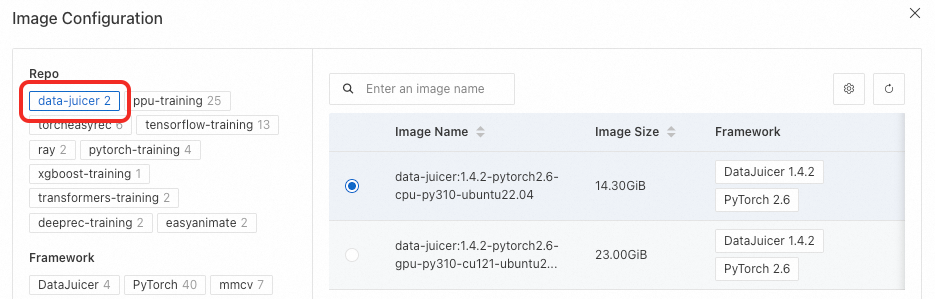
イメージ要件
DataJuicer タスクのイメージには、DataJuicer 環境がプリインストール済みで、dj-process コマンドが含まれている必要があります。data-juicer リポジトリの公式イメージ、または公式 data-juicer イメージに基づくカスタムイメージを使用できます。
起動コマンド

DLC は、Shell および YAML フォーマットの起動コマンドをサポートしています。デフォルトのフォーマットは Shell です。コマンドフォーマットが Shell の場合、使用方法は他の DLC タスクと同じです。コマンドフォーマットが YAML の場合、コマンドラインで DataJuicer 構成を直接入力できます。
起動コマンドの例を次に示します。
Shell フォーマットの例 1: 構成を一時ファイルに書き込み、
dj-processコマンドを使用してタスクを開始します。Shell フォーマットの例 2: 構成ファイルを OSS などのクラウドストレージに保存します。ファイルを DLC コンテナーにマウントします。
dj-processコマンドでマウントされた構成ファイルのパスを指定してタスクを実行します。dj-process --config /mnt/data/process_on_ray/config/demo.yamlYAML フォーマットの例: コマンドラインで DataJuicer 構成を直接入力します。
オペレーターに必要なモデル
多くの DataJuicer オペレーターは外部モデルに依存しています。モデルがローカルで利用できない場合、オペレーターは最初の実行時に自動的にダウンロードするため、実行時間が増加する可能性があります。
繰り返しのダウンロードを避けるため、DataJuicer タスクはデフォルトモデルを自動的に処理します。タスクはデフォルトモデルを /ml/data-juicer/models/ ディレクトリにマウントし、DATA_JUICER_EXTERNAL_MODELS_HOME 環境変数を設定します。したがって、デフォルトモデルを手動でダウンロードする必要はありません。