PyAlink スクリプトは、コードを通じて Alink アルゴリズムを呼び出し、分類、回帰、レコメンデーションタスクを実行します。このコンポーネントは、他の Designer コンポーネントと統合して、ビジネスワークフローを構築および検証します。
概要
PyAlink スクリプトは、スタンドアロンモード、または他の Designer コンポーネントと組み合わせたモードの 2 つのモードで動作します。このコンポーネントは、数百の Alink アルゴリズムをサポートし、コードを通じてさまざまなデータ型を読み書きします。詳細は、「データの読み書きタイプ」をご参照ください。PyAlink スクリプトによって生成された PipelineModel モデルは、Elastic Algorithm Service (EAS) サービスとしてデプロイできます。詳細は、「モデルを EAS サービスとしてデプロイ」をご参照ください。
用語
PyAlink スクリプトを使用する前に、これらの用語を理解しておいてください。
機能モジュール | 説明 |
オペレーター | Alink の各アルゴリズム機能はオペレーターです。オペレーターはバッチタイプとストリーミングタイプに分かれています。例えば、ロジスティック回帰には以下が含まれます。
オペレーターは Link または LinkFrom を使用して接続します。 各オペレーターには設定可能なパラメーターがあります。ロジスティック回帰のパラメーターには以下が含まれます。
パラメーターは `set` の後にパラメーター名を続けて設定します。 データのインポート (ソース) とエクスポート (シンク) は、特殊なオペレータータイプです。これらは Link または LinkFrom を使用してアルゴリズムコンポーネントに接続します。  Alink には、一般的なストリーミングおよびバッチデータソースが含まれています。例: |
パイプライン | パイプラインは、データ処理、特徴量エンジニアリング、モデルトレーニングを組み合わせて、トレーニング、予測、オンラインサービスを提供します。 |
ベクター | Alink は 2 種類のカスタムベクターデータ形式をサポートしています。
説明 ベクター型の列では、パラメーター名 `vectorColName` を使用します。 |
サポートされるコンポーネント
PyAlink スクリプトは、データ処理、特徴量エンジニアリング、モデルトレーニングのための数百の Alink コンポーネントをサポートしています。
PyAlink スクリプトは、パイプラインコンポーネントとバッチコンポーネントのみをサポートします。ストリームコンポーネントはサポートされていません。
スタンドアロンでの使用
この例では、Designer 上の PyAlink スクリプトを使用して、ItemCf モデルで MovieLens データセットをスコアリングします。
Designer を開き、空のパイプラインを作成します。詳細は、「操作手順」をご参照ください。
ワークフローリストでパイプラインを見つけ、[ワークフローに入る] をクリックします。
コンポーネントリストから [PyAlink スクリプト] をキャンバスにドラッグして、PyAlink スクリプト-1 を作成します。
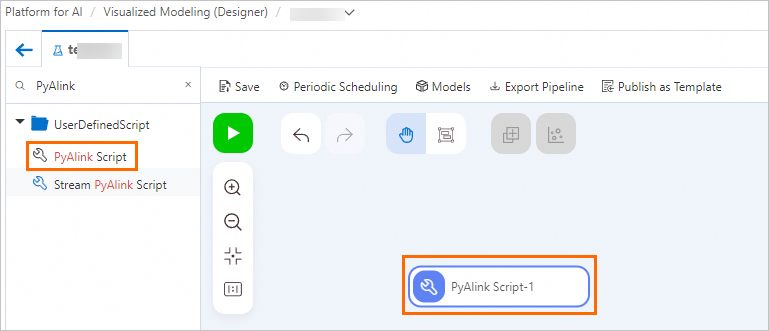
PyAlink スクリプト-1 を選択します。[パラメーター設定] タブと [実行チューニング] タブでパラメーターを設定します。
[パラメーター設定] タブで、コードを入力します。
from pyalink.alink import * def main(sources, sinks, parameter): PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/" RATING_FILE = "ratings.csv" PREDICT_FILE = "predict.csv" RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long" ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) predictData = CsvSourceBatchOp() \ .setFilePath(PATH + PREDICT_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) itemCFModel = ItemCfTrainBatchOp() \ .setUserCol("user_id").setItemCol("item_id") \ .setRateCol("rating").linkFrom(ratingsData); itemCF = ItemCfRateRecommender() \ .setModelData(itemCFModel) \ .setItemCol("item_id") \ .setUserCol("user_id") \ .setReservedCols(["user_id", "item_id"]) \ .setRecommCol("prediction_score") result = itemCF.transform(predictData) result.link(sinks[0]) BatchOperator.execute()PyAlink スクリプトには 4 つの出力ポートがあります。コード
result.link(sinks[0])は、出力データを最初のポートに書き込みます。ダウンストリームコンポーネントは、このポートに接続してデータを読み取ります。詳細は、「データの読み書きタイプ」をご参照ください。[実行チューニング] タブで、実行モードとノードスペックを設定します。
パラメーター
説明
ジョブ実行モードの選択
実行モード:
DLC (単一ノード複数同時実行):テストおよび検証中の小規模データセット向け。
MaxCompute (分散):大規模データセットまたは本番タスク向け。
フルマネージド Flink (分散):ワークスペースにアタッチされた Flink クラスターリソースを分散実行に使用します。
ワーカー数
[ジョブ実行モードの選択] が [MaxCompute (分散)] または [フルマネージド Flink (分散)] の場合に必須です。ワーカー数を指定します。デフォルト:Empty (システムがタスクデータに基づいて割り当てます)。
ワーカーあたりのメモリ (MB)
[ジョブ実行モードの選択] が [MaxCompute (分散)] または [フルマネージド Flink (分散)] の場合に必須です。ワーカーのメモリを MB 単位で指定します (正の整数)。デフォルト:8192。
ノードあたりの CPU コア数
[ジョブ実行モードの選択] が [MaxCompute (分散)] または [フルマネージド Flink (分散)] の場合に必須です。ワーカーあたりの CPU コア数を指定します (正の整数)。デフォルト:Empty。
スクリプトのノードスペックを選択
DLC ノードのリソースタイプ。デフォルト:2 vCPU + 8 GB Mem-ecs.g6.large。
[保存] をクリックし、実行ボタン
 をクリックしてスクリプトを実行します。
をクリックしてスクリプトを実行します。タスクが完了したら、PyAlink スクリプト-1 を右クリックします。 を選択して結果を表示します。
列名
説明
user_id
ユーザー ID。
item_id
映画 ID。
prediction_score
ユーザーの映画に対するプリファレンススコア。映画のレコメンデーションに使用されます。
Designer コンポーネントとの組み合わせ
PyAlink スクリプトの入力ポートと出力ポートは、他の Designer コンポーネントと互換性があり、シームレスに統合できます。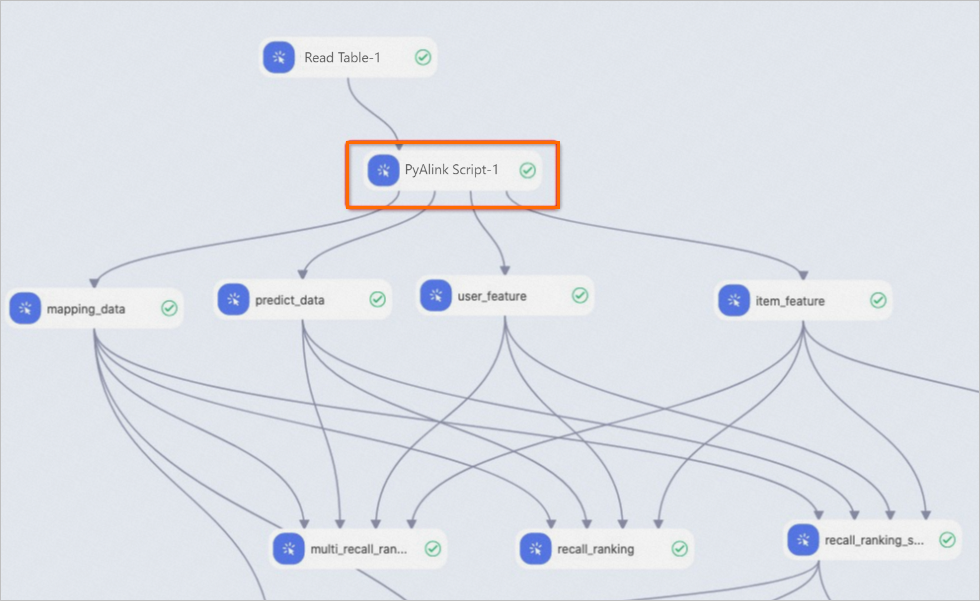
読み取りと書き込みのデータの型
データの読み取り
アップストリームコンポーネントの入力ポートから MaxCompute テーブルを読み取ります。
train_data = sources[0] test_data = sources[1]`sources[0]` は最初の入力ポートの MaxCompute テーブルを表し、`sources[1]` は 2 番目の入力ポートの MaxCompute テーブルを表します。最大 4 つの入力ポートをサポートします。
Alink ソースコンポーネント (CsvSourceBatchOp、AkSourceBatchOp) を使用して、ネットワークファイルシステムから読み取ります。サポートされているファイルタイプ:
HTTP ネットワーク共有ファイル:
ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING)OSS ネットワークファイル。図のように読み取りパスを設定します。
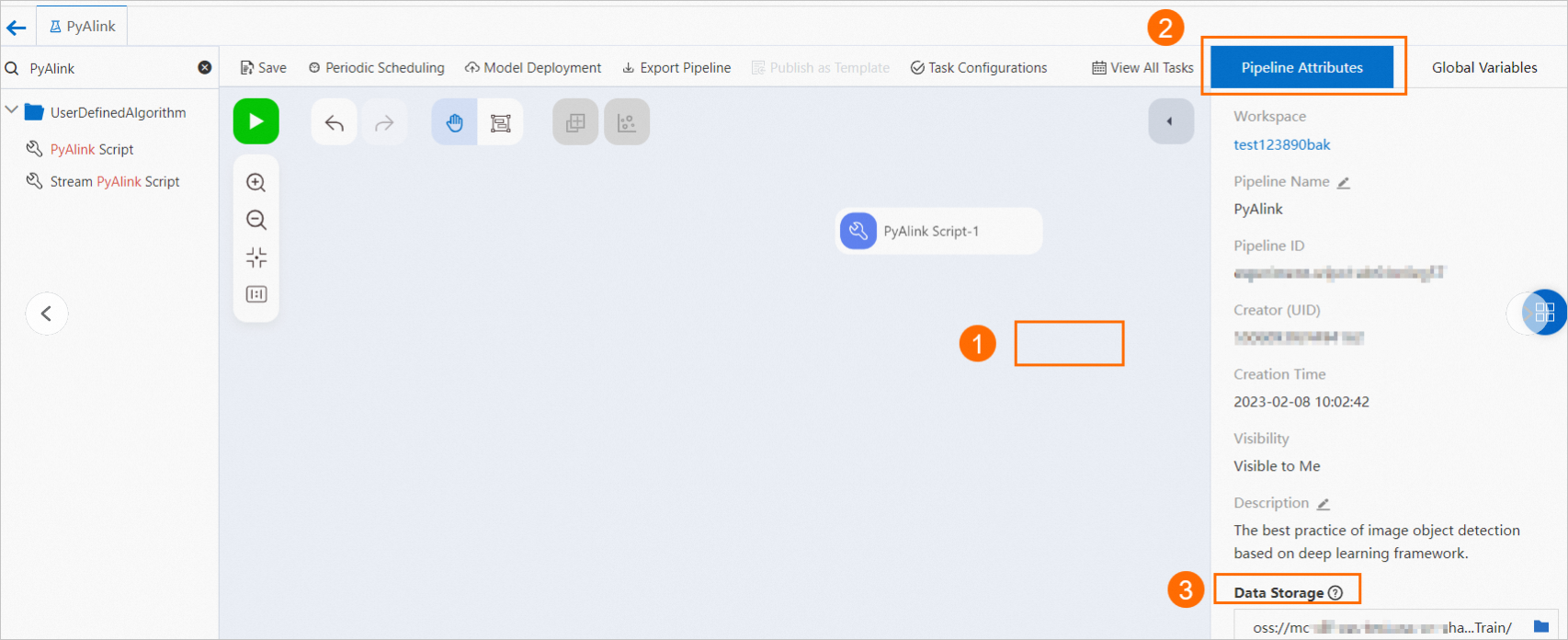
model_data = AkSourceBatchOp().setFilePath("oss://xxxxxxxx/model_20220323.ak")
データの書き込み
MaxCompute テーブルに書き込み、出力ポートを介してダウンストリームコンポーネントに渡します。
result0.link(sinks[0]) result1.link(sinks[1]) BatchOperator.execute()`result0.link(sinks[0])` は、データを最初の出力ポートに書き込みます。最大 4 つの出力ポートをサポートします。
OSS ネットワークファイルに書き込みます。図のように書き込みパスを設定します。
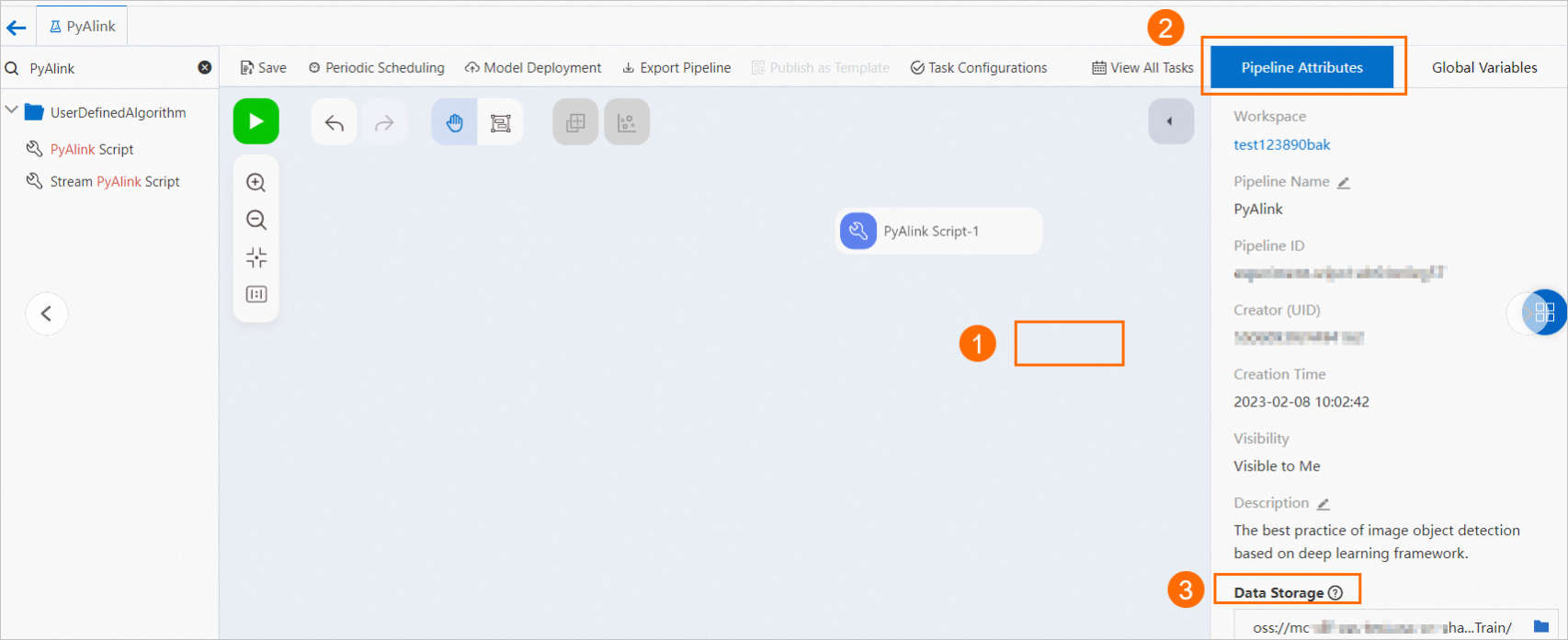
result.link(AkSinkBatchOp() \ .setFilePath("oss://xxxxxxxx/model_20220323.ak") \ .setOverwriteSink(True)) BatchOperator.execute()
モデルを EAS サービスとしてデプロイ
デプロイするモデルの生成
モデルが PipelineModel である場合にのみ、モデルを EAS サービスとしてデプロイできます。このコードを使用して PipelineModel ファイルを生成します。詳細は、「スタンドアロンでの使用」をご参照ください。
from pyalink.alink import * def main(sources, sinks, parameter): PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/" RATING_FILE = "ratings.csv" PREDICT_FILE = "predict.csv" RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long" ratingsData = CsvSourceBatchOp() \ .setFilePath(PATH + RATING_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) predictData = CsvSourceBatchOp() \ .setFilePath(PATH + PREDICT_FILE) \ .setFieldDelimiter("\t") \ .setSchemaStr(RATING_SCHEMA_STRING) itemCFModel = ItemCfTrainBatchOp() \ .setUserCol("user_id").setItemCol("item_id") \ .setRateCol("rating").linkFrom(ratingsData); itemCF = ItemCfRateRecommender() \ .setModelData(itemCFModel) \ .setItemCol("item_id") \ .setUserCol("user_id") \ .setReservedCols(["user_id", "item_id"]) \ .setRecommCol("prediction_score") model = PipelineModel(itemCF) model.save().link(AkSinkBatchOp() \ .setFilePath("oss://<your_bucket_name>/model.ak") \ .setOverwriteSink(True)) BatchOperator.execute()<your_bucket_name>は、ご利用の OSS バケット名です。重要PATH のデータセットパスに対する読み取り権限を確認してください。権限がない場合、コンポーネントの実行に失敗します。
EAS 設定ファイルの生成
このスクリプトを実行して、出力を `config.json` に書き込みます。
# EAS の設定ファイル import json # EAS のモデル設定を生成します。 model_config = {} # EAS が受け入れるデータのスキーマ。 model_config['inputDataSchema'] = "id long, movieid long" model_config['modelVersion'] = "v0.2" eas_config = { "name": "recomm_demo", "model_path": "http://xxxxxxxx/model.ak", "processor": "alink_outer_processor", "metadata": { "instance": 1, "memory": 2048, "region":"cn-beijing" }, "model_config": model_config } print(json.dumps(eas_config, indent=4))`config.json` の主要なパラメーター:
name:モデルサービス名。
model_path:PipelineModel ファイルを格納する OSS パス。実際のパスに置き換えてください。
その他の `config.json` パラメーターについては、「コマンドリファレンス」をご参照ください。
モデルを EAS サービスとしてデプロイ
eascmd クライアントにログインして、モデルサービスをデプロイします。詳細は、「クライアントのダウンロードと認証」をご参照ください。Windows 64 ビットシステムの場合は、次のコマンドを使用します。
eascmdwin64.exe create config.json