PS-SMART 回帰は、パラメーターサーバー (PS) とスケーラブルな多重加法回帰木 (SMART) を組み合わせた機械学習アルゴリズムです。大規模データセットで効率的にモデルをトレーニングするように設計されています。PS-SMART は PS アーキテクチャを使用して分散システム上で実行され、数百億のサンプルと数十万の特徴をサポートします。このアルゴリズムは、勾配ブースティング決定木 (GBDT) の反復最適化や、ヒストグラム近似などの技術を使用して、トレーニング速度とリソース効率を向上させます。
制限事項
PS-SMART 回帰コンポーネントの入力データは、次の要件を満たす必要があります。
-
ターゲット列は数値型のみをサポートします。MaxCompute テーブルのデータが STRING 型の場合、型変換を実行する必要があります。
-
データがキーと値のフォーマットである場合、特徴 ID は正の整数、特徴値は実数である必要があります。特徴 ID が STRING 型の場合、シリアル化コンポーネントを使用してデータをシリアル化できます。特徴値がカテゴリカルな文字列の場合、特徴の離散化などの特徴エンジニアリングを実行できます。
-
PS-SMART 回帰コンポーネントは数十万の特徴を持つタスクをサポートしますが、これらのタスクは大量のリソースを消費し、実行が遅くなります。代わりに GBDT アルゴリズムをトレーニングに使用できます。GBDT アルゴリズムは、連続特徴で直接トレーニングするのに適しています。GBDT アルゴリズムを使用する場合、カテゴリカル特徴にワンホットエンコーディングを実行して低頻度特徴を除外できますが、他の連続数値特徴に対しては離散化を実行しないでください。
-
PS-SMART アルゴリズムはランダム性を導入する可能性があります。たとえば、data_sample_ratio と fea_sample_ratio で表されるデータと特徴のサンプリングでランダム性が発生する可能性があります。また、アルゴリズムが使用するヒストグラム近似最適化や、ローカルスケッチをグローバルスケッチにマージする際のシーケンシャルなランダム性でも発生する可能性があります。複数のワーカーでタスクを分散して実行すると木構造が異なる場合がありますが、モデルのパフォーマンスは理論的には類似しています。同じデータとパラメーターを使用して複数回実行した場合に一貫性のない結果が得られるのは正常です。
-
トレーニングを高速化するには、[コンピューティングコア数] を増やします。PS-SMART アルゴリズムは、リクエストされたすべてのリソースが割り当てられた後にのみトレーニングを開始します。したがって、クラスターがビジー状態の場合、より多くのリソースをリクエストすると待機時間が増加します。
注意事項
PS-SMART 回帰コンポーネントを使用する際は、次の点にご注意ください。
-
PS-SMART 回帰コンポーネントは数十万の特徴を持つタスクをサポートしますが、これらのタスクは大量のリソースを消費し、実行が遅くなります。代わりに GBDT アルゴリズムをトレーニングに使用できます。GBDT アルゴリズムは、連続特徴で直接トレーニングするのに適しています。GBDT アルゴリズムを使用する場合、カテゴリカル特徴にワンホットエンコーディングを実行して低頻度特徴を除外できますが、他の連続数値特徴に対しては離散化を実行しないでください。
-
PS-SMART アルゴリズムはランダム性を導入する可能性があります。たとえば、data_sample_ratio と fea_sample_ratio で表されるデータと特徴のサンプリングでランダム性が発生する可能性があります。また、アルゴリズムが使用するヒストグラム近似最適化や、ローカルスケッチをグローバルスケッチにマージする際のシーケンシャルなランダム性でも発生する可能性があります。複数のワーカーでタスクを分散して実行すると木構造が異なる場合がありますが、モデルのパフォーマンスは理論的には類似しています。同じデータとパラメーターを使用して複数回実行した場合に一貫性のない結果が得られるのは正常です。
-
トレーニングを高速化するには、[コンピューティングコア数] を増やすことができます。ただし、PS-SMART アルゴリズムは、リクエストされたすべてのリソースが割り当てられた後にのみトレーニングを開始します。したがって、クラスターがビジー状態のときにリソースを多くリクエストすると、待機時間が増加します。
コンポーネント設定
方法1:ビジュアルインターフェイスの使用
PS-SMART 回帰コンポーネントを Designer キャンバスに追加し、右側のペインでそのパラメーターを設定できます。
|
パラメータータイプ |
パラメーター |
説明 |
|
フィールド設定 |
スパースフォーマット |
スパース形式の キーと値のペア はスペースで区切ります。キー と 値 はコロン (:) で区切ります。例:1:0.3 3:0.9。 |
|
特徴列の選択 |
トレーニングに使用される入力テーブルの特徴列。入力データが密形式の場合、BIGINT 型または DOUBLE 型の列のみを選択できます。入力データがスパースなキーと値のフォーマットで、キー と 値 が数値型の場合、STRING 型の列のみを選択できます。 |
|
|
ラベル列の選択 |
入力テーブルのラベル列。STRING 型と数値型がサポートされています。内部ストレージでは、二値分類の 0 や 1 のような数値型のみがサポートされます。 |
|
|
重み列の選択 |
サンプルの各行に重みを付けるために使用される列。数値型のみがサポートされています。 |
|
|
パラメーター設定 |
目的関数タイプ |
サポートされているタイプは次のとおりです。
|
|
Tweedie 分布インデックス |
このパラメーターは、目的関数タイプを [Tweedie 回帰] に設定した場合にのみ使用できます。Tweedie 分布の分散と平均の関係のインデックスを指定します。 |
|
|
評価メトリックタイプ |
サポートされているタイプは次のとおりです。
|
|
|
木の数 |
木の数。正の整数である必要があります。[木の数] はトレーニング時間に比例します。 |
|
|
木の最大深度 |
デフォルト値は 5 で、最大 32 のリーフノードを意味します。 |
|
|
データサンプリング率 |
各木が構築されるとき、データの一部がサンプリングされて弱学習器が構築され、トレーニングが高速化されます。 |
|
|
特徴サンプリング率 |
各木が構築されるとき、特徴の一部がサンプリングされて弱学習器が構築され、トレーニングが高速化されます。 |
|
|
L1 ペナルティ係数 |
リーフノードのサイズを制御します。値が大きいほど、リーフノードのサイズの分布が均一になります。過学習が発生した場合は、この値を大きくしてください。 |
|
|
L2 ペナルティ係数 |
リーフノードのサイズを制御します。値が大きいほど、リーフノードのサイズの分布が均一になります。過学習が発生した場合は、この値を大きくしてください。 |
|
|
学習率 |
値は (0,1) の範囲内である必要があります。 |
|
|
近似スケッチ精度 |
スケッチが構築されるときの分割のための分位数しきい値。値が小さいほど、より多くのバケットが得られます。デフォルト値の 0.03 を使用できます。 |
|
|
最小分割損失変化 |
ノードを分割するために必要な最小損失変化。値が大きいほど、分割はより保守的になります。 |
|
|
特徴数 |
特徴の数または最大の特徴 ID。リソース使用量を見積もる際にこのパラメーターが設定されていない場合、システムは SQL タスクを開始して値を自動的に計算します。 |
|
|
グローバルバイアス |
すべてのサンプルの初期予測値。 |
|
|
乱数ジェネレーターのシード |
乱数ジェネレーターのシード。値は整数である必要があります。 |
|
|
特徴重要度タイプ |
サポートされているタイプは次のとおりです。
|
|
|
実行チューニング |
コア数 |
これはデフォルトでシステムによって割り当てられます。 |
|
コアあたりのメモリ (MB) |
単一のコアが使用するメモリ (MB 単位)。デフォルトでは、システムが自動的にメモリを割り当てます。 |
方法2:PAI コマンドの使用
PS-SMART 回帰コンポーネントのパラメーターを設定するには、SQL スクリプトコンポーネントから PAI コマンドを呼び出すことができます。詳細については、「SQL スクリプト」をご参照ください。
# モデルをトレーニングします。
PAI -name ps_smart
-project algo_public
-DinputTableName="smart_regression_input"
-DmodelName="xlab_m_pai_ps_smart_bi_545859_v0"
-DoutputTableName="pai_temp_24515_545859_2"
-DoutputImportanceTableName="pai_temp_24515_545859_3"
-DlabelColName="label"
-DfeatureColNames="features"
-DenableSparse="true"
-Dobjective="reg:linear"
-Dmetric="rmse"
-DfeatureImportanceType="gain"
-DtreeCount="5"
-DmaxDepth="5"
-Dshrinkage="0.3"
-Dl2="1.0"
-Dl1="0"
-Dlifecycle="3"
-DsketchEps="0.03"
-DsampleRatio="1.0"
-DfeatureRatio="1.0"
-DbaseScore="0.5"
-DminSplitLoss="0"
# 予測を行います。
PAI -name prediction
-project algo_public
-DinputTableName="smart_regression_input";
-DmodelName="xlab_m_pai_ps_smart_bi_545859_v0"
-DoutputTableName="pai_temp_24515_545860_1"
-DfeatureColNames="features"
-DappendColNames="label,features"
-DenableSparse="true"
-Dlifecycle="28"|
パラメータータイプ |
パラメーター |
必須 |
デフォルト値 |
説明 |
|
データパラメーター |
featureColNames |
はい |
なし |
トレーニングに使用される入力テーブルの特徴列。入力テーブルが密形式の場合、BIGINT 型または DOUBLE 型の列のみを選択できます。入力テーブルがスパースなキーと値のフォーマットで、キー と 値 が数値型の場合、STRING 型の列のみを選択できます。 |
|
labelColName |
はい |
なし |
入力テーブルのラベル列。STRING 型と数値型がサポートされています。内部ストレージでは、二値分類の 0 や 1 のような数値型のみがサポートされます。 |
|
|
weightCol |
いいえ |
なし |
サンプルの各行に重みを付けるために使用される列。数値型のみがサポートされています。 |
|
|
enableSparse |
いいえ |
false |
データがスパース形式であるかどうかを指定します。有効な値は {true,false} です。スパース形式の キーと値のペア はスペースで区切ります。キー と 値 はコロン (:) で区切ります。例:1:0.3 3:0.9。 |
|
|
inputTableName |
はい |
なし |
入力テーブルの名前。 |
|
|
modelName |
はい |
なし |
出力モデルの名前。 |
|
|
outputImportanceTableName |
いいえ |
なし |
特徴重要度情報を含む出力テーブルの名前。 |
|
|
inputTablePartitions |
いいえ |
なし |
フォーマットは ds=1/pt=1 です。 |
|
|
outputTableName |
いいえ |
なし |
MaxCompute の出力テーブル。データはバイナリ形式です。 |
|
|
lifecycle |
いいえ |
3 |
出力テーブルのライフサイクル (日数)。 |
|
|
アルゴリズムパラメーター |
objective |
はい |
reg:linear |
目的関数タイプ。サポートされているタイプは次のとおりです。
|
|
metric |
いいえ |
なし |
トレーニングデータセットの評価メトリックタイプ。出力は Logview のコーディネーターエリアの stdout ファイルに書き込まれます。サポートされているタイプは次のとおりです。
|
|
|
treeCount |
いいえ |
1 |
木の数。この値はトレーニング時間に比例します。 |
|
|
maxDepth |
いいえ |
5 |
木の最大深度。値は 1 から 20 の範囲内である必要があります。 |
|
|
sampleRatio |
いいえ |
1.0 |
データサンプリング率。値は (0,1] の範囲内である必要があります。値 1.0 はサンプリングが実行されないことを示します。 |
|
|
featureRatio |
いいえ |
1.0 |
特徴サンプリング率。値は (0,1] の範囲内である必要があります。値 1.0 はサンプリングが実行されないことを示します。 |
|
|
l1 |
いいえ |
0 |
L1 ペナルティ係数。値が大きいほど、リーフノードの分布が均一になります。過学習が発生した場合は、この値を大きくしてください。 |
|
|
l2 |
いいえ |
1.0 |
L2 ペナルティ係数。値が大きいほど、リーフノードの分布が均一になります。過学習が発生した場合は、この値を大きくしてください。 |
|
|
shrinkage |
いいえ |
0.3 |
学習率。値は (0,1) の範囲内である必要があります。 |
|
|
sketchEps |
いいえ |
0.03 |
スケッチが構築されるときの分割のための分位数しきい値。バケットの数は O(1.0/sketchEps) です。値が小さいほど、より多くのバケットが得られます。デフォルト値を使用できます。値は (0,1) の範囲内である必要があります。 |
|
|
minSplitLoss |
いいえ |
0 |
ノードを分割するために必要な最小損失変化。値が大きいほど、分割はより保守的になります。 |
|
|
featureNum |
いいえ |
なし |
特徴の数または最大の特徴 ID。リソース使用量を見積もる際にこのパラメーターが設定されていない場合、システムは SQL タスクを開始して値を自動的に計算します。 |
|
|
baseScore |
いいえ |
0.5 |
すべてのサンプルの初期予測値。 |
|
|
randSeed |
いいえ |
なし |
乱数ジェネレーターのシード。値は整数である必要があります。 |
|
|
featureImportanceType |
いいえ |
gain |
特徴重要度を計算するメソッド。以下が含まれます。
|
|
|
tweedieVarPower |
いいえ |
1.5 |
Tweedie 分布の分散と平均の関係のインデックス。 |
|
|
チューニングパラメーター |
coreNum |
いいえ |
システム割り当て |
コア数。値が大きいほど、アルゴリズムの実行が速くなります。 |
|
いいえ |
システム割り当て |
各コアのメモリ (MB 単位)。 |
例
-
ODPS SQL ノードを使用して、次の SQL 文を実行して入力データを生成できます。この例では、キーと値のフォーマットのデータを使用します。
drop table if exists smart_regression_input; create table smart_regression_input as select * from ( select 2.0 as label, '1:0.55 2:-0.15 3:0.82 4:-0.99 5:0.17' as features union all select 1.0 as label, '1:-1.26 2:1.36 3:-0.13 4:-2.82 5:-0.41' as features union all select 1.0 as label, '1:-0.77 2:0.91 3:-0.23 4:-4.46 5:0.91' as features union all select 2.0 as label, '1:0.86 2:-0.22 3:-0.46 4:0.08 5:-0.60' as features union all select 1.0 as label, '1:-0.76 2:0.89 3:1.02 4:-0.78 5:-0.86' as features union all select 1.0 as label, '1:2.22 2:-0.46 3:0.49 4:0.31 5:-1.84' as features union all select 0.0 as label, '1:-1.21 2:0.09 3:0.23 4:2.04 5:0.30' as features union all select 1.0 as label, '1:2.17 2:-0.45 3:-1.22 4:-0.48 5:-1.41' as features union all select 0.0 as label, '1:-0.40 2:0.63 3:0.56 4:0.74 5:-1.44' as features union all select 1.0 as label, '1:0.17 2:0.49 3:-1.50 4:-2.20 5:-0.35' as features ) tmp;生成されたデータを以下に示します。
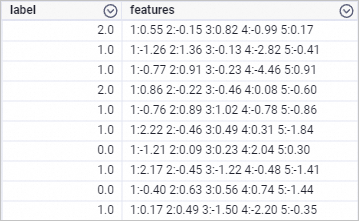
-
次のワークフローを構築し、コンポーネントを実行します。詳細については、「アルゴリズムモデリング」をご参照ください。
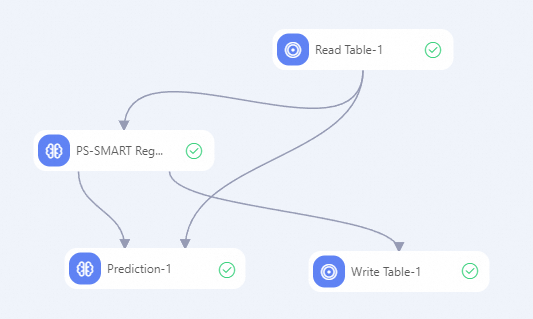
-
Designer キャンバスの左側にあるコンポーネントリストで、テーブル読み込み、PS-SMART 回帰、予測、およびテーブル書き込みコンポーネントを検索し、キャンバスにドラッグします。
-
コンポーネントのパラメーターを設定します。
-
キャンバスで、Read Table-1 コンポーネントをクリックします。右側のペインの [テーブルの選択] タブで、[テーブル名] を smart_regression_input に設定します。
-
キャンバスで、PS-SMART Regression-1 コンポーネントをクリックします。右側のペインで、次の表の説明に従ってパラメーターを設定します。他のパラメーターにはデフォルト値を使用します。
パラメータータイプ
パラメーター
説明
フィールド設定
スパース形式
[スパース形式であるか] チェックボックスを選択します。
特徴列
features 列を選択します。
ラベル列
label 列を選択します。
パラメーター設定
目的関数タイプ
[線形回帰] に設定します。
評価メトリックタイプ
[ルート平均二乗誤差] を選択します。
木の数
5 に設定します。
-
キャンバスで、Prediction-1 コンポーネントをクリックします。右側のペインで、次の表で指定されているようにパラメーターを設定します。残りのパラメーターにはデフォルト値を使用します。
パラメータータイプ
パラメーター
説明
フィールド設定
特徴列
デフォルトでは、すべての列が選択されます。余分な列は予測結果に影響しません。
パススルー列
label 列を選択します。
スパースマトリックス
[スパースマトリックス] チェックボックスを選択します。
キーと値の区切り文字
コロン (:) に設定します。
キーと値のペア間の区切り文字
スペースに設定します。
-
キャンバスで、Write Table-1 コンポーネントをクリックします。右側のペインの [テーブルの選択] タブで、[出力用テーブル名] パラメーターを smart_regression_output に設定します。
-
-
パラメーターを設定した後、実行ボタン
 をクリックしてワークフローを実行します。
をクリックしてワークフローを実行します。
-
-
Prediction-1 コンポーネントを右クリックし、 を選択します。
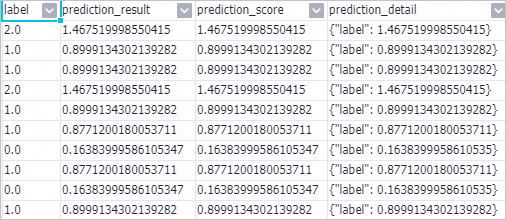
-
特徴重要度を表示するには、PS-SMART Regression-1 コンポーネントを右クリックし、ショートカットメニューから を選択します。
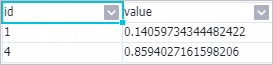
id 列は、入力特徴の序数を示します。この例の入力データはキーと値のフォーマットであるため、id 列はキーと値のペアの キー を表します。特徴重要度テーブルには 2 つの特徴しか含まれていませんが、これは木の分割プロセス中にこれらの 2 つの特徴のみが使用されたことを示します。他の特徴の特徴重要度は 0 です。value 列は、特徴重要度タイプを示します。デフォルト値は gain で、これは特徴がモデルに寄与する情報利得の合計です。
PS-SMART モデルのデプロイ手順
PS-SMART コンポーネントによって生成されたモデルをオンラインサービスとしてデプロイするには、PS-SMART コンポーネントの下流に 汎用モデルエクスポートコンポーネントを追加する必要があります。コンポーネントのパラメーターは、他の PS シリーズコンポーネントと同じ方法で設定できます。詳細については、「汎用モデルエクスポート」をご参照ください。
実行が成功すると、PAI-EAS モデルオンラインサービスページに移動してモデルサービスをデプロイできます。詳細については、「コンソールでのサービスのデプロイ」をご参照ください。
関連ドキュメント
-
Designer コンポーネントの詳細については、「Designer の概要」をご参照ください。
-
Designer はさまざまなアルゴリズムコンポーネントを提供します。さまざまなシナリオに合わせてデータを処理するために適切なコンポーネントを選択できます。詳細については、「Designer コンポーネントの概要」をご参照ください。