パラメーターサーバー (PS) は、大規模なオフラインおよびオンラインのトレーニングタスク向けに設計されています。Scalable Multiple Additive Regression Tree (SMART) は、勾配ブースティング決定木 (GBDT) に基づく反復アルゴリズムであり、PS 上に実装されています。PS-SMART は、数千のノードにわたる数百億のサンプルと数十万の特徴量を持つトレーニングタスクを処理できます。また、複数のデータ形式や、ヒストグラム近似などの最適化手法もサポートしています。
制限事項
このコンポーネントは、MaxCompute コンピューティングエンジンのみをサポートしています。
注意事項
-
PS-SMART バイナリ分類トレーニングコンポーネントのターゲット列は数値型である必要があり、0 はネガティブサンプルを、1 はポジティブサンプルを表します。MaxCompute テーブルのデータが STRING型の場合、データ型を変換する必要があります。たとえば、分類ターゲット文字列 Good/Bad を 1/0 に変換できます。
-
データがキーと値 (KV) 形式の場合、特徴IDは正の整数である必要があり、特徴値は実数である必要があります。特徴IDが STRING型の場合、シリアル化コンポーネントを使用してシリアル化する必要があります。特徴値がカテゴリ文字列の場合、特徴量離散化などの特徴量エンジニアリングを実行する必要があります。
-
PS-SMART バイナリ分類トレーニングコンポーネントは数十万の特徴量を持つタスクをサポートしていますが、トレーニングはリソースを大量に消費し、時間がかかります。パフォーマンスを向上させるには、連続特徴量で直接トレーニングできる GBDTのようなアルゴリズムを使用できます。カテゴリ特徴量に One-Hotエンコーディングを適用し、低頻度特徴量をフィルタリングする以外は、他の連続数値特徴量を離散化しないでください。
-
PS-SMART アルゴリズムはランダム性を導入します。たとえば、data_sample_ratio および fea_sample_ratio パラメーターによって制御されるデータと特徴量のサンプリング、ヒストグラム近似最適化、およびローカルスケッチがグローバルスケッチにマージされるランダムな順序によってランダム性が導入されます。複数のワーカーが分散方式で実行される場合、ツリー構造は異なる可能性がありますが、モデル性能は理論的には類似しています。したがって、同じデータとパラメーターを使用する複数の実行から一貫性のない結果が得られるのは正常です。
-
トレーニングを高速化するには、[コンピューティングコア数] を増やすことができます。PS-SMART アルゴリズムは、すべてのサーバーが必要なリソースを取得した後にのみトレーニングを開始します。したがって、クラスターがビジー状態のときにさらに多くのリソースをリクエストすると、待機時間が増加する可能性があります。
コンポーネント設定
PS-SMART バイナリ分類コンポーネントのパラメーターは、次のいずれかの方法で設定できます。
方法1: UIを使用
コンポーネントのパラメーターは、[デザイナー] ワークフローページで設定します。
|
タブ |
パラメーター |
説明 |
|
[フィールド設定] |
[スパース形式を使用] |
スパース形式では、スペースを使用して KV ペアを区切り、コロン (:) を使用して キー と 値 を区切ります。例: 1:0.3 3:0.9。 |
|
[特徴量列] |
トレーニング用の入力テーブルからの特徴量列。入力データが密形式の場合、数値型 (BIGINT または DOUBLE) の列のみを選択できます。入力データがスパース KV 形式で、キー と 値 が数値型の場合、STRING型の列のみを選択できます。 |
|
|
[ラベル列] |
入力テーブルのラベル列。STRING型と数値型をサポートしています。ただし、列の内容は、バイナリ分類における 0 や 1 のような数値のみをサポートしています。 |
|
|
重み列 |
各サンプル行に重みを付けるために使用される列。数値型をサポートしています。 |
|
|
[パラメーター設定] |
評価メトリクスの種類 |
サポートされているタイプは次のとおりです。
|
|
ツリー数 |
ツリー数。これは正の整数である必要があります。[ツリー数] は学習時間に比例します。 |
|
|
最大ツリー深さ |
デフォルト値は 5 で、これは最大 16 個のリーフノードを意味します。値は正の整数である必要があります。 |
|
|
データ サンプリング率 |
各ツリーを構築する際、データの一部がサンプリングされて弱い学習器が構築され、トレーニングが高速化されます。 |
|
|
特徴量サンプリング比率 |
各ツリーを構築する際、特徴量の一部がサンプリングされて弱い学習器が構築され、トレーニングが高速化されます。 |
|
|
[L1ペナルティ係数] |
リーフノードのサイズを制御します。値が大きいほど、リーフノードのサイズの分布はより均一になります。過学習が発生した場合は、この値を増やしてください。 |
|
|
[L2ペナルティ係数] |
リーフノードのサイズを制御します。値が大きいほど、リーフノードのサイズの分布はより均一になります。過学習が発生した場合は、この値を増やしてください。 |
|
|
学習率 |
値の範囲は (0,1) です。 |
|
|
[スケッチ近似精度] |
スケッチを構築する際の分割のための分位数しきい値。値が小さいほど、より多くのバケットが作成されます。通常、デフォルト値 0.03 を使用します。手動設定は不要です。 |
|
|
最小分割損失変化 |
ノードを分割するために必要な最小損失変化。値が大きいほど、分割はより保守的になります。 |
|
|
[特徴量数] |
特徴量数または最大特徴量ID。リソース使用量の見積もり時にこのパラメーターが設定されていない場合、システムは SQLタスクを開始して自動的に計算します。 |
|
|
[グローバルバイアス項] |
すべてのサンプルの初期予測値。 |
|
|
乱数ジェネレーターシード |
乱数シード。整数である必要があります。 |
|
|
特徴量の重要度タイプ |
サポートされているタイプは次のとおりです。
|
|
|
実行チューニング |
コンピューティングコアの数 |
システムはデフォルトでコアを自動的に割り当てます。 |
|
[コアあたりのメモリサイズ] |
単一コアで使用されるメモリ (MB単位)。通常、手動設定は不要です。システムはメモリを自動的に割り当てます。 |
方法2: PAIコマンドを使用
Platform for AI (PAI) コマンドを使用してコンポーネントパラメーターを設定できます。SQLスクリプトコンポーネントを使用して PAIコマンドを呼び出すことができます。詳細については、「SQLスクリプト」をご参照ください。
# トレーニング。
PAI -name ps_smart
-project algo_public
-DinputTableName="smart_binary_input"
-DmodelName="xlab_m_pai_ps_smart_bi_545859_v0"
-DoutputTableName="pai_temp_24515_545859_2"
-DoutputImportanceTableName="pai_temp_24515_545859_3"
-DlabelColName="label"
-DfeatureColNames="f0,f1,f2,f3,f4,f5"
-DenableSparse="false"
-Dobjective="binary:logistic"
-Dmetric="error"
-DfeatureImportanceType="gain"
-DtreeCount="5"
-DmaxDepth="5"
-Dshrinkage="0.3"
-Dl2="1.0"
-Dl1="0"
-Dlifecycle="3"
-DsketchEps="0.03"
-DsampleRatio="1.0"
-DfeatureRatio="1.0"
-DbaseScore="0.5"
-DminSplitLoss="0";
# 予測。
PAI -name prediction
-project algo_public
-DinputTableName="smart_binary_input"
-DmodelName="xlab_m_pai_ps_smart_bi_545859_v0"
-DoutputTableName="pai_temp_24515_545860_1"
-DfeatureColNames="f0,f1,f2,f3,f4,f5"
-DappendColNames="label,qid,f0,f1,f2,f3,f4,f5"
-DenableSparse="false"
-Dlifecycle="28";|
モジュール |
パラメーター |
必須 |
説明 |
デフォルト値 |
|
データパラメーター |
featureColNames |
はい |
トレーニング用の入力テーブルからの特徴量列。入力テーブルが密形式の場合、数値型 (BIGINT または DOUBLE) の列のみを選択できます。入力テーブルがスパース KV 形式で、キー と 値 が数値型の場合、STRING型の列のみを選択できます。 |
なし |
|
labelColName |
はい |
入力テーブルのラベル列。STRING型と数値型をサポートしています。内部ストレージの場合、数値型のみがサポートされます。たとえば、バイナリ分類における 0 と 1。 |
なし |
|
|
weightCol |
いいえ |
各サンプル行に重みを付けるために使用される列。数値型をサポートしています。 |
なし |
|
|
enableSparse |
いいえ |
形式がスパースであるかどうかを指定します。有効な値: {true,false}。スパース形式では、スペースを使用して KV ペアを区切り、コロン (:) を使用して キー と 値 を区切ります。例: 1:0.3 3:0.9。 |
false |
|
|
inputTableName |
はい |
入力テーブルの名前。 |
なし |
|
|
modelName |
はい |
出力モデルの名前。 |
なし |
|
|
outputImportanceTableName |
いいえ |
特徴量重要度の出力テーブルの名前。 |
なし |
|
|
inputTablePartitions |
いいえ |
形式は ds=1/pt=1 です。 |
なし |
|
|
outputTableName |
いいえ |
MaxCompute の出力テーブル。テーブルはバイナリ形式であり、読み取ることはできません。SMART 予測コンポーネントを介してのみ取得できます。 |
なし |
|
|
lifecycle |
いいえ |
出力テーブルのライフサイクル (日数)。 |
3 |
|
|
アルゴリズムパラメーター |
objective |
はい |
目的関数のタイプ。バイナリ分類トレーニングの場合、binary:logistic を選択します。 |
なし |
|
metric |
いいえ |
トレーニングデータセットの評価メトリックタイプ。出力は Logview のコーディネーターセクションにある stdout ファイルに書き込まれます。サポートされているタイプは次のとおりです。
|
なし |
|
|
treeCount |
いいえ |
ツリー数。トレーニング時間に比例します。 |
1 |
|
|
maxDepth |
いいえ |
ツリーの最大深度。1 から 20 までの正の整数である必要があります。 |
5 |
|
|
sampleRatio |
いいえ |
データサンプリング比率。値の範囲は (0,1] です。1.0 の値はサンプリングなしを意味します。 |
1.0 |
|
|
featureRatio |
いいえ |
特徴量サンプリング比率。値の範囲は (0,1] です。1.0 の値はサンプリングなしを意味します。 |
1.0 |
|
|
l1 |
いいえ |
L1ペナルティ係数。値が大きいほど、リーフノードの分布はより均一になります。過学習が発生した場合は、この値を増やしてください。 |
0 |
|
|
l2 |
いいえ |
L2ペナルティ係数。値が大きいほど、リーフノードの分布はより均一になります。過学習が発生した場合は、この値を増やしてください。 |
1.0 |
|
|
shrinkage |
いいえ |
値の範囲は (0,1) です。 |
0.3 |
|
|
sketchEps |
いいえ |
スケッチを構築する際の分割のための分位数しきい値。バケット数は O(1.0/sketchEps) です。値が小さいほど、より多くのバケットが作成されます。通常、手動設定は不要です。値の範囲は (0,1) です。 |
0.03 |
|
|
minSplitLoss |
いいえ |
ノードを分割するために必要な最小損失変化。値が大きいほど、分割はより保守的になります。 |
0 |
|
|
featureNum |
いいえ |
特徴量数または最大特徴量ID。リソース使用量の見積もり時にこのパラメーターが設定されていない場合、システムは SQLタスクを開始して自動的に計算します。 |
なし |
|
|
baseScore |
いいえ |
すべてのサンプルの初期予測値。 |
0.5 |
|
|
randSeed |
いいえ |
乱数シード。整数である必要があります。 |
なし |
|
|
featureImportanceType |
いいえ |
計算する特徴量重要度のタイプ。次のものが含まれます。
|
gain |
|
|
チューニングパラメーター |
coreNum |
いいえ |
コア数。値が大きいほど、アルゴリズムの実行は速くなります。 |
システム割り当て |
|
memSizePerCore |
いいえ |
各コアで使用されるメモリ (MB単位)。 |
システム割り当て |
例
-
ODPS SQLノード を使用して、次の SQL文を実行し、トレーニングデータを生成します。この例では、密形式のデータを使用します。
drop table if exists smart_binary_input; create table smart_binary_input lifecycle 3 as select * from ( select 0.72 as f0, 0.42 as f1, 0.55 as f2, -0.09 as f3, 1.79 as f4, -1.2 as f5, 0 as label union all select 1.23 as f0, -0.33 as f1, -1.55 as f2, 0.92 as f3, -0.04 as f4, -0.1 as f5, 1 as label union all select -0.2 as f0, -0.55 as f1, -1.28 as f2, 0.48 as f3, -1.7 as f4, 1.13 as f5, 1 as label union all select 1.24 as f0, -0.68 as f1, 1.82 as f2, 1.57 as f3, 1.18 as f4, 0.2 as f5, 0 as label union all select -0.85 as f0, 0.19 as f1, -0.06 as f2, -0.55 as f3, 0.31 as f4, 0.08 as f5, 1 as label union all select 0.58 as f0, -1.39 as f1, 0.05 as f2, 2.18 as f3, -0.02 as f4, 1.71 as f5, 0 as label union all select -0.48 as f0, 0.79 as f1, 2.52 as f2, -1.19 as f3, 0.9 as f4, -1.04 as f5, 1 as label union all select 1.02 as f0, -0.88 as f1, 0.82 as f2, 1.82 as f3, 1.55 as f4, 0.53 as f5, 0 as label union all select 1.19 as f0, -1.18 as f1, -1.1 as f2, 2.26 as f3, 1.22 as f4, 0.92 as f5, 0 as label union all select -2.78 as f0, 2.33 as f1, 1.18 as f2, -4.5 as f3, -1.31 as f4, -1.8 as f5, 1 as label ) tmp;生成されたトレーニングデータは次の図に示されています。
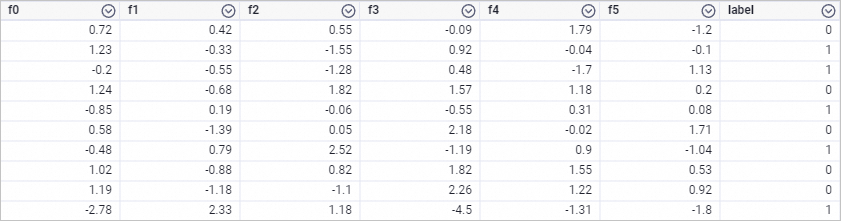
-
次の図に示すようにワークフローを構築し、コンポーネントを実行します。詳細については、「アルゴリズムモデリング」をご参照ください。
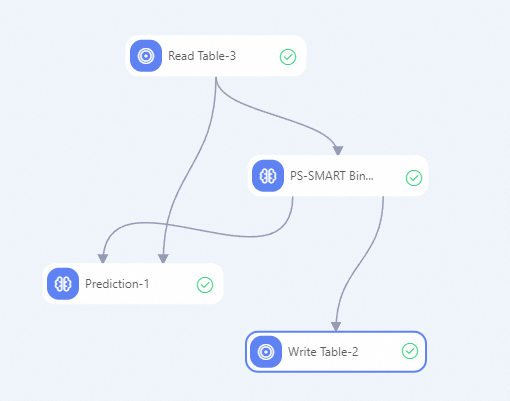
-
Designerキャンバスの左側にあるコンポーネントリストで、Read Table、PS-SMART Binary Classification Training、Prediction、および Write Table コンポーネントを検索してキャンバスにドラッグします。
-
前の図に示すようにコンポーネントを接続して、アップストリームとダウンストリームの関係を持つワークフローを構築します。
-
コンポーネントパラメーターを設定します。
-
キャンバスで、[Read Table-1] コンポーネントをクリックします。右側のペインにある [Select Table] タブで、[Table Name] を smart_binary_input に設定します。
-
キャンバスで、[PS-SMART Binary Classification Training-1] コンポーネントをクリックします。右側のペインで、次の表に示すようにパラメーターを設定します。その他のパラメーターにはデフォルト値を使用します。
タブ
パラメーター
説明
[フィールド設定]
特徴列
f0、f1、f2、f3、f4、および f5 列を選択します。
ラベル列
label 列を選択します。
[パラメーター設定]
評価指標タイプ
「[分類のための曲線下面積]」を選択します。
ツリー数
5 を入力します。
-
キャンバスで、[Prediction-1] コンポーネントをクリックします。右側のペインにある [フィールド設定] タブで、[予約済み列] を [すべて選択] に設定します。その他のパラメーターにはデフォルト値を使用します。
-
キャンバスで、[Write Table-1] コンポーネントをクリックします。右側のペインにある [Select Table] タブで、[出力テーブル名] を smart_binary_output に設定します。
-
-
パラメーターを設定したら、[実行] ボタン
 をクリックしてワークフローを実行します。
をクリックしてワークフローを実行します。
-
-
[Prediction-1] コンポーネントを右クリックし、 を選択して予測結果を表示します。
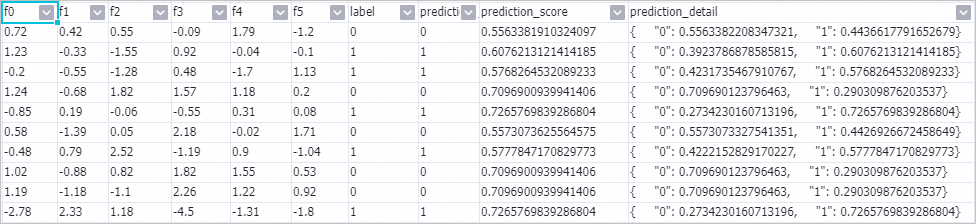 [prediction_detail] 列では、1 はポジティブサンプルを、0 はネガティブサンプルを表します。
[prediction_detail] 列では、1 はポジティブサンプルを、0 はネガティブサンプルを表します。 -
[PS-SMART Binary Classification Training-1] コンポーネントを右クリックし、 を選択して特徴量重要度テーブルを表示します。
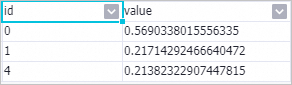 パラメーターは次のとおりです。
パラメーターは次のとおりです。-
id: 入力特徴の序数です。この例では、入力特徴は f0、f1、f2、f3、f4、f5 です。したがって、[id] 列の値 0 は f0 特徴列を表し、[id] 列の値 4 は f4 特徴列を表します。入力データがキー-値 (KV) フォーマットの場合、[id] 列は key を表します。
-
[value]: 特徴量重要度タイプ。デフォルト値は gain であり、これは特徴量がモデルにもたらす情報利得の合計です。
-
特徴量重要度テーブルには 3 つの特徴量のみが含まれています。これは、これらの 3 つの特徴量のみがツリー分割プロセスで使用されることを意味します。その他の特徴量の重要度は 0 と見なされます。
-
PS-SMARTモデルのデプロイ手順
PS-SMART コンポーネントによって生成されたモデルをオンラインサービスとしてデプロイするには、PS-SMART コンポーネントのダウンストリームに [General-purpose Model Export] コンポーネントを追加する必要があります。他の PSシリーズコンポーネントと同様に、コンポーネントパラメーターを設定できます。詳細については、「General-purpose Model Export」をご参照ください。
正常な実行後、[PAI-EAS モデルオンラインサービス] ページに移動してモデルサービスをデプロイできます。詳細については、「コンソールでサービスをデプロイする」をご参照ください。
参考
-
Designerコンポーネントの詳細については、「Designerの概要」をご参照ください。
-
Designer はさまざまなアルゴリズムコンポーネントを提供します。ご利用のシナリオに基づいて、データ処理に適したコンポーネントを選択できます。詳細については、「コンポーネントリファレンス: すべてのコンポーネント」をご参照ください。