PS 線形回帰は、線形回帰モデルとパラメーターサーバー (PS) アーキテクチャを組み合わせた機械学習アルゴリズムです。従属変数と複数の独立変数の間の線形関係を処理します。これにより、数千億のサンプルと数十億の特徴を持つ大規模データセットでのトレーニングタスクに適しています。パラメーターサーバーアーキテクチャを使用することで、PS 線形回帰は効率的に分散コンピューティングを実行し、モデルパラメーターを保存して、トレーニング効率とスケーラビリティを向上させることができます。
コンポーネントの設定
方法1:ビジュアルインターフェイスを使用
Designer のワークフローに [PS 線形回帰] コンポーネントを追加し、右側のペインでそのパラメーターを設定します。
|
パラメータータイプ |
パラメーター |
説明 |
|
フィールド設定 |
特徴列 |
トレーニングに使用する入力データソースの特徴列。 |
|
ラベル列 |
DOUBLE および BIGINT データ型をサポートします。 |
|
|
スパースフォーマットですか? |
KV フォーマットはスパースフォーマットを表します。 |
|
|
KV ペア区切り文字 |
デフォルトの区切り文字はスペースです。 |
|
|
キーと値の区切り文字 |
デフォルトの区切り文字はコロン (:) です。 |
|
|
パラメーター設定 |
L1 重み |
L1 正則化係数。値が大きいほど、モデルの非ゼロ要素が少なくなります。過学習が発生した場合は、この値を大きくします。 |
|
L2 重み |
L2 正則化係数。値が大きいほど、モデルパラメーターの絶対値が小さくなります。過学習が発生した場合は、この値を大きくします。 |
|
|
最大反復回数 |
アルゴリズムの最大反復回数。[最大反復回数] が 0 に設定されている場合、反復回数は制限されません。 |
|
|
最小収束偏差 |
最適化アルゴリズムの終了条件。 |
|
|
最大特徴 ID |
最大の特徴 ID または特徴ディメンション。この値は実際の値より大きくてもかまいません。このパラメーターを設定しない場合、システムは SQL タスクを開始して自動的に計算します。 |
|
|
実行チューニング |
コア数 |
デフォルトでは、システムが自動的に割り当てます。 |
|
コアあたりのメモリサイズ |
デフォルトでは、システムが自動的にメモリを割り当てます。 |
方法2:PAI コマンドを使用
PAI コマンドを使用して、[PS 線形回帰] コンポーネントのパラメーターを設定します。SQL スクリプトコンポーネントを使用して PAI コマンドを実行できます。詳細については、「SQL スクリプト」をご参照ください。
# トレーニング
PAI -name ps_linearregression
-project algo_public
-DinputTableName="lm_test_input"
-DmodelName="linear_regression_model"
-DlabelColName="label"
-DfeatureColNames="features"
-Dl1Weight=1.0
-Dl2Weight=0.0
-DmaxIter=100
-Depsilon=1e-6
-DenableSparse=true
# 予測
drop table if exists logistic_regression_predict;
PAI -name prediction
-DmodelName="linear_regression_model"
-DoutputTableName="linear_regression_predict"
-DinputTableName="lm_test_input"
-DappendColNames="label,features"
-DfeatureColNames="features"
-DenableSparse=true|
パラメーター |
必須 |
デフォルト値 |
説明 |
|
inputTableName |
はい |
なし |
入力テーブルの名前。 |
|
modelName |
はい |
なし |
出力モデルの名前。 |
|
outputTableName |
いいえ |
なし |
出力モデル評価テーブルの名前。このパラメーターは、enableFitGoodness が true の場合に必須です。 |
|
labelColName |
はい |
なし |
入力テーブルのラベル列の名前。DOUBLE および BIGINT データ型をサポートします。 |
|
featureColNames |
はい |
なし |
トレーニングに使用する入力テーブルの特徴列の名前。入力データが密フォーマットの場合、DOUBLE および BIGINT データ型がサポートされます。入力データがスパースフォーマットの場合、STRING データ型がサポートされます。 |
|
inputTablePartitions |
いいえ |
なし |
入力テーブルのパーティション。 |
|
enableSparse |
いいえ |
false |
入力データがスパースフォーマットであるかどうかを指定します。有効値は {true,false} です。 |
|
itemDelimiter |
いいえ |
スペース |
キーと値のペアの間の区切り文字。このパラメーターは、enableSparse が true の場合にのみ有効です。 |
|
kvDelimiter |
いいえ |
コロン (:) |
キーと値の間の区切り文字。このパラメーターは、enableSparse が true の場合にのみ有効です。 |
|
enableModelIo |
いいえ |
true |
モデルをオフラインモデルとして出力するかどうかを指定します。enableModelIo が false の場合、モデルは MaxCompute テーブルに出力されます。有効値は {true,false} です。 |
|
maxIter |
いいえ |
100 |
アルゴリズムの最大反復回数。値は非負整数である必要があります。 |
|
epsilon |
いいえ |
0.000001 |
最適化アルゴリズムの終了条件。値は [0,1] の範囲内である必要があります。 |
|
l1Weight |
いいえ |
1.0 |
L1 正則化係数。値が大きいほど、モデルの非ゼロ要素が少なくなります。過学習が発生した場合は、この値を大きくします。 |
|
l2Weight |
いいえ |
0 |
L2 正則化係数。値が大きいほど、モデルパラメーターの絶対値が小さくなります。過学習が発生した場合は、この値を大きくします。 |
|
modelSize |
いいえ |
0 |
最大の特徴 ID または特徴ディメンション。この値は実際の値より大きくてもかまいません。このパラメーターを設定しない場合、システムは SQL タスクを開始して自動的に計算します。値は非負整数である必要があります。 |
|
coreNum |
いいえ |
システム割り当て |
デフォルトでは、自動的に割り当てられます。 |
|
memSizePerCore |
いいえ |
システム割り当て |
デフォルトでは、システムが自動的にメモリを割り当てます。 |
例
-
SQL スクリプトコンポーネントを使用して次の SQL 文を実行し、入力データを生成します。この例では、キー値 (KV) フォーマットのデータを使用します。
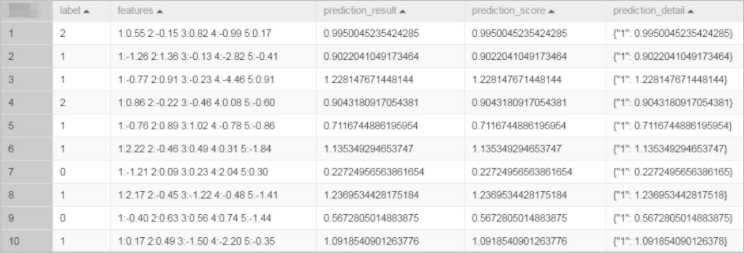
drop table if exists lm_test_input; create table lm_test_input as select * from ( select cast(2 as BIGINT) as label, '1:0.55 2:-0.15 3:0.82 4:-0.99 5:0.17' as features union all select cast(1 as BIGINT) as label, '1:-1.26 2:1.36 3:-0.13 4:-2.82 5:-0.41' as features union all select cast(1 as BIGINT) as label, '1:-0.77 2:0.91 3:-0.23 4:-4.46 5:0.91' as features union all select cast(2 as BIGINT) as label, '1:0.86 2:-0.22 3:-0.46 4:0.08 5:-0.60' as features union all select cast(1 as BIGINT) as label, '1:-0.76 2:0.89 3:1.02 4:-0.78 5:-0.86' as features union all select cast(1 as BIGINT) as label, '1:2.22 2:-0.46 3:0.49 4:0.31 5:-1.84' as features union all select cast(0 as BIGINT) as label, '1:-1.21 2:0.09 3:0.23 4:2.04 5:0.30' as features union all select cast(1 as BIGINT) as label, '1:2.17 2:-0.45 3:-1.22 4:-0.48 5:-1.41' as features union all select cast(0 as BIGINT) as label, '1:-0.40 2:0.63 3:0.56 4:0.74 5:-1.44' as features union all select cast(1 as BIGINT) as label, '1:0.17 2:0.49 3:-1.50 4:-2.20 5:-0.35' as features ) tmp;生成されたデータを次の図に示します。
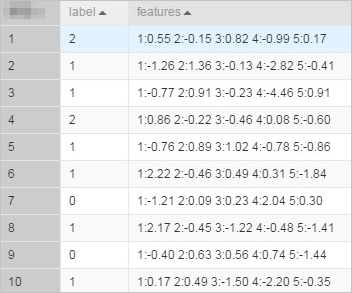 説明
説明KV フォーマットのデータの場合、特徴 ID は正の整数、特徴値は実数である必要があります。特徴 ID が文字列の場合は、データをシリアル化する必要があります。特徴値がカテゴリ文字列の場合は、特徴の離散化を実行する必要があります。
-
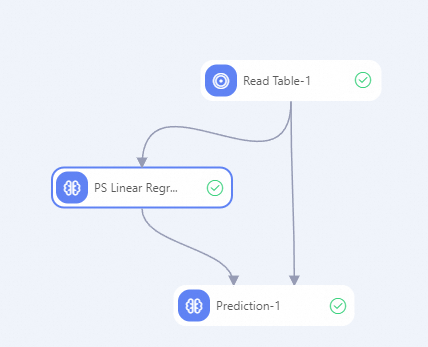
次の図に示すようにワークフローを構築します。詳細については、「アルゴリズムモデリング」をご参照ください。
-
コンポーネントのパラメーターを設定します。
-
[テーブル読み込み-1] コンポーネントをクリックします。右側のペインの [テーブルの選択] タブで、[テーブル名] を lm_test_input に設定します。
-
次の表の説明に従って、PS 線形回帰コンポーネントのパラメーターを設定します。他のパラメーターにはデフォルト値を使用します。
パラメータータイプ
パラメーター
説明
フィールド設定
スパースフォーマットですか?
true を選択します。
特徴列
features 列を選択します。
ラベル列
label 列を選択します。
実行チューニング
コア数
3 に設定します。
コアあたりのメモリサイズ
1024 MB に設定します。
-
次の表の説明に従って、予測コンポーネントのパラメーターを設定します。他のパラメーターにはデフォルト値を使用します。
パラメータータイプ
パラメーター
説明
フィールド設定
特徴列
features 列を選択します。
そのまま出力する列
[label] 列と [features] 列を選択します。
スパース行列
[スパース行列] チェックボックスを選択します。
キーと値の区切り文字
コロン (:) に設定します。
KV ペア区切り文字
このパラメーターを空のままにすると、スペースが区切り文字として使用されます。
-
-
キャンバス上の実行ボタン
 をクリックして、ワークフローを実行します。
をクリックして、ワークフローを実行します。 -
ワークフローの実行後、[予測-1] コンポーネントを右クリックし、ショートカットメニューから を選択します。