DeepSeek 671B のような大規模混合エキスパート (MoE) モデルは、単一のデバイスではホストできないほど多くのパラメーターを含んでいます。この問題に対処するため、Elastic Algorithm Service (EAS) はマルチノード分散推論ソリューションを提供しています。このソリューションは、単一のサービスインスタンスを複数のマシンにまたがってデプロイすることでハードウェアの制限を克服し、大規模モデルの効率的なデプロイメントと実行をサポートします。このトピックでは、マルチノード分散推論の設定方法について説明します。
注意事項
EAS またはモデルギャラリーから提供される一部の公式 SGLang および vLLM イメージは、ネイティブで分散推論をサポートしています。カスタムイメージを使用して分散推論をデプロイする場合は、ご利用の分散推論フレームワークのネットワーク要件と標準的な分散処理パターンに従ってください。詳細については、「仕組み」をご参照ください。
仕組み
このセクションでは、分散推論の基本概念と実装原則について説明します。
インスタンスユニット
標準的な EAS 推論サービスと比較して、分散推論ではインスタンスユニット (このトピックではユニットと呼びます) という概念が導入されています。ユニット内のインスタンスは、高性能ネットワーク通信と、テンソル並列処理 (TP) やパイプライン並列処理 (PP) などのパターンを使用して連携し、各リクエストを処理します。ユニット内のインスタンスはステートフルです。各ユニットは互いに完全に対称であり、ステートレスです。
インスタンス ID
ユニット内の各インスタンスは、環境変数を通じてインスタンス ID を受け取ります。ユニットで使用される環境変数とその説明のリストについては、「付録」をご参照ください。インスタンスにはシーケンシャル ID が割り当てられます。これらの ID を使用して、異なるインスタンスに異なるタスクを割り当てます。
トラフィック処理
デフォルトでは、各ユニットはインスタンス 0 (RANK_ID = 0) を通じてのみトラフィックを処理します。システムはサービスディスカバリを使用して、ユーザーのトラフィックを異なるユニットのインスタンス 0 にルーティングします。その後、各ユニットは内部で分散的にリクエストを処理します。各ユニットは互いに干渉することなく、独立してトラフィックを処理します。

ローリングアップデート
ローリングアップデート中、ユニットは全体として再構築されます。新しいユニット内のすべてのインスタンスは並行して起動します。新しいユニット内のすべてのインスタンスの準備が整うと、システムは古いユニットからトラフィックを削除し、その後、そのすべてのインスタンスを削除します。

ライフサイクル
ユニットの再構築
ユニットが再作成される際、古いユニット内のすべてのインスタンスは並行して削除されます。新しいユニット内のすべてのインスタンスも並行して作成されます。インスタンス ID に基づく特別な処理は行われません。
インスタンスの再作成
デフォルトでは、ユニット内の各インスタンスのライフサイクルは、インスタンス 0 のライフサイクルと一致します。インスタンス 0 が再作成されると、ユニット内の他のすべてのインスタンスも再作成されます。0 以外のインスタンスが再作成された場合、ユニット内の他のインスタンスは影響を受けません。
分散フォールトトレランス
インスタンス障害の処理
システムが分散サービスのいずれかのインスタンスで障害を検出すると、そのユニット内のすべてのインスタンスが自動的に再起動されます。
目的:単一障害点によるクラスター状態の不整合を防ぎ、すべてのインスタンスがクリーンで一貫性のある環境で起動することを保証します。
協調回復
インスタンスが再起動した後、システムは同期バリアを使用して、ユニット内のすべてのインスタンスが一貫した準備完了状態に達するのを待ちます。すべてのインスタンスの準備が整ってから、システムはビジネスプロセスを開始します。
目的:
インスタンスの状態の不整合が原因で NCCL が通信グループを形成する際の障害を防ぎます。
分散推論タスクに関与するすべてのノード間で厳密な起動同期を保証します。
分散フォールトトレランスはデフォルトで無効になっています。有効にするには、`unit.guard` パラメーターを設定します。設定例:
{
"unit": {
"size": 2,
"guard": true
}
}マルチノード分散推論の設定
モデルギャラリーを使用したワンクリックデプロイメント
マルチノード分散デプロイメントには、モデルギャラリーを使用することを推奨します。
分散推論は、推論エンジンが SGLang または vLLM の場合にのみサポートされます。
選択したテンプレートに一致するデプロイメントリソースを選択してください。
EAS を使用したカスタムデプロイメント
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
サービスの作成:Inference Service タブで、Deploy Service をクリックします。Custom Model Deployment > Custom Deployment を選択します。
サービスの更新: Inference Service タブで、サービス一覧から対象のサービスを見つけます。 Actions 列で、Update をクリックします。
パラメーター設定フォームで、次の主要なパラメーターを設定します。パラメーターの詳細については、「カスタムデプロイ」をご参照ください。
Environment Information セクションで、ランタイムイメージと起動コマンドを設定します:
Image Configuration:Alibaba Cloud Image リストで、vLLM または SGLang イメージを選択します。
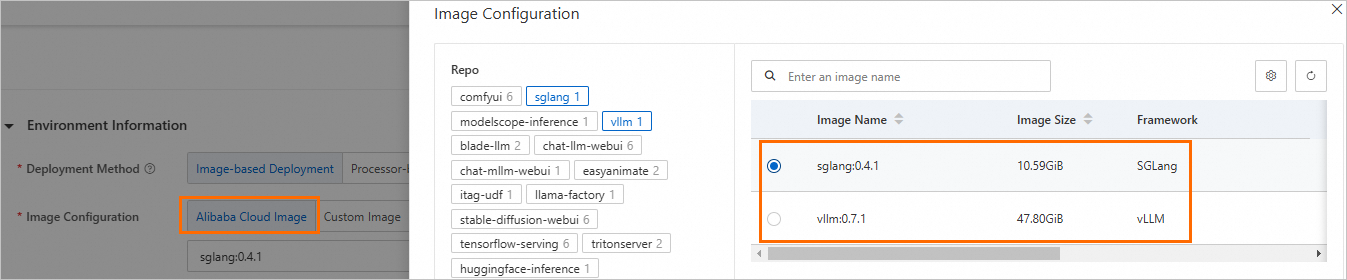
Command: イメージを選択すると、システムが起動コマンドを自動的に設定します。変更しないでください。
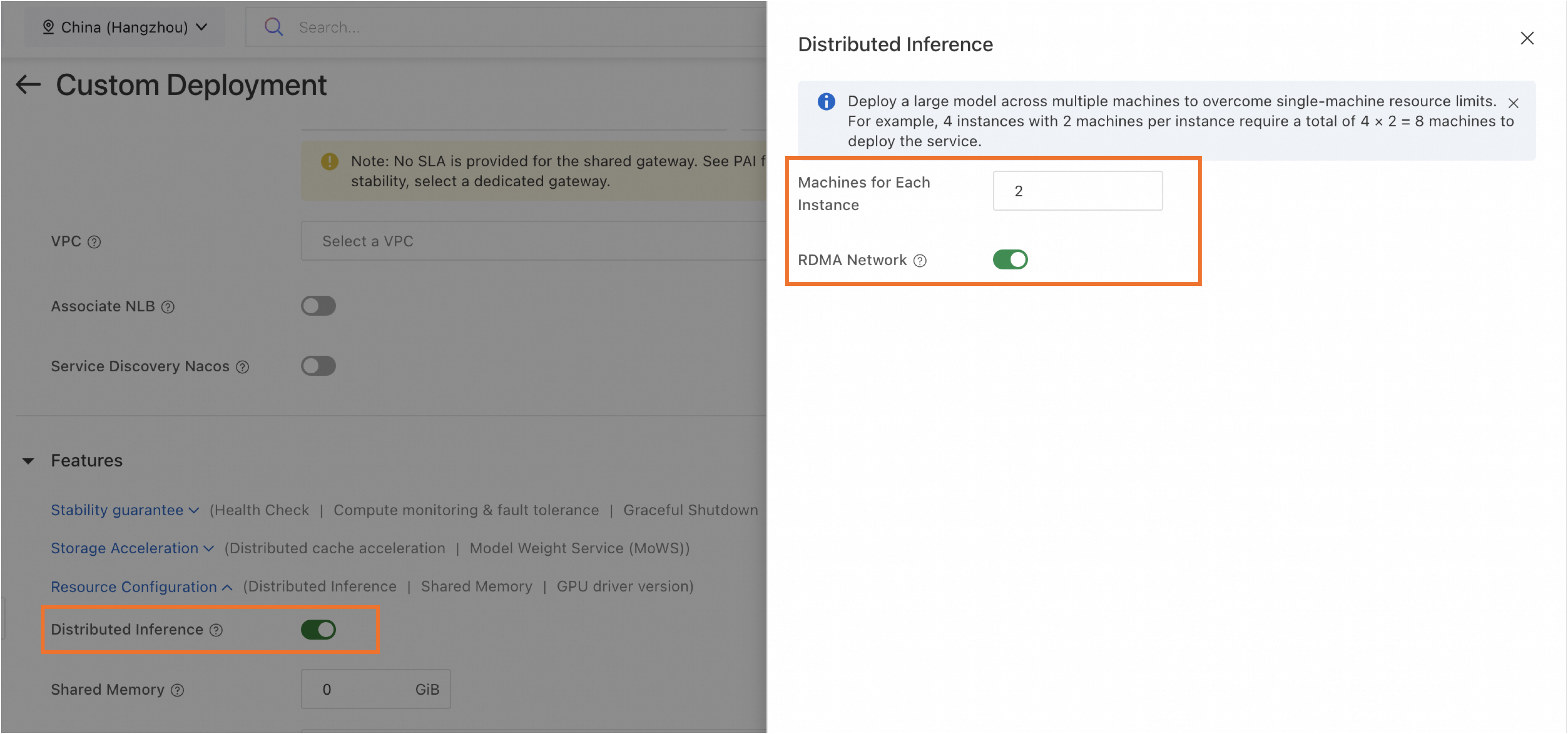
「Features」セクションで、「Distributed Inference」を有効化します。その後、以下の主要なパラメーターを設定します:
パラメーター
説明
Number of Machines for Single-Replica Deployment
単一のモデル推論インスタンスに使用されるマシン数。最小値は 2 です。
RDMA Network
RDMA を有効にすると、マシン間の高速ネットワーク接続が保証されます。
説明RDMA は、Lingjun リソースにデプロイされたサービスでのみ利用可能です。
パラメーターの設定が完了したら、Deploy または Update をクリックします。
付録
分散推論サービスをデプロイする際、Torch Distributed や Ray などのフレームワークを使用して、ネットワークを設定する必要があることがよくあります。VPC または RDMA を設定する場合、各インスタンスには複数のネットワークインターフェースコントローラー (NIC) があります。インスタンス間のネットワークにどの NIC を使用するかを指定する必要があります。
RDMA が有効な場合: デフォルトで RDMA NIC (net0) を使用します。
RDMA が無効な場合: ユーザーが設定した VPC NIC (eth1) を使用します。
関連する設定は環境変数を使用して渡します。起動コマンドでこれらを使用してください。例:
環境変数名 | 説明 | 値の例 |
RANK_ID | インスタンス ID。0 から始まり、1 ずつ増加します。 | 0 |
COMM_IFNAME | インスタンス間ネットワークに使用される NIC:
| net0 |
RANK_IP | インスタンス間ネットワークに使用される IP アドレス。COMM_IFNAME で指定された NIC の IP です。 | 11.*.*.* |
MASTER_ADDRESS | インスタンス 0 (RANK_ID = 0) の IP アドレス。インスタンス 0 の COMM_IFNAME で指定された NIC の IP です。 | 11.*.*.* |