Platform for AI (PAI) のLLM-Text Normalizer (DLC) コンポーネントを使用して、Unicodeテキストの正規化や、繁体字中国語から簡体字中国語への言語変換などの操作を実行できます。 入力Object Storage Service (OSS) データファイルは、JSONライン形式であり、次の要件を満たす必要があります。ファイルの各行は有効なJSONオブジェクトであり、ファイルは複数行のJSONオブジェクトで構成されますが、ファイルは有効なJSONオブジェクトではありません。 詳細については、「例」をご参照ください。
サポートされるコンピューティングリソース
アルゴリズムの説明
LLM-Text Normalizer (DLC) コンポーネントは、次の機能をサポートしています。
normalization Form Compatibility Composition (NFKC) メソッドを使用したUnicodeテキストの正規化。
ftfy.fix_text(text, normalization='NFKC')openccパッケージを使用した従来の中国語から簡体字への言語変換。
例:
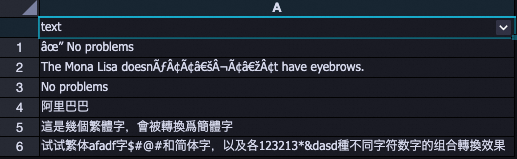
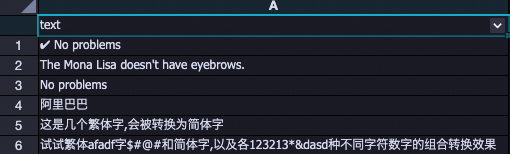
処理前
| 処理後
|
コンポーネントの設定
Machine Learning Designerのパイプラインページで、LLM-Text Normalizer (DLC) コンポーネントのパラメーターを設定します。
タブ | パラメーター | 必須 | 説明 | デフォルト値 | |
フィールドの設定 | Target Processフィールド | 可 | 処理するフィールドの名前。 | N/A | |
Unicodeテキストを正規化するかどうか (NFKCフォーム) | 不可 | NFKCメソッドを使用してUnicodeテキストを正規化するかどうかを指定します。 | 選択済み | ||
繁体字を簡体字に変換するかどうか | 不可 | 繁体字を簡体字中国語に変換するかどうかを指定します | 選択済み | ||
OutputDataを保存するためのOSSディレクトリ | 不可 | 生成されたデータが保存されるOSSディレクトリ。 このパラメーターを指定しない場合、ワークスペースのデフォルトパスが使用されます。 | N/A | ||
チューニング | プロセス数 | 不可 | プロセスの数。 | 8 | |
リソースグループの選択 | パブリックリソースグループ | 不可 | 使用するインスタンスタイプ (CPUまたはGPU) 、インスタンス数、および仮想プライベートクラウド (VPC) 。 | N/A | |
専用リソースグループ | 不可 | 使用するvCPU、メモリ、共有メモリの数、GPUの数、およびインスタンスの数。 | N/A | ||
最大実行時間 | 不可 | コンポーネントを実行できる最大期間。 この時間を超えると、ジョブは終了する。 | N/A | ||