LLM-LaTeX Remove Header (MaxCompute) コンポーネントを使用して、大規模言語モデル (LLM) のトレーニングに使用されるTeXテキストデータを前処理できます。 このコンポーネントは、<section-type>[optional-args]{name} 形式に一致する最初のセクションの前のコンテンツを削除します。
サポートされるコンピューティングリソース
アルゴリズム
LLM-LaTeX Remove Header (MaxCompute) コンポーネントは、次の正規表現を使用してLaTeXテキスト内のセクションを検索します。r' ^(.*?)(\\\ bchapter\b\*?(?:\[(.*?))\])?\{(.*?)\}|\\\ bpart\b\*?(?:\[(.*?))\])?\{(.*?)\}|\\\ bsection\b\*?(?:\[(.*?))\])?\{(.*?)\}|\\\ bsubsection\b\*?(?:\[(.*?))\])?\{(.*?)\}|\\\ bsubsection\b\*?(?:\[(.*?))\])?\{(.*?)\}|\\\ bparagraph\b\*?(?:\[(.*?))\])?\{(.*?)\}|\\\ bsubparagraph\b\*?(?:\[(.*?))\])?\{(.*?)\})'. 複数の一致パターンは縦棒 (|) で区切られています。
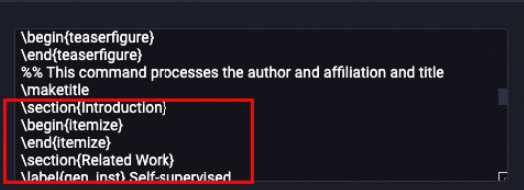
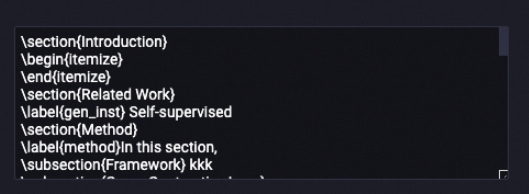
コンポーネントは、最初に見つかったセクションの前のすべてのコンテンツを削除します。 セクションラインと次のコンテンツは保持されます。 例:
処理前
| 処理後
|
コンポーネントの設定
Platform for AI (PAI) コンソールのMachine Learning Designerのパイプラインページで、LLM-LaTeX Remove Header (MaxCompute) コンポーネントのパラメーターを設定します。 下表に、各パラメーターを説明します。
タブ | パラメーター | 説明 |
フィールドの設定 | ターゲット列の選択 | 処理する列。The columns that you want to process. 複数の列を選択できます。 |
ヘッダーサンプルを削除しないかどうか | セクションが見つからないテキストサンプルを削除するかどうかを指定します。 | |
出力テーブルのライフサイクル | 値は正の整数です。 単位:日 デフォルト値: 28。 テーブルのデフォルトのライフサイクルが経過すると、コンポーネントによって生成された一時テーブルがリサイクルされます。 | |
チューニング | マップタスクのインスタンスごとのCPU数 | マップタスクの各インスタンスのCPU数。 有効な値: 50 ~ 800 デフォルト値:100 |
マップタスクのインスタンスあたりのメモリサイズ | マップタスクの各インスタンスのメモリサイズ。 有効な値: 256〜12288。 デフォルト値: 1024。 単位:MB。 | |
マップの入力データの最大サイズ | マップタスクの各インスタンスが処理できるデータの最大量。 有効な値: 1〜Integer.MAX_VALUE。 デフォルト値: 256 単位:MB。 このパラメーターを使用して、入力データのサイズを制御できます。 |