ユースケースに画像分類が含まれる場合、画像分類トレーニング (Torch) コンポーネントを使用して画像分類モデルを構築し、モデルの推論を実行できます。このトピックでは、画像分類トレーニング (Torch) コンポーネントの設定方法と使用方法について説明します。
前提条件
OSS が有効化されており、Machine Learning Studio が OSS へのアクセスを承認されている必要があります。詳細については、「OSS の有効化」および「Designer の権限付与」をご参照ください。
制限事項
このアルゴリズムコンポーネントは Designer でのみ利用可能です。
サポートされているコンピューティングエンジンは Deep Learning Container (DLC) です。
アルゴリズムについて
画像分類トレーニング (Torch) コンポーネントは、畳み込みニューラルネットワーク (CNN) と Transformer という 2 つの主要なモデルファミリーをサポートしています。ResNet、ResNeXt、HRNet、ViT、SwinT、MobileNetv2 などのアルゴリズムが含まれています。また、ImageNet に基づく事前学習済みモデルも提供しており、モデルの迅速なファインチューニングに役立ちます。
画像分類トレーニング (Torch) コンポーネントは、コンポーネントライブラリの [Computer Vision Algorithms] フォルダ配下にある [Offline Training Models] サブフォルダにあります。
コンポーネントの視覚的な設定
入力ポート
入力ポート (左から右へ)
データ型の制限
推奨される上流コンポーネント
必須
トレーニングデータのアノテーションファイル
OSS
いいえ
検証データのアノテーションファイル
OSS
いいえ
コンポーネントパラメーター
タブ
パラメーター
必須
説明
デフォルト値
フィールド設定
トレーニングモデルタイプ
はい
トレーニングに使用するアルゴリズムタイプ。Classification のみがサポートされています。
Classification
トレーニング出力の保存先 OSS ディレクトリ
はい
トレーニング済みモデルを保存する OSS ディレクトリ。例:
oss://examplebucket/yunji.cjy/designer_test。なし
トレーニングデータのアノテーション結果ファイルの OSS パス
いいえ
このパラメーターは、入力ポート経由でトレーニングデータのアノテーション結果ファイルを提供しない場合にのみ設定します。
説明入力ポートとこのパラメーターの両方でトレーニングデータのアノテーション結果ファイルを提供した場合、入力ポートが優先されます。
トレーニングデータのアノテーション結果ファイルの OSS パス。例:
oss://examplebucket/yunji.cjy/data/imagenet/meta/train_labeled.txt。train_labeled.txt ファイルの各行は、
absolute_path/image_name.jpg label_idの形式に従います。重要画像パスと ラベル ID はスペースで区切ります。
重要このコンポーネントは、ClsSourceImageList と ClsSourceItag の 2 つのトレーニングデータ形式をサポートしています。PAI のインテリジェントアノテーションモジュールでアノテーション付けされたデータファイルを直接使用できます。
検証データのアノテーション結果ファイルの OSS パス
いいえ
このパラメーターは、入力ポート経由で検証データのアノテーション結果ファイルを提供しない場合にのみ設定します。
説明入力ポートとこのパラメーターの両方で検証データのアノテーション結果ファイルを提供した場合、入力ポートが優先されます。
検証データのアノテーション結果ファイルの OSS パス。例:
oss://examplebucket/yunji.cjy/data/imagenet/meta/val_labeled.txt。val_labeled.txt ファイルの各行は、
absolute_path/image_name.jpg label_idの形式に従います。重要画像パスと ラベル ID はスペースで区切ります。
説明このコンポーネントは、ClsSourceImageList と ClsSourceItag の 2 つのトレーニングデータ形式をサポートしています。PAI のインテリジェントアノテーションモジュールでアノテーション付けされたデータファイルを直接使用できます。
なし
クラス名リストファイル
はい
このファイルは、画像分類のクラスリストを定義します。クラス名を直接入力するか、クラス名を含む TXT ファイルのパスを指定できます。
クラス名を直接入力する:
[name1,name2,...]の形式で、複数の名前をカンマで区切ります。例:[0, 1, 2]または[person, dog, cat]。TXT ファイルのパスを指定する:クラス名を TXT ファイルに書き込み、同じリージョンの OSS バケットにアップロードしてから、ここに OSS パスを入力します。
この場合、TXT ファイル内のクラス名はカンマまたは改行 (\n) で区切ります。例:
0, 1, 2または0,\n1,\n2\n。このパラメーターが空の場合、クラス名はデフォルトで
str(0)からstr(num_classes-1)になります。ここで、num_classesはクラスの数です。たとえば、3 つのクラスがある場合、デフォルトのクラス名リストは
0, 1, 2です。
なし
データソース形式
はい
入力データの形式。サポートされている値:ClsSourceImageList および ClsSourceItag。
ClsSourceItag
事前学習済みモデルの OSS パス
いいえ
独自の事前学習済みモデルがある場合は、このパラメーターにその OSS パスを設定します。このパラメーターを設定しない場合、コンポーネントは PAI が提供するデフォルトの事前学習済みモデルを使用します。
なし
パラメーター設定
画像分類のバックボーンモデル
はい
使用するバックボーンモデル。サポートされているモデル:
resnet
resnext
hrnet
vit
swint
mobilenetv2
inceptionv4
resnet
画像クラスの数
はい
データ内のクラスラベルの数。
なし
画像のリサイズサイズ
はい
すべての画像を固定の高さと幅にサイズ変更します。デフォルトでは、高さと幅は同じです。
224
最適化手法
はい
モデルトレーニングの最適化手法。サポートされている値:
SGD
Adam
SGD
初期学習率
はい
初期学習率。
0.05
学習率スケジュール
はい
スケジュールを使用して学習率を制御します。サポートされているスケジュールは step です。各ステージの学習率を手動で指定します。
step
lr ステップ
はい
学習率スケジュールと併用します。複数のステップはカンマで区切ります。指定された各エポックで、学習率は 0.1 倍に減衰します。
例:初期学習率が 0.1、総トレーニングエポック数が 20、lr ステップが 5,10 の場合、エポック 1~5 の学習率は 0.1、エポック 5~10 の学習率は 0.01、エポック 10~20 の学習率は 0.001 になります。
[30,60,90]
トレーニングのバッチサイズ
はい
トレーニングの反復ごと (ステップごと) に処理されるサンプル数。
2
評価のバッチサイズ
はい
評価 (検証) の反復ごと (ステップごと) にロードされるサンプル数。
2
総トレーニングエポック数
はい
1 エポックは、すべてのサンプルを 1 回完全に通過することを意味します。総エポック数は、完全な通過の回数です。
1
チェックポイントの保存頻度
いいえ
モデルのチェックポイントを保存する頻度。値が 1 の場合、エポックごとにモデルが保存されます。
1
エクスポートされるモデルのタイプ
はい
エクスポートされるモデルの形式。サポートされている形式:
raw
onnx
raw
実行チューニング
トレーニングデータ読み取り用の GPU あたりのプロセス数
いいえ
トレーニングデータを読み取るために使用される GPU あたりのプロセス数。
4
半精度を有効にする
いいえ
このオプションを選択すると、トレーニングに FP16 半精度が使用されます。これにより、メモリ使用量が削減されます。
なし
スタンドアロンまたは分散 DLC
はい
コンポーネントを実行するコンピューティングエンジン。ニーズに基づいて選択します。サポートされているエンジン:
スタンドアロン DLC
分散 DLC
スタンドアロン DLC
ワーカー数
いいえ
このパラメーターは、エンジンが分散 DLC の場合にのみ設定します。
トレーニング中の同時ワーカープロセス数。
1
CPU インスタンスタイプ
いいえ
このパラメーターは、エンジンが分散 DLC の場合にのみ設定します。
使用する CPU インスタンスタイプ。
16 vCPU + 64 GB メモリ (ecs.g6.4xlarge)
GPU インスタンスタイプ
はい
使用する GPU インスタンスタイプ。
8 vCPU + 60 GB メモリ + 1 × P100 (ecs.gn5-c8g1.2xlarge)
出力ポート
出力ポート
データ型
下流コンポーネント
出力モデル
OSS パス。これは、[フィールド設定] タブの [トレーニングの出力を保存する OSS ディレクトリ] パラメーターに設定する OSS パスです。トレーニング済みモデルがこのパスに保存されます。
例
画像分類トレーニング (Torch) コンポーネントを使用して、次のワークフローを構築できます。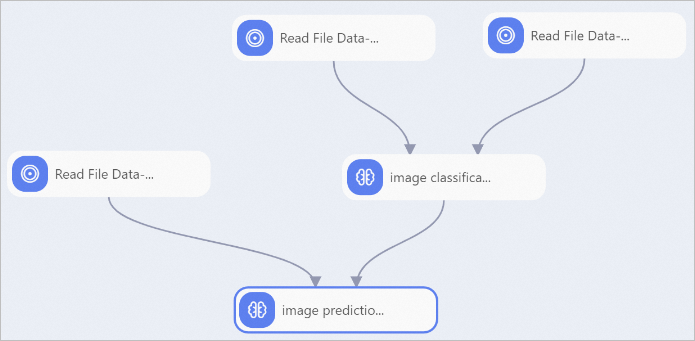 この例では、コンポーネントを次のように設定します。
この例では、コンポーネントを次のように設定します。
PAI のインテリジェントアノテーションモジュールを使用して、データを準備し、アノテーションを付けます。詳細については、「」および「インテリジェントアノテーション (iTAG)」をご参照ください。
OSS データの読み取り-1 および OSS データの読み取り-2 コンポーネントを使用して、トレーニングデータと検証データのアノテーション結果ファイルをロードします。各 OSS データの読み取りコンポーネントの [OSS Data Path] パラメーターを、対応するファイルが保存されている OSS パスに設定します。
重要データソース形式として ClsSourceItag を選択します。
2 つの OSS データの読み取りコンポーネントを画像分類トレーニング (Torch) コンポーネントに接続し、そのパラメーターを設定します。詳細については、「コンポーネントの視覚的な設定」セクションをご参照ください。
OSS データの読み取り-3 コンポーネントを使用して、予測データファイルをロードします。OSS データの読み取りコンポーネントの [OSS Data Path] パラメーターを、予測データファイルが保存されている OSS パスに設定します。
汎用画像予測コンポーネントを使用してオフライン推論を実行します。次の主要なパラメーターを設定します。詳細については、「汎用画像予測」をご参照ください。
モデルタイプ:torch_classifier を選択します。
モデルの OSS パス:画像分類トレーニング (Torch) コンポーネントから出力されたトレーニング済みモデルへの OSS パス。