Elastic Algorithm Service (EAS) Scalable Job サービスは、モデルトレーニングおよび推論シナリオをサポートしています。トレーニングシナリオでは、単一インスタンス (ジョブ) 内でタスクをループ実行することをサポートし、キュー長に基づいて自動スケーリングを提供します。推論シナリオでは、各リクエストの実行進捗を追跡し、より公平なタスクスケジューリングを可能にします。このトピックでは、Scalable Job サービスの使用方法について説明します。
利用シーン
トレーニングシナリオ
トレーニングシナリオでは、Scalable Job サービスを次のように使用できます。
-
実装: フロントエンドとバックエンドが分離されたアーキテクチャを使用しており、常駐フロントエンドサービスと Scalable Job サービスのデプロイをサポートしています。
-
アーキテクチャの利点: フロントエンドサービスは通常、必要なリソースが少なく、低コストです。常駐フロントエンドサービスをデプロイすることで、頻繁なサービス作成を回避し、待機時間を短縮します。バックエンド Scalable Job サービスは、単一インスタンス (ジョブ) 内でトレーニングタスクをループ実行することをサポートしており、インスタンスが繰り返し起動およびリリースされるのを防ぎ、スループットを向上させます。また、バックエンド Scalable Job サービスは、キュー長が長すぎたり短すぎたりすると、自動的にスケールアウトまたはスケールインし、効率的なリソース利用を保証します。
推論シナリオ
モデル推論シナリオでは、Scalable Job サービスは各リクエストの実行進捗を追跡し、より公平なタスクスケジューリングを実現できます。
応答時間の長い推論サービスには、EAS 非同期推論サービスを使用します。ただし、非同期サービスには次の問題があります。
-
キューサービスは、リクエストがアイドルインスタンスに優先的にプッシュされることを保証できないため、リソース利用率が不足します。
-
サービスのスケーリングイン中に、インスタンスが終了する前にインスタンス内のリクエストが完了することをサービスが保証できないため、リクエストが中断され、再スケジュールされる可能性があります。
これらの問題を解決するために、Scalable Job サービスは次の最適化を提供します。
-
最適化されたサブスクリプションロジック: リクエストをアイドルインスタンスに優先的にプッシュします。インスタンスが終了する前に、現在のリクエストが処理されるまでブロックして待機します。
-
スケーリング効率の向上: 定期的なレポートメカニズムとは異なり、キューサービスには組み込みのモニタリングサービスがあり、スケーリングを迅速にトリガーするため、スケーリング応答時間を数分から約 10 秒に短縮します。
基本アーキテクチャ
アーキテクチャは、次の図に示すように、キューサービス、Horizontal Pod Autoscaler (HPA) コントローラー、および Scalable Job サービスの 3 つの部分で構成されています。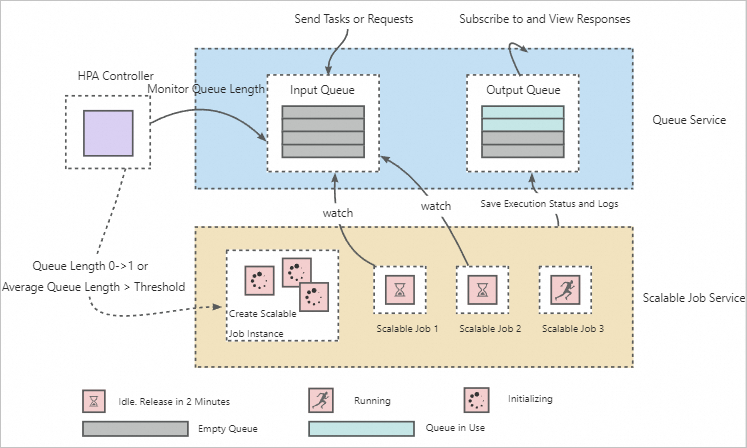
仕組み:
-
キューサービスは、リクエストまたはタスクの送信と実行を分離し、単一の Scalable Job サービスが複数の異なるリクエストまたはタスクを処理できるようにします。
-
HPA コントローラーは、キューサービス内の保留中のトレーニングタスクとリクエストの数を監視し、Scalable Job サービスインスタンスの弾力的なスケーリングを実装します。Scalable Job サービスのデフォルトの自動スケーリング構成は次のとおりです。パラメーターの詳細については、「水平オートスケーリング」をご参照ください。
{ "behavior":{ "onZero":{ "scaleDownGracePeriodSeconds":60 # スケールダウンしてゼロになるまでの猶予期間 (秒)。 }, "scaleDown":{ "stabilizationWindowSeconds":1 # スケールインの安定化ウィンドウ (秒)。 } }, "max":10, # 最大インスタンス数 (ジョブ)。 "min":1, # 最小インスタンス数 (ジョブ)。 "strategies":{ "avg_waiting_length":2 # 各インスタンス (ジョブ) の平均負荷しきい値。 } }
サービスデプロイメント
推論サービスのデプロイ
プロセスは、非同期推論サービスの作成と似ています。次の例に基づいてサービス構成ファイルを作成します。
{
"containers": [
{
"image": "registry-vpc.cn-shanghai.aliyuncs.com/eas/eas-container-deploy-test:202010091755",
"command": "/data/eas/ENV/bin/python /data/eas/app.py",
"port": 8000,
}
],
"metadata": {
"name": "scalablejob",
"type": "ScalableJob",
"rpc.worker_threads": 4,
"instance": 1,
}
}type を ScalableJob に設定して、推論サービスを Scalable Job サービスとしてデプロイします。その他のパラメーター設定の詳細については、「JSON デプロイメント」をご参照ください。推論サービスのデプロイ方法の詳細については、「オンライン写真生成推論サービスのデプロイ」をご参照ください。
サービスがデプロイされると、キューサービスと Scalable Job サービスが自動的に作成されます。Autoscaler (水平オートスケーリング) 機能もデフォルトで有効になります。
トレーニングサービスのデプロイ
統合デプロイメントと独立デプロイメントの 2 つのデプロイ方法がサポートされています。実装ロジックと構成の詳細を以下に説明します。具体的なデプロイ手順については、「オートスケーリング Kohya トレーニングサービスのデプロイ」をご参照ください。
-
実装ロジック
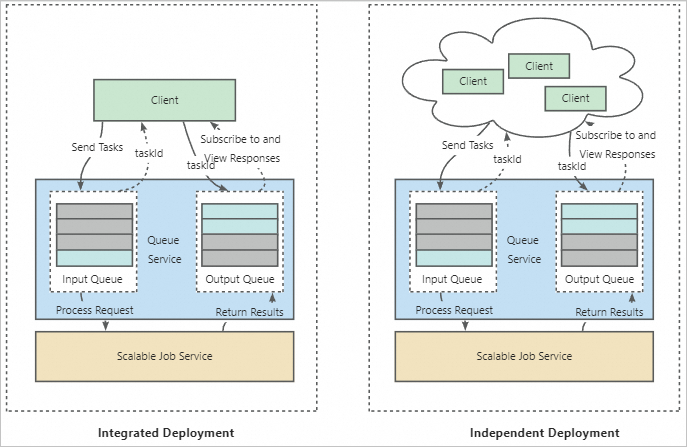
-
統合デプロイメント: キューサービスと Scalable Job サービスに加えて、EAS はフロントエンドサービスを作成します。フロントエンドサービスはユーザーリクエストを受信し、それらをキューサービスに転送します。フロントエンドサービスは Scalable Job サービスのクライアントと見なすことができます。このモードでは、Scalable Job サービスは一意のフロントエンドサービスにバインドされ、そのフロントエンドサービスから送信されたトレーニングタスクのみを実行できます。
-
独立デプロイメント: この方法はマルチユーザーシナリオに適しています。このモードでは、Scalable Job サービスは共有バックエンドサービスとして機能し、複数のフロントエンドサービスにバインドできます。各ユーザーは独自のフロントエンドサービスからトレーニングタスクを送信できます。バックエンドジョブサービスは、トレーニングタスクを実行するために対応するジョブインスタンスを作成します。各ジョブインスタンスは異なるトレーニングタスクを順次実行できるため、複数のユーザーがトレーニングリソースを共有できます。これにより、トレーニングタスクを複数回作成することを回避し、コストを効果的に削減できます。
-
-
構成の詳細
Scalable Job サービスをデプロイする際は、カスタムイメージ環境を提供します。Kohya シナリオでは、EAS の `kohya_ss` イメージプリセットを直接使用できます。イメージには、トレーニングタスクの実行に必要なすべての依存関係が含まれている必要があります。トレーニングタスクの実行環境としてのみ機能するため、開始コマンドやポート番号を構成する必要はありません。トレーニングタスクが開始する前に初期化タスクを実行するには、初期化コマンドを構成できます。EAS は、これらのタスクを実行するためにインスタンス (ジョブ) 内に個別のプロセスを作成します。カスタムイメージの準備方法については、「カスタムイメージ」をご参照ください。EAS のプリセットイメージアドレスは、eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2 です。
統合デプロイメント
EAS が提供する `kohya_ss` プリセットイメージを使用する次の例に基づいて、サービス構成ファイルを作成します。
{ "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJobService" }, "front_end": { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2", "port": 8001, "script": "python -u kohya_gui.py --listen 0.0.0.0 --server_port 8001 --data-dir /workspace --headless --just-ui --job-service" } }主要なパラメーター設定を以下に説明します。その他のパラメーター設定については、「JSON デプロイメント」をご参照ください。
-
type を ScalableJobService に設定します。
-
デフォルトでは、フロントエンドサービスは Scalable Job サービスと同じリソースグループを使用します。システムはデフォルトで 2 vCPU と 8 GB のメモリを割り当てます。
-
リソースグループまたはリソースをカスタマイズするには、次の例をご参照ください。
{ "front_end": { "resource": "", # フロントエンドサービス専用のリソースグループ。 "cpu": 4, "memory": 8000 } } -
デプロイするインスタンスタイプをカスタマイズするには、次の例をご参照ください。
{ "front_end": { "instance_type": "ecs.c6.large" } }
-
独立デプロイメント
EAS が提供する `kohya_ss` プリセットイメージを使用する次の例に基づいて、サービス構成ファイルを作成します。
{ "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJob" } }type を ScalableJob に設定します。その他のパラメーター設定については、「JSON デプロイメント」をご参照ください。
このモードでは、フロントエンドサービスを手動でデプロイし、その中でリクエストプロキシを実装する必要があります。プロキシは受信したリクエストを Scalable Job サービスのキューに転送し、フロントエンドサービスをバックエンドジョブサービスにバインドします。詳細については、「キューサービスへのデータ送信」をご参照ください。
-
サービス呼び出し
Scalable Job サービスを呼び出す際に、トレーニングシナリオと推論シナリオを区別するには、taskType フィールドを command または query に設定します。
-
command: トレーニングサービスを識別します。
-
query: 推論サービスを識別します。
サービスを呼び出す際には、`taskType` を明示的に指定する必要があります。以下に例を示します。
-
HTTP 呼び出し: 推論サービスの場合、`{Wanted_TaskType}` を `query` に置き換えます。
curl http://166233998075****.cn-shanghai.pai-eas.aliyuncs.com/api/predict/scalablejob?taskType={Wanted_TaskType} -H 'Authorization: xxx' -D 'xxx' -
SDK を使用する場合は、`tags` パラメーターを使用して `taskType` を指定します。次の例では、推論サービスの場合、`wanted_task_type` を `query` に置き換えます。
# タスクまたはリクエストを送信するための入力キューを作成します。 queue_client = QueueClient('166233998075****.cn-shanghai.pai-eas.aliyuncs.com', 'scalabejob') queue_client.set_token('xxx') queue_client.init() tags = {"taskType": "wanted_task_type"} # 入力キューにタスクまたはリクエストを送信します。 index, request_id = inputQueue.put(cmd, tags)
結果の取得:
-
推論サービス: EAS キューサービスの SDK を使用して、出力キューから結果を取得します。詳細については、「キューサービスをサブスクライブ」をご参照ください。
-
トレーニングサービス: サービスをデプロイする際に OSS マウントを構成します。これにより、トレーニング結果が OSS パスに直接保存され、永続ストレージが実現されます。詳細については、「オートスケーリング Kohya トレーニングサービスのデプロイ」をご参照ください。
ログ収集の構成
EAS Scalable Job サービスは、enable_write_log_to_queue 設定を提供します。この設定を使用して、リアルタイムログをキューに書き込みます。
{
"scalable_job": {
"enable_write_log_to_queue": true
}
}-
トレーニングシナリオ: この設定はデフォルトで有効になっています。リアルタイムログは出力キューに書き戻されます。EAS キューサービス SDK を使用して、トレーニングログをリアルタイムで取得できます。詳細については、「カスタムフロントエンドサービスイメージを使用して Scalable Job サービスを呼び出す」をご参照ください。
-
推論シナリオ: この設定はデフォルトで無効になっています。ログは stdout を使用してのみ出力できます。
参考文献
EAS Scalable Job サービスのより詳細なシナリオについては、次のトピックをご参照ください。