Mixture-of-Experts (MoE) モデルは、スパース活性化メカニズムを使用して計算コストを削減しつつ、数兆パラメーター規模を実現します。しかし、このアプローチは従来の推論デプロイメントに課題をもたらします。エキスパート並列化 (EP) は、MoE モデル向けに設計された分散戦略です。異なるエキスパートを別々の GPU にデプロイし、リクエストに対して動的ルートを使用します。このメソッドは GPU メモリのボトルネックを解決し、並列計算のパフォーマンスを向上させ、デプロイコストを大幅に削減します。このトピックでは、Platform for AI (PAI) の Elastic Algorithm Service (EAS) で MoE モデルのエキスパート並列化 (EP) と Prefill-Decode (PD) 分離を有効にして、より高い推論スループットとコスト効率を実現する方法について説明します。
ソリューションアーキテクチャ
Alibaba Cloud の Platform for AI (PAI) は、本番環境レベルの EP デプロイメントをサポートする Elastic Algorithm Service (EAS) を提供します。EAS は、PD 分離、大規模な EP、計算と通信の協調最適化、MTP などのテクノロジーを統合し、多次元共同最適化という新しいパラダイムを創出します。

メリット:
ワンクリックデプロイメント:EAS は、組み込みイメージ、オプションのリソース、実行コマンドを備えた EP デプロイメントテンプレートを提供します。これにより、複雑な分散デプロイメントがウィザード形式のプロセスに簡素化され、基盤となる実装を管理する必要がなくなります。
集約されたサービス管理:Prefill、Decode、LLM インテリジェントルーターなどのサブサービスのライフサイクルを、統合ビューから個別に監視、スケーリング、管理できます。
EP サービスのデプロイ
このセクションでは、DeepSeek-R1-0528-PAI-optimized モデルを例として使用します。この PAI 最適化モデルは、より高いスループットとより低いレイテンシーをサポートします。次の手順を実行します:
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、Elastic Algorithm Service (EAS) をクリックします。
[推論サービス] タブで [サービスをデプロイ] をクリックします。[シナリオベースのモデルデプロイメント] セクションで [LLM デプロイメント] をクリックします。
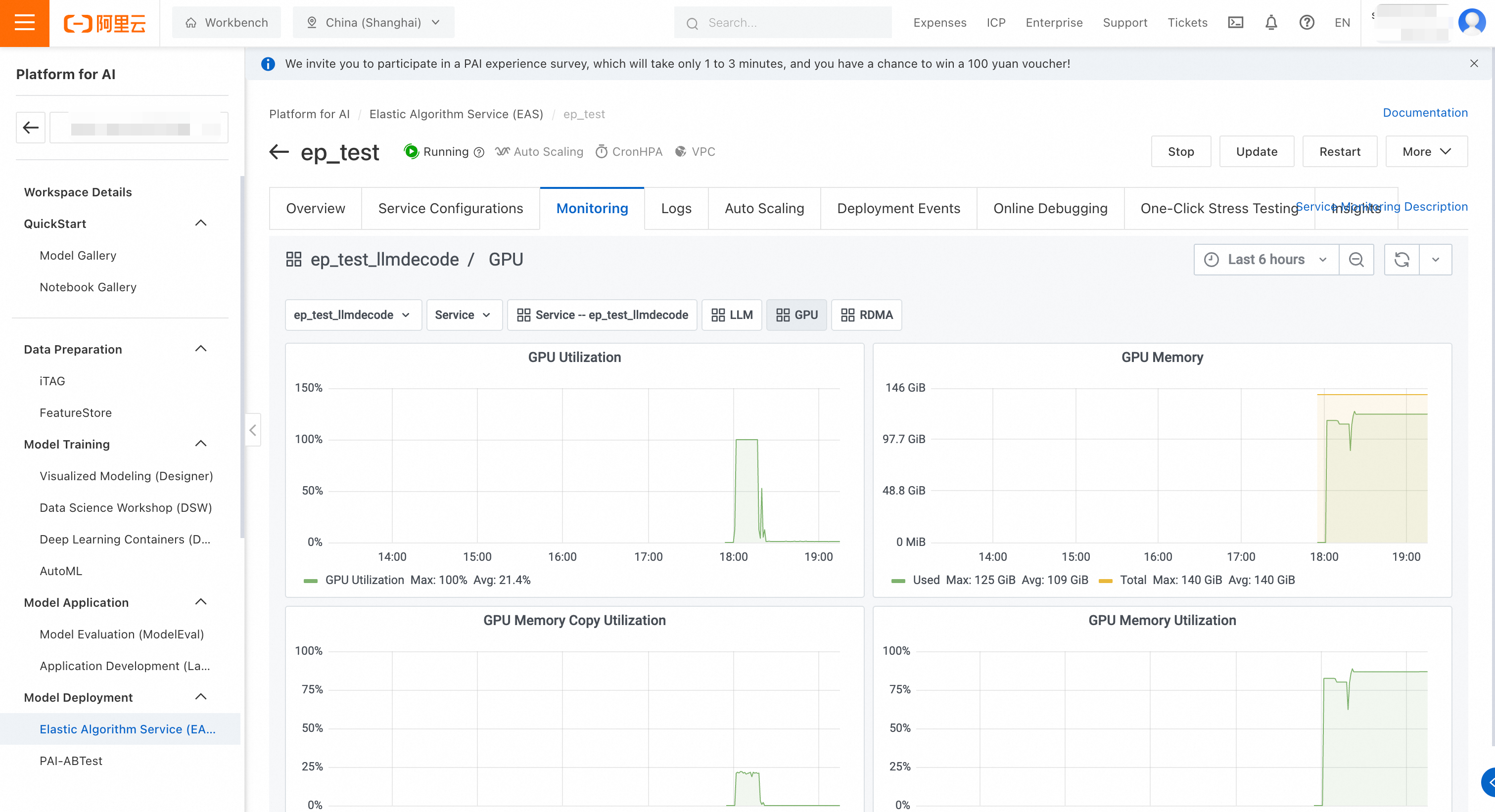
[モデル設定] セクションで、パブリックモデル DeepSeek-R1-0528-PAI-optimized を選択します。
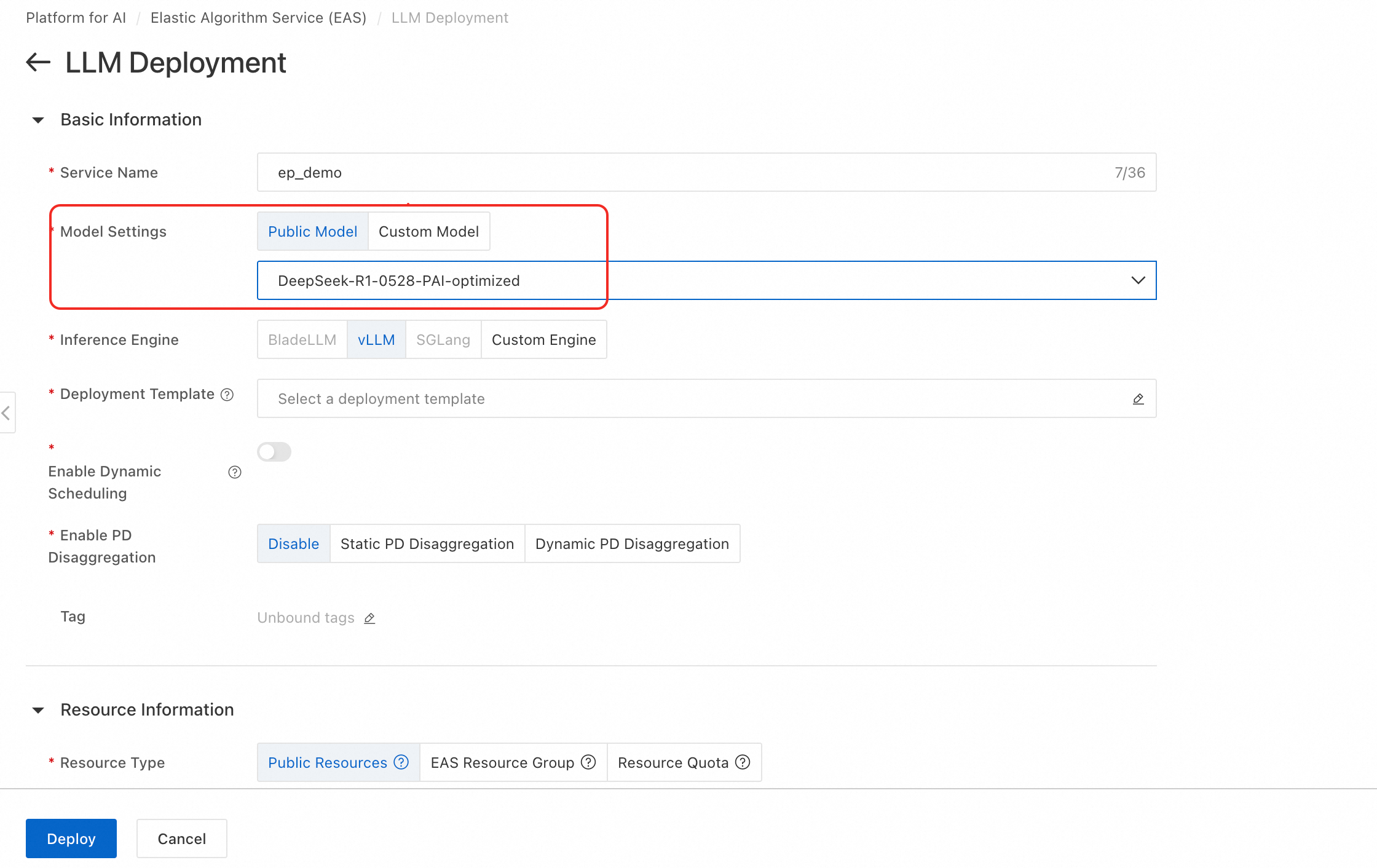
推論エンジンを vLLM に、デプロイメントテンプレートを [EP+PD Separation-PAI Optimized] に設定します。
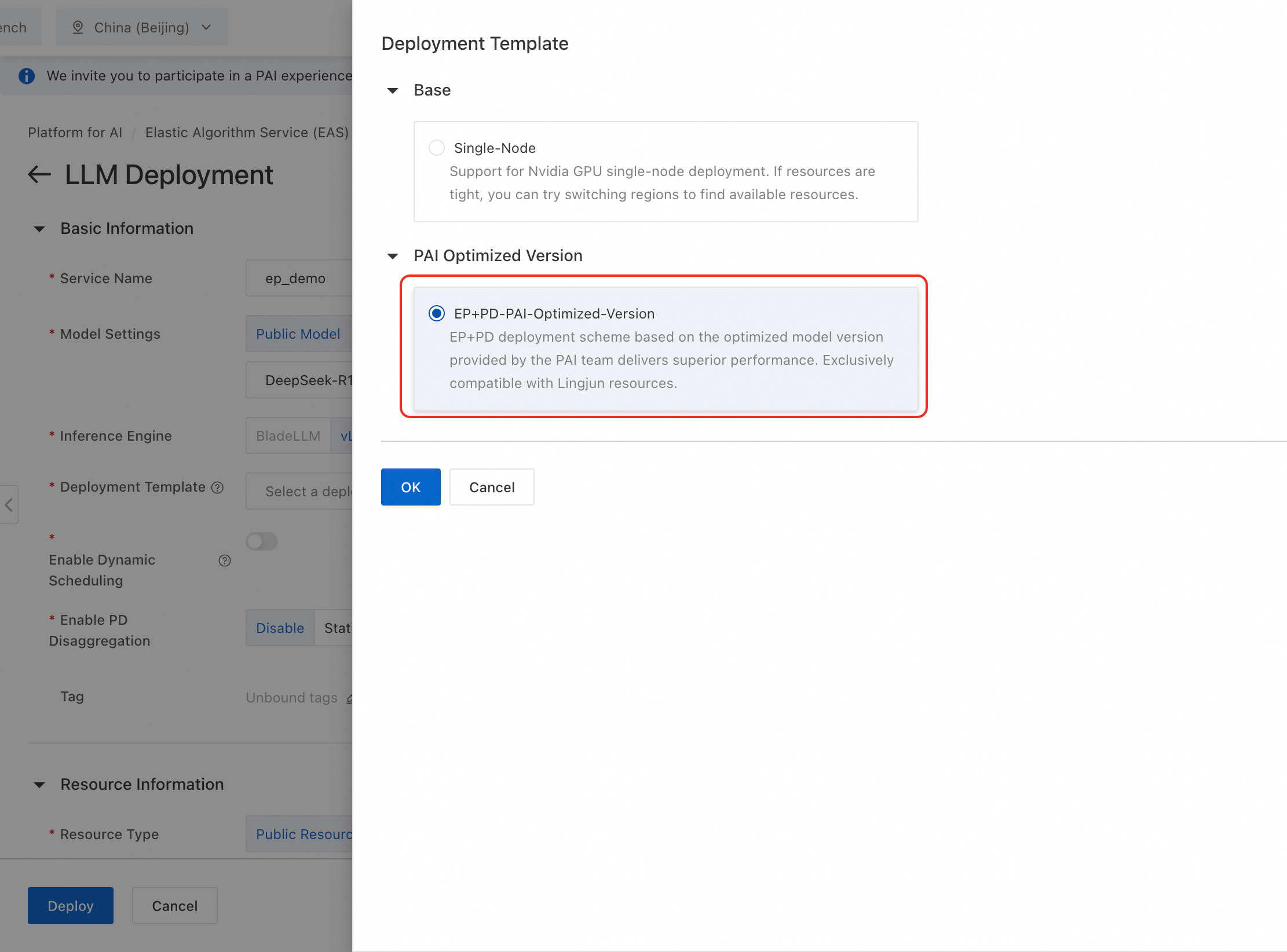
Prefill サービスと Decode サービスのデプロイリソースを設定します。パブリックリソースまたはリソースクォータを選択できます。
パブリックリソース:迅速な試用や開発テストに適しています。利用可能な仕様は
ml.gu8tea.8.48xlargeまたはml.gu8tef.8.46xlargeです。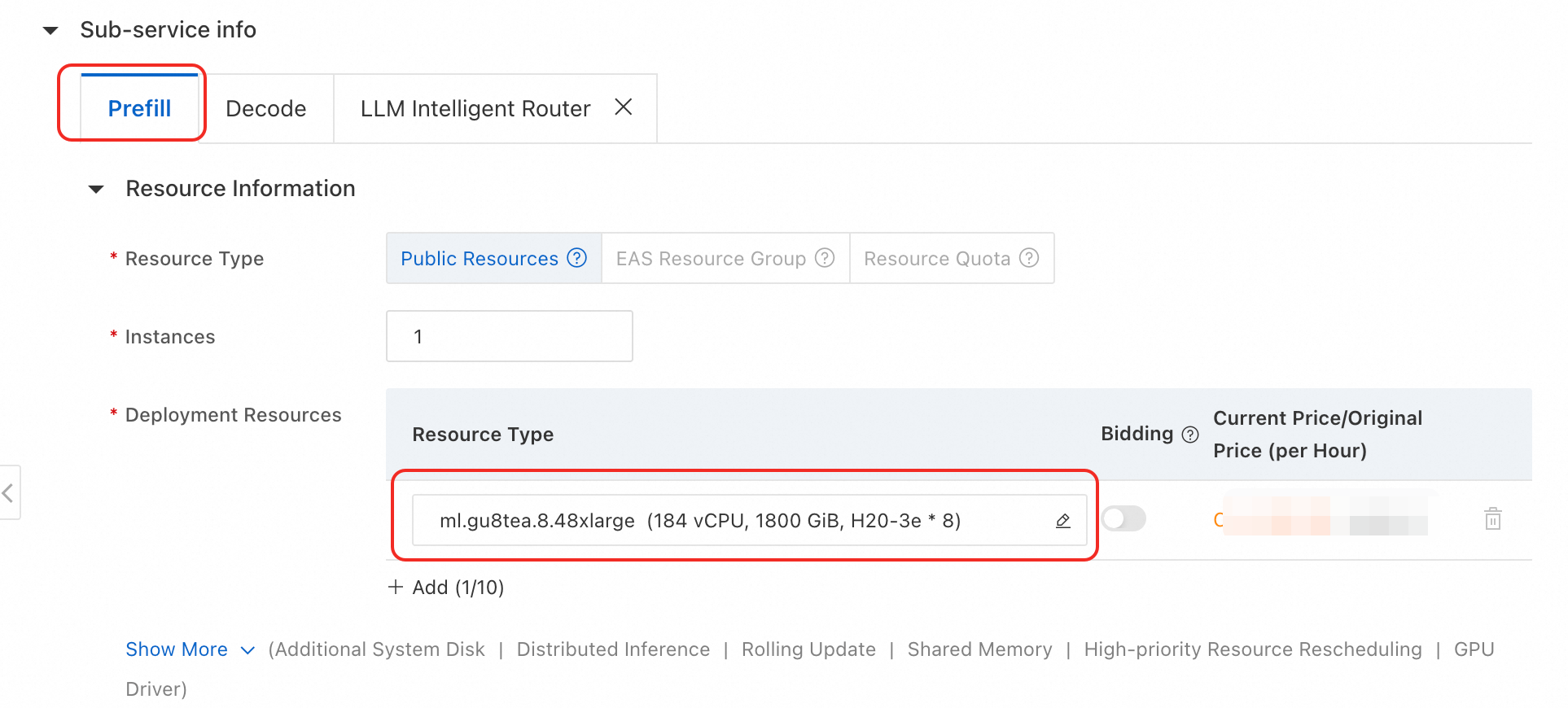
リソースクォータ:リソースの安定性と隔離を確保するために、本番環境で推奨されます。利用可能なリソース構成がない場合、このタイプは選択できません。
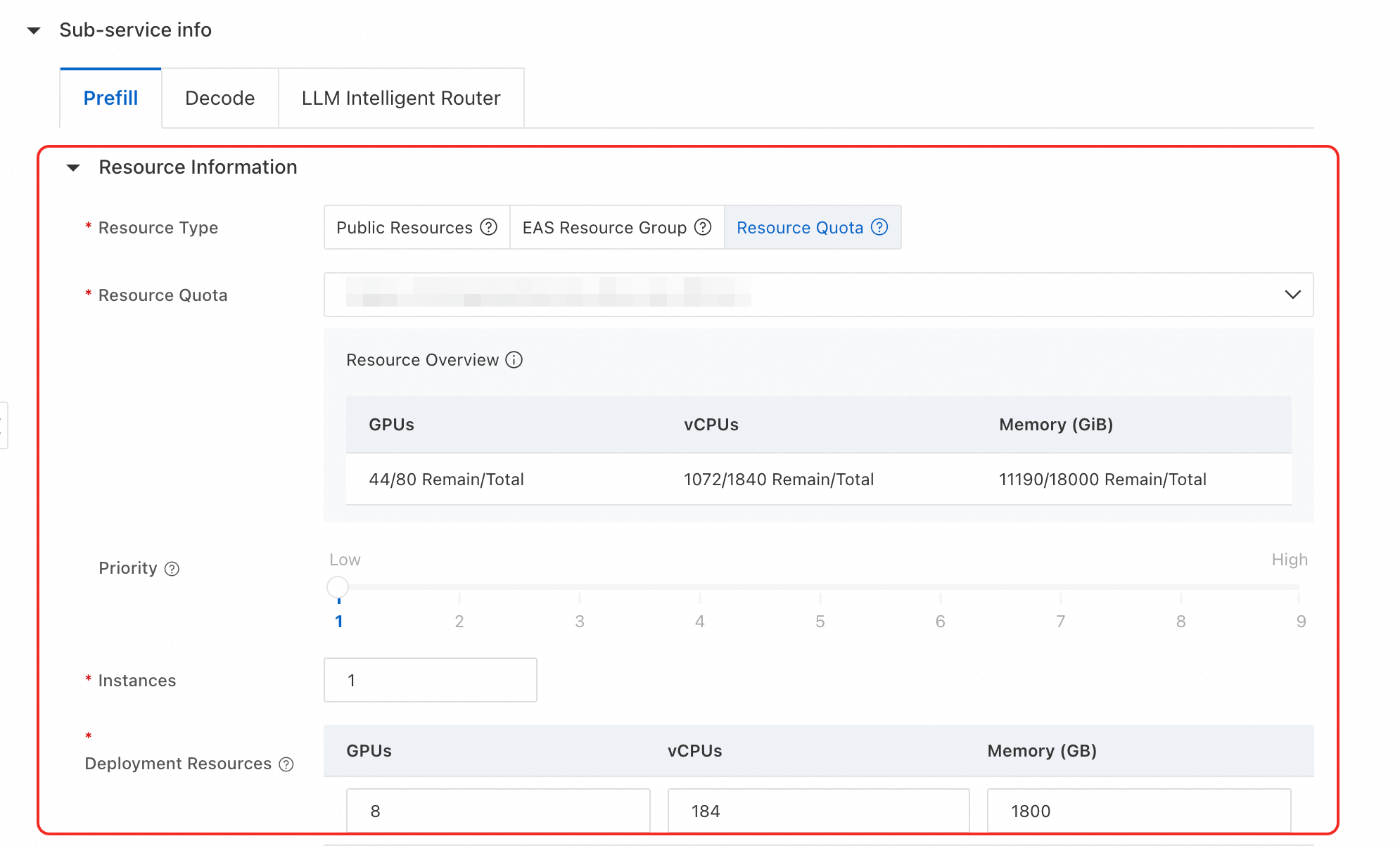
(オプション) パフォーマンスを最適化するためにデプロイパラメーターを調整します。
インスタンス数:Prefill と Decode のインスタンス数を調整して、PD 比率を変更します。デプロイメントテンプレートのデフォルトのインスタンス数は 1 です。
並列化パラメーター:環境変数で、Prefill サービスと Decode サービスの
EP_SIZE、DP_SIZE、TP_SIZEなどの並列化パラメーターを調整できます。デプロイメントテンプレートでは、Prefill のTP_SIZEのデフォルト値は 8 に設定され、Decode のEP_SIZEとDP_SIZEのデフォルト値は 8 に設定されています。説明DeepSeek-R1-0528-PAI-optimized のモデルの重みを保護するため、プラットフォームは推論エンジンの実行コマンドを公開しません。重要なパラメーターは環境変数を使用して変更できます。
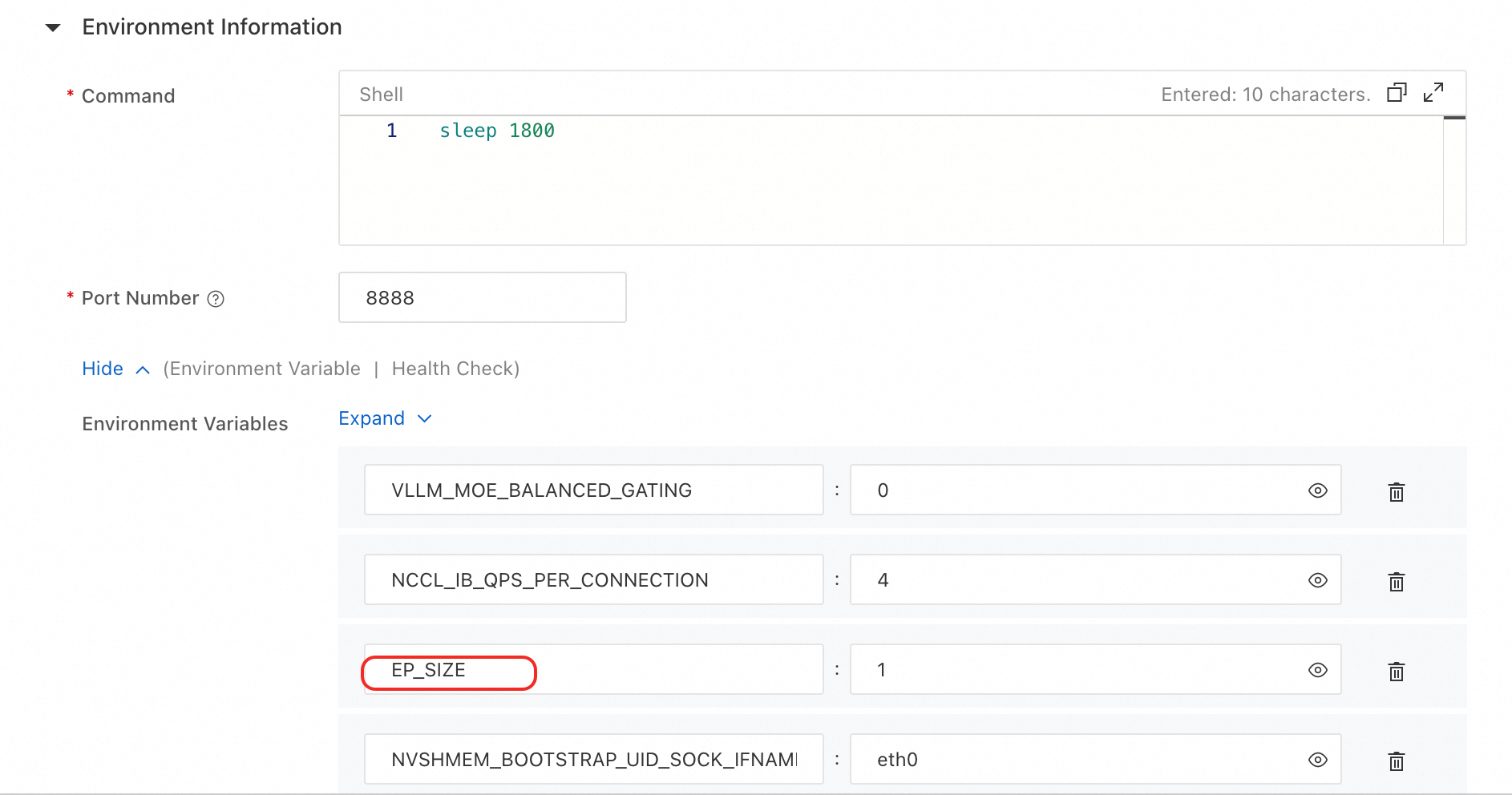
[デプロイ] をクリックし、サービスが開始するまで待ちます。このプロセスには約 40 分かかります。
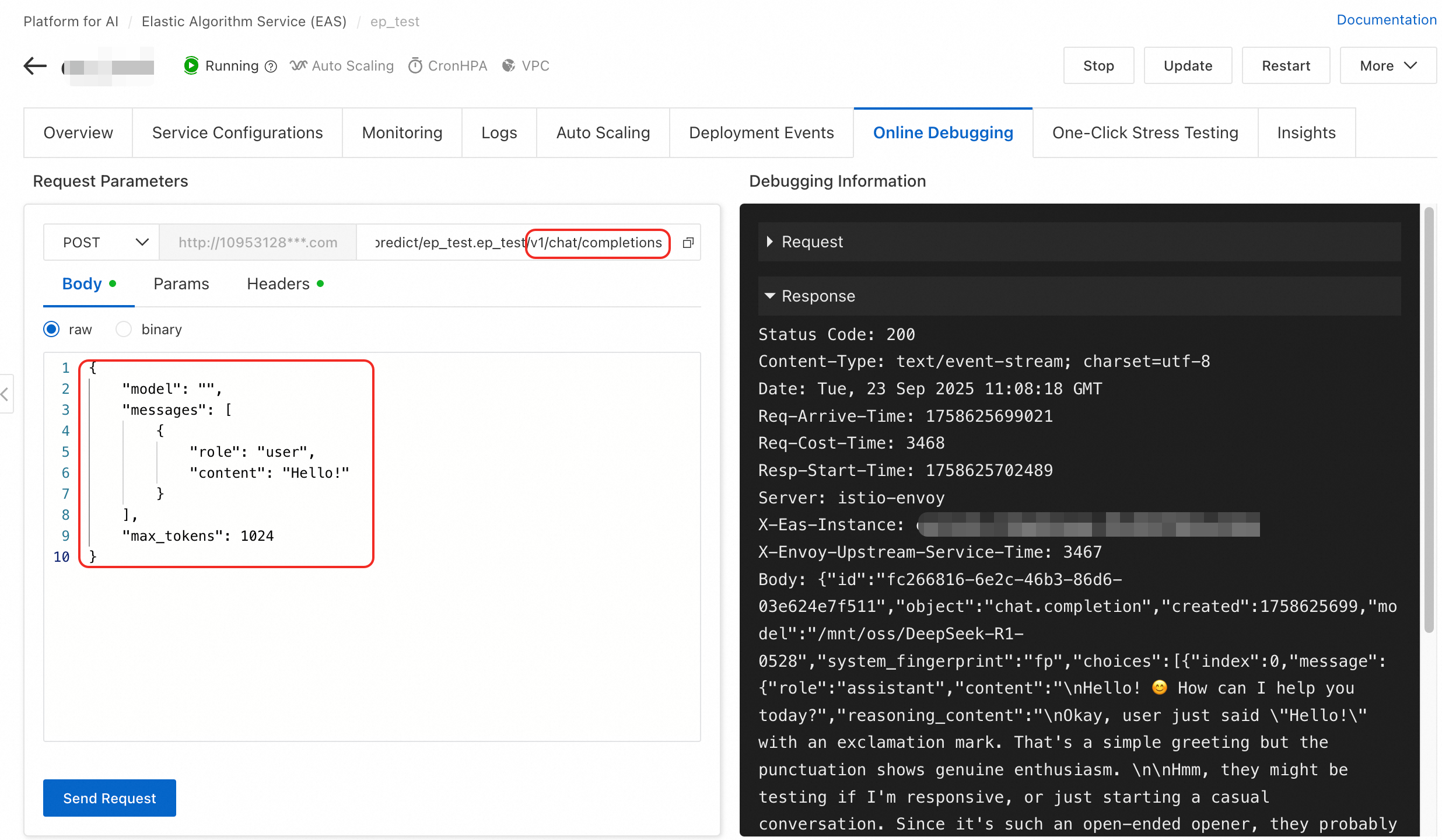
サービスステータスを確認します。デプロイが完了したら、サービス詳細ページの [オンラインデバッグ] タブに移動して、サービスが正常に実行されているかどうかをテストします。
説明API 呼び出しとサードパーティアプリケーションとの連携の詳細については、「LLM サービスの呼び出し」をご参照ください。
OpenAI フォーマットに従ってリクエストを作成します。URL パスに
/v1/chat/completionsを追加します。リクエストボディは次のとおりです:{ "model": "", "messages": [ { "role": "user", "content": "Hello!" } ], "max_tokens": 1024 }[リクエストの送信] をクリックします。応答ステータスが 200 で、モデルから正常な回答が返されれば、サービスは正しく実行されています。
EP サービスの管理
サービスリストページで、サービス名をクリックして詳細ページに移動し、詳細な管理を行います。このページでは、集約サービス全体、および Prefill、Decode、LLM インテリジェントルーターなどのサブサービスのビューが提供されます。
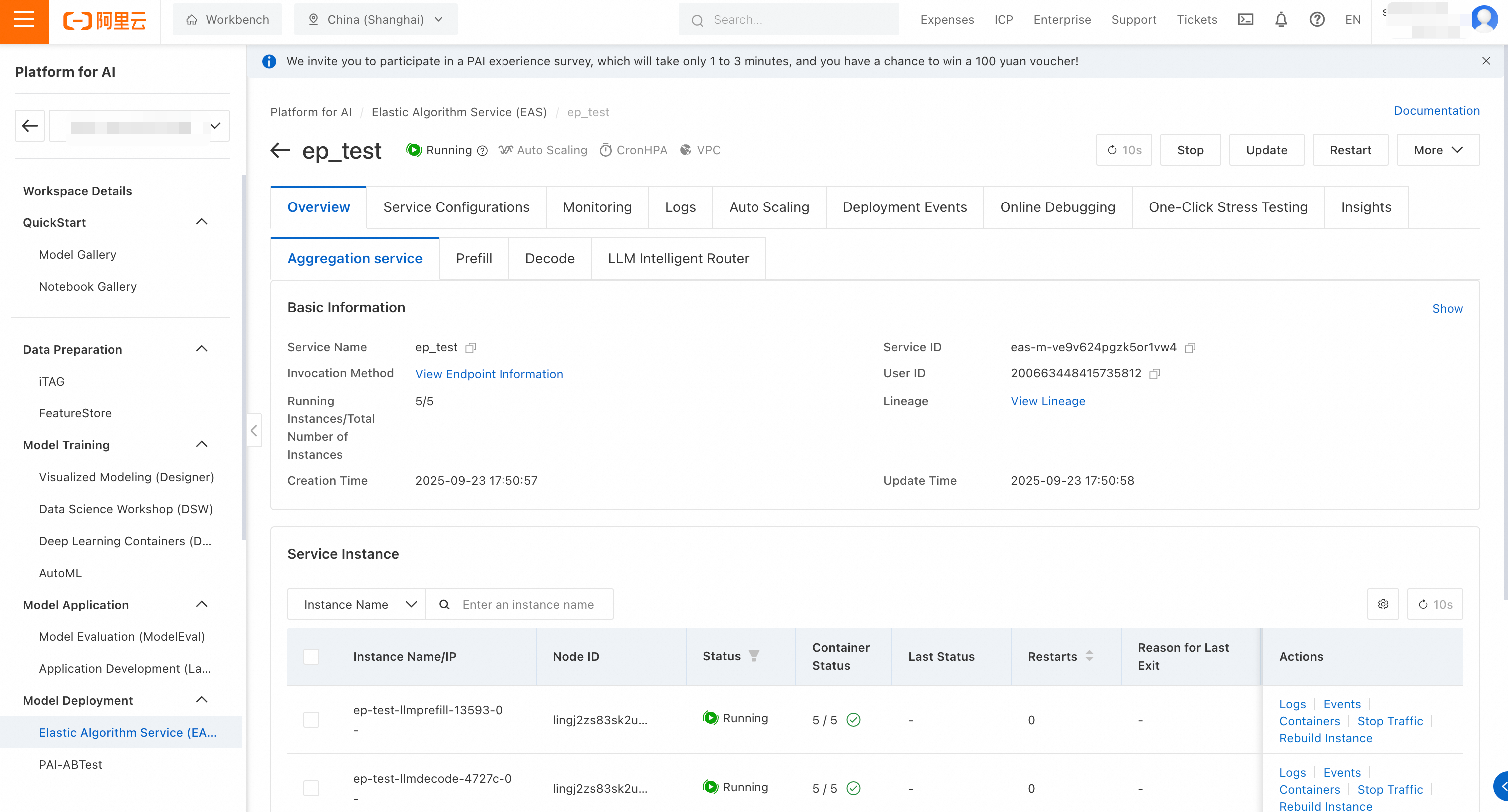
サービスの監視データとログを表示し、自動スケーリングポリシーを設定できます。