混同行列コンポーネントは、予測ラベルと実際のラベルを比較し、その結果をマトリックス形式で表示することで、分類モデルの性能を評価します。各セルには、特定の「実際のクラス vs 予測クラス」の組み合わせに該当するサンプル数が表示され、モデルがどのクラスを他のクラスと混同しているかを簡単に把握できます。このコンポーネントは教師あり学習向けに設計されており、教師なし学習における対応マトリックスに相当します。
サポートされるコンピューティングエンジン: MaxCompute のみ。
仕組み
このコンポーネントは、予測結果テーブルを入力として受け取ります。各行が 1 つのサンプルを表し、実際のラベルと予測ラベル(または予測確率)を含むカラムを持ちます。コンポーネントは、「実際のクラス vs 予測クラス」の各組み合わせに該当するサンプル数を集計し、結果を出力テーブルに書き込みます。
マトリックスの読み方: 各行は実際の(真の)クラスに対応し、各列は予測されたクラスに対応します。対角セルには正しく分類されたサンプル数が表示され、対角成分の値が高いほどモデルの性能が良好であることを示します。非対角セルには誤って分類されたサンプル数が表示され、モデルがどのクラスを混同しているかを明らかにします。
二項分類では、しきい値を設定して予測確率をラベルに変換できます。予測確率がしきい値を超えるサンプルは正例として扱われます。
コンポーネントの設定
混同行列コンポーネントは、Machine Learning Designer で設定する方法(方法 1)と、SQL スクリプト内で PAI コマンドを実行する方法(方法 2)のいずれかで設定できます。
方法 1: Machine Learning Designer で設定
パラメーターの選択: 予測結果ラベルカラム または 予測結果詳細カラム のいずれか一方のみを使用します。予測結果ラベルカラム は、入力テーブルにすでに予測ラベルが含まれている場合に使用します。予測結果詳細カラム は、確率のしきい値を適用して正例を判定したい場合に使用します。
| パラメーター | 説明 |
|---|---|
| 元ラベルカラム | 実際の(正解)ラベルを含むカラムです。数値型のデータがサポートされています。 |
| 予測結果ラベルカラム | 予測ラベルを含むカラムです。しきい値 を設定しない場合に必須です。 |
| しきい値 | 正例を判定するための確率のカットオフ値です。このしきい値を超える予測値を持つサンプルは正例として分類されます。 |
| 予測結果詳細カラム | 予測確率を含むカラムです。しきい値 を設定する場合に必須です。予測結果ラベルカラム とは同時に使用できません。 |
| 正例ラベル | 二項分類において正例を識別するラベル値です。しきい値 を設定する場合に必須です。 |
方法 2: PAI コマンドの実行
SQL スクリプト内で PAI コマンドを使用してコンポーネントを設定および実行します。詳細については、「SQL スクリプト」をご参照ください。
すべてのコマンドは、confusionmatrix アルゴリズム名と algo_public プロジェクトを使用します。
モードの選択: 入力テーブルにすでに予測ラベルが含まれている場合は predictionColName を使用します。予測確率に基づいてサンプルを分類したい場合は、predictionDetailColName と threshold を併用します。
しきい値なし(ラベルベースの分類):
pai -name confusionmatrix -project algo_public
-DinputTableName=wpbc_pred
-DoutputTableName=wpbc_confu
-DlabelColName=label
-DpredictionColName=prediction_result;しきい値あり(確率ベースの二項分類):
pai -name confusionmatrix -project algo_public
-DinputTableName=wpbc_pred
-DoutputTableName=wpbc_confu
-DlabelColName=label
-DpredictionDetailColName=prediction_detail
-Dthreshold=0.8
-DgoodValue=N;パラメーター:
| パラメーター | 必須 | 説明 | デフォルト |
|---|---|---|---|
inputTableName | はい | 入力テーブル(予測結果テーブル)の名前です。 | — |
inputTablePartition | いいえ | 入力テーブルから読み取るパーティションです。 | 全テーブル |
outputTableName | はい | 混同行列を格納する出力テーブルの名前です。 | — |
labelColName | はい | 実際のラベルカラムの名前です。 | — |
predictionColName | いいえ | 予測ラベルカラムの名前です。threshold を設定しない場合に必須です。predictionDetailColName とは同時に設定できません。 | — |
predictionDetailColName | いいえ | 予測確率カラムの名前です。threshold を設定する場合に必須です。predictionColName とは同時に設定できません。 | — |
threshold | いいえ | サンプルを正例として分類するための確率のカットオフ値です。 | 0.5 |
goodValue | いいえ | 二項分類において正例を識別するラベル値です。threshold を設定する場合に必須です。 | — |
coreNum | いいえ | 使用するコア数です。 | 自動割り当て |
memSizePerCore | いいえ | コアあたりに割り当てるメモリ量(単位:MB)です。 | 自動割り当て |
lifecycle | いいえ | 出力テーブルのライフサイクルです。 | — |
例
この例では、ラベルクラスが A と B の 2 種類ある 10 行のデータセットを使用した二項分類シナリオを紹介します。
ステップ 1: 入力テーブルの作成
次のスキーマを持つ test_data という名前の MaxCompute テーブルを作成します。
| カラム | 型 |
|---|---|
id | bigint |
label | string |
prediction_result | string |
設定手順については、「MaxCompute クライアント (odpscmd)」および「テーブルの作成」をご参照ください。
ステップ 2: テストデータのインポート
次のデータを test_data にインポートします。インポート手順については、「テーブルへのデータのインポート」をご参照ください。
| id | label | prediction_result |
|---|---|---|
| 0 | A | A |
| 1 | A | B |
| 2 | A | A |
| 3 | A | A |
| 4 | B | B |
| 5 | B | B |
| 6 | B | A |
| 7 | B | B |
| 8 | B | A |
| 9 | A | A |
ステップ 3: パイプラインの構築と実行
Machine Learning Designer を開き、テーブル読み取り コンポーネントと 混同行列 コンポーネントをキャンバス上にドラッグします。
次の図のようにコンポーネントを接続します。
テーブル読み取り -1 コンポーネントを設定します:テーブル選択 タブで、テーブル名 を
test_dataに設定します。混同行列 -1 コンポーネントを設定します: 他のすべてのパラメーターはデフォルト値を使用します。
パラメーター 値 元ラベルカラム label予測結果ラベルカラム prediction_result をクリックしてパイプラインを実行します。詳細については、「アルゴリズムモデリング」をご参照ください。
をクリックしてパイプラインを実行します。詳細については、「アルゴリズムモデリング」をご参照ください。
ステップ 4: 結果の確認
パイプラインの実行が完了したら、混同行列 -1 コンポーネントを右クリックし、ビジュアル分析 を選択します。
混同行列 タブ: 完全なマトリックスを表示します。行は実際のクラスを、列は予測されたクラスを表します。対角成分の値が高いほど、正しく予測されたサンプルが多いことを示します。非対角成分の値は誤って分類されたサンプルを示しており、たとえばクラス
Aの行とクラスBの列の交点にある値は、多くのAサンプルが誤ってBと予測されたことを意味します。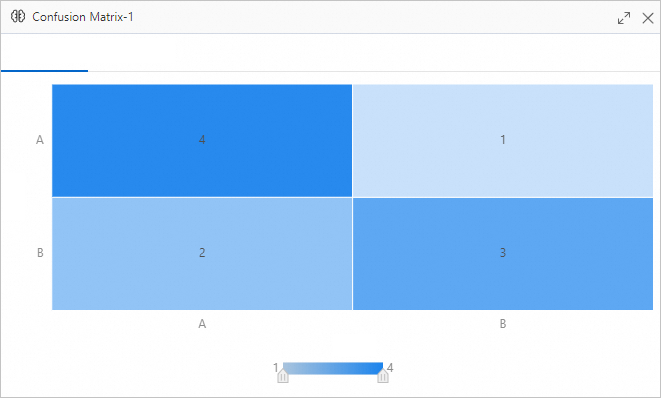
統計情報 タブ: モデルに関する統計情報を表示します。