Data Science Workshop (DSW) と NAS ストレージを使用して、Deep Learning Containers (DLC) で PyTorch 転移学習ジョブを送信します。
前提条件
ターゲットリージョンに汎用型 NAS ファイルシステムを作成します。 詳細については、「コンソールを使用した汎用型 NAS ファイルシステムの作成」をご参照ください。
制限事項
このドキュメントの操作は、パブリックリソースグループの汎用コンピューティングリソースを使用するクラスターにのみ適用されます。
データセットの作成
-
[データセット] ページに移動します。
-
PAI コンソールにログインします。
-
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
-
左側のナビゲーションウィンドウで、 を選択します。
-
-
基本データセットを作成します。 [ストレージクラス] パラメーターを [汎用型 NAS] に設定します。
DSW インスタンスの作成
DSW インスタンスを作成し、次のパラメーターを設定します。 詳細については、「DSW インスタンスの作成」をご参照ください。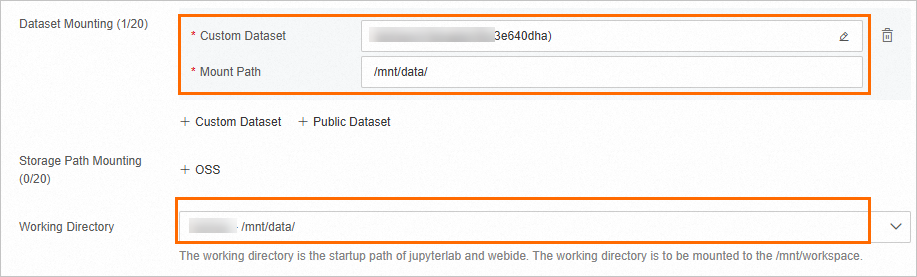
|
パラメーター |
説明 |
|
|
[環境コンテキスト] |
[データセットマウント] |
「[カスタムデータセット]」をクリックし、前のセクションで作成した NAS データセットを選択して、「[マウントパス]」を |
|
[作業ディレクトリ] |
|
|
|
[ネットワーク情報] |
[VPC 設定] |
不要です。 |
データの準備
公開されているトレーニングデータ (データのダウンロード) をダウンロードして解凍します。
-
DSW インスタンスの開発環境に移動します。
-
PAI コンソールにログインします。
-
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
-
ページの左上隅で、PAI を使用するリージョンを選択します。
-
左側のナビゲーションウィンドウで、 を選択します。
-
任意: [Data Science Workshop (DSW)] ページで、検索ボックスに DSW インスタンスの名前またはキーワードを入力して、DSW インスタンスを検索します。
-
インスタンスの [操作] 列にある [開く] をクリックします。
-
-
DSW 開発環境の上部にあるメニューバーで、[ノートブック] をクリックします。
-
データをダウンロードします。
-
左上のツールバーにある
 アイコンをクリックして、`pytorch_transfer_learning` という名前のフォルダを作成します。
アイコンをクリックして、`pytorch_transfer_learning` という名前のフォルダを作成します。 -
メニューバーで [ターミナル] をクリックしてターミナルを開きます。
-
ターミナルで、作成したフォルダに移動し、データセットをダウンロードします。
cd /mnt/workspace/pytorch_transfer_learning/ wget https://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/data.tar.gz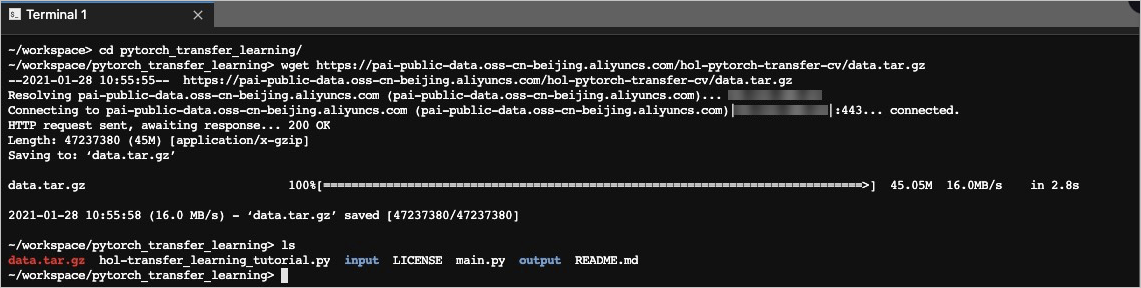
-
データセットを解凍します。
tar -xf ./data.tar.gz -
[ノートブック] タブに切り替え、`pytorch_transfer_learning` ディレクトリに移動し、解凍したデータフォルダ (`hymenoptera_data`) を右クリックして、[名前の変更] を選択します。 名前を input に変更します。
-
トレーニングコードとモデルストレージの準備
-
pytorch_transfer_learningフォルダにトレーニングコードをダウンロードします。cd /mnt/workspace/pytorch_transfer_learning/ wget https://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/main.py -
トレーニング済みモデルを格納するための output フォルダを作成します。
mkdir output -
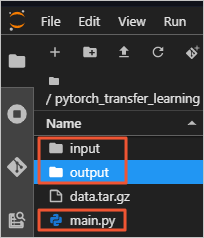
フォルダに次のファイルが含まれていることを確認します:
-
input:トレーニングデータフォルダ。
-
main.py:トレーニングコード。
-
output:モデルストレージフォルダ。
-
ジョブの作成
-
[ジョブの作成] ページに移動します。
-
PAI コンソールにログインします。 ページの上部でターゲットリージョンとワークスペースを選択し、[Deep Learning Containers (DLC)] をクリックします。
-
[Deep Learning Containers (DLC)] ページで、Create Job をクリックします。
-
-
[ジョブの作成] ページで次のパラメーターを設定します。
パラメーター
説明
基本情報
ジョブ名
ディープラーニングトレーニングジョブの名前です。
環境コンテキスト
ノードイメージ
[Alibaba Cloud イメージ] を選択し、PyTorch イメージを選択します。 例:
pytorch-training:1.12-gpu-py39-cu113-ubuntu20.04。データセット
[カスタムデータセット] をクリックし、事前に作成した NAS データセットを選択します。
起動コマンド
次のコマンドを入力します:
python /mnt/data/pytorch_transfer_learning/main.py -i /mnt/data/pytorch_transfer_learning/input -o /mnt/data/pytorch_transfer_learning/outputサードパーティライブラリ設定
[サードパーティライブラリリスト] を選択し、次のライブラリを入力します:
numpy==1.16.4 absl-py==0.11.0コード設定
不要です。
リソース情報
リソースソース
[パブリックリソース] を選択します。
フレームワーク
[PyTorch] を選択します。
ジョブリソース
リソース仕様を選択します。 例: [リソース仕様] > [CPU] > [ecs.g6.xlarge] を選択し、[ノード数] を 1 に設定します。
-
[OK] をクリックします。
ジョブの詳細とログの表示
-
[Deep Learning Containers (DLC)] ページでジョブ名をクリックします。
-
ジョブの概要ページで [基本情報] と [リソース情報] を表示します。
-
ページ下部の [インスタンス] セクションで、[操作] 列の [ログ] をクリックします。
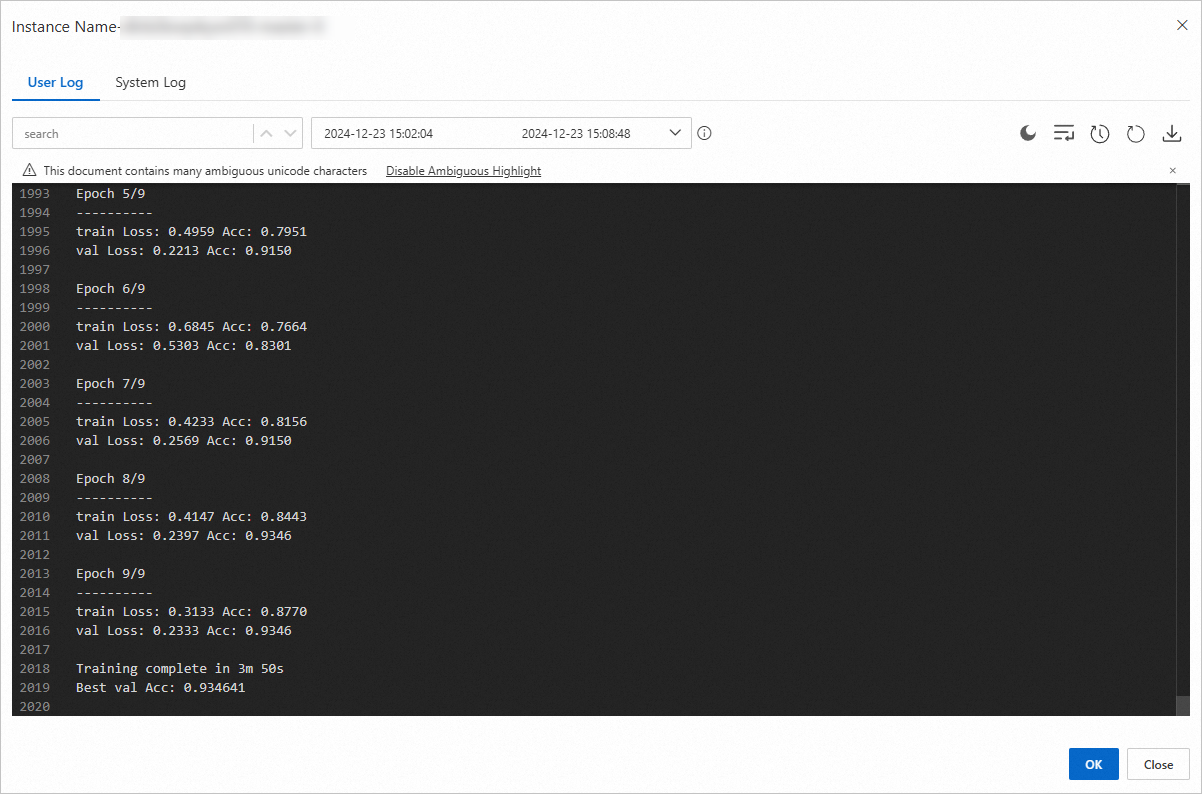
ログの例: